正则表达式
基础语法






什么是正则表达式
- 正则表达式就是为了
处理大量的字符串而定义的一套规则和方法。 - 通过定义的这些特殊符号的辅助,系统管理员就可以快速过滤(grep),替换(sed)或输出(awk)需要的字符串。
- Linux 正则表达式一般以行为单位处理文件数据的,文件数据

学正则的注意事项
-
Linux下普通命令无法使用正则表达式的,只能使用linux下的三个命令,结合正则表达式处理。
- sed
- grep
- awk
-
通配符是大部分普通命令都支持的,用于查找文件或目录
-
而正则表达式是通过三剑客命令在文件(数据流)中过滤内容的,注意区别
-
以及注意字符集,需要设置
LC_ALL=C,注意这一点很重要
关于字符集设置
LC_ALL=C
这个变量赋值的动作,是等于还原linux系统的字符集
因为我们系统本身是支持多语言的
德文
英文
中文
每一个语言都有其特有的语言,字符,计算机为了统一字符,生成了编码表
比如你平时喜欢让linux支持中文,如果你的系统编码是中文,很可能导致你的正则出错,因此要还原系统的编码
LANG='zh_CN.UTF-8'
执行一个还原本地所有编码信息的变量
LC_ALL=C
用法如下
[242-yuchao-class01 root ~]#export LC_ALL=C
linux通过如下变量设置程序运行的不同语言环境,如中文、英文环境
[root@yuchao-tx-server ~]# locale
LANG=en_US.UTF-8
LC_CTYPE="zh_CN.UTF-8"
LC_NUMERIC="zh_CN.UTF-8"
LC_TIME="zh_CN.UTF-8"
LC_COLLATE="zh_CN.UTF-8"
LC_MONETARY="zh_CN.UTF-8"
LC_MESSAGES="zh_CN.UTF-8"
LC_PAPER="zh_CN.UTF-8"
LC_NAME="zh_CN.UTF-8"
LC_ADDRESS="zh_CN.UTF-8"
LC_TELEPHONE="zh_CN.UTF-8"
LC_MEASUREMENT="zh_CN.UTF-8"
LC_IDENTIFICATION="zh_CN.UTF-8"
LC_ALL=zh_CN.UTF-8
一般我们会使用$LANG变量来设置linux的字符集,一般设置为我们所在的地区,如zh_CN.UTF-8
[root@yuchao-tx-server ~]# echo $LANG
en_US.UTF-8
为了让系统能正确执行shell语句(由于自定义修改的不同语言环境,对一些特殊符号的处理区别,如中文输入法,英文输入法下的标点符号等,导致shell无法执行)
我们会使用如下语句,恢复linux的所有的本地化设置,恢复系统到初始化的语言环境。
[root@yuchao-tx-server ~]# export LC_ALL=C
通配符和正则的区别
1.从语法上就记住,只有awk、gred、sed才识别正则表达式符号、其他都是通配符
2.从用法上区分
- 表达式操作的是文件、目录名(属于是通配符)
- 表达式操作的是文件内容(正则表达式)
3.比如如下符号区别
通配符和正则表达式 都有 * ? [abcd] 符号
通配符中,都是用来标识任意的字符
如 ls *.log,可以找到a.log b.log ccc.log
正则中,都是用来表示这些符号前面的字符,出现的次数,如
grep 'a*'
正则表达式分类
使用正则表达式的问题是、有两大类正则表达式规范、linux不同的应用程序,会使用不同的正则表达式。
1 基本正则表达式(BRE、basic regular expression)
BRE对应元字符有
^ $ . [ ] *
其他符号是普通字符
; \
2 扩展正则表达式(ERE、extended regular expression)
ERE在在BRE基础上,增加了
( ) { } ? + | 等元字符
转义符
反斜杠 \
反斜杠用于在元字符前添加,使其成为普通字符
因为grep
awk
sed
在处理正则时,默认也只认识 基础正则表达式
如果你写了分区,或者,这样的符号,必须给grep,加上额外的参数,让它识别这些扩展正则
基本正则表达式
测试数据
[242-yuchao-class01 root ~]#cat -n t1.log
1 I am teacher yuchao.
2 I teach linux,python!
3
4 I like english
5
6 My website is http://yuchaoit.cn
7 Our school site is https://apecome.com
8 My qq num is 877348180
9
10 Good good study , day day up!
11
12
13 my name is wu yan zu .
grep与正则
grep '关键字,模式,正则表达式' 数据流
^m,以m开头的行
[242-yuchao-class01 root ~]#grep '^m' t1.log
my name is wu yan zu .
-n 显示行号
[242-yuchao-class01 root ~]#grep '^m' t1.log -n
13:my name is wu yan zu .
-o 只显示grep找出来的结果,而不是那一行所有的信息
[242-yuchao-class01 root ~]#grep '^m' t1.log -n -o
13:m
^ 尖角符
语法
写于最左侧,如
^yu 逐行匹配,找到以yu开头的内容
结合grep用法,-i 忽略大小写,可以找到更多的数据匹配
找出以yu开头的行
grep '^yu' t1.log -i
找出以m开头的行,且显示行号
[242-yuchao-class01 root ~]#grep '^m' t1.log -i -n
6:My website is http://yuchaoit.cn
8:My qq num is 877348180
13:my name is wu yan zu .
找出m或M开头的行
[242-yuchao-class01 root ~]#grep '^m' t1.log -i -n
6:My website is http://yuchaoit.cn
8:My qq num is 877348180
13:my name is wu yan zu .
只显示grep每次匹配到的结果,而不是匹配到的文本行数据
找出以my开头的行
[242-yuchao-class01 root ~]#grep '^my' t1.log -i -n -o
[242-yuchao-class01 root ~]#grep '^my' t1.log -i -n -o
6:My
8:My
13:my
[242-yuchao-class01 root ~]#grep '^my' t1.log -i -n
6:My website is http://yuchaoit.cn
8:My qq num is 877348180
13:my name is wu yan zu .
匹配出qq那一行
[242-yuchao-class01 root ~]#grep 'qq' t1.log
My qq num is 877348180
匹配行内容,且显示行号
找出包含i字符的行
grep 'i' t1.log
[242-yuchao-class01 root ~]#grep 'i' t1.log -n -o
2:i
4:i
4:i
6:i
6:i
6:i
7:i
7:i
8:i
13:i
找出以i开头的行
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#grep '^i' t1.log
[242-yuchao-class01 root ~]#grep '^i' t1.log -i
I am teacher yuchao.
I teach linux,python!
I like english
[242-yuchao-class01 root ~]#grep '^i' t1.log -i -n
1:I am teacher yuchao.
2:I teach linux,python!
4:I like english
找出以i开头的行,且只显示匹配内容
[242-yuchao-class01 root ~]#
[242-yuchao-class01 root ~]#grep '^i' t1.log
[242-yuchao-class01 root ~]#grep '^i' t1.log -i
I am teacher yuchao.
I teach linux,python!
I like english
[242-yuchao-class01 root ~]#grep '^i' t1.log -i -n
1:I am teacher yuchao.
2:I teach linux,python!
4:I like english
[242-yuchao-class01 root ~]#grep '^i' t1.log -i -n -o
1:I
2:I
4:I
$ 美元符
语法
word$ 匹配以word结尾的行
匹配所有以字符n结尾的行
[242-yuchao-class01 root ~]#grep 'n$' t1.log -n
6:My website is http://yuchaoit.cn
匹配所有以.结尾的行
[242-yuchao-class01 root ~]#grep '\.$' t1.log -n
1:I am teacher yuchao.
13:my name is wu yan zu .
单、双引号区别
-
单引号、所见即所得,可以用于匹配如标点符号,还原其本义。
-
双引号、能够识别linux的特殊符号、或变量,需要借助转义符还原字符本义。
-
当需要引号嵌套时,一般做法是,双引号,嵌套单引号
^$ 匹配空行
找出文件的空行
[242-yuchao-class01 root ~]#grep '^$' t1.log -n
3:
5:
9:
11:
12:
. 点符
. 匹配除了换行符以外所有的内容、字符+空格,除了换行符。
. 点处理空格
-
.可以匹配到空格,以及任意字符 -
以及拿不到空行
-
但是点,不匹配换行符。(拿不到换行符,什么意思?)
测试数据
cat -n t1.log
y
u
c
h
a o
验证点和换行、空格的关系
[242-yuchao-class01 root ~]#grep '.' t2.log -on
1:y
2:u
3:c
4:h
6:a
6:
6:o
. 匹配除换行符的所有字符
[242-yuchao-class01 root ~]#grep '.' t1.log -n
1:I am teacher yuchao.
2:I teach linux,python!
4:I like english
6:My website is http://yuchaoit.cn
7:Our school site is https://apecome.com
8:My qq num is 877348180
10:Good good study , day day up!
13:my name is wu yan zu .
.$ 匹配任意字符结尾
. 任意一个字符
.$ 任意字符结尾
拿到每一行的结尾的符号
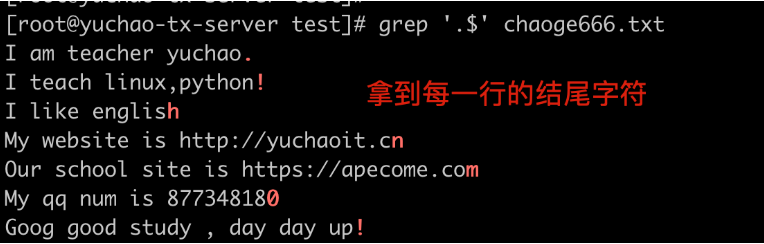
**. 和转义符**
只想拿到每一行结尾的普通小数点 .,需要对点转义

**\ 转义符**
转义字符,让有特殊意义的字符,现出原形,还原其本义。
如
. 还原为小数点
**换行符、制表符**
\b 匹配单词边界,如我想从字符串中“This is Regex”匹配单独的单词 “is” 正则就要写成 “\bis\b”
\n 匹配换行符 ,表示newline,向下移动一行,不会左右移动
\r 匹配回车符,表示return,回到当前行的最左边
linux换行符是\n,表示\r+\n 换行且回车,换行且回到下一行的行首
windows换行符是\r\n,表示回车+换行
\t 匹配一个横向的制表符,等于tab键
**星号**
重复前一个字符0此或n次
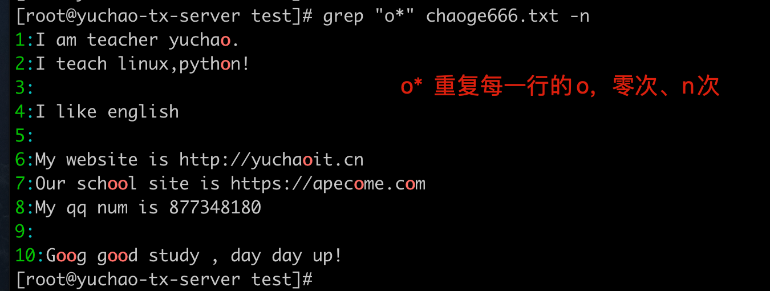
. 符*
匹配任意字符
.表示任意一个字符,*表示匹配前一个字符0次或多次
因此放一起,代表匹配每一行所有内容,包括空格
注意 . 点不匹配换行

图解点 . 不匹配换行
首先,不匹配换行这事,是因为 . 的作用
.* 是重复前面这个字符0次或N次

^.* 符
语法
^.* 表示以任意多个字符开头的行
基础用法,^.*

找出任意以字母i开头的行,且匹配后续所有内容

找出任意以字母i开头的行,且以h结尾的行

.*$ 符
以任意多个字符结尾的行

以p.*$结尾的行
等于、匹配出从p到结尾的所有内容

[ ] 中括号
[abc]
[abc] 匹配括号内的小写a、b、c字符

[a-z]、 [A-Z] 、[a-zA-z]、[0-9]
[a-z] 匹配所有小写单个字母
[A-Z] 匹配所有单个大写字母
[a-zA-Z] 匹配所有的单个大小写字母
[0-9] 匹配所有单个数字
[a-zA-Z0-9] 匹配所有数字和字母
[a-z] 匹配小写字母

[A-Z] 匹配大写字母

[a-z0-9] 匹配小写字母和数字

[0-9A-Z] 匹配大写字母和数字

[a-z0-9A-Z] 匹配大写、小写字母、数字

中括号取反
语法
[^abc] 排除中括号里的a、b、c ,和单独的^符号,作用是不同的
[^a-z] 排除小写字母

扩展正则------------------------------------------------------
{ } 花括号
a{n,m}
a\{n,m\} 重复字符a,n到m次
a\{1,3\} 重复字符a,1到3次
测试数据
[root@yuchao-tx-server test]# cat chaoge666.txt
I am teacher yuchao.
I teach linux,python!
I like english
My website is http://yuchaoit.cn
Our school site is https://apecome.com
My qq num is 877348180
my qq num is not 87777773333344444888811188880000
Goog good study , day day up!
8\{1,3\}
匹配数字8一次到3次

每次最少找出2个8、最多3个8
8\{2,3\}

grep 默认不认识扩展正则 {}
grep默认不认识扩展正则{},识别不到它的特殊作用,因此只能用转义符,让他成为有意义的字符。

办法1
使用转义符 \{\}
办法2,让grep认识花括号,可以省去转义符
使用egrep命令
或者 grep -E

a{n,}
重复a字符至少n次,可以用简写了

a{n}
重复字符a,正好n次。

a{,m}
匹配字符a最多m次

扩展正则表达式(ERE)
这样记忆就好
基本正则表达式
属于早期正则表达式,支持一些基本的功能
与grep、sed命令结合使用
扩展正则表达式
后来添加的正则表达式
和egrep、awk命令结合
+ 加号
语法
+
重复前一个字符1次或多次
注意和*的区别,*是0次或多次
匹配一次或者多次0,没有0的行是不会显示的
0+
找出一个、或者多个数字零

[0-9]+
从文中找出连续的数字,排除字母,特殊符号、空格

[a-z]+
找出连续的小写字母、排除大写字母、标点符号、数字

[A-Za-z0-9]+
注意,这里添加了+号,就是找的连续的字母数字了、缺少+号则是每次匹配单个字符

[^A-Za-z0-9]+]
此写法,找出除了数字、大小写字母以外的内容,如空格、标点符号。
你可以使用-o参数,看到每次匹配的内容。

*和+的区别
语法
*是重复0次、重复多次,因此没匹配到的行也过滤出来了
+是重复1次、多次、因此至少匹配到1次才看到
例如,我们来找到字母o,看如下2个写法

go*d和go+d和go?d区别
数据
[root@yuchao-tx-server test]# cat god.log
I am God, I need you to good good study and day day up, otherwise I will send you to see Gd,oh sorry, gooooooooood!
关于寻找god、goooood、gd的区别
go*d 可以有0个或者n个字母o
go*d 可以找到god、good、gd、gooooooooood
go+d 可以有一个或n个字母o
go+d 可以找到god、good、gooooooooood
go?d 可以有0个或者1个字母0
go?d 可以找到gd、god

| 或者符
竖线在正则里是或者的意思
查看内存信息

查看文件系统inode和block信息
ext4文件系统
[242-yuchao-class01 root ~]#dumpe2fs /dev/sdc |grep -Ei '^(inode|block)'
dumpe2fs 1.42.9 (28-Dec-2013)
Inode count: 1310720
Block count: 5242880
Block size: 4096
Blocks per group: 32768
Inodes per group: 8192
Inode blocks per group: 512
Inode size: 256
xfs文件系统
[242-yuchao-class01 root /mnt]#xfs_info /mnt |grep -E 'blocks.*imax.*|isize='
meta-data=/dev/sdd isize=512 agcount=4, agsize=3276800 blks
data = bsize=4096 blocks=13107200, imaxpct=25
找出文件中的空行以及注释行
测试数据
[root@yuchao-tx-server test]# cat chaoge666.txt
I am teacher yuchao.
I teach linux,python!
I like english
My website is http://yuchaoit.cn
Our school site is https://apecome.com
My qq num is 877348180
my qq num is not 87777773333344444888811188880000
#Goog good study , day day up!
#
#hello halo

( ) 括号、分组符
语法
() 作用是将一个或者多个字符捆绑在一起,当做一个整体进行处理
小括号功能之一是分组过滤被括起来的内容,括号内的内容表示一个整体
括号()内的内容可以被后面的"\n"正则引用,n为数字,表示引用第几个括号的内容
\1:表示从左侧起,第一个括号中的模式所匹配到的字符
\2:从左侧起,第二个括号中的模式所匹配到的字符
分组基本用法
测试数据
[root@yuchao-tx-server test]# cat god.log
I am God, I need you to good good study and day day up, otherwise I will send you to see Gd,oh sorry, gooooooooood!
I am glad to see you, god,you are a good god!
要求仅仅匹配出glad和good
可以使用分组写法
grep -iE "g(la|oo)d" god.log

分组与向后引用
语法
()
分组过滤,被括起来的内容表示一个整体,另外()的内容可以被后面的\n引用,n为数字,表示引用第几个括号的内容
\n
引用前面()里的内容,例如(abc)\1 表示匹配abcabc
测试数据
[root@yuchao-tx-server test]# cat lovers.log
I like my lover.
I love my lover.
He likes his lovers.
He love his lovers.
分组正则,提取love出现2次的行。
拆解
love,可以写为l..e

提取/etc/passwd
找出系统中几个特殊shell、专门用来开机,关机的用户
特点是、用户名、登录shell名字一样
可以用分区提取出

分组正则,提取特殊用户
这部分正则需要拆开,更容易理解
1.提取冒号以外的字符,使用+可以匹配更多字母,没必要每次只处理一个
grep -Ei "[^:]+" /etc/passwd
2. 使用\b匹配单词边界,提取出单词,示例用法,通常英文单词的边界是空格,标点符号
[root@yuchao-tx-server test]# echo 'my name is chao,everyone call me chaoge' | grep -Ei "chao\b" -o
chao
3.继续提取用户文件,来确定第一个单词的边界

更简单的写法,多次分组



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南