


浏览器从输入网址发生的事(前端优化)
监控网页与程序性能
当在浏览器地址栏输入一个网址开始,到最终页面的呈现,浏览器完成了他的工作。我们要优化这个程序呈现的速度,首先就得弄明白这其中都发生了 什么事?
1.处理环节与顺序
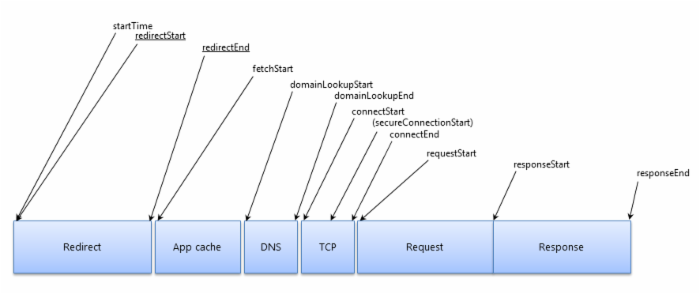
这张图大致的描述了浏览器的一系列工作。
2.chrome中的performance属性
在chrome 浏览器的console中输入window.performace会得到下图的内容
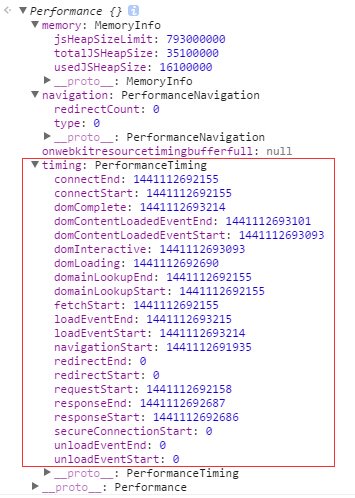
- usedJSHeapSize js对象占用的内存一定小于totalJSHeapSize
- totalJSHeapSize 可使用的内存
- jsHeapSizeLimit 内存大小限制
navigation 对象(描述页面从哪里来)
- redirectCount 如果有重定向的话,页面通过几次重定向跳转而来
- type
type 取值 0:即 TYPE_NAVIGATENEXT 正常进入的页面(非刷新、非重定向等) 1:即 TYPE_RELOAD 通过window.location.reload 刷新页面 2:即 TYPE_BACK_FORWARD 通过浏览器的前进后退按钮 255:即 TYPE_UNDEFINED 非以上方式进入页面
timing 对象
- navigationStart 初始化页面,在同一个浏览器上下文中前一个页面unload的时间戳,如果没有前一个页面的unload,则与fetchStart值相等
- unloadEventStart 前一个页面的unload的时间戳 如果没有则为0、
- unloadEventEnd 与unloadEventStart 相对应,返回的是unload函数执行完成的时间戳
- redirectStart 第一个http重定向发生的时间 有跳转且是同域的重定向 否则为0
- redirectEnd 最后一个重定向完成时的时间,否则为0
- fetchStart 浏览器准备好使用http请求抓取文档的时间,这发生在检查缓存之前
- domainLookupStart DNS域名开始查询的时间,如果有本地的缓存或keep-alive 时间为0.
- domianLookupEnd
- connectStart Http(TCP) 开始建立连接的时间,如果是持久连接,则与fecthStart 值相等。 (注意 如果在传输层发生了错误且重新建立了连接,则这里显示的是新建立的连接开始时间)
- connectEnd Http(Tcp) 完成握手的时间,如果是持久连接则与fecthStart 值相等。(注意 如果在传输层发生了错误且重新建立了连接,则这里显示的是新连接完成的时间。 这里包括ssl等授权通过)
- secureConnectionStart https 连接开始的时间,如果不是安全连接 则为0
- requestStart http请求读取真实文档开始的时间(完成建立连接),包括从本地缓存读取。 连接错误时这里也显示重新建立连接的时间。
- requestEnd 包括本地缓存
- responseStart
- responseEnd
- domloading 开始解析渲染dom树的时间,此时Document.readyState 变成loading ,并将抛出readyStateChange 事件
- dominteractive 完成解析DOM树的时间,Document.readyState 变成interactive,并将抛出readyStateChange事件(注意 只是DOM树解析完成,这时候并没有开始加载网页内的资源)
- domContentLoadedEventStart 在DOM树解析完成后,网页内资源加载开始的时间。在DOMcontentLoaded事件抛出前发生
- domContentLoadedEventEnd DOM树解析完成后,网页内资源加载完成时间(如JS脚本加载执行完成) 这个阶段会可能会触发 domcontentLoaded 事件
- domCompelete Dom树解析完成,且资源也准备就绪的时间,Document.readyState变成complete.并将抛出readystatechange 事件
- loadEventStart load 事件发送给文档,也即load回调函数开始执行的时间
- loadEventEnd load回调函数执行完成的时间
使用 performance.timing 信息简单计算出网页性能数据
// 计算加载时间 function getPerformanceTiming() { var performance = window.performance; if (!performance) { // 当前浏览器不支持 console.log('你的浏览器不支持 performance 接口'); return; } var t = performance.timing; var times = {}; //【重要】页面加载完成的时间 //【原因】这几乎代表了用户等待页面可用的时间 times.loadPage = t.loadEventEnd - t.navigationStart; //【重要】解析 DOM 树结构的时间 //【原因】反省下你的 DOM 树嵌套是不是太多了! times.domReady = t.domComplete - t.responseEnd; //【重要】重定向的时间 //【原因】拒绝重定向!比如,http://example.com/ 就不该写成 http://example.com times.redirect = t.redirectEnd - t.redirectStart; //【重要】DNS 查询时间 //【原因】DNS 预加载做了么?页面内是不是使用了太多不同的域名导致域名查询的时间太长? // 可使用 HTML5 Prefetch 预查询 DNS ,见:[HTML5 prefetch](http://segmentfault.com/a/1190000000633364) times.lookupDomain = t.domainLookupEnd - t.domainLookupStart; //【重要】读取页面第一个字节的时间 //【原因】这可以理解为用户拿到你的资源占用的时间,加异地机房了么,加CDN 处理了么?加带宽了么?加 CPU 运算速度了么? // TTFB 即 Time To First Byte 的意思 // 维基百科:https://en.wikipedia.org/wiki/Time_To_First_Byte times.ttfb = t.responseStart - t.navigationStart; //【重要】内容加载完成的时间 //【原因】页面内容经过 gzip 压缩了么,静态资源 css/js 等压缩了么? times.request = t.responseEnd - t.requestStart; //【重要】执行 onload 回调函数的时间 //【原因】是否太多不必要的操作都放到 onload 回调函数里执行了,考虑过延迟加载、按需加载的策略么? times.loadEvent = t.loadEventEnd - t.loadEventStart; // DNS 缓存时间 times.appcache = t.domainLookupStart - t.fetchStart; // 卸载页面的时间 times.unloadEvent = t.unloadEventEnd - t.unloadEventStart; // TCP 建立连接完成握手的时间 times.connect = t.connectEnd - t.connectStart; return times; }
使用performance.getEntries() 获取所有资源请求的时间数据
这个函数返回的将是一个数组, 包含了页面中所有的 HTTP 请求, 这里拿第一个请求 window.performance.getEntries()[0] 举例。 注意 HTTP 请求有可能命中本地缓存, 所以请求响应的间隔将非常短 可以看到, 与 performance.timing 对比: 没有与 DOM 相关的属性: navigationStart unloadEventStart unloadEventEnd domLoading domInteractive domContentLoadedEventStart domContentLoadedEventEnd domComplete loadEventStart loadEventEnd 新增属性: name entryType initiatorType duration 与 window.performance.timing 中包含的属性就不再介绍了: var entry = { // 资源名称,也是资源的绝对路径 name: "http://cdn.alloyteam.com/wp-content/themes/alloyteam/style.css", // 资源类型 entryType: "resource", // 谁发起的请求 initiatorType: "link", // link 即 <link> 标签 // script 即 <script> // redirect 即重定向 // 加载时间 duration: 18.13399999809917, redirectStart: 0, redirectEnd: 0, fetchStart: 424.57699999795295, domainLookupStart: 0, domainLookupEnd: 0, connectStart: 0, connectEnd: 0, secureConnectionStart: 0, requestStart: 0, responseStart: 0, responseEnd: 442.7109999960521, startTime: 424.57699999795295 }; 可以像 getPerformanceTiming 获取网页的时间一样, 获取某个资源的时间: // 计算加载时间 function getEntryTiming(entry) { var t = entry; var times = {}; // 重定向的时间 times.redirect = t.redirectEnd - t.redirectStart; // DNS 查询时间 times.lookupDomain = t.domainLookupEnd - t.domainLookupStart; // 内容加载完成的时间 times.request = t.responseEnd - t.requestStart; // TCP 建立连接完成握手的时间 times.connect = t.connectEnd - t.connectStart; // 挂载 entry 返回 times.name = entry.name; times.entryType = entry.entryType; times.initiatorType = entry.initiatorType; times.duration = entry.duration; return times; }
浏览器中timeline 时间线说明
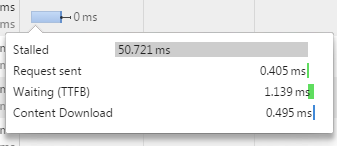
-
Stalled是浏览器得到要发出这个请求的指令,到请求可以发出的等待时间,一般是代理协商、以及等待可复用的TCP连接释放的时间,不包括DNS查询、建立TCP连接等时间等 -
Request sent请求第一个字节发出前到最后一个字节发出后的时间,也就是上传时间 -
Waiting请求发出后,到收到响应的第一个字节所花费的时间(Time To First Byte) -
Content Download收到响应的第一个字节,到接受完最后一个字节的时间,就是下载时间
浏览器允许的并发请求资源数
浏览器即使放弃保护自己,将所有请求一起发给服务器,也很可能会引发服务器的并发阈值控制而被BAN,而另外一个控制在8以内的原因也是keep alive技术的存在使得浏览器复用现有连接和服务器通信比创建新连接的性能要更好一些。
所以,浏览器的并发数其实并不仅仅只是良知的要求,而是双方都需要保护自己的默契,并在可靠的情况下提供更好的性能。
前端技术的逐渐成熟,还衍生了domain hash, cookie free, css sprites, js/css combine, max expires time, loading images on demand等等技术。这些技术的出现和大量使用都和并发资源数有关。
- 按照普通设计,当网站cookie信息有1 KB、网站首页共150个资源时,用户在请求过程中需要发送150 KB的cookie信息,在512 Kbps的常见上行带宽下,需要长达3秒左右才能全部发送完毕。 尽管这个过程可以和页面下载不同资源的时间并发,但毕竟对速度造成了影响。 而且这些信息在js/css/images/flash等静态资源上,几乎是没有任何必要的。 解决方案是启用和主站不同的域名来放置静态资源,也就是cookie free。
- 将css放置在页面最上方应该是很自然的习惯,但第一个css内引入的图片下载是有可能堵塞后续的其他js的下载的。而在目前普遍过百的整页请求数的前提下,浏览器提供的仅仅数个并发,对于进行了良好优化甚至是前面有CDN的系统而言,是极大的性能瓶颈。 这也就衍生了domain hash技术来使用多个域名加大并发量(因为浏览器是基于domain的并发控制,而不是page),不过过多的散布会导致DNS解析上付出额外的代价,所以一般也是控制在2-4之间。 这里常见的一个性能小坑是没有机制去确保URL的哈希一致性(即同一个静态资源应该被哈希到同一个域名下),而导致资源被多次下载。
- 再怎么提速,页面上过百的总资源数也仍然是很可观的,如果能将其中一些很多页面都用到的元素如常用元素如按钮、导航、Tab等的背景图,指示图标等等合并为一张大图,并利用css background的定位来使多个样式引用同一张图片,那也就可以大大的减少总请求数了,这就是css sprites的由来。
- 全站的js/css原本并不多,其合并技术的产生却是有着和图片不同的考虑。 由于cs/js通常可能对dom布局甚至是内容造成影响,在浏览器解析上,不连贯的载入是会造成多次重新渲染的。因此,在网站变大需要保持模块化来提高可维护性的前提下,js/css combine也就自然衍生了,同时也是minify、compress等对内容进行多余空格、空行、注释的整理和压缩的技术出现的原因。
- 随着cookie free和domain hash的引入,网站整体的打开速度将会大大的上一个台阶。 这时我们通常看到的问题是大量的请求由于全站公有header/footer/nav等关系,其对应文件早已在本地缓存里存在了,但为了确保这个内容没有发生修改,浏览器还是需要请求一次服务器,拿到一个304 Not Modified才能放心。 一些比较大型的网站在建立了比较规范的发布制度后,会将大部分静态资源的有效期设置为最长,也就是Cache-Control max-age为10年。 这样设置后,浏览器就再也不会在有缓存的前提下去确认文件是否有修改了。 超长的有效期可以让用户在访问曾访问过的网站或网页时,获得最佳的体验。 带来的复杂性则体现在每次对静态资源进行更新时,必须发布为不同的URL来确保用户重新加载变动的资源。
- 即使是这样做完,仍然还存在着一个很大的优化空间,那就是很多页面浏览量很大,但其实用户直接很大比例直接就跳走了,第一屏以下的内容用户根本就不感兴趣。 对于超大流量的网站如淘宝、新浪等,这个问题尤其重要。 这个时候一般是通过将图片的src标签设置为一个loading或空白的样式,在用户翻页将图片放入可见区或即将放入可见区时再去载入。 不过这个优化其实和并发资源数的关系就比较小了,只是对一些散布不合理,或第一页底部的资源会有一定的帮助。 主要意图还是降低带宽费用。
1.为了让html文档在解析时,尽量地快,常规的做法是将<script>标签放到</body>标签的前面,这样就不会阻塞html中其他资源的下载了。
2.HTML5中的defer和async
<script src="file1.js" defer></script> <script src="file2.js" async></script>
defer和async区别:
就defer和async的区别而言,使用defer的<script>标签是按照他们排列的顺序执行的,而使用async的<script>标签是不按他们在HTML中的排列顺序执行的;
就执行时间而言,defer是在DOMContentloaded事件之前执行,而async是在window.onload事件之前执行的,且只支持IE10+。当defer和async同时存在时,会忽略defer而遵循async。
3.动态加载
补录:
1.html 下载
2.解析成dom树
3.下载dom中的资源
4.开始生成render树
render 树的生成 两个重要的元素: 1.link 2.script 遍历dom树遇到script 时 ,会加载script,然后执行他。 并且会立即把已经render的元素 paint到网页上。 有个前提,如果当前有正在下载的 link 则要等待下载完成,再来一次render 和paint。如果没有直接绘制已经render好的元素。 另外改script 标签的执行 会依赖于他上面的link标签的加载。就是说书写在改script 标签上面的link加载完成时,才能执行这个script里面的内容。 这是chrome 下的表现。 在ff下有一点不同,就是不需要等待还在下载的link,就会直接绘制。 (各有利弊吧,chrome 这样做 reflow可能会少。ff这样做 页面呈现快) 在所有的script 都执行完成后, DOMcontentload事件触发。 在所有的资源加载完成后 ,onload事件触发

