

textRNN
textRNN利用RNN循环神经网络解决文本分类问题
流程:embedding—>BiLSTM—>concat final output/average all output—–>softmax layer
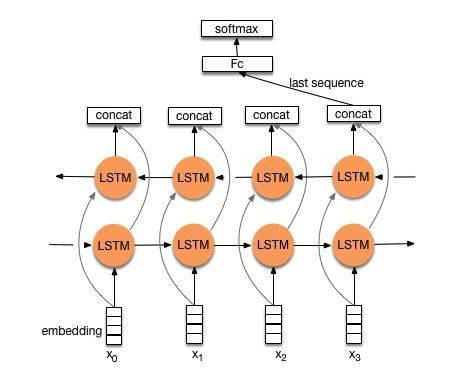
一般取前向/反向LSTM在最后一个时间步长上隐藏状态,然后进行拼接,在经过一个softmax层(输出层使用softmax激活函数)进行多分类;
或者取前向/反向LSTM在每一个时间步长上的隐藏状态,对每一个时间步长上的两个隐藏状态进行拼接,然后对所有时间步长上拼接后的隐藏状态取均值,再经过一个softmax层进行分类。
可以添加dropout/L2正则化或BatchNormalization 来防止过拟合以及加速模型训练。
特点
- 结构非常灵活,可以任意改变。把LSTM单元替换为GRU单元,把双向改为单向,添加dropout或BatchNormalization以及再多堆叠一层等。
- TextRNN在文本分类任务上的效果与TextCNN不相上下,但RNN的训练速度相对偏慢。
textCNN
TextCNN中采用的是一维卷积,每个卷积核的大小为h×kh×k(h为卷积核的窗口大小,k为词向量的维度)通过采用了多种不同尺寸的卷积核,用以提取不同文本长度的特征。
对于卷积核的输出进行MaxPooling,目的是提取最重要的特征。
将所有卷积核的输出通过MaxPooling之后拼接形成一个新向量,再将该向量输出到全连接层分类器(Dropout + Linear + Softmax)实现文本分类
池化层可以解决每次输入的文本的长度不同造成向量维度不相同的问题
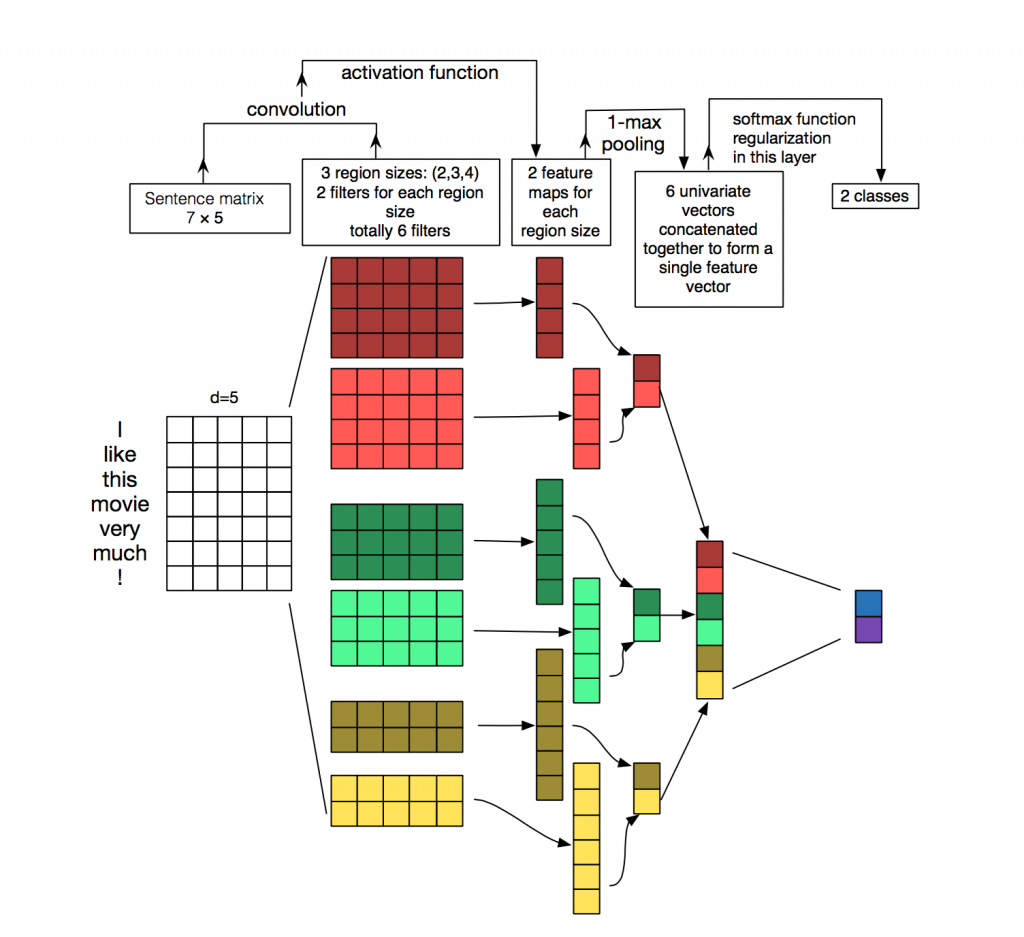
⽤⼀个例⼦解释了textCNN的设计。这⾥的输⼊是⼀个有11个词的句⼦,每个词⽤6维词向量表⽰。因此输⼊序列的宽为11,输⼊通道数为6。给定2个⼀维卷积核,核宽分别为2和4,输出通道数分别设为4和5。因此,⼀维卷积计算后,4个输出通道的宽为 11 - 2 + 1 = 10,而其他5个通道的宽为 11 - 4 + 1 = 8。尽管每个通道的宽不同,我们依然可以对各个通道做时序最⼤池化,并将9个通道的池化输出连结成⼀个9维向量。最终,使⽤全连接将9维向量变换为2维输出,即正⾯情感和负⾯情感的预测。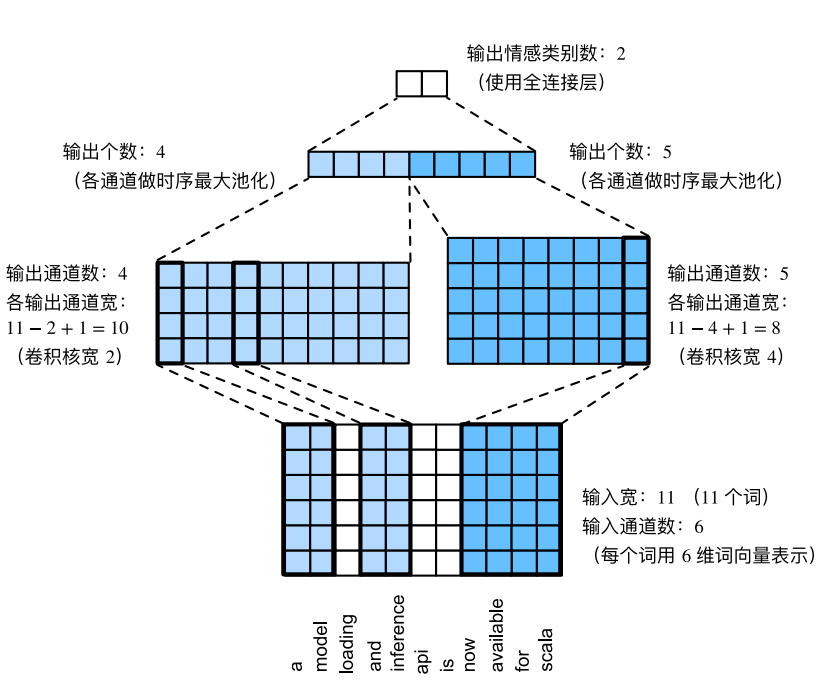
特点
- 对短距离文本效果挺好,而且计算速度快,但是无法捕获长距离文本。
- 提取特征最大的优势,不规则矩阵不做任何处理可以变为规则的向量;可以通过灵活使用卷积核对不同的局部特征进行抽取
TextRCNN
在TextCNN网络中,网络结构是卷积层+池化层的形式,卷积层用于提取n-gram类型的特征
在RCNN中,卷积层的特征提取的功能被双向RNN替代,因此整体结构变为了双向RNN+池化层
具体来说,在embedding的基础上加上了上下文环境作为新的词嵌入表示;左侧和右侧的context是通过前向和后向两层RNN的中间层输出得到;中间层的输出和原始的词嵌入拼接形成新的词嵌入y,然后送入池化层
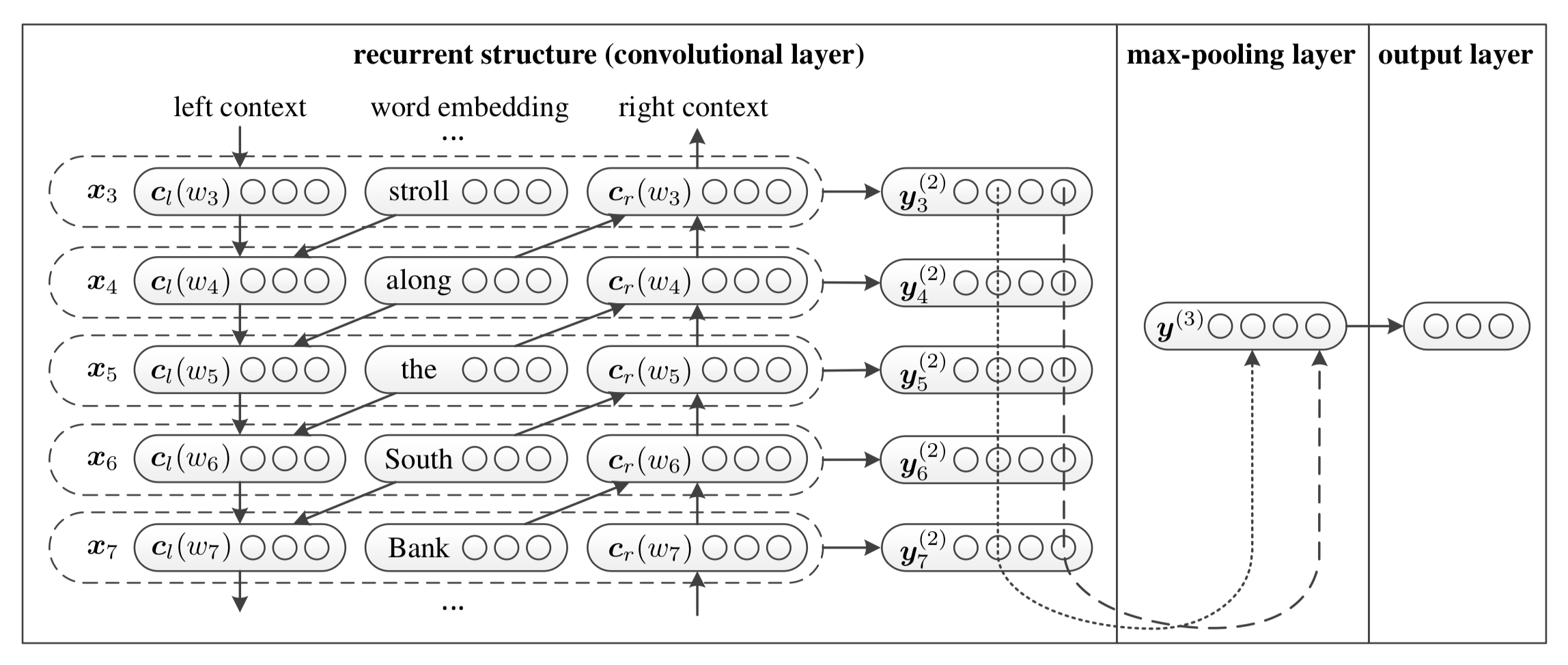
大致步骤:

优势:
- 用双向循环结构来尽可能多地获取上下文信息,这比传统的基于窗口的神经网络更能减少噪声,而且在学习文本表达时可以大范围的保留词序。
- 其次使用最大池化层获取文本的重要部分,自动判断哪个特征在文本分类过程中起更重要的作用。
FastText
FastText是Facebook于2016年发布的文本分类模型,主要思想基于word2vec中的skip-gram模型,在训练文本分类模型的同时也将训练出字符级n-gram词向量。
对比skip-gram模型,可以FastText的词典规模会更大,模型参数会更多。
但每一个词的词向量都是子词向量的和,使得一些生僻词或未出现的单词能够从形态相近的单词中得到较好的词向量表示,从而在一定程度上能够解决OOV问题
字符级别的n-gram
fastText使用了字符级别的n-grams来表示一个单词,对于“apple”,假设n的取值为3,则它的trigram有:
"<ap","app","ppl","ple","le>"
其中<表示前缀,>表示后缀,于是可以使用这5个trigram的向量叠加来表示“apple”的词向量
优点:对于低频词生成的词向量效果会更好,因为它们的n-gram可以和其他词共享;对于训练词库之外的单词,仍然可以构建它们的词向量,可以叠加它们的字符级别n-gram向量
模型结构
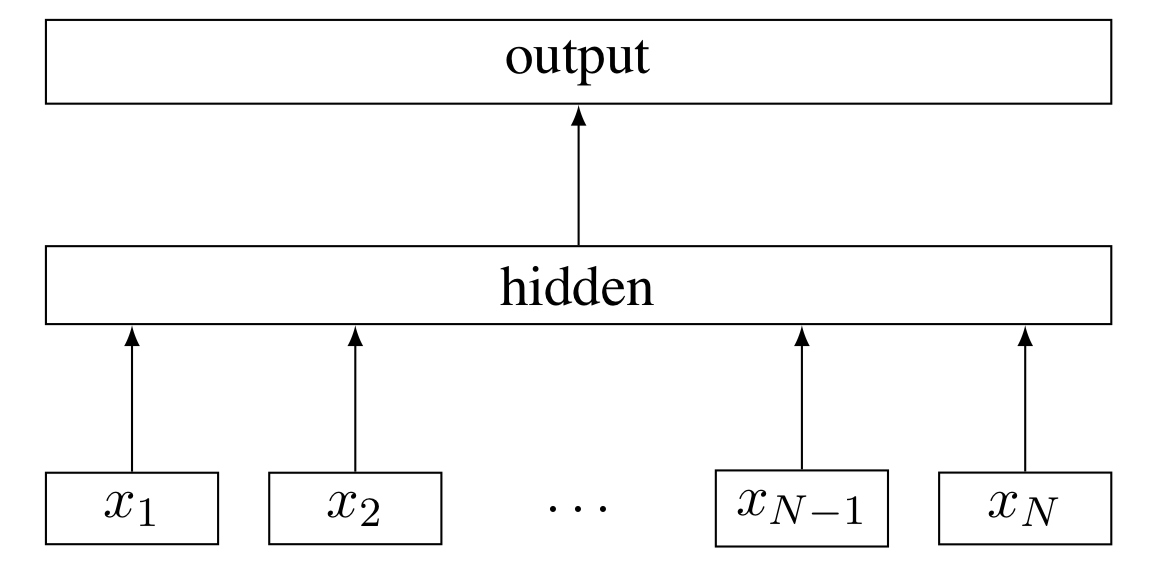
fastText模型包括输入层、隐含层、输出层共三层。输入的是词向量,输出的是label,隐含层是对多个词向量的叠加平均。
将整篇文档的词及n-gram向量叠加平均得到文档向量,然后使用文档向量做softmax多分类
与CBOW模型对比
1)CBOW的输入是目标单词的上下文,fastText的输入是多个单词及其n-gram特征,这些单词用来表示单个文档
2)CBOW的输入单词被one-hot编码过,fastText的输入特征时被embedding
3)CBOW的输出是目标词汇,fastText的输出是文档对应的分类标签

 浙公网安备 33010602011771号
浙公网安备 33010602011771号