面向对象程序设计第三单元总结
面向对象程序设计第三单元总结
一、写在前面
“好的规范总能够比任何编程工具或技术更好地改进程序员的生产力。”—— Milt Bryce,系统方法论之父
经过本单元的学习和训练,我体会到了规格化设计的思想,了解并实践了JML(Java Modeling Language)。三次作业的训练背景是实现一个社交网络(NetWork)及其功能,本文将从以下几个方面进行梳理总结:
-
数据构造逻辑:主要从白盒和黑盒两方面展开,其中白盒数据主要从JML规格出发构造,黑盒数据依赖于随机数据生成。
-
方法复杂度控制:主要阐述在实现社交网络功能的过程中,如何根据JML规格发现复杂度高的方法,以及如何采取有针对性的措施降低方法复杂度。
-
互测过程中发现他人的bug:主要罗列互测时同房间成员的bug及分析。
-
JML知识的应用:主要通过对NetWork的扩展来进一步练习JML规格的书写,加深对JML的理解。
-
相关知识拓展:主要介绍与JML高度相关的契约式编程,并总结学习体会。
二、自测——从JML规格出发构造测试数据
2.1白盒测试——从JML规格出发
笔者认为,在本单元,直接从JML规格出发构造数据将带来更佳的测试体验,下面以具体实例阐述构造逻辑:
第一次作业
对比阅读各个方法的JML,发现其中最复杂的当属 queryBlockSum:
/*@ ensures \result ==
@ (\sum int i; 0 <= i && i < people.length &&
@ (\forall int j; 0 <= j && j < i; !isCircle(people[i].getId(), people[j].getId()));
@ 1);
@*/
public /*@ pure @*/ int queryBlockSum();
其中 isCircle判断两个节点是否可达,也是一个比较复杂的方法,因此,如果真的完全按照JML规格用二重循环书写上述qbs方法,时间复杂度可能会爆掉。
经过上述分析,我们在数据要求限制下构造极端数据:
500条add Person,500条qbs
第二次作业
社交网络功能进一步增加,通过阅读JML可以看出,本次作业中最复杂的方法非常容易被人所忽略,那就是 qgvs,它调用了Group类内部的 getValueSum方法:
/*@ ensures \result == (\sum int i; 0 <= i && i < people.length;
@ (\sum int j; 0 <= j && j < people.length &&
@ people[i].isLinked(people[j]); people[i].queryValue(people[j])));
@*/
public /*@ pure @*/ int getValueSum();
如果单纯按照规格实现,这将是一个 n^2复杂度的方法,因此也可能CTLE。构造数据可以类似如下:
1111条add Person,1111条add to Group,2118条qgvs
第三次作业
本次作业虽然也有复杂度可能会写得很高的方法,但是大部分同学都吸取了前两次的经验教训,着重改进自己的方法复杂度,因此想从卡CTLE入手hack更加困难。
2.2黑盒测试——随机数据生成
随机数据生成的主要作用就是:当白盒测试数据失效,hack失去方向时,可以利用随机数据进行轰炸,运气好就可以爆出对方的错误(本人在第三次作业就是利用随机数据成功hack了同房成员得到两个肉眼不易发现的bug,下面会详细讲解)。
随机生成数据的技巧(以下是wxg同学的先进经验,我大受启发):
-
参数宏控制:提高数据的覆盖率

-
测试主题分类:提高数据的针对性
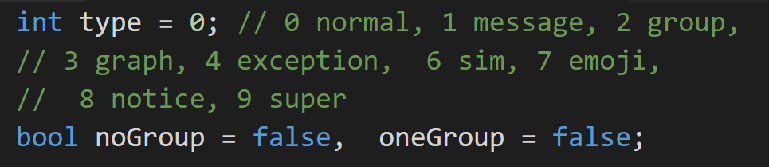
-
数据具体生成逻辑
-
首先针对不同测试主题调用不同指令类的顶层生成函数
-
其次在指令类顶层生成函数中依概率调用具体指令的生成函数(借助random等函数)
-
最后实现每个指令的生成函数
-
2.3JML应用工具链
在课程组的建议下,我还了解了一些和JML相关的工具:OpenJML以及JMLUnit
OpenJML
OpenJML是可用于Java程序的程序验证工具,它可以检查使用JML(Java Modeling Language)语言进行注释的程序的正确性。它支持静态的检查,也支持运行时检查。此外它还集成了一些SMT Solvers,便于对程序进行更深层次的验证。
JMLUnit
最大的优点是可以检查数据覆盖率,但是不幸的是就算全覆盖了,还是不能保证没有bug。
三、三次作业中图模型的构建和维护策略
本单元的基础是实现一个社交网络及其功能,该模型的层次主要有三层:Network、Group和Person。关于图模型的功能实现已经有JML规格给出,但是从第二部分的白盒测试部分我们也已经感受到,如果完全按照规格实现,将带来时间复杂度超标的严重问题,接下来笔者将具体例举自己解决这些复杂度问题的措施。
3.1第一次作业——连通分支数(并查集)
如第二部分所述,我们直接关注 qbs方法,思考如何降低其复杂度:翻译一下 qbs的JML,它完成的是遍历所有的person,如果当前person和先前的person都不可达,则结果加1,经过思考发现,同一连通块(点互相可达)里的person只要有一个在之前被遍历,则之后该连通块里的person将不再影响结果,换句话说,本质上该方法求得是图中连通分支得个数。
因此,我们可以使用并查集维护根节点的数目,从而使qbs方法得复杂度被均摊,调用时直接返回维护得连通分支数即可。
3.2第二次作业——最小生成树 & qgvs
-
最小生成树——克鲁斯卡尔
第二次作业大部分同学都关注到了最复杂的方法: queryLeastConnection,该方法本质上是求图中由一个点出发的最小生成树。我采用了基于并查集的克鲁斯卡尔算法,并尝试了路径压缩、按秩归并等优化。
public int queryLeastConnection(int id) throws PersonIdNotFoundException {
if (!contains(id)) {
throw new MyPersonIdNotFoundException(id);
} else {
int sum = 0;//记录边权和
int n = 0;
ancestors = new HashMap<>();
for (int personId : people.keySet()) {
if (isCircle(personId, id)) {
ancestors.put(personId, personId);//init
n++;
}
}
for (MyEdge edge : edges) {
if (ancestors.containsKey(edge.getStart())
&& ancestors.containsKey(edge.getTo())) {
int start = find(edge.getStart());
int to = find(edge.getTo());
if (start != to) {
merge(start, to);//合并
sum += edge.getValue();
n--;
if (n == 1) {
break;
}
}
}
}
return sum;//最小生成树
}
}
但是,本次作业还有一个方法可能导致CTLE却被很多同学忽略,那就是第二部分提到的 qgvs,笔者的措施是动态维护Group的valueSum,具体有以下几点:
-
addRelation时,更新所有包含person点的组public void updateGroupValueSum(Person person1, Person person2, int value) {
for (Group group : groups.values()) {
if (group.hasPerson(person1) && group.hasPerson(person2)) {
((MyGroup) group).addValueSum(value);
}
}
}
-
addPerson和delPerson时public void addPerson(Person person) {
this.people.put(person.getId(), person);
for (Person per : people.values()) {
valueSum += person.queryValue(per);
}
}
public void delPerson(Person person) {
people.remove(person.getId());
for (Person per : people.values()) {
valueSum -= person.queryValue(per);
}
}
这样我们将原本 O(n^2)的复杂度分摊成了 O(n)。
3.3第三次作业——堆优化的Dijistra
本次作业的关键是sendIndirectMessage方法,该方法的核心是求解两点间的最短距离,笔者采用的思路是堆优化的 Dijistra,利用了java中的PriorityQueue容器,十分方便。
public int shortest(int start, int end) {
for (Integer id : people.keySet()) {
dis.put(id, inf);
vis.put(id, false);
}
dis.put(start, 0);
queue = new PriorityQueue<>();
queue.add(new Pair(0, start));
while (!queue.isEmpty()) {
Pair temp = queue.poll();
if (vis.get(temp.getTo())) {
continue;
}
if (temp.getTo() == end) {
break;
}
vis.put(temp.getTo(), true);
MyPerson myPerson = (MyPerson) getPerson(temp.getTo());
HashMap<Integer, Person> acquaintance = myPerson.getAcquaintance();
for (Integer id : acquaintance.keySet()) {
if (vis.get(id)) {
continue;
}
int tempDis = temp.getDis() + myPerson.queryValue(acquaintance.get(id));
if (dis.get(id) > tempDis) {
dis.put(id, tempDis);
queue.add(new Pair(tempDis, id));
}
}
}
return dis.get(end);
}
四、性能问题与修复情况
本人在三次作业的强测和互测中均未出现bug,在互测中发现同房间人的bug如下:
-
qbs复杂度过高 -
qgvs复杂度过高 -
第三次作业中发现的bug比较特殊,是通过随机数据炸出来的,刚看到房友的错误时还以为自己进了C房,具体截图记录如下:

该同学的括号本应该括住 people.size()-1,但是不幸只括住了 people.size(),肉眼确实难以发现。

该同学犯的是边遍历边删除的经典错误。
五、Network扩展及JML规格书写
要求:
假设出现了几种不同的Person
-
Advertiser:持续向外发送产品广告
-
Producer:产品生产商,通过Advertiser来销售产品
-
Customer:消费者,会关注广告并选择和自己偏好匹配的产品来购买 -- 所谓购买,就是直接通过Advertiser给相应Producer发一个购买消息
-
Person:吃瓜群众,不发广告,不买东西,不卖东西
如此Network可以支持市场营销,并能查询某种商品的销售额和销售路径等 请讨论如何对Network扩展,给出相关接口方法,并选择3个核心业务功能的接口方法撰写JML规格(借鉴所总结的JML规格模式)
-
如何对
NetWork进行扩展?(定义接口方法)
首先Advertiser、Producer和Customer需要继承Person接口,另外为了支持广告及购买,需要新建AdvertisementMessage类和PurchaseMessage类,且都实现Message接口,另还需要定义Product类存储产品信息。具体行为如下:
Advertiser可以发送AdvertisementMessage给Customer,也可以发送PurchaseMessage给Producer;Customer接收 AdvertisementMessage,并在AdvertisementMessage中根据自己的偏好选择是否回复Advertiser指定的 PurchaseMessage,Advertiser接收到PurchaseMessage后转发给Producer,并增减相应Money,完成商品销售的流程。
-
Adversier类:内部存储订阅自己广告的客户群Customer,以及和自己合作的Producer,方法由sendAdvertisementMessage和sendPurchaseMessage等。 -
Customer类:内部存储自己的偏好产品Product。
-
Producer类:内部存储自己生产的产品Product。
-
Product类:存储一类产品的诸多信息。
-
AdvertisementMessage:存储AdvertiserId、ProducerId、ProductId、Price等信息,这些信息供Customer查看。 -
PurchaseMessage:存储AdvertiserId、CustomerId、ProductId、Number等信息,这些信息供Producer查看。
NetWork中添加 public int queryProductSalesVolume(int ProductId)用来查询某产品的销售量、public List<> queryProduct(int ProductId)用来查询某产品的销售路径。
-
选择三个核心业务功能的接口方法撰写JML规格:
-
求产品销售量:
/*@ public normal_behavior
@ requires containsProductId(ProductId);
@ ensures \result == getProduct(ProductId).getSalesAmount();
@ also
@ public exceptional_behavior
@ signals (ProductNotFoundException e) !containsProduct(ProductId);
@*/
public int queryProductSalesVolume(int ProductId) throws ProductNotFoundException;
-
Adversier向 Customer发送广告:/*@ public normal_behavior
@ requires containsAdvertisement(id);
@ assignable AdvertisementList;
@ ensures !containsAdvertisement(id) && AdvertisementList.length == \old(AdvertisementList.length) - 1 &&
@ (\forall int i; 0 <= i && i < \old(AdvertisementList.length) && \old(AdvertisementList[i].getId()) != id;
@ (\exists int j; 0 <= j && j < AdvertisementList.length; AdvertisementList[j].equals(\old(AdvertisementList[i]))));
@ ensures (\forall int i; 0 <= i && i < CustomerList.length;
@ (\forall int j; 0 <= j < \old(CustomerList[i].AdvertisementList.length)
@ (\exists int k; 0 <= k < CustomerList[i].AdvertisementList.length;
@ \old(CustomerList[i].AdvertisementList[j]) == CustomerList[i].AdvertisementList[k])));
@*/
public void sendAdvertisement(int id); -
给Customer新加产品偏好
/*@ public normal_behavior
@ requires containsCustomer(CustomerId);
@ requires containsProduct(ProductId);
@ ensures getCustomer(CustomerId).isPerfer(ProductId) == true;
@*/
public /*@ pure @*/void addPerference(int CustomerId, int ProductId);
六、本单元学习体会
在本单元,除了课内作业的练习,我还搜集学习了一些和本单元相关的内容,例如契约式编程,具体如下:
1. 什么是契约式编程?
英文名:Design by Contract(DbC),维基百科上的定义是a software correctness methodology,意为软件正确性方法,是软件工程中的一种设计方法,最初设计时有preconditions and postconditions,后经发展主要由先验条件、后验条件和不变式组成,这三个概念和我们课程学习的JML类似。该方法要求软件设计者为软件组件定义正式、精确且可验证的接口,从而达到确保软件正确性的目的。”契约“是一种比喻,指该设计方法中设计者和实现者之间的约定。
2. 契约式编程的目的和作用?
契约式编程的主要目的是希望程序员能够在设计程序时明确地规定一个模块单元(具体到面向对象,就是一个类的实例)在调用某个操作前后应当属于何种状态,它更像是一种设计风格或一种语法规范。
契约式编程的三个组成要素先验条件、后验条件和不变式与JML的定义类似,但是有一点不同的是,在契约式编程中,当以上规范没有成立时,编译器会直接报错,停止执行,如此保证了能够正确运行的程序的行为在合理的规范要求内,避免出现意想不到或模糊不清的错误,基于此,契约式编程类似于进攻式编程,就是如果员工没有得到想要的东西,就会直接罢工。
3. 契约式编程的对比
契约式编程经常和防御式编程对比,
契约式编程形象地说就是双方达成一致,各自尽到应尽的义务,如果有一方出现问题,则契约失败,程序当场运行出错
防御式编程形象地说就是我没法保证另一方给我的条件一定是合适的,我得有提防和解决另一方犯的各种错误,这时如果有一方犯错,程序往往会执行已经设计好的防御步骤,从而避免自我崩溃。
4. 设计思想启示
在我看来以上两种编程方式,都是非常理想化的编程,契约式编程要想奏效需要保证每个人都遵守契约,但是人性复杂,这一点不可能时刻保证;而防御式编程则需要防御者对可能出现的错误情况实现精准预测,但是人都会有局限性,百密一疏时常发生,没有人能做到绝对正确。放到具体的情境里,例如前端与后端的接口、不同部门同事的交流,按照契约式编程,没人Care你的契约,按照防御式编程,代码惨不忍睹,还容易漏掉防御。那么到底该怎么办呢,我认为,我们应当尽可能地推广契约式编程,因为契约式编程确实有助于开发效率的提升,让每个人都对自己写的代码负责,在开发者之间建立良好的信任关系,同时也能减少不必要的沟通成本和精力,以及本可通过协商避免的相互提防。但同时,必要的防御式编程也是不能少的,这主要是为了保证程序的健壮与稳定。总的来说就是物极必反,我们还是应该秉持中庸之道,到底是契约还是防御,视情况而定,追求二者的平衡。
5.总结
all is well.

