hadoop词频统计
1.首先要启动hdfs集群和hive数据库
2.创建并导入文件
进入到hadop目录下
在命令行窗口输入下面的命令:
hadoop fs -mkdir /input1
在电脑桌面中新建两个文件file1.txt和file2.txt
将这两个文件拖到虚拟机中任意的文件目录下(记住这个文件目录)
然后将这两个文件导入到input1文件夹中
hdfs dfs -put /(你的该文件目录)/file1.txt /input1
hdfs dfs -put /(你的该文件目录)/file2.txt /input1
3.进入到mapreduce目录中并执行语句:
hadoop jar hadoop-mapreduce-examples-3.3.4.jar wordcount /input1 /output1
(你可以在node1:9870中查看结果)
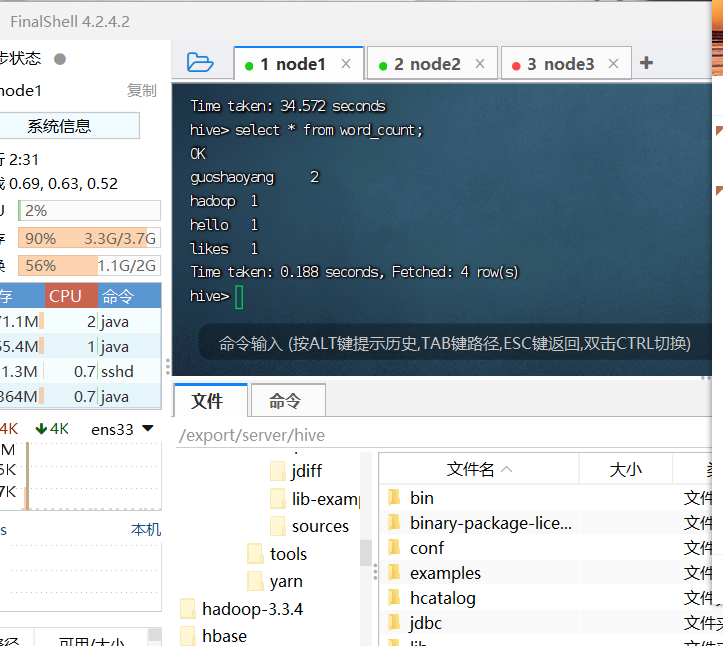
4.通过HiveQL实现词频统计功能
(在这步我出现了一些问题,大家都懂每台电脑都有它的脾气秉性😭同样的步骤在别人那里行到你的电脑上就不行😂)
首先进入到Hive目录下,输入bin/hive,进入到Hive,以下都在Hive中执行。
最后的正确步骤:(一定要分三行来执行,如果按照上面的方法来,文件路径就是/input1)

#第一行执行 create table docs(line string); #第二行执行 load data inpath 'hdfs中文件的路径,一般在根目录下' overwrite into table docs; #第三行执行 create table word_count as select word, count(1) as count from (select explode(split(line,' '))as word from docs) w group by word order by word;
然后执行
select * from word_count