面向对象设计与构造第三单元总结
1.JML语言的理论基础及应用工具链
在谈JML的理论之前,我觉得有必要提一下JML的起源(研讨课分享了一下,这里再重述一遍)
上世纪50年代,就已经有早期的编程语言出现
然而那个时代,软件开发基本局限于自己或自己部门内部的使用,需求并没有很多,也并不复杂(或者说人们并没有意识到有那么多事情可以通过软件解决)。所以基本都是靠早期的程序猿们的自由开发,也并没有现代代码规范的概念。
等到了60到70年代,随着硬件技术和工业界思想的进步,软件层面上的需求越来越多
出现了一次软件危机:一方面需要大量的软件系统,如操作系统、数据库管理系统;另一方面,软件研制周期长,可靠性差,维护困难。人们希望编写出的程序结构清晰、易阅读、易修改、易验证,即得到良好结构的程序。
1968年,Dijkstra提出了“GOTO是有害的”,希望通过程序的静态结构的良好性保证程序的动态运行的正确性
1969年,Wirth提出采用“自顶向下逐步求精、分而治之”的原则进行大型程序的设计。其基本思想是:从欲求解的原问题出发,运用科学抽象的方法,把它分解成若干相对独立的小问题,依次细化,直至各个小问题获得解决为止。
在1970年代到1980年代,规格说明(Spec)和体(body)的分离。说明是类型定义和操作描述,体是操作的具体实现。解决方案设计只关注说明,实现时引用或者设计体。体的更改、置换不影响规格说明,保证了可移植性。此时产生了划时代的面向对象技术。
在此之后,抽象化设计,契约式设计也都发展了起来。而JML就是为这种编程思想服务的。
JML为说明性的描述行为引入了许多构造。包括
模型字段
public model ...
量词
\forall... \exist...
前置条件 后置条件
requires ... ensures ...
不变式(这三次作业中似乎没有用到)
invariant...
异常行为
signal... signal only...
等等。这些构造使得JML的功能非常强大,几乎能够满足所有的功能描述。这样我们就能跳过实现区描述功能。这也是面向对象设计时的一种原则。
JML的应用工具链:
1.OpenJML
OpenJML的功能大致有两个。一是检查JML语法的正确性。二是将JML和程序代码之间隐含的待证明的问题传递给后端的SMTsolver(OpenJML内置),让SMTsolver去证明正确性,这样就能检测我们JML是否和代码表达出的意思相符合。(以下操作均在命令行中进行)
具体而言,我们大致会用到三种检测模式:
1)检查JML语法正确性
java -jar $OJ/openjml.jar -check A.java
一个简单的例子(\result 表达式不能用在void 方法的规格描述中)

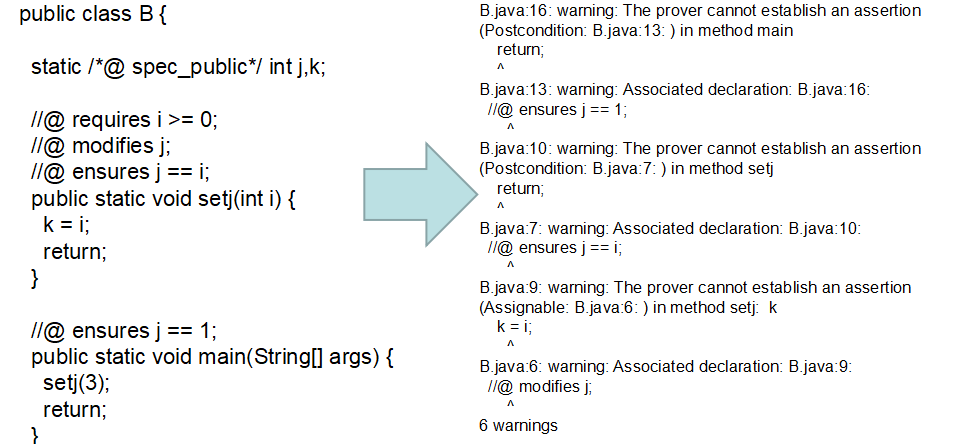
2)静态检查
java -jar $OJ/openjml.jar -esc B.java
再来一个简单的例子
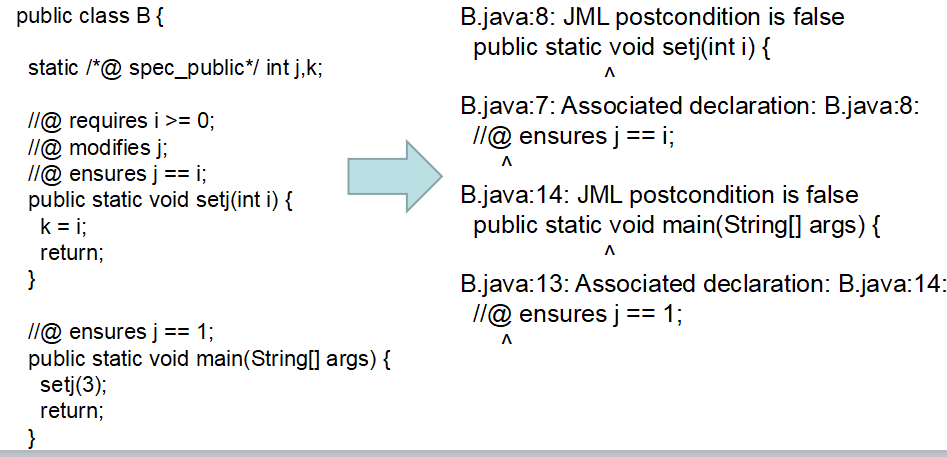
3)运行状态下检查
java -jar $OJ/openjml.jar -rac B.java
可以简单的理解为根据JML定的前置条件,后置条件等等条件。在程序中加入assert语句,然后在运行程序,一旦不满足某个assert就会报错。最后一个简单的例子
2.JMLunit
官网上对于JMLunit的定义是 :生成用于在带JML注释的Java文件上运行JUnit测试的文件。
命令行上用法如下:
jmlunit [option] ... file-or-directory-or-package [file-or-directory-or-package] ...
jmlunit-gui [option] ... file-or-directory-or-package [file-or-directory-or-package] ...
3.JMLc
官网上对于JMLc的定义是:使用运行时断言检查编译带有JML注释的Java文件。个人感觉OpenJML中的-rac选项和这个很类似。故不在赘述,只介绍以下命令行下的用法
jmlc [option] ... file-or-directory-or-package [file-or-directory-or-package] ...
jmlc-gui [option] ... file-or-directory-or-package [file-or-directory-or-package] ...
4.jmldoc
jmldoc和javadoc类似,不过jmldoc能够理解带JML注释的java文件,而javadoc做不到。
官网上对于jmldoc的解释为从JML和Java文件生成HTML页面。命令行下用法如下
jmldoc [option] ... file-or-package-or-directory [file-or-package-or-directory] ...
jmldoc-gui [option] ... file-or-package-or-directory [file-or-package-or-directory] ...
5.其他
从JML的官网中可以看到还有很多工具,例如jml-launcher,jml-gui,jmle,jmlre,jmlspec。具体每个的功能这里不再赘述,放个链接,大家有需要的可以自取。
http://www.eecs.ucf.edu/~leavens/JML/documentation.shtml
2.部署SMTsolver(Pass)
3.部署JMLunit
首先我写了一个简单的测试程序
public class Test {
/*
@ ensures \result == a-b;
*/
public static int sub(int a, int b) {
return a - b;
}
public static void main(String[] args) {
sub((int)Math.pow(2,32), (int)Math.pow(2,32));
}
}
然后根据评论区巨佬的指示操作,得到如下结果(按道理应该和评论区的一样,果不其然,应该是int型溢出问题)
Passed: static compare(-2147483648, -2147483648)
Failed: static compare(0, -2147483648)
Failed: static compare(2147483647, -2147483648)
Passed: static compare(-2147483648, 0)
Passed: static compare(0, 0)
Passed: static compare(2147483647, 0)
Failed: static compare(-2147483648, 2147483647)
Passed: static compare(0, 2147483647)
Passed: static compare(2147483647, 2147483647)
Passed: static main(null)
Passed: static main({})
4.三次作业的架构梳理,重构分析
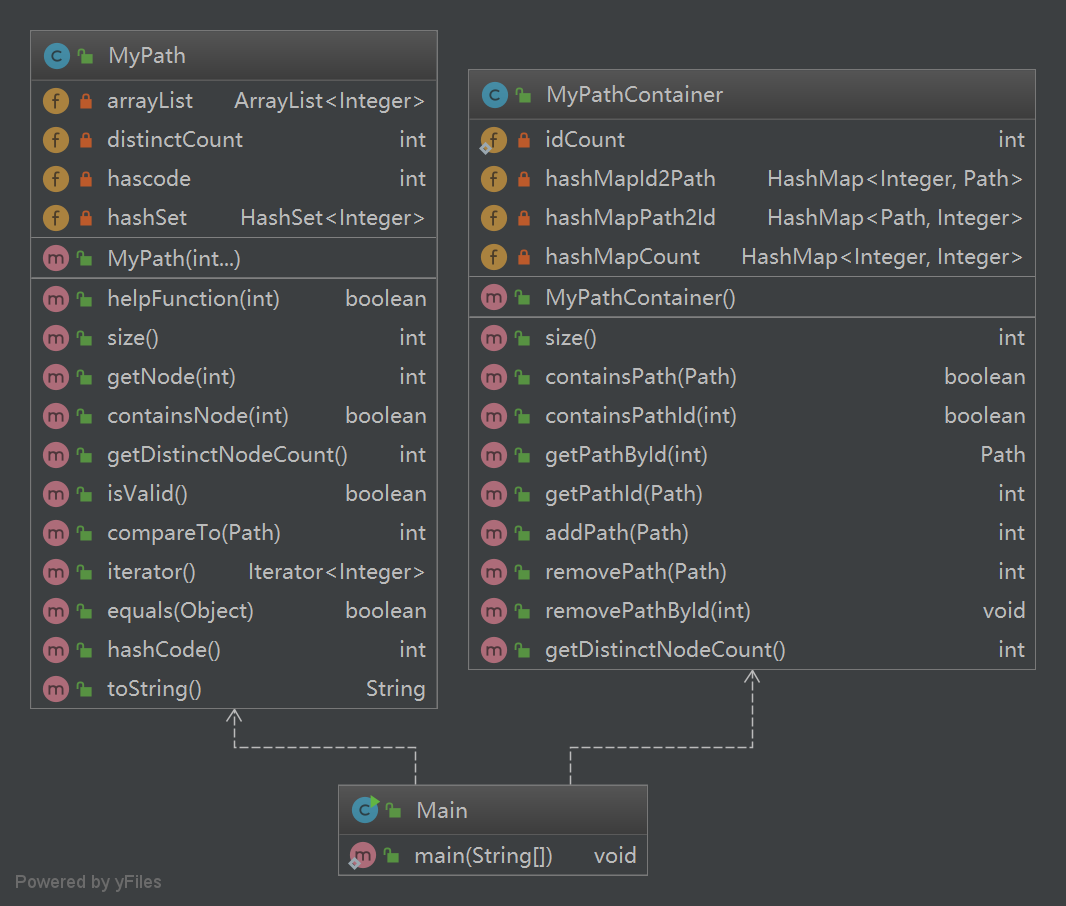
1.第一次作业
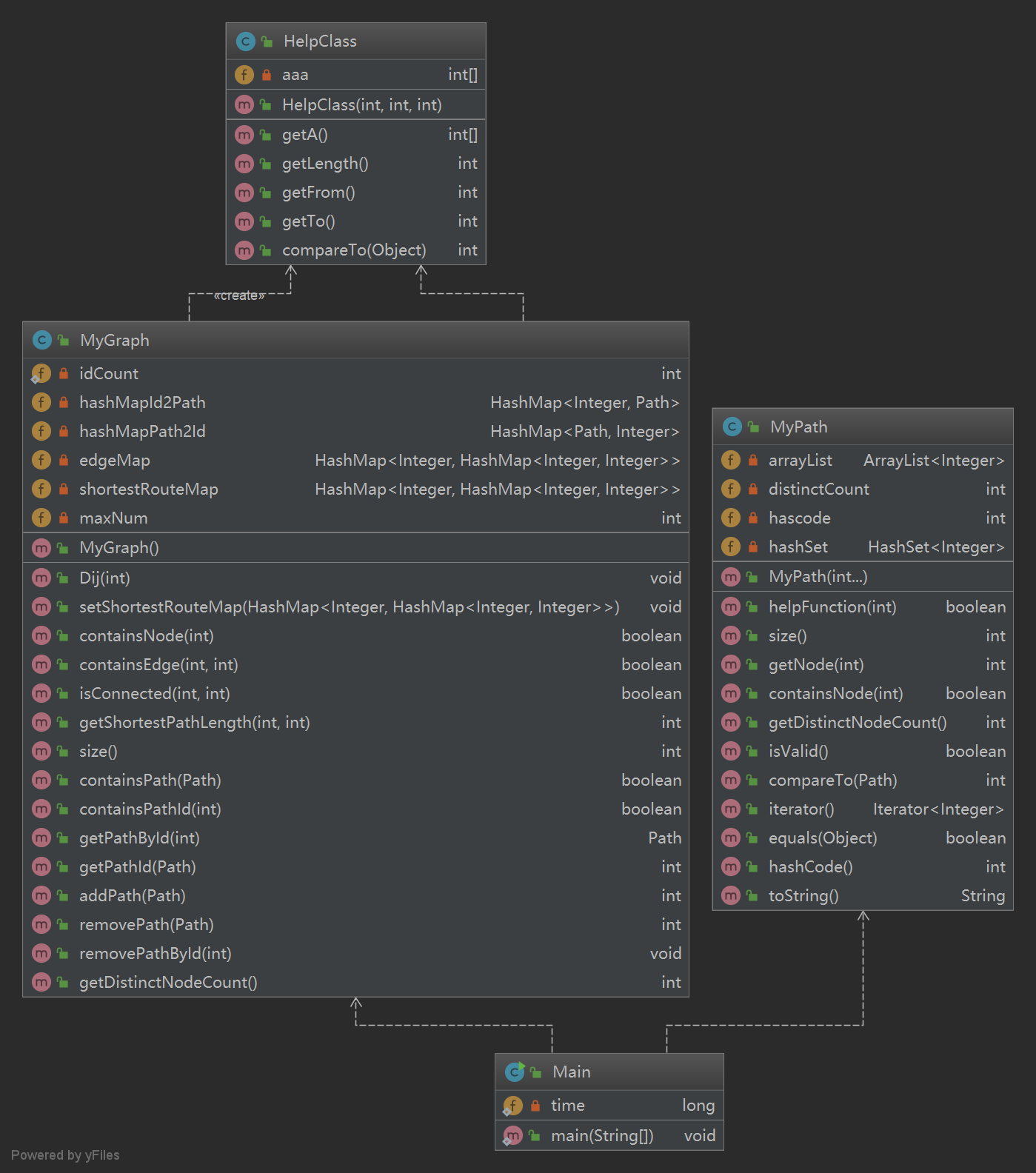
该次作业UML类图如下
方法复杂度
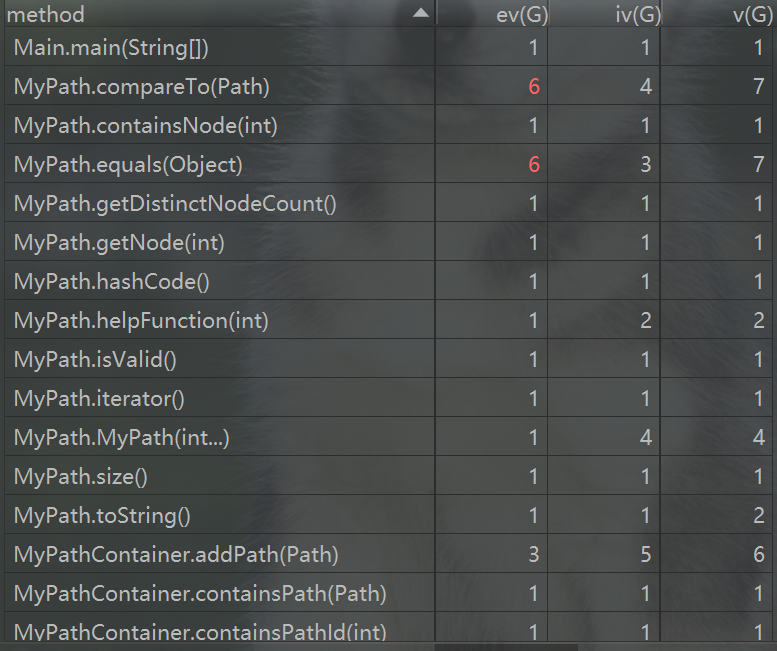
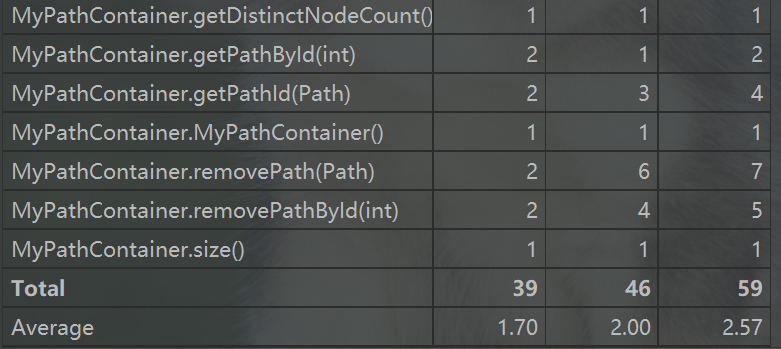
这次作业两个方法比较复杂,分别是compareTo和equals。两个方法内都有对path对象每一个节点的遍历,这或许就是造成方法复杂的原因。总体来说第一次作业较为简单,比较坑的就是程序的时间复杂度的控制,这里要用合适的容器当作pathcontainer,我选的是HashMap,查找,增删的时间复杂度就很低。并且利用类似缓存的策略存储distinctNodeCount的结果。确保了程序CPU时间不超时。
2.第二次作业
UML图
方法复杂度
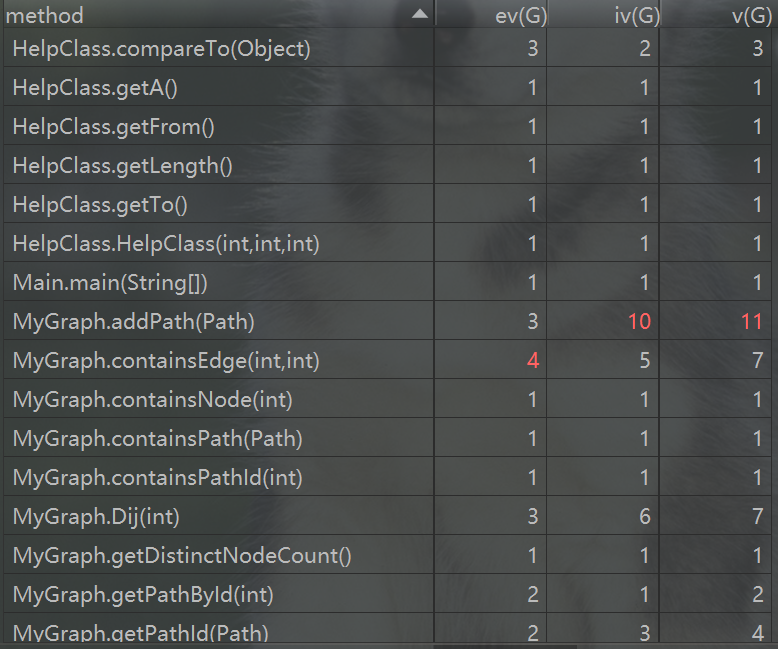
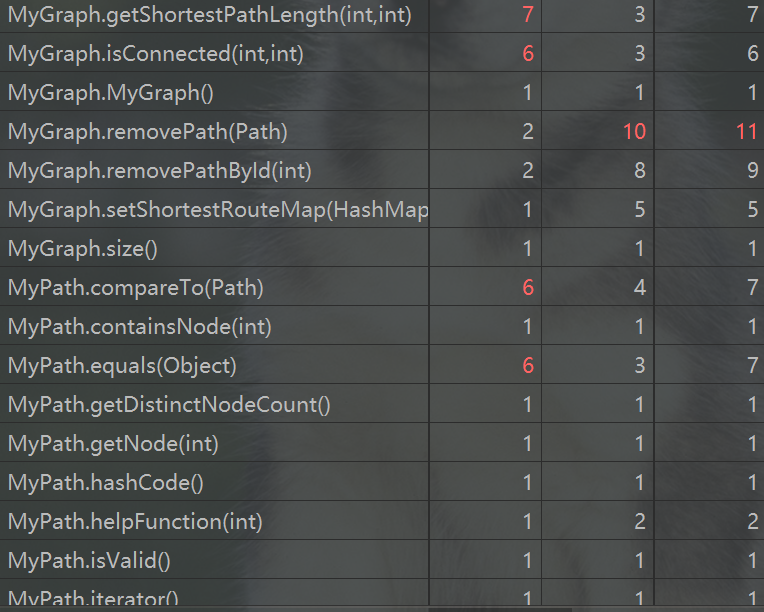

这次作业复杂的方法主要是add和remove。具体原因就是为了实现快速查询,我将大部分工作都放在了add和remove方法内部。具体而言就是,每add一跳路径,我都将此时刻的图结构构好,每remove一条图,也改变对应的图结构。计算最短路径使用的是迪杰斯特拉算法,并且用优先队列进行优化,时间复杂度是O(ElogE ),每次计算好都存到一张记录各个点之间最短路径的HashMap中。这种想法也是仿照缓存的思想。一旦之前算过一次,之后直接从HashMap中取出即可。不过每次add和remove之后,HashMap中存的值都无效了。再计算最短路径就需要重新计算。
3.第三次作业
UML图
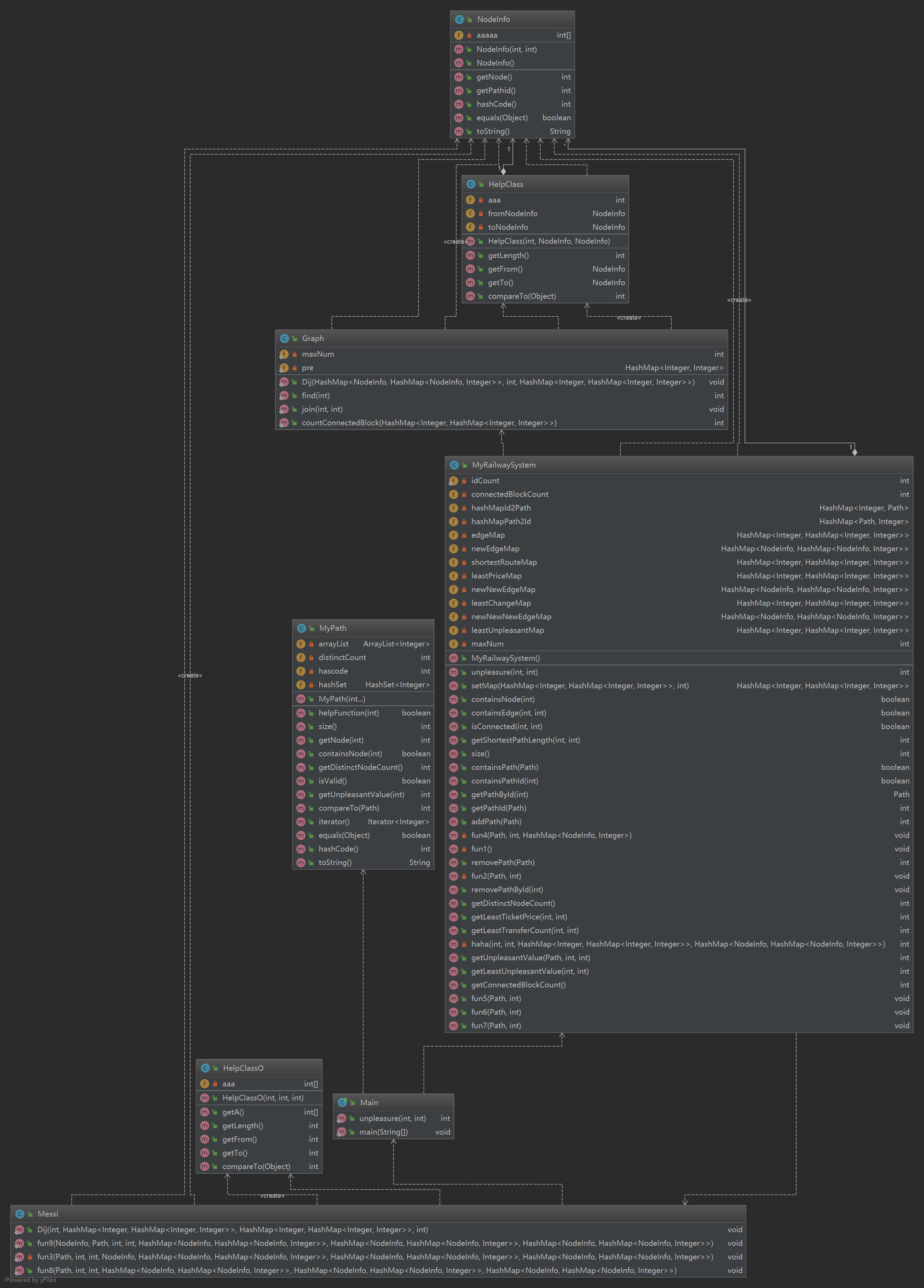
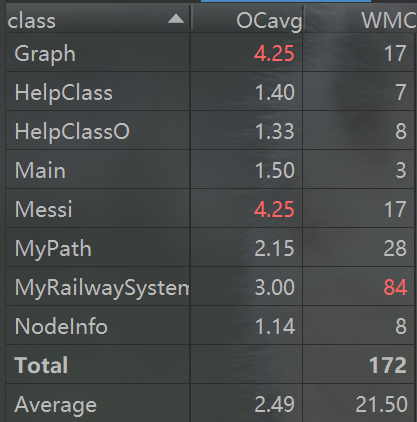
类复杂度(方法太多,方法复杂度表格太大,这里就不放了。。。)
第三次作业秉承了我前两个单元的传统,那就是第三次作业的架构就是屎山。我写完这次作业的时候,MyRailwaySystem的行数达到了900行,为了代码风格分,我只好把MyRailwaySystem中的部分方法放到Messi类中,变成Messi类的静态方法来使用。这样代码风格分的问题就解决了。但是很不面向对象,完全就是面向方法编程。但由于完成的时间是在太晚,无奈没时间重构了。就只能交上去一个没法读的project(我猜互测的时候没人愿意看我的代码。。。)
这次作业主要的思想就是拆点,并且每个点加一根点进行辅助计算。算法上难度不是很大,主要是实现上过于复杂,每次add和remove的过程都要仔仔细细的处理,不然就会出错。我一开始中测倒数第二个点一直过不去就是因为在add的时候的构图问题。比如说一条指令
PATH_ADD 1 2 3 3
第二个“3”的邻接表会把第一个“3”的邻接表覆盖,导致3和2不邻接。这样程序就崩了,这个bug很难找,无奈只能对拍。这里也感谢金哥哥救我一命。
5.分析bug和修复情况
三次作业很幸运,在公测互测中都没有被找出bug。这主要是对拍器的功劳,充分对拍后基本上就不会出现bug了。当然也要感谢给我提供jar包的各位巨佬。
前两次互测我都处在划水模式,因为前两次都比较简单,看了一眼同组人的神仙框架,感觉不会有bug就没有去跑对拍器。
第三次由于我很晚才写完,心里没底,于是就跑起了评测机。果不其然,同组Berserker哇了。经过一番分析。以下指令对导致他出错
PATH_ADD 1 1 2 3
CONTAIN_EDGE 1 1
正常来说应该输出yes.但这位仁兄输出no.具体原因没去深究。捅了他四刀就溜。
6.心得体会
前文提到了,JML的目的是跳过实现去描述功能。那么为什么我们不能直接用自然语言(汉语,英语)去描述呢?
个人认为一方面自然语言具有二义性,不同人对同一句话可能产生不同的理解,但是类似JML的规格描述就不会有这样的问题。如果采用自然语言描述功能,很可能适得其反。
第二方面,现在自然语言处理的水平有限,很难有一个工具能够理解并对其做出检查。或许在不久的将来,机器学习到达了Ray Kurzweil口中的奇点,这些都能实现。
用了一个月的JML,感受确实很不好。就拿第一次作业的一个方法规格为例
1 /*@ ensures (\exists int[] arr; (\forall int i, j; 0 <= i && i < j && j < arr.length; arr[i] != arr[j]);
2 @ (\forall int i; 0 <= i && i < arr.length; (\exists Path p; this.containsPath(p); p.containsNode(arr[i])))
3 @ &&(\forall Path p; this.containsPath(p); (\forall int node; p.containsNode(node); (\exists int i; 0 <= i && i < arr.length; node == arr[i])))
4 @ &&(\result == arr.length));
5 @*/
6 public /*@pure@*/int getDistinctNodeCount(); //在容器全局范围内查找不同的节点数
JML的描述多达5行,看起来也十分费劲,而中文的解释只需数十个字,一目了然就知道要干啥。可见JML在描述复杂功能上的缺陷
在第三次作业中,这个缺陷再次被放大。为了描述一个求最低票价的方法规格,课程组首先描述了 isConnectedInPathSequence 和 getTicketPrice 这两个方法的规格。为了描述 isConnectedInPathSequence 的规格,课程组又描述了 containsPathSequenc的规格。每个规格都很复杂。直接导致了我没看规格,完全凭借指导书理解。没有出bug实属幸运。(下个单元我一定好好读要求!!)
最后想说的就是这个单元其实对于算法的要求有点高,要考虑每个算法的时间复杂度,数据结构,利用缓存的思想减少计算次数。个人对此没有异议,正好以前没怎么学过算法,这一单元也算学了点。
7.写在最后
OO还有一个月就要结束了,希望我能给这门课画上圆满的句号!
