
前程无忧岗位数据爬取+Tableau可视化分析
一、项目背景
随着科技的不断进步与发展,数据呈现爆发式的增长,各行各业对于数据的依赖越来越强,与数据打交道在所难免,而社会对于“数据”方面的人才需求也在不断增大。因此了解当下企业究竟需要招聘什么样的人才?需要什么样的技能?不管是对于在校生,还是对于求职者来说,都显得十分必要。
对于一名小白来说,想要入门数据分析,首先要了解目前社会对于数据相关岗位的需求情况,基于这一问题,本文针对前程无忧招聘网站,利用python爬取了其全国范围内大数据、数据分析、数据挖掘、机器学习、人工智能等与数据相关的岗位招聘信息。并通过Tableau可视化工具分析比较了不同行业的岗位薪资、用人需求等情况;以及不同行业、岗位的知识、技能要求等。

二、数据爬取
- 爬取字段:岗位名称、公司名称、薪资水平、工作经验、学历需求、工作地点、招聘人数、发布时间、公司类型、公司规模、行业领域、福利待遇、职位信息;
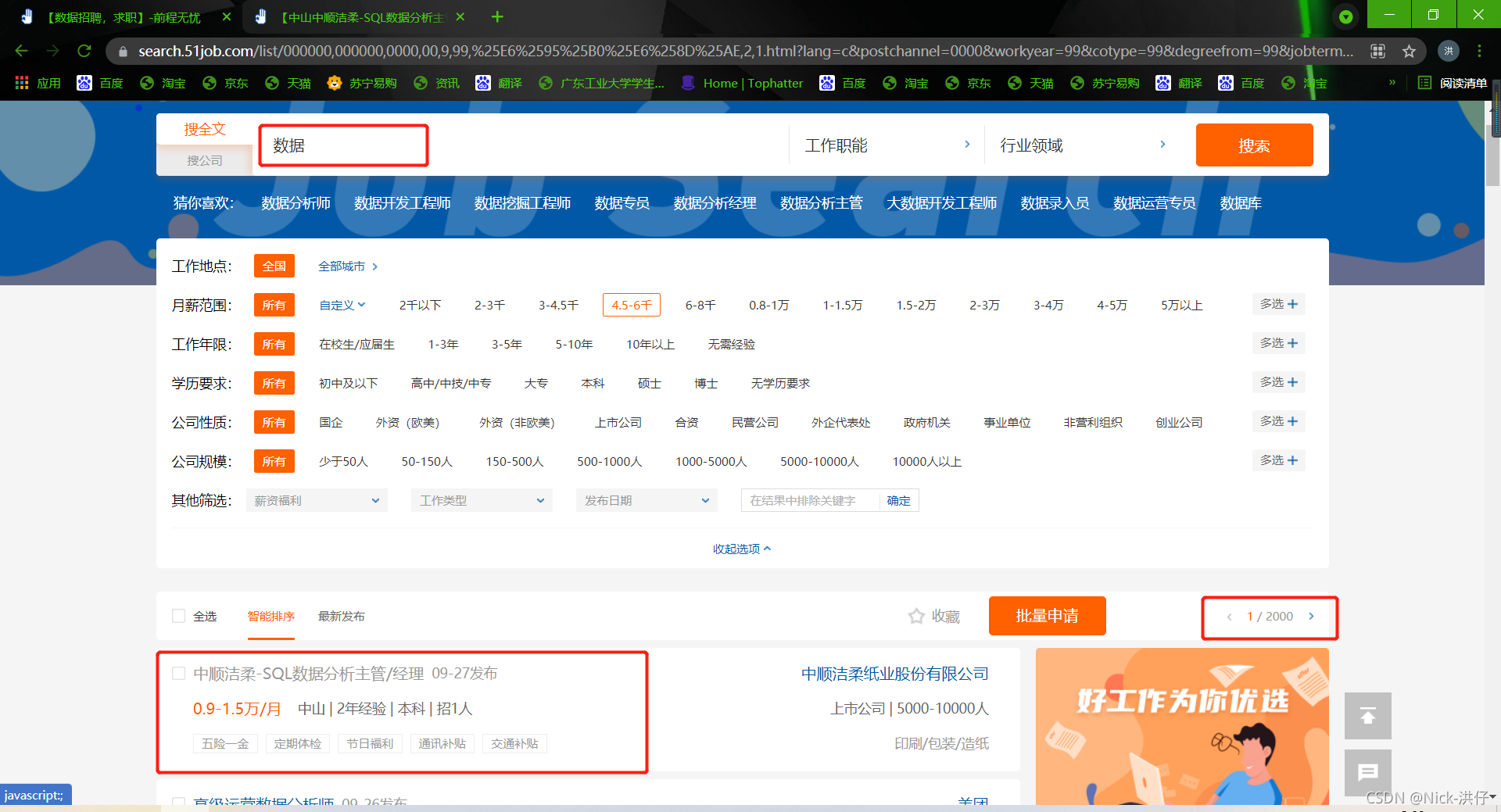
- 说明:在前程无忧招聘网站中,我们在搜索框中输入“数据”两个字进行搜索发现,共有2000个一级页面,其中每个页面包含50条岗位信息;
一级页面如下:
二级页面如下:
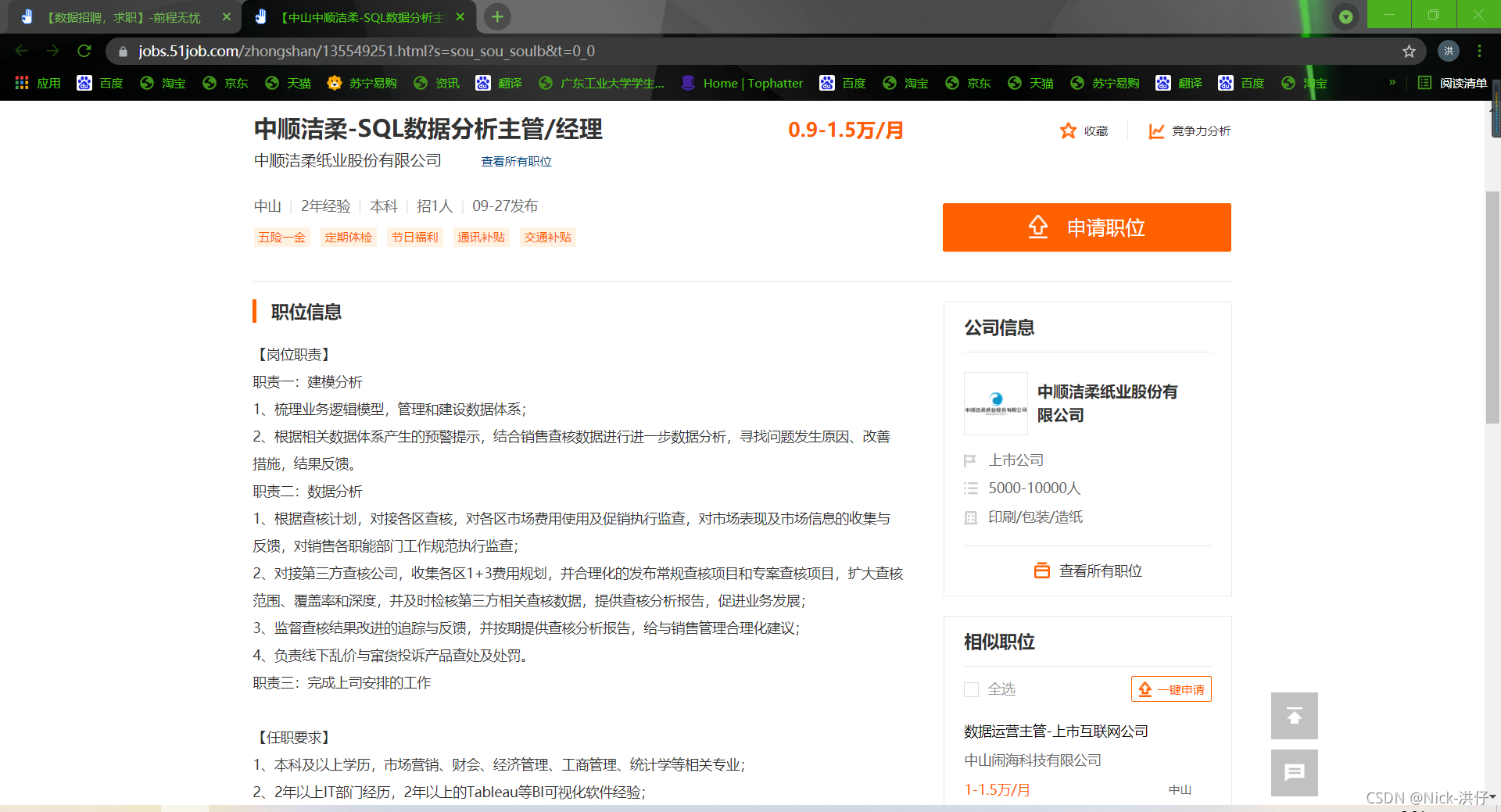
- 爬取思路:先针对一级页面爬取所有岗位对应的二级页面链接,再根据二级页面链接遍历爬取相应岗位信息;
- 开发环境:python3、Spyder
1、相关库的导入与说明
import json import requests import pandas as pd from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from lxml import etree from selenium.webdriver import ChromeOptions
由于前程无忧招聘网站的反爬机制较强,采用动态渲染+限制ip访问频率等多层反爬,因此在获取二级页面链接时需借助json进行解析,本文对于二级页面岗位信息的获取采用selenium模拟浏览器爬取,同时通过代理IP的方式,每隔一段时间换一次请求IP以免触发网站反爬机制。
2、获取二级页面链接
1)分析一级页面url特征
# 第一页URL的特征 "https://search.51job.com/list/000000,000000,0000,00,9,99,数据,2,1.html?" # 第二页URL的特征 "https://search.51job.com/list/000000,000000,0000,00,9,99,数据,2,2.html?" # 第三页URL的特征 "https://search.51job.com/list/000000,000000,0000,00,9,99,数据,2,3.html?"
通过观察不同页面的URL可以发现,不同页面的URL链接只有“.html”前面的数字不同,该数字正好代表该页的页码 ,因此只需要构造字符串拼接,然后通过for循环语句即可构造自动翻页。
2)构建一级url库
url1 = []
for i in range(2000):
url_pre = "https://search.51job.com/list/000000,000000,0000,00,9,99,数据,2,%s" % (1+i) #设置自动翻页
url_end = ".html?"
url_all = url_pre + url_end
url1.append(url_all)
print("一级URL库创建完毕")
注意:爬取二级URL链接时发现并非爬取的所有链接都是规范的,会存在少部分异常URL,这会对后续岗位信息的爬取造成干扰,因此需要利用if条件语句对其进行剔除。
三、数据清洗
1、数据读取、去重、空值处理
在获取了所需数据之后,可以看出数据较乱,并不利于我们进行分析,因此在分析前需要对数据进行预处理,得到规范格式的数据才可以用来最终做可视化数据展示。
获取的数据截图如下:

1)相关库导入及数据读取
#导入相关库 import pandas as pd import numpy as np import jieba #读取数据 df = pd.read_excel(r'E:\python爬虫\前程无忧招聘信息.xlsx',index_col=0)
2)数据去重与控制处理
- 对于重复值的定义,我们认为一个记录的公司名称和岗位名称一致时,即可看作是重复值。因此利用drop_duplicates()函数剔除所有公司名称和岗位名称相同的记录并保留第一个记录。
- 对于空值处理,只删除所有字段信息都为nan的记录。
#去除重复数据 df.drop_duplicates(subset=['公司名称','岗位名称'],inplace=True) #空值删除 df[df['公司名称'].isnull()] df.dropna(how='all',inplace=True)
3)岗位名称标准化处理
基于前面对“岗位名称”字段的统计情况,我们定义了目标岗位列表job_list,用来替换统一相近的岗位名称,之后,我们将“数据专员”、“数据统计”统一归为“数据分析”。
job_list = ['数据分析',"数据统计","数据专员",'数据挖掘','算法','大数据','开发工程师','运营',
'软件工程','前端开发','深度学习','ai','数据库','仓库管理','数据产品','客服',
'java','.net','andrio','人工智能','c++','数据管理',"测试","运维","数据工程师"]
job_list = np.array(job_list)
def Rename(x,job_list=job_list):
index = [i in x for i in job_list]
if sum(index) > 0:
return job_list[index][0]
else:
return x
job_info['岗位名称'] = job_info['岗位名称'].apply(Rename)
job_info["岗位名称"] = job_info["岗位名称"].apply(lambda x:x.replace("数据专员","数据分析"))
job_info["岗位名称"] = job_info["岗位名称"].apply(lambda x:x.replace("数据统计","数据分析"))
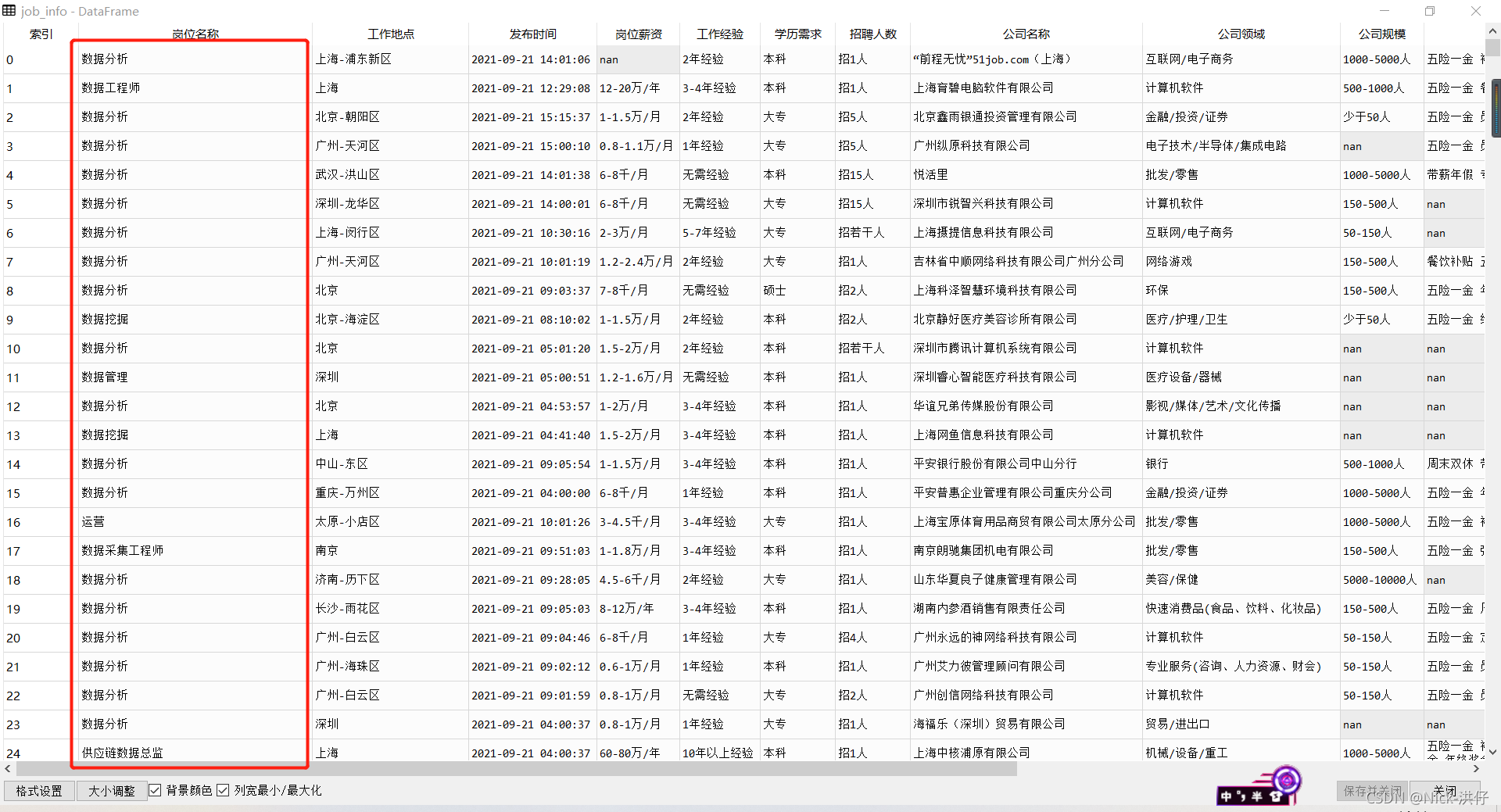
统一之后的“岗位名称”如下图所示:
import pandas as pd
import numpy as np
import jieba
#数据读取
df = pd.read_excel(r'E:\python爬虫\前程无忧招聘信息.xlsx',index_col=0)
#数据去重与空值处理
df.drop_duplicates(subset=['公司名称','岗位名称'],inplace=True)
df[df['招聘人数'].isnull()]
df.dropna(how='all',inplace=True)
#岗位名称字段处理
df['岗位名称'] = df['岗位名称'].apply(lambda x:x.lower())
counts = df['岗位名称'].value_counts()
target_job = ['算法','开发','分析','工程师','数据','运营','运维','it','仓库','统计']
index = [df['岗位名称'].str.count(i) for i in target_job]
index = np.array(index).sum(axis=0) > 0
job_info = df[index]
job_list = ['数据分析',"数据统计","数据专员",'数据挖掘','算法','大数据','开发工程师',
'运营','软件工程','前端开发','深度学习','ai','数据库','仓库管理','数据产品',
'客服','java','.net','andrio','人工智能','c++','数据管理',"测试","运维","数据工程师"]
job_list = np.array(job_list)
def Rename(x,job_list=job_list):
index = [i in x for i in job_list]
if sum(index) > 0:
return job_list[index][0]
else:
return x
job_info['岗位名称'] = job_info['岗位名称'].apply(Rename)
job_info["岗位名称"] = job_info["岗位名称"].apply(lambda x:x.replace("数据专员","数据分析"))
job_info["岗位名称"] = job_info["岗位名称"].apply(lambda x:x.replace("数据统计","数据分析"))
#岗位薪资字段处理
index1 = job_info["岗位薪资"].str[-1].isin(["年","月"])
index2 = job_info["岗位薪资"].str[-3].isin(["万","千"])
job_info = job_info[index1 & index2]
job_info['平均薪资'] = job_info['岗位薪资'].astype(str).apply(lambda x:np.array(x[:-3].split('-'),dtype=float))
job_info['平均薪资'] = job_info['平均薪资'].apply(lambda x:np.mean(x))
#统一工资单位
job_info['单位'] = job_info['岗位薪资'].apply(lambda x:x[-3:])
job_info['公司领域'].value_counts()
def con_unit(x):
if x['单位'] == "万/月":
z = x['平均薪资']*10000
elif x['单位'] == "千/月":
z = x['平均薪资']*1000
elif x['单位'] == "万/年":
z = x['平均薪资']/12*10000
return int(z)
job_info['平均薪资'] = job_info.apply(con_unit,axis=1)
job_info['单位'] = '元/月'
#工作地点字段处理
job_info['工作地点'] = job_info['工作地点'].apply(lambda x:x.split('-')[0])
#公司领域字段处理
job_info['公司领域'] = job_info['公司领域'].apply(lambda x:x.split('/')[0])
#招聘人数字段处理
job_info['招聘人数'] = job_info['招聘人数'].apply(lambda x:x.replace("若干","1").strip()[1:-1])
#工作经验与学历要求字段处理
job_info['工作经验'] = job_info['工作经验'].apply(lambda x:x.replace("无需","1年以下").strip()[:-2])
job_info['学历需求'] = job_info['学历需求'].apply(lambda x:x.split()[0])
#公司规模字段处理
job_info['公司规模'].value_counts()
def func(x):
if x == '少于50人':
return "<50"
elif x == '50-150人':
return "50-150"
elif x == '150-500人':
return '150-500'
elif x == '500-1000人':
return '500-1000'
elif x == '1000-5000人':
return '1000-5000'
elif x == '5000-10000人':
return '5000-10000'
elif x == '10000人以上':
return ">10000"
else:
return np.nan
job_info['公司规模'] = job_info['公司规模'].apply(func)
#公司福利字段处理
job_info['公司福利'] = job_info['公司福利'].apply(lambda x:str(x).split())
#职位信息字段处理
job_info['职位信息'] = job_info['职位信息'].apply(lambda x:x.split('职能类别')[0])
with open(r"E:\C++\停用词表.txt",'r',encoding = 'utf8') as f:
stopword = f.read()
stopword = stopword.split()
job_info['职位信息'] = job_info['职位信息'].apply(lambda x:x.lower()).apply(lambda x:"".join(x)).apply(lambda x:x.strip()).apply(jieba.lcut).apply(lambda x:[i for i in x if i not in stopword])
cons = job_info['公司领域'].value_counts()
industries = pd.DataFrame(cons.index,columns=['行业领域'])
industry = pd.DataFrame(columns=['分词明细','行业领域'])
for i in industries['行业领域']:
words = []
word = job_info['职位信息'][job_info['公司领域'] == i]
word.dropna(inplace=True)
[words.extend(str(z).strip('\'[]').split("\', \'")) for z in word]
df1 = pd.DataFrame({'分词明细':words,
'行业领域':i})
industry = industry.append(df1,ignore_index=True)
industry = industry[industry['分词明细'] != "\\n"]
industry = industry[industry['分词明细'] != ""]
count = pd.DataFrame(industry['分词明细'].value_counts())
lst = list(count[count['分词明细'] >=300].index)
industry = industry[industry['分词明细'].isin(lst)]
#数据存储
industry.to_excel(r'E:\python爬虫\数据预处理\词云.xlsx')
job_info.to_excel(r'E:\python爬虫\数据预处理\前程无忧(已清洗).xlsx')

