
LSTM&GRU
LSTM
LSTM的全称是Long Short Term Memory,顾名思义,是具有记忆长短期信息的能力的神经网络。LSTM首先在1997年由Hochreiter & Schmidhuber提出,由于深度学习在2012年的兴起,LSTM又经过了若干代大牛的发展形成了比较系统且完整的LSTM框架,并且在很多领域得到了广泛的应用。
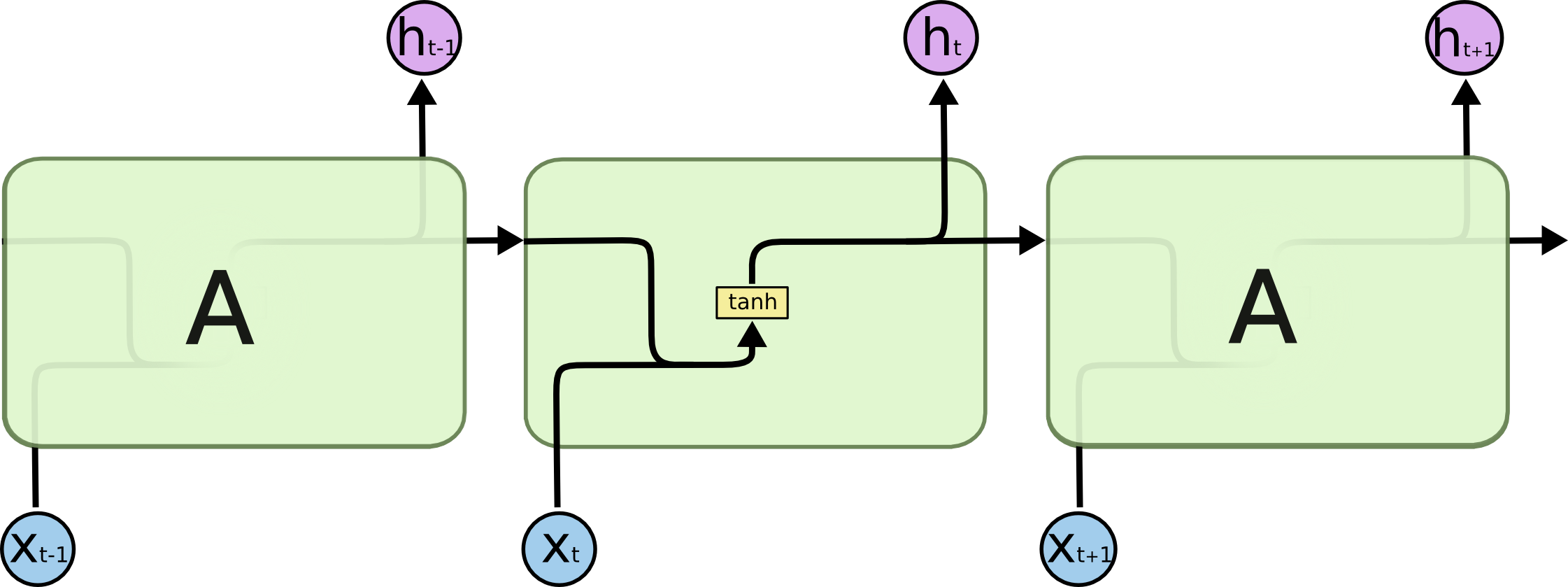
传统的RNN节点输出仅由权值,偏置以及激活函数决定。RNN是一个链式结构,每个时间片使用的是相同的参数。
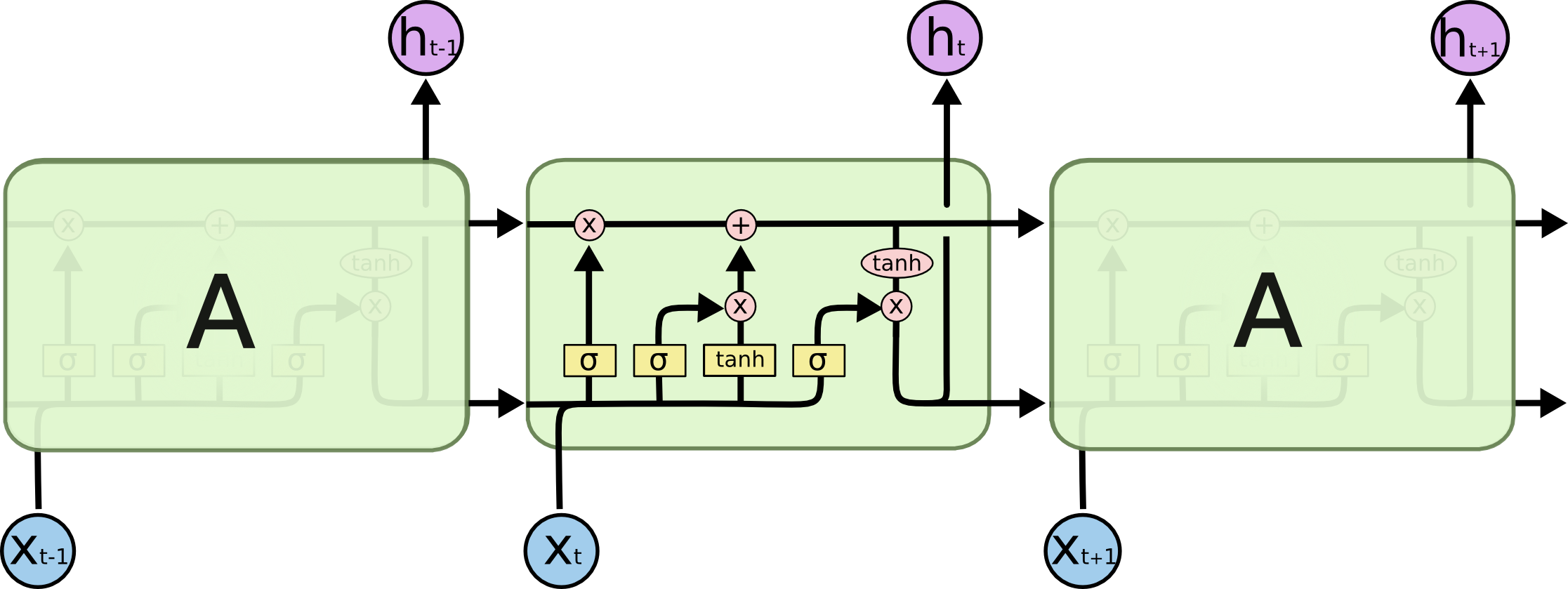
LSTM通过引入门结构来减弱短期记忆的影响,包括遗忘门,输入门和输出门,每一时刻具有细胞状态和隐层状态。LSTM中贯穿细胞的水平线Ct代表了长时记忆,下面的ht代表了工作记忆或短时记忆
RNN结构
LSTM结构
模型结构
遗忘门
作用:决定是否要保留信息
- 前一个隐藏状态和当前输入拼接,通过权重矩阵及偏置项后进入sigmoid函数,使得输出值介于0和1之间,并判断是否需要保留

sigmoid激活函数的作用
sigmoid函数的输出为0-1的值,这代表具体有多少的信息能够流过sigmoid层,0表示不能通过(丢弃),1表示能通过(保留)
输入门
作用:更新细胞状态
首先,需要考虑给细胞新增添的信息(即需要给细胞更新什么)。它利用ht-1和xt通过一个tanh层得到新的候选细胞信息$\widetilde{C_t}$,这些新的信息会被更新到细胞信息中
- 前一个隐藏状态和当前输入进入sigmoid函数;
- 前一个隐藏状态和当前输入进入tanh函数;
- sigmoid结果和tanh结果相乘
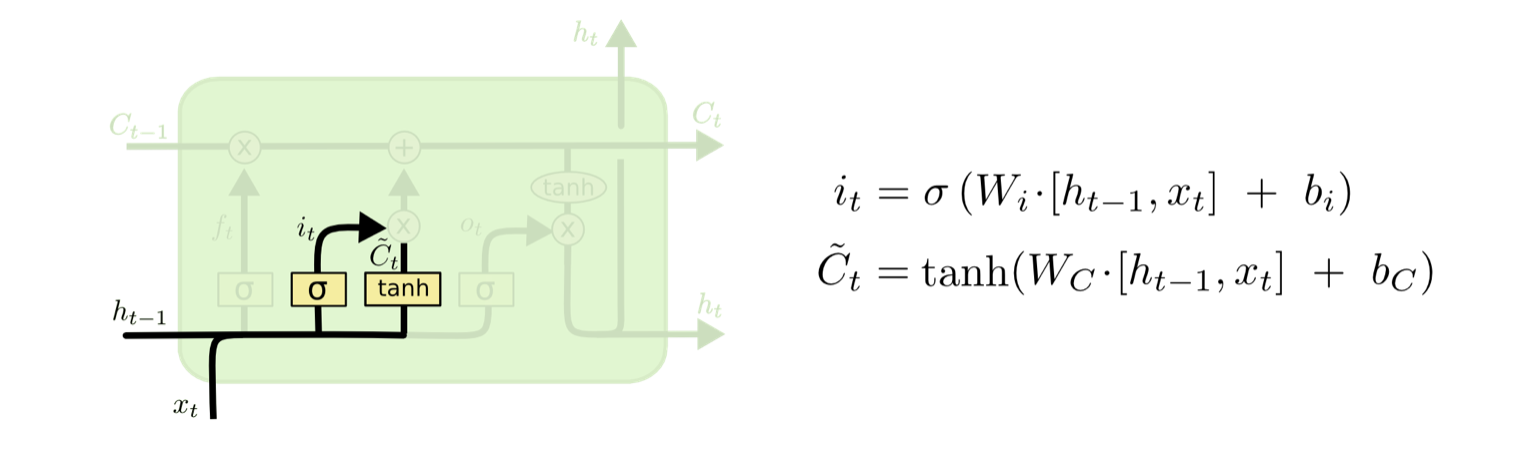
tanh函数的作用
tanh函数(即双曲正切)来说,它类似于幅度增大的sigmoid,输出范围为[-1,1],且导函数的取值范围为0-1之间,由于sigmoid的0到1/4,在一定程度上减轻了梯度消失的问题;同时,它需要做对数据的处理,不决定取舍,通过扩大输出范围进而决定输出放大或缩小。
细胞状态计算
需要对旧的细胞信息Ct-1进行更新完善,变为新的细胞信息Ct。更新的原则则是将通过遗忘门的旧细胞信息与通过输入门的候选细胞信息$\widetilde{C_t}$相结合得到新的细胞信息Ct
- 前一个细胞状态和遗忘门结果点乘;
- 点乘结果与输入门结果相加,得到更新的细胞状态;

输出门
作用:确定下一个隐藏状态,判断需要输出细胞的哪些状态特征
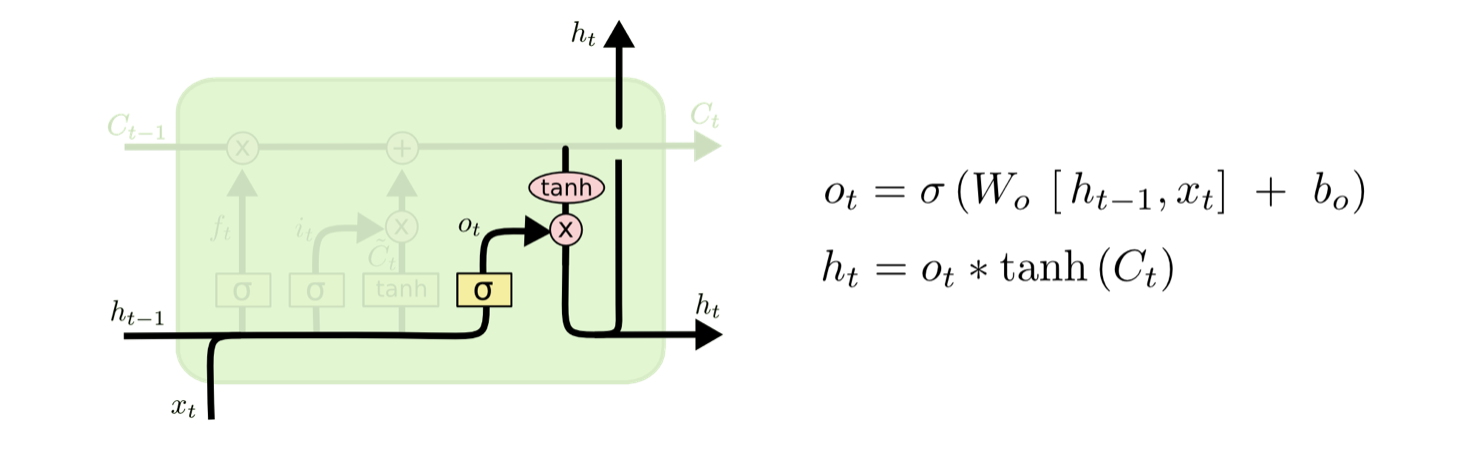
将$h_{t-1}$和$x_t$经过输出门的sigmoid激活函数得到判断条件(即哪些细胞信息需要输出),然后将细胞状态信息$C_t$经过tanh层得到范围为[-1,1]的向量,然后与输出门得到的判断条件进行相乘得到该RNN模块(time_step=t)的输出。
- 前一个隐藏状态和当前输入进入sigmoid函数;
- 更新的细胞状态进入tanh函数;
- tanh输出与sigmoid输出相乘,得到新的隐藏状态
LSTM可以缓解RNN梯度消失或者梯度爆炸的问题
RNN梯度消失的问题:
造成梯度消失的最大原因就是需要计算递归导数。RNN反向传播过程中,需要计算U,V,W等参数的梯度,以W的梯度表达式为例,会包含tanh的导数以及W的连乘,随着梯度的传导,如果W的主特征值小于1,梯度便会消失,如果W的特征值大于1,梯度便会爆炸。
RNN 中的梯度消失/梯度爆炸和普通的 MLP 或者深层 CNN 中梯度消失/梯度爆炸的含义不一样。MLP/CNN 中不同的层有不同的参数,各是各的梯度;而 RNN 中同样的权重在各个时间步共享,最终的梯度 g = 各个时间步的梯度 g_t 的和。RNN 中总的梯度是不会消失的。即便梯度越传越弱,那也只是远距离的梯度消失,由于近距离的梯度不会消失,所有梯度之和便不会消失。RNN 所谓梯度消失的真正含义是,梯度被近距离梯度主导,导致模型难以学到远距离的依赖关系。
在LSTM迭代过程中,每一步可细胞状态对上一时刻细胞状态的偏导以自主的选择在[0,1]之间,或者大于1,因为遗忘门的输出f(x)是可训练学习的。整体偏导的连乘就不会一直减小。远距离梯度不至于完全消失,也就能够解决RNN中存在的梯度消失问题。LSTM虽然能够解决梯度消失问题,但并不能够避免梯度爆炸问题,仍有可能发生梯度爆炸。但是,由于LSTM众多门控结构,和普通RNN相比,LSTM发生梯度爆炸的频率要低很多。梯度爆炸可通过梯度裁剪解决。
LSTM遗忘门值可以选择在[0,1]之间,让LSTM来改善梯度消失的情况。也可以选择接近1,让遗忘门饱和,此时远距离信息梯度不消失。也可以选择接近0,此时模型是故意阻断梯度流,遗忘之前信息。
【不至于像RNN对于所有时刻的求导值要么在区间[0,1],要么都在区间[1,正无穷]】
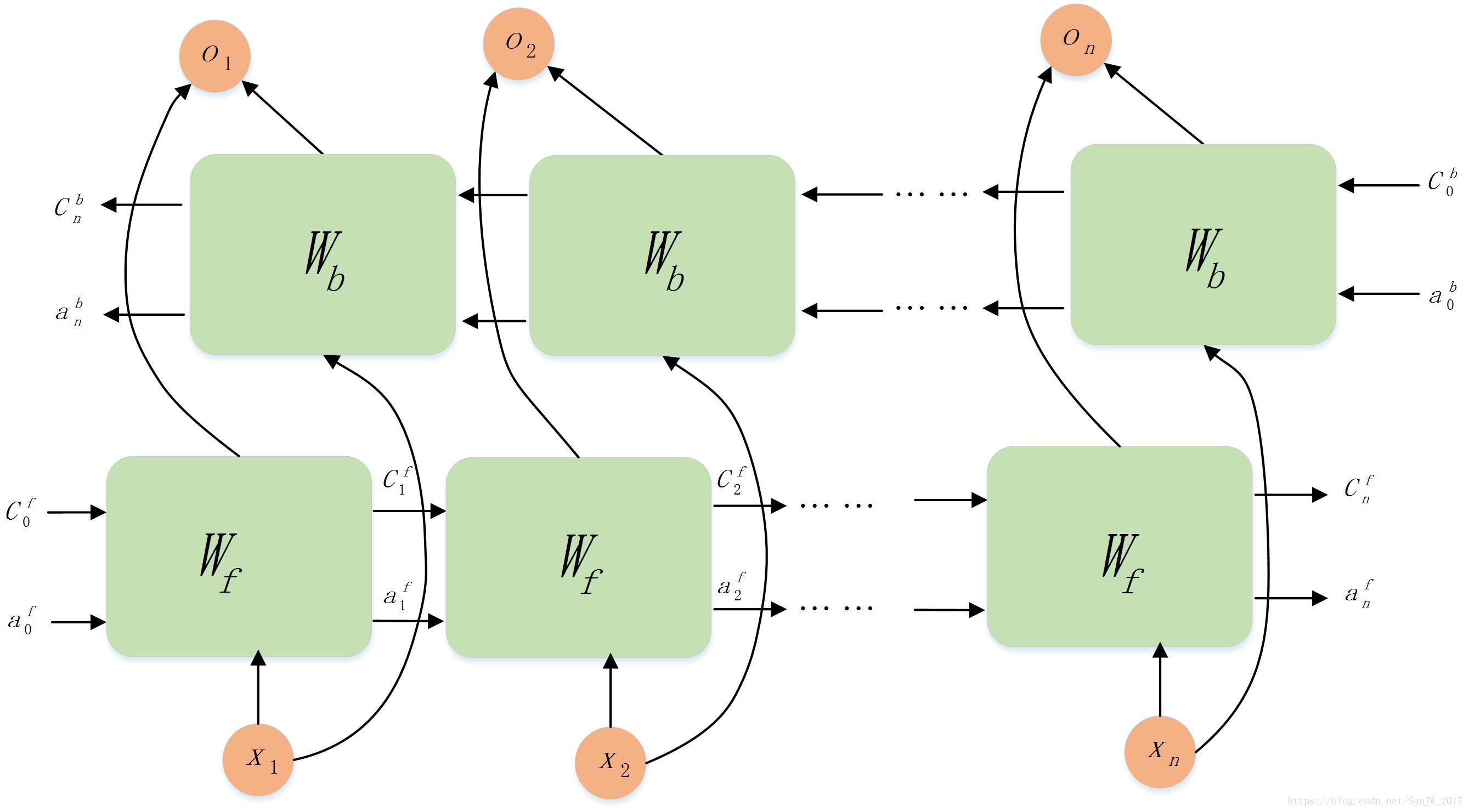
双向LSTM
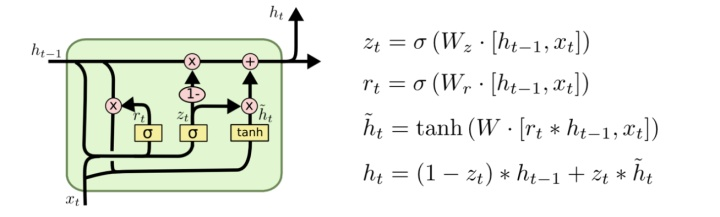
GRU
1. 忘记门和输入门合成更新门
2. 混合细胞状态和隐藏状态
GRU的优点是其模型的简单性 ,因此更适用于构建较大的网络。它只有两个门控,从计算角度看,它的效率更高,它的可扩展性有利于构筑较大的模型;但是LSTM更加的强大和灵活,因为它具有三个门控。LSTM是经过历史检验的方法。
因此,如果你要选取一个,我认为大多数人会把LSTM作为默认第一个去尝试的方法。
同时GRU,因为其简单而且效果可以(和LSTM)比拟,可以更容易的将其扩展到更大的问题。
http://colah.github.io/posts/2015-08-Understanding-LSTMs/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号