

SciKit learn的简称是SKlearn,是一个python库,专门用于机器学习的模块。官方网站:http://scikit-learn.org/stable/#
SKlearn包含的机器学习方式:分类,回归,无监督,数据降维,数据预处理等等,包含了常见的大部分机器学习方法。官网有一张图给了如何根据数据来选择转换器。(图源:https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html)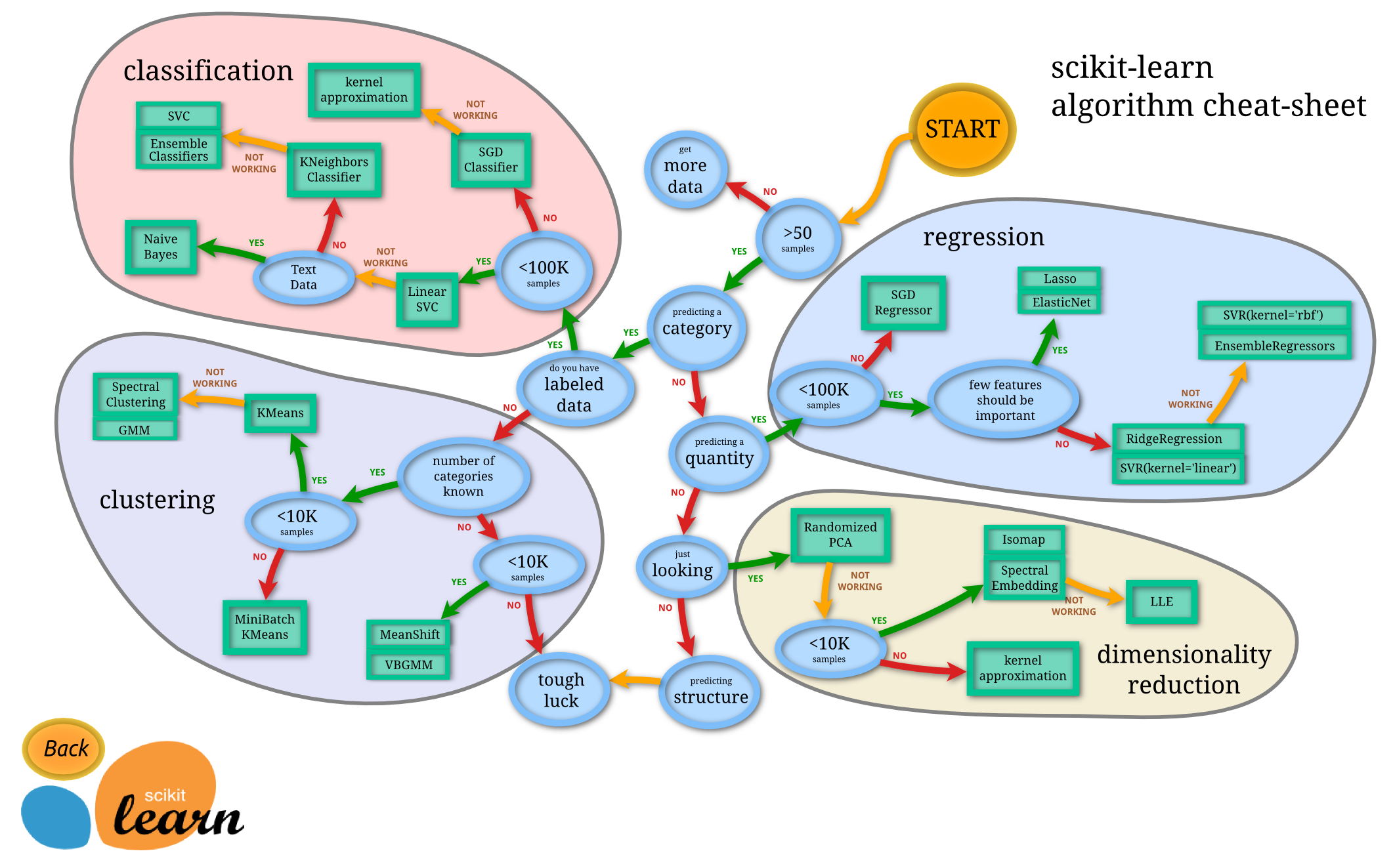
sklearn-datasets
sklearn库的datasets模块集成了部分数据分析的经典数据集,常用数据集的加载函数和解释如下:
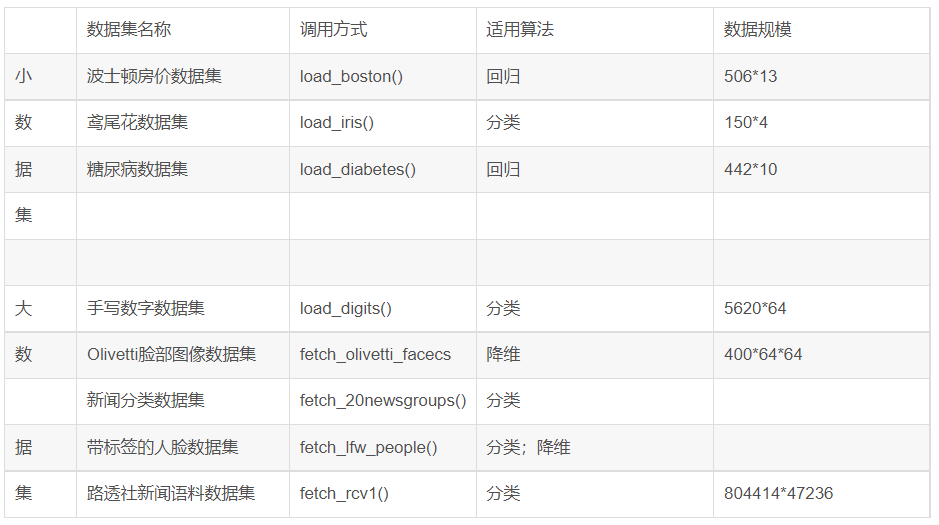
1 from sklearn.datasets import load_breast_cancer 2 # 波士顿房价-load_boston();糖尿病-load_diabetes();乳腺癌-load_breast_cancer() 3 # 手写数字-load_digits();新闻分类-fetch_20newsgroups() 4 cancer = load_breast_cancer()# 字典 5 # data-数据;target-标签;feature_names-特征名称;DESCR-描述信息 6 print("breast_cancer数据集长度:", len(cancer)) 7 print("breast_cancer数据集类型:", type(cancer)) 8 9 cancer_data = cancer.data 10 print("Breast_cancer数据集数据:", cancer_data) 11 print("Breast_cancer数据集数据长度:",len(cancer_data)) 12 cancer_target = cancer.target 13 print("Breast_cancer数据集标签:", cancer_target) 14 cancer_names = cancer.feature_names 15 print("Breast_cancer数据集特征名称:", cancer_names) 16 cancer_desc = cancer.DESCR 17 print("Breast_cancer数据集的描述信息:", cancer_desc)
数据集划分:train_test_split(*array,**options):函数返回划分好的训练集和测试集数据。0.16版的新功能:如果输入是稀疏的,则输出将是scipy.sparse.csr_矩阵。否则,输出类型与输入类型相同。

cancer_data_train, cancer_data_test,cancer_target_train, cancer_target_test = train_test_split(cancer_data, cancer_target, test_size=0.2, random_state=111) print("训练集大小:", cancer_data_train.shape, cancer_target_train.shape) print("测试集大小:", cancer_data_test.shape, cancer_target_test.shape)
数据预处理与降维
转换器:帮助用户方便实现大量的特征处理相关操作,sklearn把相关的功能封装成转换器。目前,使用sklearn的转换器能够实现对传入的Numpy数组进行标准化处理、归一化处理、二值化处理和PCA降维等处理。
转换器主要包含3种方法:
- fit():训练算法,设置内部参数。
- transform():数据转换。将规则应用于训练集或者测试集
- fit_transform():合并fit和transform两个方法
在数据预处理中
fit(): Method calculates the parameters μ and σ and saves them as internal objects. 解释:简单来说,就是求得训练集X的均值,方差,最大值,最小值,这些训练集X固有的属性。 transform(): Method using these calculated parameters apply the transformation to a particular dataset. 解释:在fit的基础上,进行标准化,降维,归一化等操作(看具体用的是哪个工具,如PCA,StandardScaler等)。 fit_transform(): joins the fit() and transform() method for transformation of dataset. 解释:fit_transform是fit和transform的组合,既包括了训练又包含了转换。 transform()和fit_transform()二者的功能都是对数据进行某种统一处理(比如标准化~N(0,1),将数据缩放(映射)到某个固定区间,归一化,正则化等) fit_transform(trainData)对部分数据先拟合fit,找到该part的整体指标,如均值、方差、最大值最小值等等(根据具体转换的目的),然后对该trainData进行转换transform,从而实现数据的标准化、归一化等等。 根据对之前部分trainData进行fit的整体指标,对剩余的数据(testData)使用同样的均值、方差、最大最小值等指标进行转换transform(testData),从而保证train、test处理方式相同。
在算法模型中
以CountVectorizer为例(根据输入数据获取词频矩阵)
- fit(raw_documents) :根据CountVectorizer参数规则进行操作,比如滤除停用词等,拟合原始数据,生成文档中有价值的词汇表;\
源码中的desc
def fit(self, raw_documents, y=None): """Learn a vocabulary dictionary of all tokens in the raw documents."""
- fit_transform(raw_documents, y=None):学习词汇词典并返回术语 - 文档矩阵(稀疏矩阵)。
源码中的desc
def fit_transform(self, raw_documents, y=None): """Learn the vocabulary dictionary and return term-document matrix. This is equivalent to fit followed by transform, but more efficiently implemented."""
- transform(raw_documents):使用符合fit的词汇表或提供给构造函数的词汇表,从原始文本文档中提取词频,转换成词频矩阵
源码中的desc
def transform(self, raw_documents): """Transform documents to document-term matrix. Extract token counts out of raw text documents using the vocabulary fitted with fit or the one provided to the constructor."""
以TfidfTransformer举例
- fit(raw_documents, y=None):根据训练集生成词典和逆文档词频 由fit方法计算的每个特征的权重存储在model的idf_属性中。
- transform(raw_documents, copy=True):使用fit(或fit_transform)学习的词汇和文档频率(df),将文档转换为文档-词矩阵。返回稀疏矩阵,[n_samples, n_features],即,Tf-idf加权文档矩阵(Tf-idf-weighted document-term matrix)
- fit_transform(raw_documents[, y]):根据训练集生成词典和逆文档词频,返回Tf-idf加权文档矩阵。比fit+transform更高效。
总结:算法中的fit方法的应用等价于第一类的fit,只不过产生的结果意义不同(不是均值等统计意义,而是根据算法本身拟合获取不同信息以备后用),transform根据fit的结果转换成目标形式
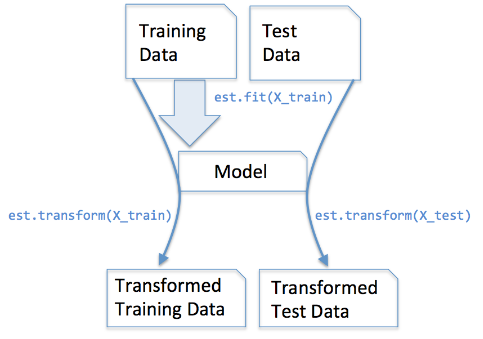
预处理函数(主要在sklearn.preprcessing包下)
规范化:
MinMaxScaler :最大最小值规范化
import pandas as pd from sklearn.preprocessing import MinMaxScaler data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]] data = pd.DataFrame(data) #实现归一化 scaler = MinMaxScaler() #实例化 scaler = scaler.fit(data) #fit,在这里本质是生成min(x)和max(x) result = scaler.transform(data) #通过接口导出结果 result #训练和导出结果一步达成 result_ = scaler.fit_transform(data) #将归一化后的结果逆转 # scaler.inverse_transform(result) #使用MinMaxScaler的参数feature_range实现将数据归一化到[0,1]以外的范围中 data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]] scaler = MinMaxScaler(feature_range=[5,10]) #依然实例化 result = scaler.fit_transform(data) #fit_transform一步导出结果 result
Normalizer :使每条数据各特征值的和为1
sklearn.preprocessing.Normalizer(norm=’l2’, copy=True)
norm:可以为l1、l2或max,默认为l2
若为l1时,样本各个特征值除以各个特征值的绝对值之和
若为l2时,样本各个特征值除以各个特征值的平方之和
若为max时,样本各个特征值除以样本中特征值最大的值
from sklearn import preprocessing X = [[ 1., -1., 2.], [ 2., 0., 0.],[ 0., 1., -1.]] normalizer = preprocessing.Normalizer().fit(X)#fit does nothing normalizer normalizer.transform(X)
output:
Normalizer(copy=True, norm='l2') array([[ 0.40824829, -0.40824829, 0.81649658], [ 1. , 0. , 0. ], [ 0. , 0.70710678, -0.70710678]])
StandardScaler :为使各特征的均值为0,方差为1
from sklearn.preprocessing import StandardScaler # 标准化工具 import numpy as np x_np = np.array([[1.5, -1., 2.], [2., 0., 0.]]) scaler = StandardScaler() x_train = scaler.fit_transform(x_np) print('矩阵初值为:\n{}'.format(x_np)) print('该矩阵的均值为:\n{}\n 该矩阵的标准差为:{}'.format(scaler.mean_,np.sqrt(scaler.var_))) print('标准差标准化的矩阵为:\n{}'.format(x_train))
output:
矩阵初值为: [[ 1.5 -1. 2. ] [ 2. 0. 0. ]] 该矩阵的均值为: [ 1.75 -0.5 1. ] 该矩阵的标准差为:[ 0.25 0.5 1. ] 标准差标准化的矩阵为: [[-1. -1. 1.] [ 1. 1. -1.]]
编码:(数据预处理函数)
LabelEncoder :把字符串类型的数据转化为整型
import numpy as np import pandas as pd from sklearn import preprocessing sex = pd.Series(["male", "female", "female", "male"]) le = preprocessing.LabelEncoder() #获取一个LabelEncoder le = le.fit(["male", "female"]) #训练LabelEncoder, 把male编码为0,female编码为1 sex = le.transform(sex) #使用训练好的LabelEncoder对原数据进行编码 print(sex) le.inverse_transform([1,0,0,1])
[1 0 0 1] array(['male', 'female', 'female', 'male'], dtype='<U6')
OneHotEncoder :特征用一个二进制数字来表示
from sklearn.preprocessing import OneHotEncoder ohe = OneHotEncoder() ohe.fit([[1],[2],[3],[4]]) ohe.transform([[2],[3],[1],[4]]).toarray()
output:
array([[ 0., 1., 0., 0.], [ 0., 0., 1., 0.], [ 1., 0., 0., 0.], [ 0., 0., 0., 1.]])
LabelEncoder 和 OneHotEncoder 的区别
LabelEncoder 将一列文本数据转化成数值;OneHotEncoder 将一列文本数据转化成一列或多列只有0和1的数据
Binarizer :对定量特征进行二值化处理,根据阈值将数值型转变为二进制型,阈值可以进行设定
from sklearn.preprocessing import Binarizer df = pd.DataFrame(np.arange(12).reshape(4,3),columns=['A','B','C']) binarize = Binarizer(threshold=5) binarize.fit_transform(df)
output:
A B C 0 0 1 2 1 3 4 5 2 6 7 8 3 9 10 11 array([[0, 0, 0], [0, 0, 0], [1, 1, 1], [1, 1, 1]])
MultiLabelBinarizer:多标签二值化
from sklearn.preprocessing import MultiLabelBinarizer mlb = MultiLabelBinarizer(classes = [2,3,4,5,6,1]) # 注意这里加了classes参数 mlb.fit_transform([(1, 2), (3,4),(5,)])
output:
array([[1, 0, 0, 0, 0, 1], [0, 1, 1, 0, 0, 0], [0, 0, 0, 1, 0, 0]])
FunctionTransformer:对特征进行自定义函数变换
import numpy as np from sklearn.preprocessing import FunctionTransformer transformer = FunctionTransformer(np.log1p) X = np.array([[0, 1], [2, 3]]) transformer.transform(X)
output:
array([[ 0. , 0.69314718],
[ 1.09861229, 1.38629436]])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号