
第一次个人编程作业
| 这个作业属于哪个课程 | 软件工程2024-双学位 (广东工业大学) |
|---|---|
| 这个作业要求在哪里 | 个人项目作业-论文查重 |
| 这个作业的目标 | 完成个人编程作业编码部分 |
GitCode链接
https://gitcode.com/Starseon/cdf/blob/main/3121005947/CheckRepetition/main.py
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 5 | 10 |
| · Estimate | · 估计这个任务需要多少时间 | 5 | 10 |
| Development | 开发 | 406 | 748 |
| · Analysis | · 需求分析 (包括学习新技术) | 240 | 420 |
| · Design Spec | · 生成设计文档 | 10 | 15 |
| · Design Review | · 设计复审 | 3 | 3 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 3 | 10 |
| · Design | · 具体设计 | 10 | 20 |
| · Coding | · 具体编码 | 120 | 200 |
| · Code Review | · 代码复审 | 10 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 10 | 60 |
| Reporting | 报告 | 50 | 70 |
| · Test Report | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 30 |
| 合计 | 461 | 828 |
模块接口的设计与实现过程
1. 使用difflib模块来进行对比
difflib的作用是对比文本之间的差异。并且支持输出可读性比较强的HTML文档,而且支持生成差异报告和对比度:
import difflib
# 创建一个SequenceMatcher对象
sm = difflib.SequenceMatcher(None, a, b)
with open(paths.path3, 'w', encoding='utf-8') as fp:
similarity = sm.ratio()
print('差异报告:', file=fp)
print(f'相似度:{similarity:.2f}', file=fp)
fp.close()
2. 使用命令行来运行程序
我这里选用的是argparse模块,主要作用就是允许用户在命令行内执行程序,同时输入程序所需要的参数:
import difflib
# 命令行输入文件路径
parser = argparse.ArgumentParser(description='命令行传入文件路径')
parser.add_argument('path1', type=str, help='原文文件')
parser.add_argument('path2', type=str, help='抄袭版的论文文件')
parser.add_argument('path3', type=str, help='答案文件')
paths = parser.parse_args()
三个add_argument分别代表原文文件、抄袭版的论文文件和答案文件。用户必须输入这三个参数才能运行程序。
3. 写入文件
使用open()函数来读取文件:
# 读取path1和path2的文件
with open(paths.path1, 'r', encoding='utf-8') as file1:
a = file1.read()
with open(paths.path2, 'r', encoding='utf-8') as file2:
b = file2.read()
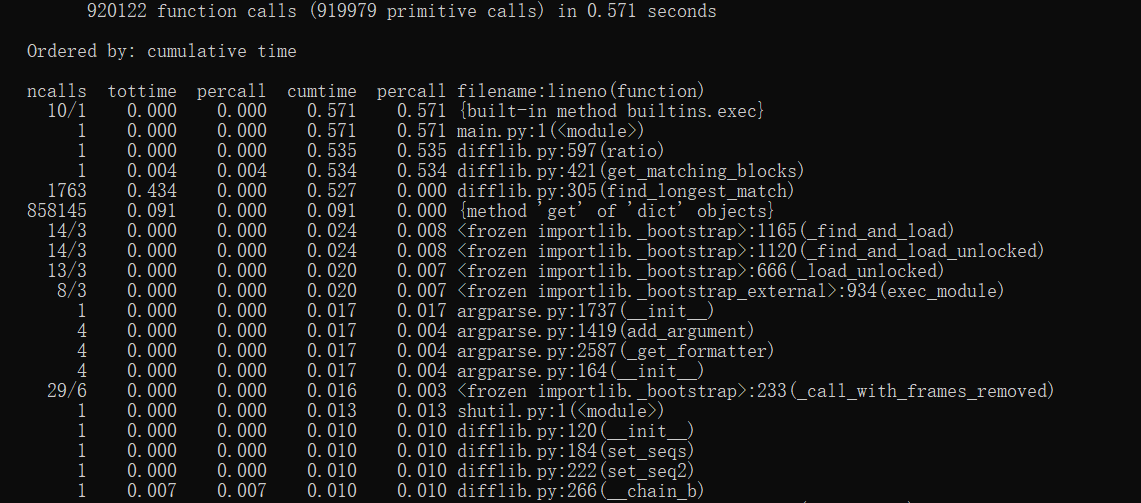
计算模块接口部分的性能
异常处理
在进行单元测试时,发现如果path1和path2的路径输入错误,会相应的在代码内的open()函数中报错,所以为了防止输入错误导致报错,我添加了几个条件判断来确保path路径输入错误时会提示玩家错误信息,正确时则会正常输出。若path3输入错误,则会新生成一个txt文件来保存答案。
import os.path
if os.path.isfile(paths.path1):
with open(paths.path1, 'r', encoding='utf-8') as file1:
a = file1.read()
else:
print('path1的路径错误或不存在')
if os.path.isfile(paths.path2):
with open(paths.path2, 'r', encoding='utf-8') as file2:
b = file2.read()
else:
print('path2的路径错误或不存在')
if os.path.isfile(paths.path1) & os.path.isfile(paths.path2):
# 创建一个SequenceMatcher对象
sm = difflib.SequenceMatcher(None, a, b)
# 计算并打印两篇文章的相似度
with open(paths.path3, 'w', encoding='utf-8') as fp:
similarity = sm.ratio()
print('差异报告:', file=fp)
print(f'相似度:{similarity:.2f}', file=fp)
fp.close()

合并代码
import difflib # 导入查重包
import argparse # 导入命令行包
import os.path
# 命令行输入文件路径
parser = argparse.ArgumentParser(description='命令行传入文件路径')
parser.add_argument('path1', type=str, help='原文文件')
parser.add_argument('path2', type=str, help='抄袭版的论文文件')
parser.add_argument('path3', type=str, help='答案文件')
paths = parser.parse_args()
# 读取path1和path2的文件
if os.path.isfile(paths.path1):
with open(paths.path1, 'r', encoding='utf-8') as file1:
a = file1.read()
else:
print('path1的路径错误或不存在')
if os.path.isfile(paths.path2):
with open(paths.path2, 'r', encoding='utf-8') as file2:
b = file2.read()
else:
print('path2的路径错误或不存在')
if os.path.isfile(paths.path1) & os.path.isfile(paths.path2):
# 创建一个SequenceMatcher对象
sm = difflib.SequenceMatcher(None, a, b)
# 计算并打印两篇文章的相似度
with open(paths.path3, 'w', encoding='utf-8') as fp:
similarity = sm.ratio()
print('差异报告:', file=fp)
print(f'相似度:{similarity:.2f}', file=fp)
fp.close()

