flink面试题
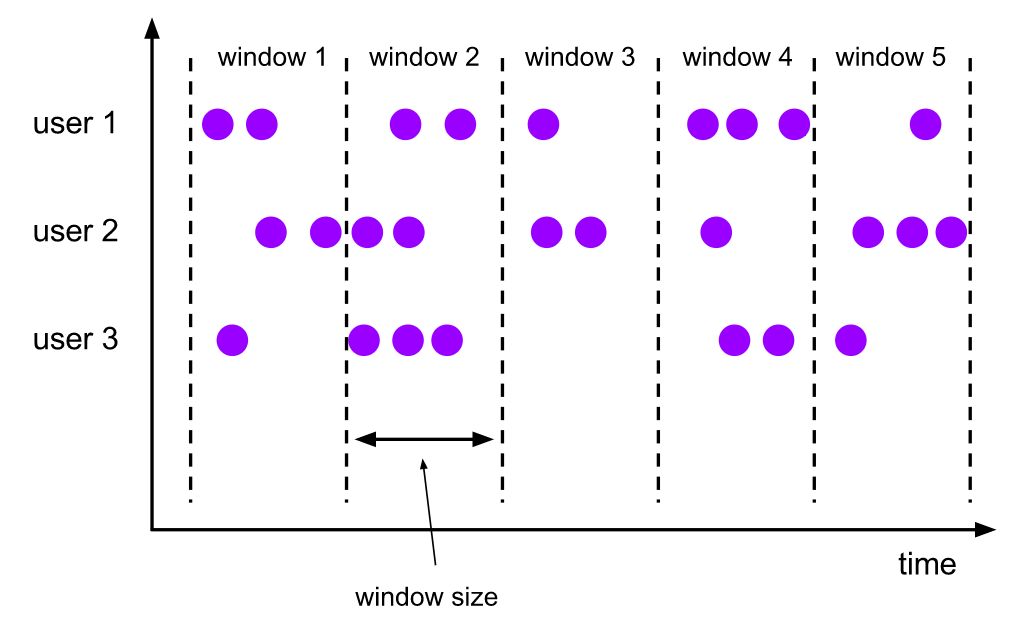
time-tumbling-window 无重叠数据的时间窗口,设置方式举例:timeWindow(Time.seconds(5))
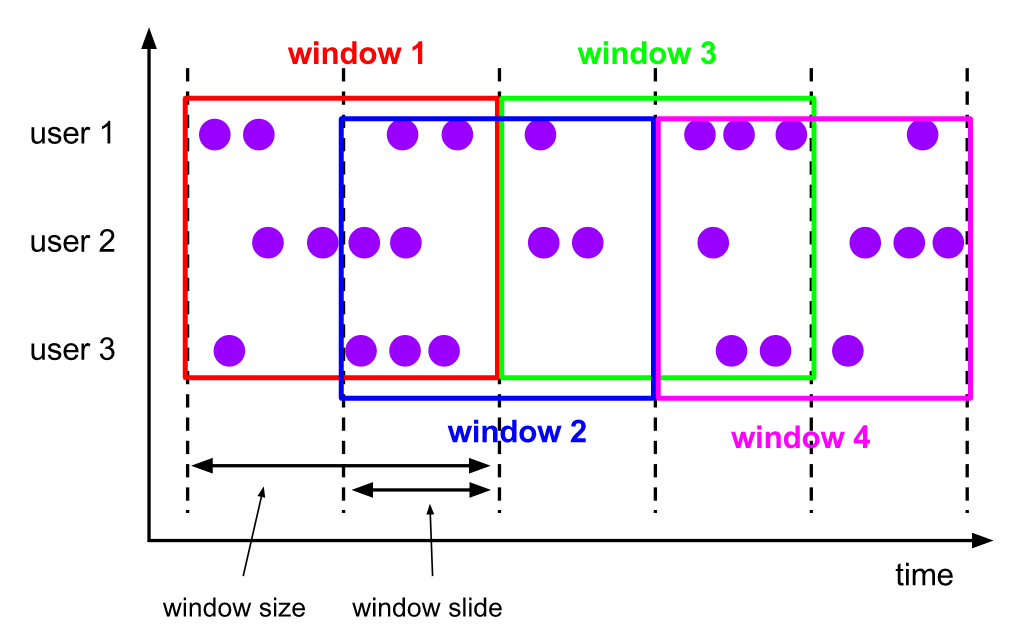
time-sliding-window 有重叠数据的时间窗口,设置方式举例:timeWindow(Time.seconds(5), Time.seconds(3))
count-tumbling-window无重叠数据的数量窗口,设置方式举例:countWindow(5)
count-sliding-window 有重叠数据的数量窗口,设置方式举例:countWindow(5,3)
17. 说说Flink中的状态存储?
Flink在做计算的过程中经常需要存储中间状态,来避免数据丢失和状态恢复。选择的状态存储策略不同,会影响状态持久化如何和 checkpoint 交互。Flink提供了三种状态存储方式:MemoryStateBackend、FsStateBackend、RocksDBStateBackend。
18. Flink中的时间有哪几类
Flink 中的时间和其他流式计算系统的时间一样分为三类:事件时间,摄入时间,处理时间三种。如果以 EventTime 为基准来定义时间窗口将形成EventTimeWindow,要求消息本身就应该携带EventTime。如果以 IngesingtTime 为基准来定义时间窗口将形成 IngestingTimeWindow,以 source 的systemTime为准。如果以 ProcessingTime 基准来定义时间窗口将形成 ProcessingTimeWindow,以 operator 的systemTime 为准。
19. Flink 中水印是什么概念,起到什么作用?
Watermark 是 Apache Flink 为了处理 EventTime 窗口计算提出的一种机制, 本质上是一种时间戳。 一般来讲Watermark经常和Window一起被用来处理乱序事件。
20. Flink Table & SQL 熟悉吗?TableEnvironment这个类有什么作用
TableEnvironment是Table API和SQL集成的核心概念。这个类主要用来:
在内部catalog中注册表
注册外部catalog
执行SQL查询
注册用户定义(标量,表或聚合)函数
将DataStream或DataSet转换为表
持有对ExecutionEnvironment或StreamExecutionEnvironment的引用
21. Flink SQL的实现原理是什么?是如何实现 SQL 解析的呢?
首先大家要知道 Flink 的SQL解析是基于Apache Calcite这个开源框架。
基于此,一次完整的SQL解析过程如下:
用户使用对外提供Stream SQL的语法开发业务应用
用calcite对StreamSQL进行语法检验,语法检验通过后,转换成calcite的逻辑树节点;最终形成calcite的逻辑计划
采用Flink自定义的优化规则和calcite火山模型、启发式模型共同对逻辑树进行优化,生成最优的Flink物理计划

 浙公网安备 33010602011771号
浙公网安备 33010602011771号