
flume原理
flume:是分布式、可靠、可用性好服务,用于收集、聚合、移动大量日志数据。是基于流计算的简单灵活框架,用于在线分析
stream:动态计算
flume优点:
1.可以和任意集中式存储进程集成
2.输入的数据速率大于写入存储目的地的速度,flume会进行缓冲
3.flume提供上下文路由(数据流路线)
4.flume中的事物基于channel,使用了两个事物模型(sender+receiver)确保消息被可靠发送
5.flume is reliable,fault tolerant,scalable,manageable,and customs
flume特点:
1.flume高效手机web,server的log到hdfs
2.可以高效获取输入
3.导入大量数据
4.flume支持大量的source和destination类型
5.flume支持多级跳跃、source和destination的fan in和fan out
6.flume可以水平伸缩
put问题:
1.同一时刻只能传输一个文件
2.put处理的静态文件
flume架构:
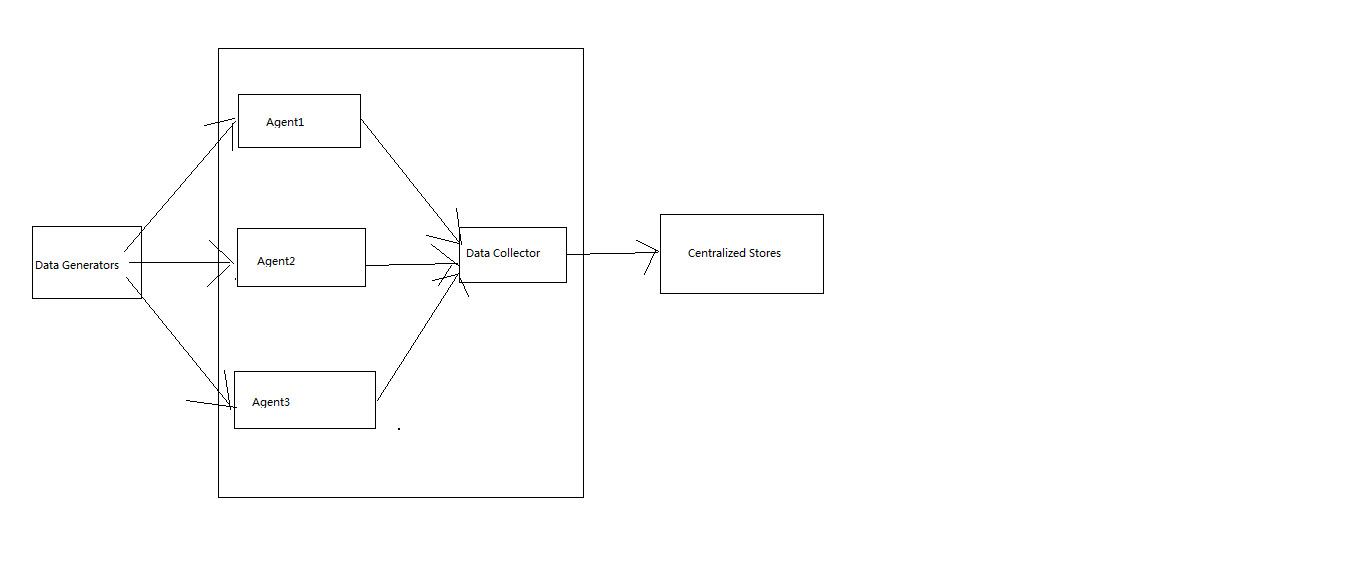
1.描述:在数据生成器运行的节点上启动单独的flume agent来收集数据。数据收集器收集数据,推送到hdfs
2.Fluem Event:事件是flume的传输单元。主要是byte[],可以含有一二写header信息。在source和destination之间
3.Flume agent:每个agent是一个独立的java进程,从客户端(其他agent)接受数据,然后转发到下一个destination(sink|agent)
agent包含三个组件
1.source
从事件源头生成器接受数据,传给agent的channel(多个或一个,以event事件的方式)
2.channel
从source中接受flume event,作为历史存放地,缓存到buffer中,直到sink将其消费掉,是source和sink的桥梁
channel是事务的,可以和多个source和sink协同
3.sink
存放数据到hdfs,hbase..从channel中消费event,并分发给destination,sink的destination也可以是另一个hdfs sink,hbase sink,AVro sink等
agent_nane.sources=r1,r2
agent_name.sinks=s1,s2
agent_name.channels=c1,c2
a1.sources=r1,r2
a1.sinks=s1,s2
a1.channels=c1,c2
#source-r1
a1.sources.r1.type=
a1.sources.r1.xxx=
a1.sources.r1.yyy=
#sink-s1
a1.sinks.s1.type=
a1.sinks.s1.xxx=
#channel-c1
a1.channels.c1.type=
a1.channels.c1.xxx=
#binding绑定
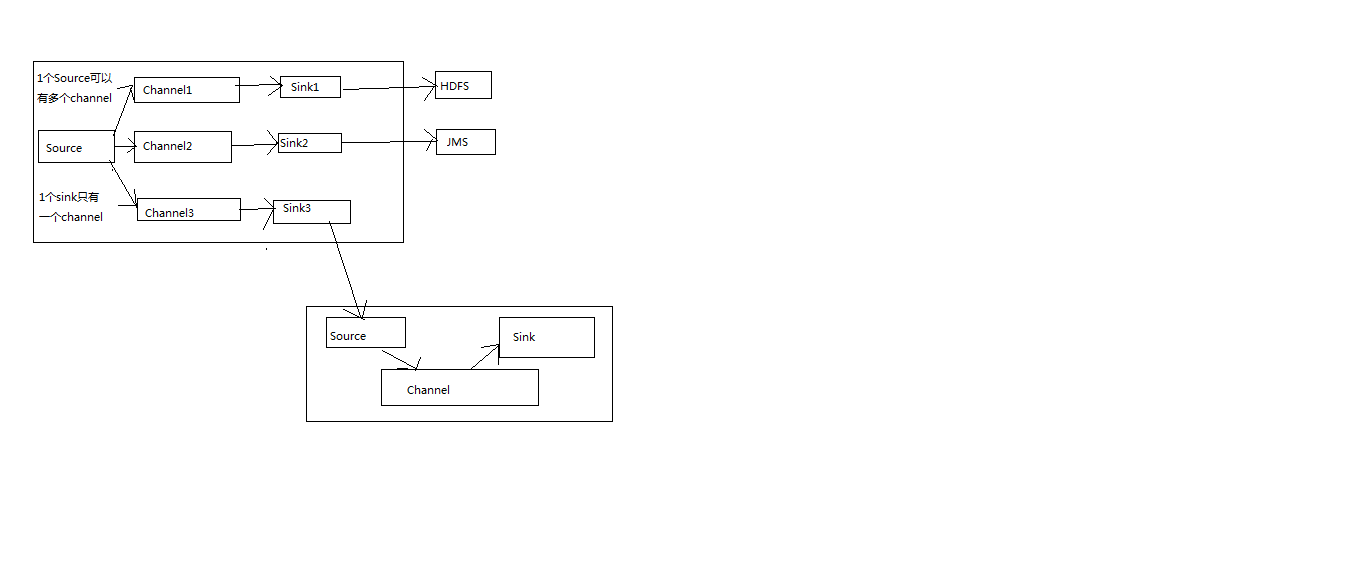
a1.sources.r1.channels=c1 -->一个source可以配置多个channels
a1.sinks.s1.channel=c1 -->一个sink只能配置一个channel
Flume外部结构:
Flume内部结构:

Flume流程:
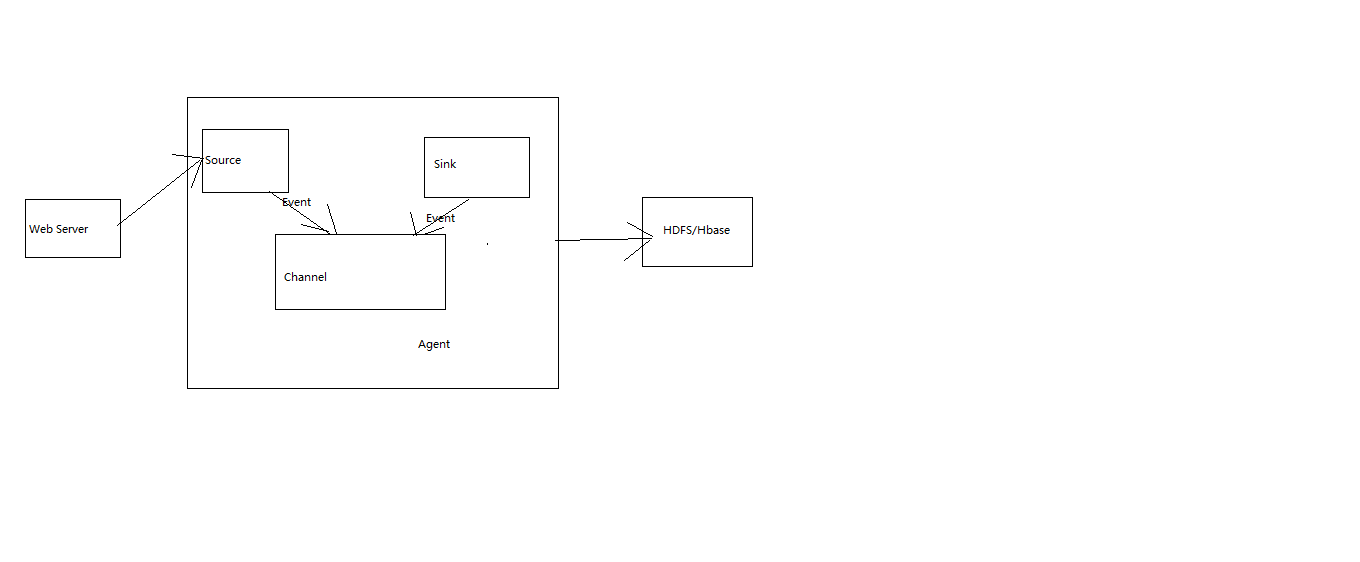
Agent结构:
Flume Event结构:

事件作为Flume内部数据传输的最基本单元.它是由一个转载数据的字节数组(该数据组是从数据源接入点传入,并传输给传输器,也就是HDFS/HBase)和一个可选头部构成.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号