数组与链表(单链表与双链表的区别)
链表跟数组的区别:
数组随机访问性强(通过下标进行快速定位),查找速度快;链表不能随机查找,必须从第一个开始遍历,查找效率低
数组插入和删除效率低(插入和删除需要移动数据),链表插入删除速度快(因为有next指针指向其下一个节点,通过改变指针的指向可以方便的增加删除元素)
数组浪费内存(每次创建数组之前必须规定数组的大小,静态分配内存,大小固定),链表内存利用率高,不会浪费内存(可以使用内存中的不连续空间,并且可以动态括展空间)
数组利用下标定位,时间复杂度为O(1),链表定位元素时间复杂度O(n);
数组插入或删除元素的时间复杂度O(n),链表的时间复杂度O(1)。
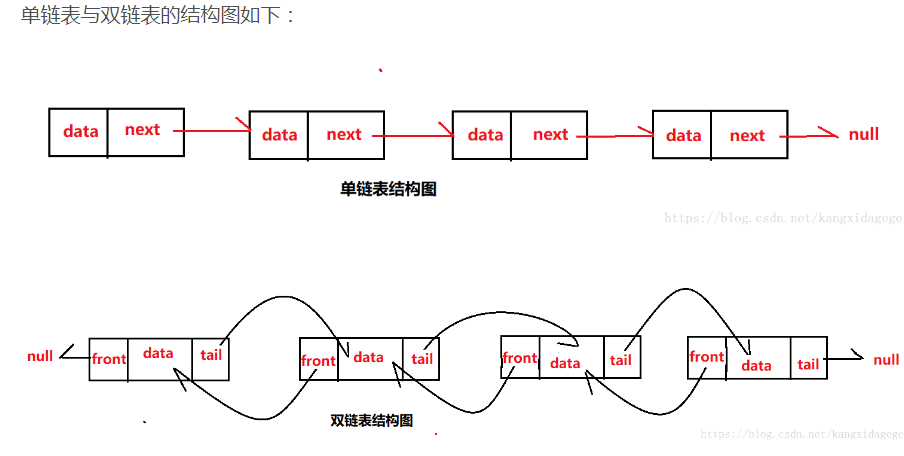
单链表和双链表的区别:
单链表只有一个指向下一结点的指针,也就是只能next(单链表只能单向读取)
双链表除了有一个指向下一结点的指针外,还有一个指向前一结点的指针,可以通过prev()快速找到前一结点
1、删除单链表中的某个结点时,一定要得到待删除结点的前驱(加待删除节点),得到该前驱有两种方法,第一种方法是在定位待删除结点的同时一路保存当前结点的前驱。第二种方法是在定位到待删除结点之后,重新从单链表表头开始来定位前驱。尽管通常会采用方法一。但其实这两种方法的效率是一样的,指针的总的移动操作都会有2*i次。而如果用双向链表,则不需要定位前驱结点。因此指针总的移动操作为i次。
2、查找时也一样,我们可以借用二分法的思路,从中间节点开始前后同时查找,这样双链表的效率可以提高一倍。
可是为什么市场上单链表的使用多余双链表呢?
从存储结构来看,每个双链表的节点要比单链表的节点多一个指针(多存放一个引用),这在一些追求时间效率不高应用下并不适应,因为它占用空间比较大;这时设计者就会采用以时间换空间的做法,选取单链表,这时一种工程总体上的衡量。
转载:https://blog.csdn.net/kangxidagege/article/details/80211225

 浙公网安备 33010602011771号
浙公网安备 33010602011771号