软工结对作业—最长单词链
[2019BUAA软件工程]结对作业——最长单词链
1、github链接:
https://github.com/KarCute/Wordlist
2、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 30 |
| Development | 开发 | 2565 | 2320 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 100 |
| · Design Spec | · 生成设计文档 | 50 | 30 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 30 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 15 | 30 |
| · Design | · 具体设计 | 90 | 120 |
| · Coding | · 具体编码 | 2000 | 1680 |
| · Code Review | · 代码复审 | 60 | 40 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 200 | 300 |
| Reporting | 报告 | 370 | 510 |
| · Test Report | · 测试报告 | 120 | 200 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 240 | 300 |
| 合计 | 2945 | 2860 |
3、看教科书和其它资料中关于Information Hiding, Interface Design, Loose Coupling的章节,说明你们在结对编程中是如何利用这些方法对接口进行设计的。
Information Hiding (信息隐藏)
In computer science, information hiding is the principle of segregation of the design decisions in a computer program that are most likely to change, thus protecting other parts of the program from extensive modification if the design decision is changed. The protection involves providing a stable interface which protects the remainder of the program from the implementation (the details that are most likely to change).
维基百科——Information Hiding
在这里信息隐藏并不是指信息加密或者隐匿,而是一种设计思想,将程序中设计决策中最容易改变的部分分离开来,从而保护其他部分不受影响。在这里我们的设计自始至终都将计算接口剥离开单独处理,因为这部分本身较难实现,并且在优化代码算法时也是只需要对这部分进行改进。
Interface Design (接口设计)
Interface除了接口外还有界面的意思,一般说来User Interface Design指的是UI设计。这里应该指的接口设计。
我们在设计时是按照指定的接口完成了计算模块的设计,同时注意到,虽然我们在整个项目实现时,满足了传入接口的参数都保证正确,但是对用户来说,这个接口内部是未知的,他们不一定会按照规范传入参数,因此需要考虑到设计的完备性,即异常处理。
Loose Coupling(松散耦合)
In computing and systems design a loosely coupled system is one in which each of its components has, or makes use of, little or no knowledge of the definitions of other separate components.
耦合是软件结构中各模块之间相互连接的一种度量,耦合强弱取决于模块间接口的复杂程度、进入或访问一个模块的点以及通过接口的数据。
百度百科——高内聚低耦合
早在接触面向对象时就已经知道了好的程序应该做到“高内聚,低耦合”。在我们的编程中,模块的接口设计大多传入参数并不复杂,耦合程度较低。如读取文件部分,我们只接受一个文件名,然后就能将单词存入一个vector容器中。其余模块只需要接受这个容器,而不需要与该模块有较多的交互。
4、计算模块接口的设计与实现过程。
4.1 问题分析
以前做过类似的题,输入的所有单词能否全部首尾相连形成链。由于单词首尾相连有多种连接方式,故基本的数据结构为图。
建图有两种方式,一种是以单词为节点,如果单词间正好可以首尾连接,则添加一条边,该边即为连接的字母。另一种建图方式是以字母为节点,以单词为边,出现一个单词,即把首字母节点向尾字母节点添加一条边,边的值即为该单词。
对于这道题目而言,由于单词需要输出,加之对第二种建图方式掌握并不熟练,因此选择的是第一种建图方式。
模型确立后,问题就可以简化成“求图中的最长链”,即最长路径问题,显然问题是多源最长路径问题。
4.2数据结构与算法
数据结构为图,存储方式为邻接矩阵,理由是能更契合floyd算法。
对于无环情况,由于为多源最长路径问题,联想到最短路径问题,可以确定为floyd算法。
而对于有环情况,由于出现了正值环,floyd算法不再适用。在找不到更有解决方法的情况下,只能适用DFS深度优先搜索求解。
4.3模块组织
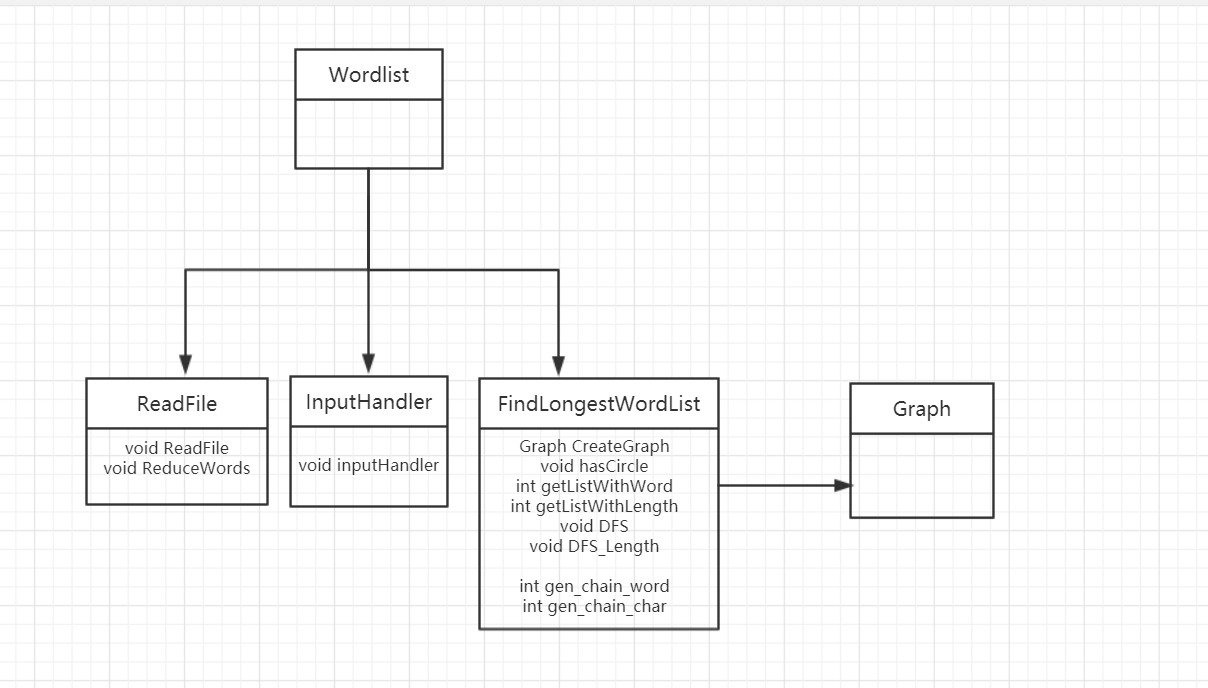
ReadFile: 读取文件的模块,将文件中的单词提取进入容器vector中。
Graph: 图的定义。
InputHandler:处理输入的模块,读取命令行并处理参数。
FindLongestWordList: 计算模块,内含计算接口。计算出单词中的最长链。
4.4算法关键
首先需要判断有无环,对于没有-r参数的输入来说,如果有环需要报错。这里也是用到DFS的染色算法。每个点有三种状态:未遍历过,遍历过,当前序列正在遍历。如果一次DFS中一个点与正在遍历中的点相连了,说明DFS回到了之前的点,即图中有环。
另一问题是由于无环情况最多可有10000个单词,而floyd算法时间复杂度为O(\(n^3\)),暴力的计算显然是不行的。考虑到对于无环的情况,有如下特性:对于单词element和elephant,由于无环,这两个单词最多只有一个会出现在链中。(否则会出现element, t..., ..., ....e, elephant / element,这样一定是有环的),而如果要满足字母最多,显然这时候需要选择elephant加入链中。因此我们可以对于所有首尾字母相同的单词,保留首尾字母组合中,最长的一个单词。这样的操作之后,最多的单词数目为351,即使是时间复杂度O(\(n^3\))的算法也能很快得出结果。另外可以计算得,最长链的长度最大为51。
5、UML图
6、计算模块接口部分的性能改进。
首先是无环情况,其性能最大阻碍是10000个单词大样本情况下,floyd算法时间复杂度过高导致的。但是在4.4有介绍过,我们可以通过无环单词链的特性来削减样本数量,削减后单词数量少,即使时间复杂度高也能很快跑出结果。因此性能方面上没有太大问题。
其次是有环情况,由于DFS算法仍属于暴力递归搜索,并不算很好的算法,其性能也着实较差。但是我们也想不到更好的解决算法,所以并没有改进。


7、Design by Contract, Code Contract
契约式设计:定义正式、精确和可验证的接口规范。
- 优点:
- 按照契约设计,可以简单清楚的了解一个接口,并且能够使错误率降低。
- 按照前置条件始终为真来编写代码,可以省去很多测试检查。
- 缺点:契约设计的规格非常复杂,必须花很长时间编写规格。
- 契约设计并不能取代常规的单元测试,仅仅只是对外部测试的补充。
- 出现违背契约的人时,会对工程造成严重打击。
在我们的结对编程过程中,并没有过多使用契约式设计。因为作为结对编程,大多数时候我们在编写代码时,都是两个人同时沟通和编写。每写完一个接口,我们都对接口有了大致的认识,因此不太需要启悦设计。
8、计算模块部分单元测试展示。
在单元测试部分我们对程序中除输出部分外(由于输出部分只是一个简单的输出到文件)其他所以部分或函数进行的全面的单元测试,如图共25个。
TEST_METHOD(TestMethod3)
{
// TODO: normal_test3
char* words[101] = { "element", "heaven", "table", "teach", "talk"};
char* answer[101];
for (int i = 0; i < 101; i++)
{
answer[i] = (char*)malloc(sizeof(char) * 601);
}
int l = gen_chain_word(words, 5, answer, 0, 0, true);
Assert::AreEqual(l, 4);
Assert::AreEqual("table", answer[0]);
Assert::AreEqual("element", answer[1]);
Assert::AreEqual("teach", answer[2]);
Assert::AreEqual("heaven", answer[3]);
for (int i = 0; i < 101; i++)
{
free(answer[i]);
}
}
- 上面的单元测试代码是测试计算核心中的gen_chain_word接口函数,由于单元测试需要我手动加入words,所以这里的单元测试数据比较小,就是构造一个有环有链的单词文本,并且是在输入‘-r’的情况下,从而得到一个正确的单词链。
TEST_METHOD(TestMethod6)
{
// TODO: normal_test6
char* words[101] = { "apple", "banane", "cane", "a", "papa", "erase" };
char* answer[101];
for (int i = 0; i < 101; i++)
{
answer[i] = (char*)malloc(sizeof(char) * 601);
}
int l = gen_chain_char(words, 6, answer, 'a', 'e', false);
Assert::AreEqual(l, 3);
Assert::AreEqual("a", answer[0]);
Assert::AreEqual("apple", answer[1]);
Assert::AreEqual("erase", answer[2]);
for (int i = 0; i < 101; i++)
{
free(answer[i]);
}
}
- 上面的单元测试代码是测试计算核心中的gen_chain_char接口函数,这里构造了一个没有环的文本数据,而且其最多单词链和最长单词链不同,并固定了首尾字母。
TEST_METHOD(TestMethod2)
{
// 正确_2
int argc = 6;
char* argv[101] = { "Wordlist.exe", "-r", "-h", "a", "-c", "test_1.txt" };
char head;
char tail;
bool enable_loop;
int word_or_char = 0;
string Filename;
InputHandler(argc, argv, enable_loop, word_or_char, head, tail, Filename);
Assert::AreEqual(enable_loop, true);
Assert::AreEqual(word_or_char, 2);
Assert::AreEqual(head, 'a');
Assert::AreEqual(tail, char(0));
Assert::AreEqual(Filename, (string)"test_1.txt");
}
- 上面的单元测试代码是测试接收命令行输入函数InputHandler,这里没有什么太多好说的, 就是把命令行输入参数的所有正确组合全部测试一遍即可(参数输入顺序可以改变)。
总体测试思路为控制变量,即控制是否有首字母、尾字母约束,是否带环,是最多单词还是最多字符。
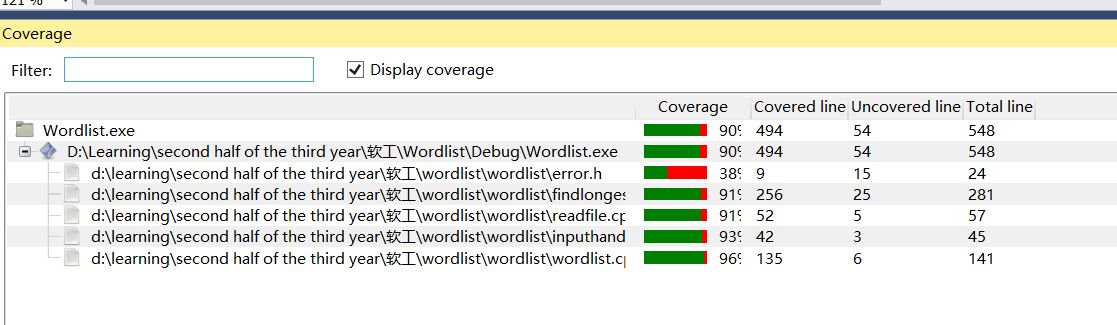
单元测试覆盖率截图(由于C++没有找到直接测试单元测试覆盖率的插件,这里用的方法是将单元测试代码移至main函数中用OpenCppCoverage插件得到的覆盖率,部分异常测试没有放进来,所以覆盖率没有达到100%)
9、计算模块部分异常处理说明。
- 在异常处理模块我们一共自定义了8种类型的异常,接下来我将会结合每种异常的单元测试说明每种异常的设计目标以及错误对应的场景(单元测试的构造方法就是保证此函数可以捕捉到异常且捕捉的是与当前错误相对应的异常,否则单元测试不通过)。
1. 错误的参数组合(其中包括出现多个相同命令比如‘-r’、‘-r’,‘-h’和‘-c’同时出现,‘-h’和‘-c’都没有,即不指定求何种单词链)
TEST_METHOD(TestMethod3)
{
// 错误_1
int argc = 5;
char* argv[101] = { "Wordlist.exe", "-r", "-r", "-c", "test_1.txt" };
char head;
char tail;
bool enable_loop;
int word_or_char = 0;
string Filename;
try {
InputHandler(argc, argv, enable_loop, word_or_char, head, tail, Filename);
Assert::IsTrue(false);
}
catch (myexception1& e) {
Assert::IsTrue(true);
}
catch (...) {
Assert::IsTrue(false);
}
}
这个单元测试是‘-r’出现了两次,错误的参数组合。
2. 指定单词链首尾不合法(比如‘-h’、‘1’或者‘-t’、‘ag’)
TEST_METHOD(TestMethod7)
{
// 错误_5
int argc = 6;
char* argv[101] = { "Wordlist.exe", "-r", "-h", "1", "-c", "test_1.txt" };
char head;
char tail;
bool enable_loop;
int word_or_char = 0;
string Filename;
try {
InputHandler(argc, argv, enable_loop, word_or_char, head, tail, Filename);
Assert::IsTrue(false);
}
catch (myexception2& e) {
Assert::IsTrue(true);
}
catch (...) {
Assert::IsTrue(false);
}
}
这个单元测试是‘-h’指定首字母为‘1’,明显是错误的。
3. 输入的参数不是指定的那几个参数,不符合规定(如输入‘-b’)
TEST_METHOD(TestMethod9)
{
// 错误_7
int argc = 5;
char* argv[101] = { "Wordlist.exe", "-b", "-r", "-c", "test_1.txt" };
char head;
char tail;
bool enable_loop;
int word_or_char = 0;
string Filename;
try {
InputHandler(argc, argv, enable_loop, word_or_char, head, tail, Filename);
Assert::IsTrue(false);
}
catch (myexception3& e) {
Assert::IsTrue(true);
}
catch (...) {
Assert::IsTrue(false);
}
}
这个单元测试是输入参数‘-b’显然是不符合规定的。
4. 文件不存在的情况
TEST_METHOD(TestMethod2)
{
// 错误
vector <string> words;
try {
ReadFile("normal_test3.txt", words); // 不存在的文件
Assert::IsTrue(false);
}
catch (myexception4& e) {
Assert::IsTrue(true);
}
catch (...) {
Assert::IsTrue(false);
}
}
这个单元测试是测试了一个在此路径下不存在的文件。
5. 读取的文件中有单词长度超过600
TEST_METHOD(TestMethod2)
{
// 错误
vector <string> words;
try {
ReadFile("long_word_test.txt", words);
Assert::IsTrue(false);
}
catch (myexception4& e) {
Assert::IsTrue(true);
}
catch (...) {
Assert::IsTrue(false);
}
}
这个单元测试是文件中存在长度超过600的单词。
6. 读取的文件中无环的超过10000个单词,有环的超过100个单词
TEST_METHOD(TestMethod2)
{
// 错误
vector <string> words;
try {
ReadFile("more_words_test.txt", words);
Assert::IsTrue(false);
}
catch (myexception4& e) {
Assert::IsTrue(true);
}
catch (...) {
Assert::IsTrue(false);
}
}
这个单元测试是所测试文件中单词数超过了10000。
7. 读取文件中有单词环且参数没有输入‘-r’
TEST_METHOD(TestMethod10)
{
// wrong_test2
char* words[101] = { "alement", "oeaven", "tabla", "teaco", "talk" };
char* answer[101];
for (int i = 0; i < 101; i++)
{
answer[i] = (char*)malloc(sizeof(char) * 601);
}
try {
int l = gen_chain_char(words, 5, answer, 0, 'n', false);
Assert::IsTrue(false);
}
catch (myexception7& e) {
Assert::IsTrue(true);
}
catch (...) {
Assert::IsTrue(false);
}
}
这个单元测试是传入单词可以形成环,且用户没有传入参数‘-r’。
8. 读取文件中无法形成最少两个单词的单词链
TEST_METHOD(TestMethod11)
{
// wrong_test3
char* words[101] = { "alement", "oeaven", "tabla", "teaco", "talk" };
char* answer[101];
for (int i = 0; i < 101; i++)
{
answer[i] = (char*)malloc(sizeof(char) * 601);
}
try {
int l = gen_chain_word(words, 5, answer, 'b', 'n', true);
Assert::IsTrue(false);
}
catch (myexception8& e) {
Assert::IsTrue(true);
}
catch (...) {
Assert::IsTrue(false);
}
}
这个单元测试是规定了首尾字母后,单词链中没有用户所要求的单词链。
10、界面模块的详细设计过程(GUI)
- 在界面模块这方面我们没有实现GUI,而是完成了最基本的命令行模块。命令行参数(个数、参数内容)首先传入main函数中,然后再传给InputHandler函数中对传入的参数进行分析处理,主要是识别错误的参数输入(第9部分已经详细介绍)以及将正确的参数组合中的信息存下来,比如说head和tail是否有限定,单词文本是否允许有环以及要求的单词链是要单词最多还是单词总长度最长。
11、界面模块与计算模块的对接(GUI)
- 命令行模块与两个计算核心模块的对接其实也很简单。我们从命令行读入的各类参数如果是正确无误的,那么我们可以相对应地确定传入两个计算模块的head、tail、enable_loop以及执行哪个计算模块的判断变量。即确定规范的单词链首字母尾字母,如果没有规定则传入0,是否允许有环的变量。如果不允许,则需要判断传入单词文本是否可以形成环,如果形成环则报告异常。下面是简单是一张命令行输入截图:

12、描述结对的过程
由于与队友为舍友,结对时相对简单很多,只需要到对铺和队友一起结对编程就行了。我们的水平差不多, 编程能力和数据结构算法的掌握都不算太好。初期时我们主要是一起讨论算法,如何实现基本的功能,数据结构应该用什么。敲定一个算法之后就开始分头找资料,最后再汇总资料,交给他来敲代码或者我来在一些地方进行修改。编写时经常会遇到一些意料不到的bug,最后必须一起搜索如何解决。但是两个人在一起编写代码时,有一个人来随时审视代码,有不懂的地方或者不对劲的地方另一人都可以随时提出来。因此虽然结对编程效率没有提高, 但是效果会比两个单人编写来的更好。
总的来说这次题目难度还是没有那么爆炸,所以我们之间的合作也比较愉快。至于提意见的艺术是根本用不上的,毕竟是舍友也不会产生矛盾。下面是我们在初期时讨论算法的图片:

13、结对编程的优点和缺点在哪里
- 优点:
- 结对编程时,有实时的复审过程,这样可以使得编码时一些意想不到的bug出现的更少。而单人编程(如OO)时,往往出现较多bug,疲于修改。
- 结对编程能够使得编程时思想更加集中,不会出现开小差的情况。
- 结对编程时,设计时经过了两个人的思考,不太会出现设计出问题的情况。
- 缺点:
- 时间必须协调好,有时在对方有事的情况下,必须得等待对方。
- 在两人水平相差不大时,可能会出现两人都放过bug的情况。
结对的每一个人的优点和缺点在哪里 (要列出至少三个优点和一个缺点)
自己的话,优点是设计时肯思考,能接受对方的意见,愿意花时间寻找资料。缺点可能是有点爱开小差。
对对方的话,优点是能主动找资料,能包容我的不足,在我有事时能主动在差不多的测试上花时间编写。缺点可能是和我一样数据结构和算法掌握不够好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号