用Python实现感知机 (python机器学习一)
0x01 感知机
感知机是一种二类分类的线性分类器,属于判别模型(另一种是生成模型)。简单地说,就是通过输入特征,利用超平面,将目标分为两类。感知机是神经网络和支持向量机的基础。
假设输入空间为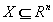 ,输出空间是
,输出空间是 .其中
.其中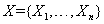 ,
,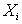 为一个特征向量,
为一个特征向量,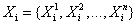 。
。
定义从输入空间到输出空间的函数: 为感知机。
为感知机。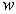 为感知机的权重,
为感知机的权重,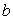 为偏置量,
为偏置量,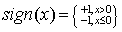 。
。
感知机最终得到的结果是通过一个超平面,将正实例点和负实例点区分开。对应于二维平面,即通过确定一条直线对分布于平面坐标系中的两种点进行区分,已达到给出一个点的坐标(特征向量),就能确定这个点的类别。
0x02 算法
监督学习有三大要素,模型,策略,和算法。我们采用的是感知机学习模型,下面我们说一下算法和学习策略。
具体步骤:
- 确定初始的
![]() 和
和![]() ;
; - 随机从训练样本中选取点
![]() ,预测值为
,预测值为![]() ;
; - 如果预测值不等于真实值,即
![]() ,更新
,更新![]() 和
和![]() ;
; - 重复步骤2、3,直到达到训练次数或小于指定误差;
- 输入未知点
![]() 的特征向量
的特征向量![]() ,
,![]() 。
。
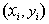 ,预测值为
,预测值为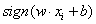 ;
;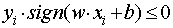 ,更新
,更新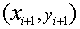 的特征向量
的特征向量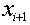 ,
,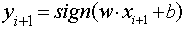 。
。而在第3步中如何更新和,则由学习策略来决定。这里我们的损失函数采用所有误分类点到超平面的总距离,即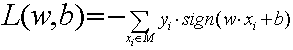 ,
,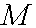 为误分类点的集合。根据最小梯度下降法,
为误分类点的集合。根据最小梯度下降法,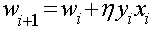 ,
,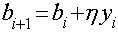 。这就是感知机学习模型的全部算法,下面用python来实现感知机。
。这就是感知机学习模型的全部算法,下面用python来实现感知机。
0x03 代码实现
首先定义符号函数:
1 # 符号函数 2 def sign(v): 3 if v > 0: 4 return 1 5 else: 6 return -1
训练函数:
1 def training(): 2 train_data1 = [[1, 3, 1], [2, 5, 1], [3, 8, 1], [2, 6, 1]] # 正样本 3 train_data2 = [[3, 1, -1], [4, 1, -1], [6, 2, -1], [7, 3, -1]] # 负样本 4 train_datas = train_data1 + train_data2 # 样本集 5 6 weight = [0, 0] # 权重 7 bias = 0 # 偏置量 8 learning_rate = 0.5 # 学习速率 9 10 train_num = int(raw_input("train num: ")) # 迭代次数 11 12 for i in range(train_num): 13 train = random.choice(train_datas) 14 x1, x2, y = train 15 predict = sign(weight[0] * x1 + weight[1] * x2 + bias) # 输出 16 print("train data: x: (%d, %d) y: %d ==> predict: %d" % (x1, x2, y, predict)) 17 if y * predict <= 0: # 判断误分类点 18 weight[0] = weight[0] + learning_rate * y * x1 # 更新权重 19 weight[1] = weight[1] + learning_rate * y * x2 20 bias = bias + learning_rate * y # 更新偏置量 21 print("update weight and bias: "), 22 print(weight[0], weight[1], bias) 23 24 print("stop training: "), 25 print(weight[0], weight[1], bias) 26 27 return weight, bias
测试函数:
1 # 测试函数 2 def test(): 3 weight, bias = training() 4 while True: 5 test_data = [] 6 data = raw_input('enter test data (x1, x2): ') 7 if data == 'q': break 8 test_data += [int(n) for n in data.split(',')] 9 predict = sign(weight[0] * test_data[0] + weight[1] * test_data[1] + bias) 10 print("predict ==> %d" % predict)
0x04 总结
感知机是神经网络和支持向量机的基础,实现起来并不难,但是涉及到很多思想。接下来会写写k-近邻算法。
本人也是机器学习新手,上面的介绍都是我在学习过程中的总结,如有不正确的地方,欢迎指正。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号