python网络编程
socket
Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。所以,我们无需深入理解tcp/udp协议,socket已经为我们封装好了,我们只需要遵循socket的规定去编程,写出的程序自然就是遵循tcp/udp标准的。
套接字分类
- 基于文件类型的套接字家族:AF_UNIX
- 基于网络类型的套接字家族:AF_INET
套接字工作流程
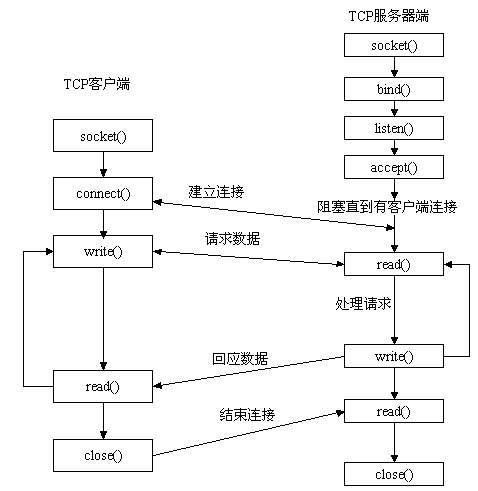
套接字函数
一、服务端套接字函数
- s.bind() 绑定(主机,端口号)到套接字
- s.listen() 开始TCP监听
- s.accept() 被动接受TCP客户的连接,(阻塞式)等待连接的到来
二、客户端套接字函数
- s.connect() 主动初始化TCP服务器连接
- s.connect_ex() connect()函数的扩展版本,出错时返回出错码,而不是抛出异常
三、公共用途的套接字函数
- s.recv() 接收TCP数据
- s.send() 发送TCP数据(send在待发送数据量大于己端缓存区剩余空间时,数据丢失,不会发完)
- s.sendall() 发送完整的TCP数据(本质就是循环调用send,sendall在待发送数据量大于己端缓存区剩余空间时,数据不丢失,循环调用send直到发完)
- s.recvfrom() 接收UDP数据
- s.sendto() 发送UDP数据
- s.getpeername() 连接到当前套接字的远端的地址
- s.getsockname() 当前套接字的地址
- s.getsockopt() 返回指定套接字的参数
- s.setsockopt() 设置指定套接字的参数
- s.close() 关闭套接字
四、面向锁的套接字方法
tcp是基于链接的,必须先启动服务端,然后再启动客户端去链接服务端
五、面向文件的套接字的函数
- s.fileno() 套接字的文件描述符
- s.makefile() 创建一个与该套接字相关的文件
基于TCP的套接字
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
"""服务端:"""import sockets=socket.socket(socket.AF_INET,socket.SOCK_STREAM) #创建服务器套接字s.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1) #重启服务端时遇上Address already in use 时加上,在bind前加s.bind(('127.0.0.1',8083)) #把地址绑定到套接字s.listen(5) #监听链接print('starting...')while True: # 链接循环 conn,client_addr=s.accept() #接受客户端链接 print(client_addr) while True: #通信循环 try: data=conn.recv(1024) if not data:break #适用于linux操作系统 正在链接的客户端突然断开,recv便不再阻塞,死循环发生 print('客户端的数据',data) conn.send(data.upper()) except ConnectionResetError: #适用于windows操作系统 break conn.close() #关闭客户端套接字s.close() #关闭服务器套接字(可选)"""客户端"""import socketc=socket.socket(socket.AF_INET,socket.SOCK_STREAM) # 创建客户套接字c.connect(('127.0.0.1',8083)) # 尝试连接服务器while True: # 通讯循环 msg=input('>>: ').strip() #msg='' if not msg:continue c.send(msg.encode('utf-8')) #c.send(b'') data=c.recv(1024) print(data.decode('utf-8'))c.close() # 关闭客户套接字 |
基于UDP的套接字
udp是无链接的,先启动哪一端都不会报错
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
"""服务端:"""from socket import *server=socket(AF_INET,SOCK_DGRAM)server.bind(('127.0.0.1',8080))while True: data,client_addr=server.recvfrom(1024) print(data) server.sendto(data.upper(),client_addr)server.close()"""客户端"""from socket import *client = socket(AF_INET, SOCK_DGRAM)while True: msg=input('>>: ').strip() client.sendto(msg.encode('utf-8'),('127.0.0.1',8080)) data,server_addr=client.recvfrom(1024) print(data,server_addr)client.close() |
粘包现象
一、产生原因
粘包问题主要是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的。
- 发送端需要等缓冲区满才发送出去,造成粘包(发送数据时间间隔很短,数据量很小,会合到一起,产生粘包)
- 接收方不及时接收缓冲区的包,造成多个包接收(客户端发送了一段数据,服务端只收了一小部分,服务端下次再收的时候还是从缓冲区拿上次遗留的数据,产生粘包)
二、补充说明
- TCP(transport control protocol,传输控制协议)是面向连接的,面向流的,提供高可靠性服务。
- UDP(user datagram protocol,用户数据报协议)是无连接的,面向消息的,提供高效率服务。
- 只有TCP有粘包现象,UDP永远不会粘包
三、解决粘包的方法
把报头做成字典,字典里包含将要发送的真实数据的详细信息,然后json序列化,然后用struck将序列化后的数据长度打包成4个字节
1.发送时:
- 先发报头长度
- 再编码报头内容然后发送
- 最后发真实内容
2.接收时:
- 先收报头长度,用struct取出来
- 根据取出的长度收取报头内容,然后解码,反序列化
- 从反序列化的结果中取出待取数据的详细信息,然后去取真实的数据内容
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
"""服务端"""import socketimport subprocessimport structimport jsonphone=socket.socket(socket.AF_INET,socket.SOCK_STREAM)phone.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)phone.bind(('127.0.0.1',9909)) phone.listen(5)print('starting...')while True: # 链接循环 conn,client_addr=phone.accept() print(client_addr) while True: #通信循环 try: #1、收命令 cmd=conn.recv(8096) if not cmd:break #适用于linux操作系统 #2、执行命令,拿到结果 obj = subprocess.Popen(cmd.decode('utf-8'), shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE) stdout=obj.stdout.read() stderr=obj.stderr.read() #3、把命令的结果返回给客户端 #第3.1步:制作固定长度的报头 header_dic={ 'filename':'a.txt', 'md5':'xxdxxx', 'total_size': len(stdout) + len(stderr) } header_json=json.dumps(header_dic) header_bytes=header_json.encode('utf-8') #第3.2步:先发送报头的长度 conn.send(struct.pack('i',len(header_bytes))) #第3.3步:再发报头 conn.send(header_bytes) #第3.4步:再发送真实的数据 conn.send(stdout) conn.send(stderr) except ConnectionResetError: #适用于windows操作系统 break conn.close()phone.close() |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
"""客户端"""import socketimport structimport jsonphone=socket.socket(socket.AF_INET,socket.SOCK_STREAM)phone.connect(('127.0.0.1',9909))while True: #1、发命令 cmd=input('>>: ').strip() #ls /etc if not cmd:continue phone.send(cmd.encode('utf-8')) #2、拿命令的结果,并打印 #第2.1步:先收报头的长度 obj=phone.recv(4) header_size=struct.unpack('i',obj)[0] #第2.2步:再收报头 header_bytes=phone.recv(header_size) #第2.3步:从报头中解析出对真实数据的描述信息 header_json=header_bytes.decode('utf-8') header_dic=json.loads(header_json) print(header_dic) total_size=header_dic['total_size'] #第2.4步:接收真实的数据 recv_size=0 recv_data=b'' while recv_size < total_size: res=phone.recv(1024) #1024是一个坑 recv_data+=res recv_size+=len(res) print(recv_data.decode('utf-8'))phone.close() |


""" 内网ip 192.168.0.0-192.168.255.255 172.16.0.0-172-172.31.255.255 10.0.0.0-10.255.255.255 网卡 mac地址 全球唯一 交换机进行局域网内的通讯 交换机:只认识mac地址,广播,单播,组播 arp协议:地址解析协议,已知一个机器的IP地址,获取这台机器的mac地址(广播-单播),由交换机完成的(广播,单播) 路由器 局域网与局域网的通讯,识别IP地址 网关IP,访问局域网外部服务的一个出口IP,访问局域网之外的区域都需要经过路由器和网关 网段指的是一个地址段 ip地址在网络上定位一台机器 ipv4 ipv6 端口port能够在网络上定位一台机器的一个服务 0-65535 子网掩码判断两台机器是否在同一个网段内 阻塞io模型 非阻塞io模型 事件驱动io io多路复用 异步io模型 非阻塞io模型+io多路复用 虽然非阻塞,提高了cpu的利用率,但是耗费了很多无用功 import os print(os.urandom(32)) server:接受链接,发送随机字符串,使用密钥和随机字符串计算,接受字符串,检测接受到的结果和自己计算的是否一致 client:发送连接请求,接受随机字符串,使用密钥和随机字符串计算,发送计算结果 """ import os import socket import hashlib def get_md5(secret_key,randseq): md5 = hashlib.md5(secret_key) md5.update(randseq) return md5.hexdigest() sk=socket.socket() sk.bind(('127.0.0.1',9000)) sk.listen() conn,addr=sk.accept() secret_key=b'qweqweqwe' randseq=os.urandom(32) conn.send(randseq) md5_code=get_md5(secret_key,randseq) ret=conn.recv(32).decode('utf-8') print(ret) if ret==md5_code: print('合法') else: print('非法') conn.close() sk.close() ######################客户端 import socket import hashlib def get_md5(secret_key,randseq): md5 = hashlib.md5(secret_key) md5.update(randseq) return md5.hexdigest() sk=socket.socket() sk.connect(('127.0.0.1',9000)) randseq=sk.recv(32) secret_key=b'qweqweqwe' md5_code=get_md5(secret_key,randseq) sk.send(md5_code.encode('utf-8')) sk.close() ###################### import os import hmac secret_key=b'qweqweqwe' randseq=os.urandom(32) hmac=hmac.new(secret_key,randseq) ret=hmac.digest() print(ret) #字节 print(len(ret)) #16 #######################
import os import struct def send_data(conn, content): """ 发送数据 """ data = content.encode('utf-8') header = struct.pack('i', len(data)) conn.sendall(header) conn.sendall(data) def recv_data(conn, chunk_size=1024): """ 接收数据 """ # 获取头部信息:数据长度 has_read_size = 0 bytes_list = [] while has_read_size < 4: chunk = conn.recv(4 - has_read_size) has_read_size += len(chunk) bytes_list.append(chunk) header = b"".join(bytes_list) data_length = struct.unpack('i', header)[0] # 获取数据 data_list = [] has_read_data_size = 0 while has_read_data_size < data_length: size = chunk_size if (data_length - has_read_data_size) > chunk_size else data_length - has_read_data_size chunk = conn.recv(size) data_list.append(chunk) has_read_data_size += len(chunk) data = b"".join(data_list) return data def recv_save_file(conn, save_file_path, chunk_size=1024): """ 接收并保存文件 """ # 获取头部信息:数据长度 has_read_size = 0 bytes_list = [] while has_read_size < 4: chunk = conn.recv(4 - has_read_size) bytes_list.append(chunk) has_read_size += len(chunk) header = b"".join(bytes_list) data_length = struct.unpack('i', header)[0] # 获取数据 file_object = open(save_file_path, mode='wb') has_read_data_size = 0 while has_read_data_size < data_length: size = chunk_size if (data_length - has_read_data_size) > chunk_size else data_length - has_read_data_size chunk = conn.recv(size) file_object.write(chunk) file_object.flush() has_read_data_size += len(chunk) file_object.close() def send_file_by_seek(conn, file_size, file_path, seek=0): """ 读取并发送文件(支持从指定字节位置开始读取)""" header = struct.pack('i', file_size) conn.sendall(header) has_send_size = 0 file_object = open(file_path, mode='rb') if seek: file_object.seek(seek) while has_send_size < file_size: chunk = file_object.read(2048) conn.sendall(chunk) has_send_size += len(chunk) file_object.close()
socketserver实现并发
- 基于tcp的套接字,关键就是两个循环,一个链接循环,一个通信循环
- socketserver模块中分两大类:server类(解决链接问题)和request类(解决通信问题)
import socketserver #1、引入模块 class MyServer(socketserver.BaseRequestHandler): #2、自己写一个类,类名自己随便定义,然后继承socketserver这个模块里面的BaseRequestHandler这个类 def handle(self): #3、写一个handle方法,必须叫这个名字 #self.request #6、self.request 相当于一个conn self.request.recv(1024) #7、收消息 msg = '亲,学会了吗' self.request.send(bytes(msg,encoding='utf-8')) #8、发消息 self.request.close() #9、关闭连接 # 拿到了我们对每个客户端的管道,那么我们自己在这个方法里面的就写我们接收消息发送消息的逻辑就可以了 pass if __name__ == '__mian__': server = socketserver.ThreadingTCPServer(('127.0.0.1',8090),MyServer)#4、使用socketserver的ThreadingTCPServer这个类,将IP和端口的元祖传进去,还需要将上面咱们自己定义的类传进去,得到一个对象,相当于我们通过它进行了bind、listen server.serve_forever() #5、使用我们上面这个类的对象来执行serve_forever()方法,他的作用就是说,我的服务一直开启着,就像京东一样,不能关闭网站,对吧,并且serve_forever()帮我们进行了accept
import socket HOST, PORT = "127.0.0.1", 9999 data = "hello" # 创建一个socket链接,SOCK_STREAM代表使用TCP协议 with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as sock: sock.connect((HOST, PORT)) # 链接到客户端 sock.sendall(bytes(data + "\n", "utf-8")) # 向服务端发送数据 received = str(sock.recv(1024), "utf-8")# 从服务端接收数据 print("Sent: {}".format(data)) print("Received: {}".format(received))
""" 1.功能类 class Myserver(socketserver.BaseRequestHandler): def handle(self): #放入要并发的逻辑 self.request 就是之前的conn pass 2.server=socketserver.ThreadingTCPServer(("127.0.0.1",8881),Myserver) 3.server.serve_forever() """ import socketserver class Myserver(socketserver.BaseRequestHandler): def handle(self): #放入要并发的逻辑 self.request 就是之前的conn while True: try: client_data=self.request.recv(1024) if len(client_data)==0: break # 适用于linux操作系统 正在链接的客户端突然断开,recv便不再阻塞,死循环发生 print ("客户端的数据 >>>",str(client_data,"utf8")) server_data=input("服务端的数据 >>>").strip() self.request.send(bytes(server_data,"utf8")) except ConnectionResetError: # 适用于windows操作系统 break self.request.close() server=socketserver.ThreadingTCPServer(("127.0.0.1",8881),Myserver) server.serve_forever() ###################################################################### import socket c=socket.socket(socket.AF_INET,socket.SOCK_STREAM) # 创建客户套接字 c.connect(('127.0.0.1',8881)) # 尝试连接服务器 while True: # 通讯循环 msg=input('>>: ').strip() #msg='' if not msg:continue c.send(msg.encode('utf-8')) #c.send(b'') data=c.recv(1024) print(data.decode('utf-8')) c.close() # 关闭客户套接字
四、分析socketserver源码:
- server=socketserver.ThreadingTCPServer(("127.0.0.1",8881),Myserver)
- server.serve_forever()
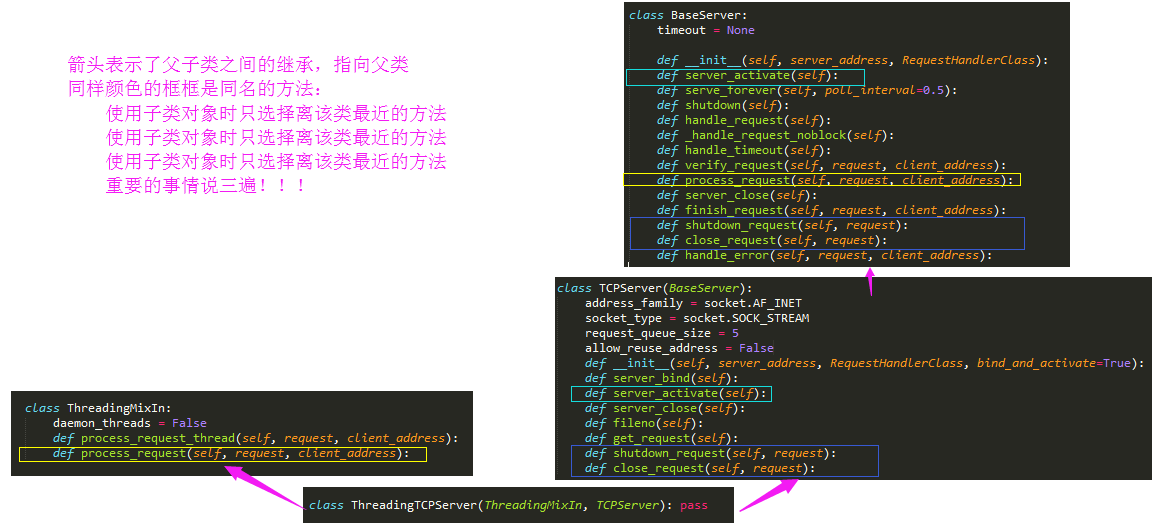
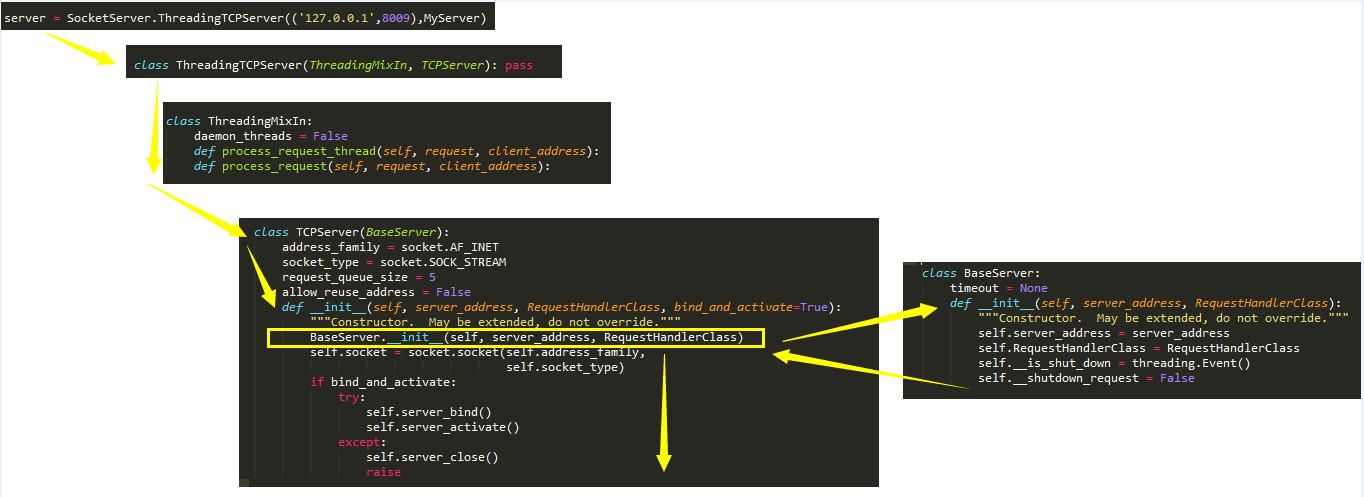
- 查找属性的顺序:ThreadingTCPServer->ThreadingMixIn->TCPServer->BaseServer
- 实例化得到server,先找类ThreadingTCPServer的__init__,在TCPServer中找到,进而执行server_bind,server_active
- 找server下的serve_forever,在BaseServer中找到,进而执行self._handle_request_noblock(),该方法同样是在BaseServer中 执行self._handle_request_noblock()进而执行request,client_address = self.get_request()(就是TCPServer中的self.socket.accept()),然后执行self.process_request(request, client_address)
- 在ThreadingMixIn中找到process_request,开启多线程应对并发,进而执行process_request_thread,执行self.finish_request(request, client_address) 上述完成了链接循环.
- 开始进入通讯部分,在BaseServer中找到finish_request,触发我们自己定义的类的实例化,去找__init__方法,而我们自己定义的类没有该方法,则去它的父类也就是BaseRequestHandler中找__init__方法....
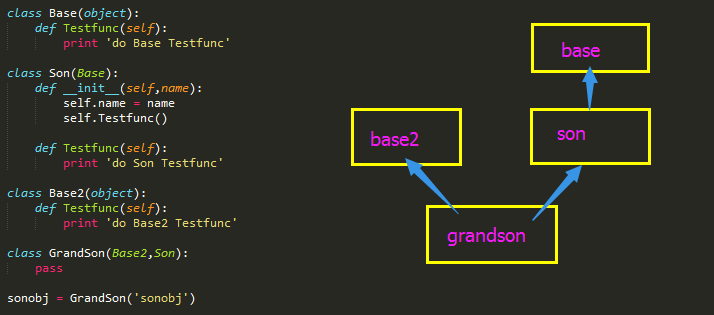
#_*_coding:utf-8_*_ """ 尽管Son继承了Base类,父子类中都有同样的方法, 但是由于我们实例化了子类的对象,所以这个在初始化方法里的self.Testfunc, self指的是子类的对象,当然也就先调用子类中的方法啦。 所以尽管初始化方法在父类执行,但是还是改变不了它是子类对象的本质, 当使用self去调用Testfunc方法时,始终是先调用子类的方法。 """ class Base(object): def __init__(self,name): self.name = name self.Testfunc() def Testfunc(self): print ('do Base Testfunc') class Son(Base): def Testfunc(self): print ('do Son Testfunc') sonobj = Son('sonobj') # do Son Testfunc """ 尽管这三个类中都有同样的Testfunc方法,但是,由于计算机在找方法的时候, 遵循的顺序是:Base2,Son,Base,所以它会先找到Base2类, 而这个类中刚好有它要找的方法,它也就拿去执行啦! """ class Base(object): def Testfunc(self): print ('do Base Testfunc') class Son(Base): def __init__(self,name): self.name = name self.Testfunc() def Testfunc(self): print ('do Son Testfunc') class Base2(object): def Testfunc(self): print ('do Base2 Testfunc') class GrandSon(Base2,Son): pass sonobj = Son('sonobj') #do Son Testfunc sonobj = GrandSon('sonobj') #do Base2 Testfunc class A: def func(self): super().func() #B里的func 此处的super是找mro中的下一个 print('AAA') class B: def func(self): print('BBB') class C(A,B): pass c=C() c.func() #BBB AAA print(C.mro()) #[<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>, <class 'object'>]
""" MRO方法路径顺序: py2 1.使用经典类(写继承关系的时候,基类不继承object) 2.新式类(继承关系的根,是)object py3 只有新式类 经典类的MRO使用的是深度优先遍历 新式类中摒弃了(部分)旧的深度优先算法,使用C3算法 如果你的继承关系中没有菱形继承(深度优选就够了) 如果有菱形:使用C3算法来计算MRO 假设C3算法:是L(x)表示x的继承关系 先拆分,拆到你能看出结果为止,反着进行merge()运算 合并 merge(元祖,元祖,元祖...) (GECAMNO),(FDBECA) (ECAMNO),(FDBECA) G (ECAMNO),(DBECA) GF (ECAMNO),(BECA) GFD (ECAMNO),(ECA) GFDB (CAMNO),(CA) GFDBE (AMNO),(A) GFDBECAMNO ... GFDBECAMNO 摘头 头和尾在比对,如果下一个尾没有这个头,头就出现,如果头在后面的尾出现,跳过该元祖,继续下一个头,直到最后一个元素跟自己去匹配 --super--可以访问MRO列表中的下一个类中的内容,找父类。 不管super()写在那,在那执行,一定先找到MRO列表,根据MRO列表的顺序往下找,否则一切都是错的。 """
1:threadingTCPServer的相关类:
2:初始化相关过程:
3:执行serve_forever的相关代码:
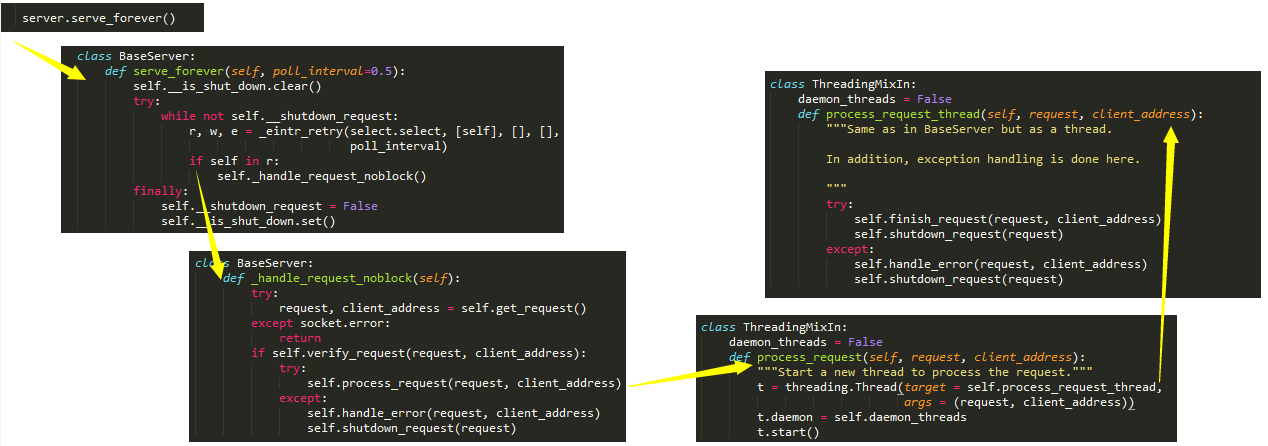
五、源码分析总结:
1、基于tcp的socketserver我们自己定义的类中的
- self.server即套接字对象
- self.request即一个链接
- self.client_address即客户端地址
2、基于udp的socketserver我们自己定义的类中的
- self.request是一个元组(第一个元素是客户端发来的数据,第二部分是服务端的udp套接字对象),如(b'adsf', )
- self.client_address即客户端地址

 浙公网安备 33010602011771号
浙公网安备 33010602011771号