
一文让你从此告别HTTP乱码(二)Response篇
概述
开发Web项目的过程中,经常遇到浏览器中显示的内容乱码,或者服务器获取浏览器请求参数时乱码的问题,很多同学基本都是在遇到乱码的时候去网上一顿搜索,然后看哪篇文章比较靠谱就照着上面的内容去配后乱码成功消失了,然后就没然后了...
最后基本只是停留在知道怎么样设置能避免常见的乱码问题,而不知道具体的原理,一旦遇到了网上查不到的乱码场景就不知道如何解决了~
本文会深入的让你了解针对于HTTP请求时,这一去一回(Request,Response)之间,到底做了怎样的事情,让你彻底告别Web项目中的乱码烦恼。本文的内容是基于Tomcat 8.0.23版本的,其他容器也可以参考本文的内容,毕竟理论都是通的~
Response乱码
当你在浏览器中看到响应的内容是乱码的时候,第一反应就是,是不是我程序的问题,是不是我程序吐出的内容就是个乱码,所以才导致了浏览器里面看到了乱码。那么接下来我将带你过一遍Response的过程,以及对刚才的猜测进行验证~
首先,我建了一个非常简单的Web项目,里面只有一个Servlet,作用是直接返回我要响应的内容~
项目结构如下:

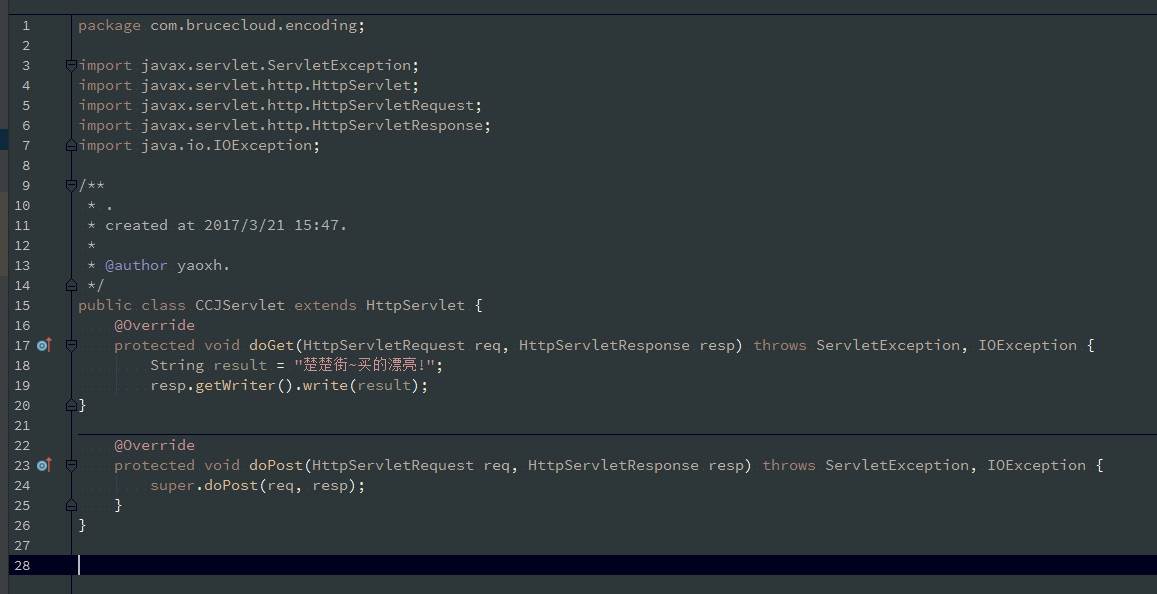
Servlet内容如下:
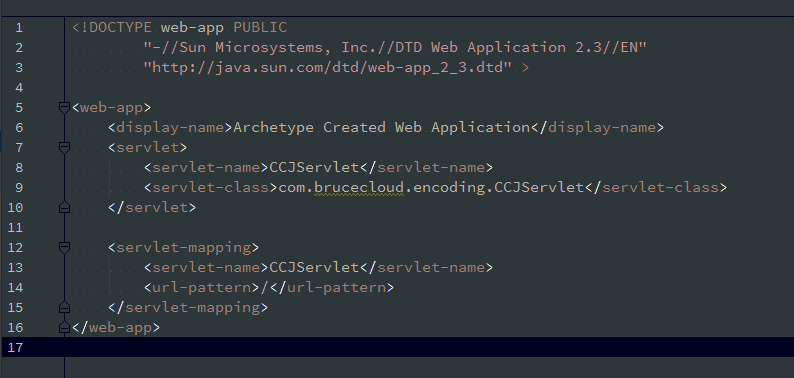
web.xml内容如下:
接下来我们在浏览器中访问:http://localhost:8080
首先在Firefox中访问,结果如下:

接下来再在QQ Browser中访问,结果如下:
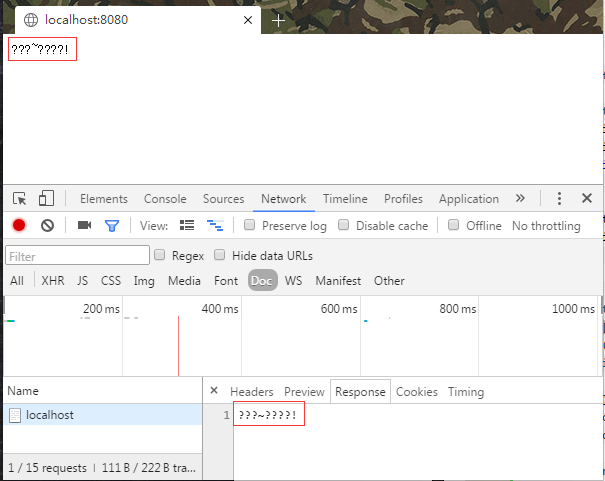
此时我们看见2个浏览器中展示的内容无论是浏览器正文还是下面的Response标签中显示的字符都是乱码,并且是相同的乱码内容~
那么这个乱码是怎么产生的呢?回头再去看我们servlet中的代码:

代码中可以看见我们没有指定任何的编码相关内容,那么Tomcat在将result字符串转换成字节数组时会使用HTTP规范的默认编码ISO-8859-1,于是输出的内容就是将result进行ISO-8859-1编码后的字节数组,
因为ISO-8859-1能表示的字符数量有限,它无法表示中文,所以在此时Response的内容与就已经是乱码了。
然后Response到达浏览器,浏览器会获取Response中的内容,因为Response中的响应头中没有指定信息的编码类型,所以浏览器会尝试根据编码规则进行推测,并根据推测进行解码,由于我使用的是中文系统,Firefox
的正文部分采用的是GBK编码,而Response中的内容则使用了UTF-8编码。QQ Browser正文部分使用的也是GBK编码,而Resopnse中的内容则使用了ISO-8859-1编码(不同浏览器,或者同一个浏览器的不同版本解码使用的编码都可能会不一样),
解码之后就是我所看见的 ???~????! 乱码了。
下面这段程序就可以验证上面的内容:
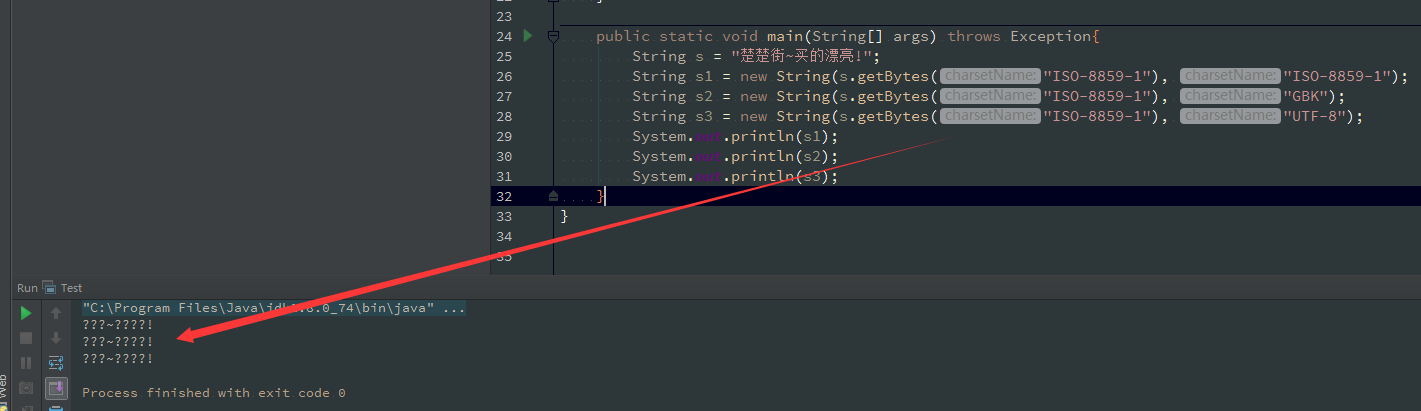
上面的验证本质上是因为在Servlet中处理Response的时候没有指定编码,从而导致了使用了默认的ISO-8859-1对Response的内容(楚楚街~卖得漂亮!)进行了编码,但是因为ISO-8859-1无法表示中文,结果在Servlet编码
时就已经产生了乱码,之后无论你怎么解码它都是个乱码。
接下来我们改进下Servlet,使其在Response的时候使用UTF-8(因为UTF-8可以表示中文)进行编码,代码如下:

然后我们再次请求http://localhost:8080
Firefox结果如下:
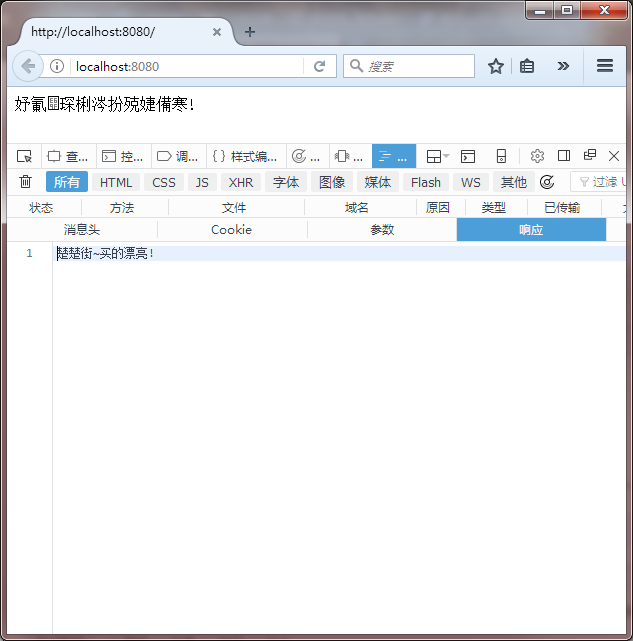
QQ Browser结果如下:
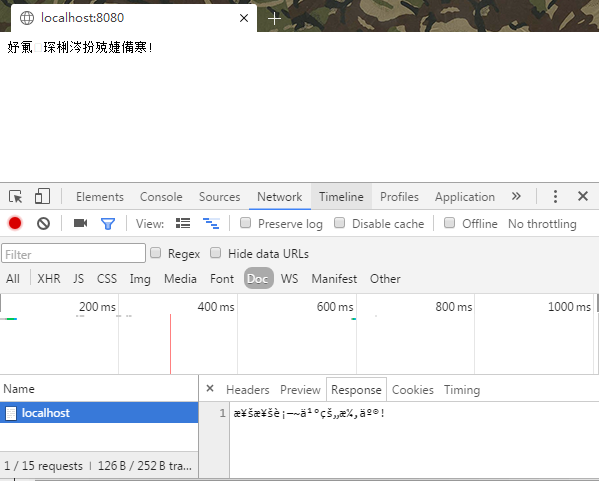
从结果我们可以看出,Firefox中正文依然乱码,而Response的内容正确解析了,而QQ Browser中正文和Response中的内容都是乱码。
根据之前的分析,我们已经知道Firefox的正文是GBK编码,Response内容是UTF-8编码,而QQ Browser中的正文也是GBK编码,Response的内容是ISO-8859-1编码。
下面代码对上面的内容进行了验证:
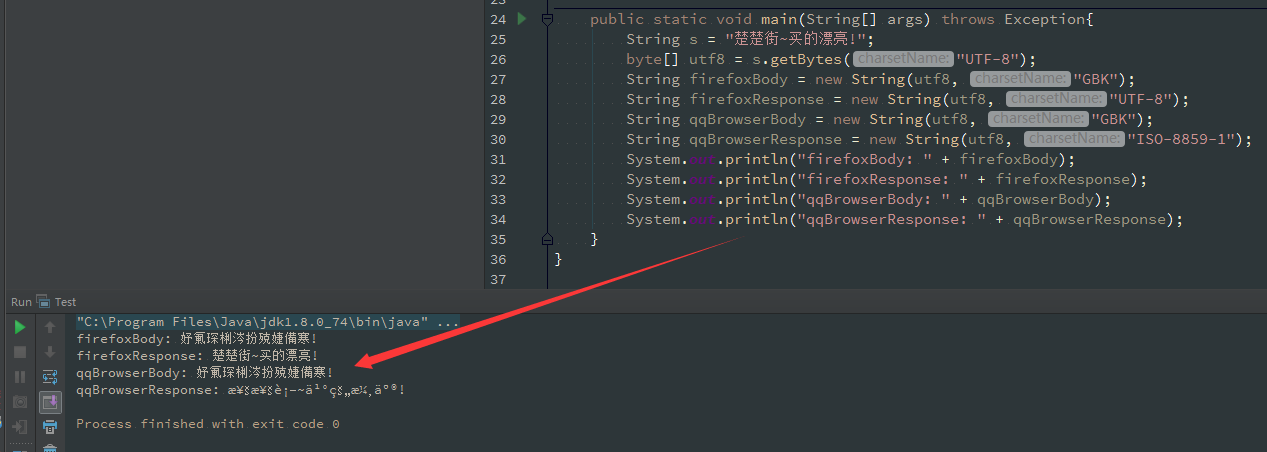
我们在对Servlet返回给2个浏览器的Response进行一下抓包,看下Response的内容到底是啥~
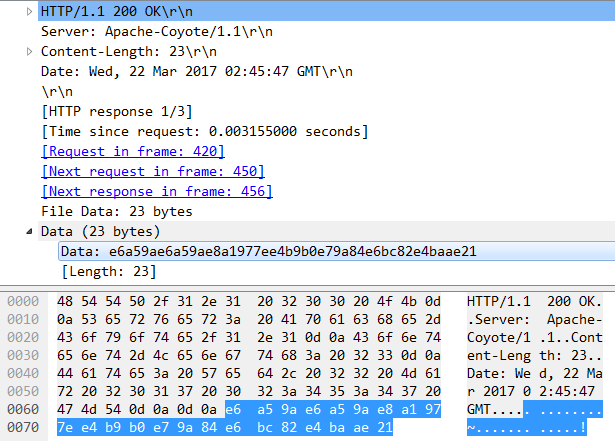
对Firefox的抓包:
对QQ Browser的抓包:
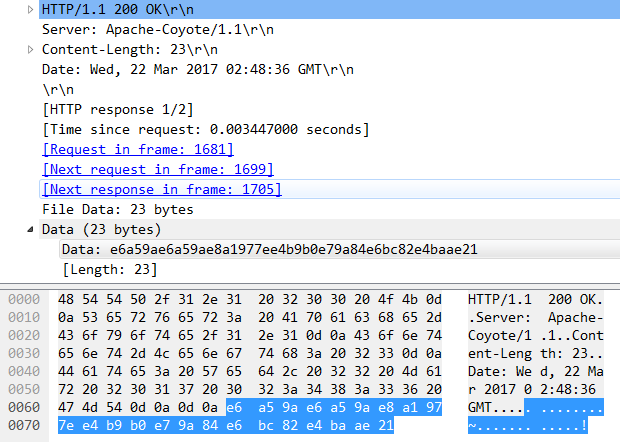
从结果我们可以看到2个浏览器收到的Response的结果都是相同的,其中Data部分都是e6a59ae6a59ae8a1977ee4b9b0e79a84e6bc82e4baae21,这串值就是
对 楚楚街~买的漂亮! 进行UTF-8编码后的值。
到此为止,做一个小总结:
1.Response在返回前会对要返回的内容做编码,在不指定(setCharacterEncoding("UTF-8"))的情况下会使用默认的ISO-8859-1编码。
2.不同的浏览器在收到返回的Response时,获取到的内容是一致的,之后浏览器会根据自身的策略对内容进行解析。
继续上面的乱码问题,为什么这次使用UTF-8对中文进行了编码后,浏览器里面依然是乱码呢?原因就是在Response中没有对响应的内容使用的是哪种编码做说明,导致了
浏览器不知道使用哪种编码做解码,然后就使用了浏览器默认的解码行为进行解码,从而导致了乱码。
接下来我们为Response加上响应头Content-Type:text/plain; charset=utf-8来告诉浏览器,Response内容应该用什么编码来解码,代码如下:

上面的代码中,我们指定了2次编码并且2次的编码不一致,那么到底会使用哪个编码呢?还会出现乱码么?看实际结果说话~
Firefox结果:
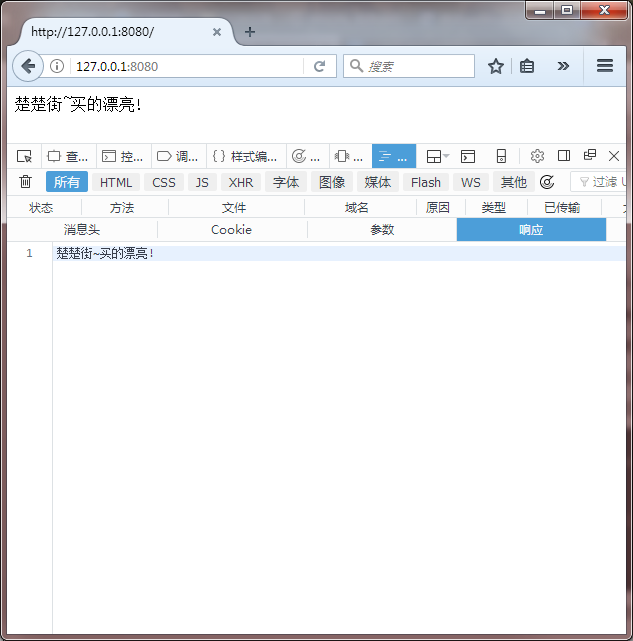
QQ Browser结果:
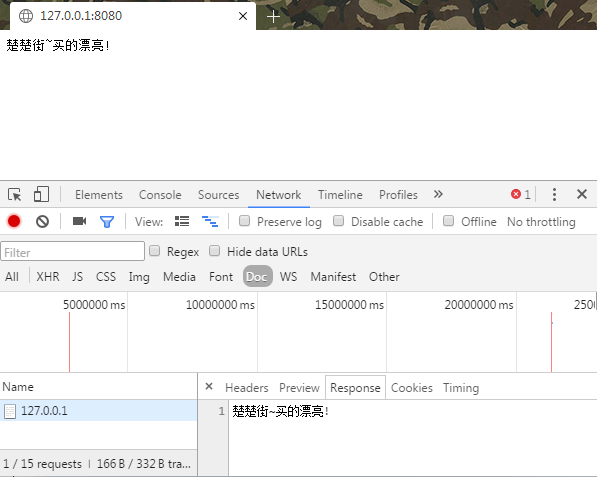
我们可以看到,2个浏览器无论是正文部分还是Response的内容中都正确的解码了~
总结:
1.Response需要告知浏览器使用哪一种编码来解码其内容。
2.Response所使用的编码为最后一次设置的编码,也就是说后面的编码设置信息会覆盖掉前面的编码设置信息。
接下来我们再来使用命令行来请求下试试,如下图:
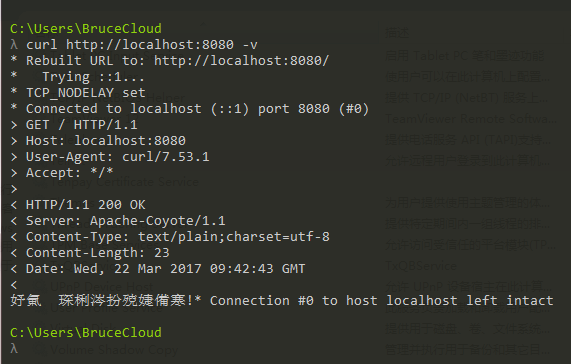
发现结果居然是乱码,难道之前的结论是错误的?什么鬼...
其实之前的结论并没错,而是之前的结论需要加个限定条件(只适用于浏览器),我们把HTTP请求的Response可以划分为2个步骤,第一步是获取到这个Response,第二步就是对
这个Response进行解析,上面的问题就出现在了第二步(解析)。因为浏览器是遵循HTTP规范的,HTTP规范中说明了响应头中的Content-Type属性中的charset指定的编码就是Response
中内容的实际编码,所以浏览器会使用这个charset中指定的编码对Response中的内容进行解码,那么自然没问题了,而命令行则不需要遵循HTTP中的规范,所以命令行并没有关心charset指定
的内容,而是使用命令行默认的编码进行解码的,所以导致了乱码,知道了问题的根本原因,那么是不是我们改变了命令行的编码就可以正确显示了呢?看下面结果:
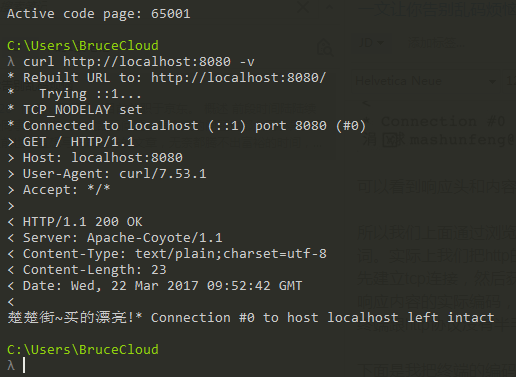
首先我们修改了命令行的编码为UTF-8(chcp 65001),然后重新请求后,发现显示正常了~
到此为止~Response时的乱码问题成功解决啦~
Response乱码总结:
1.Response在返回前会对要返回的内容做编码,在不指定编码的情况下会使用默认的ISO-8859-1编码。
2.不同的浏览器在收到返回的Response时,获取到的内容是一致的,之后浏览器会根据自身的策略对内容进行解析。
3.Response需要告知浏览器使用哪一种编码来解码其内容。
4.Response所使用的编码为最后一次设置的编码,也就是说后面的编码设置信息会覆盖掉前面的编码设置信息。
5.浏览器会遵循HTTP规范,使用Content-Type属性中的charset指定的编码去解码,而命令行工具则不会关注charset的内容,而是根据命令行自身的编码方案进行解码。
至此,一文让你从此告别HTTP乱码系列文章全部结束了~希望对遇到乱码的同学有所帮助,哪怕只有一点点~
附上上一篇文章的连接:一文让你从此告别HTTP乱码(一)Request篇

 浙公网安备 33010602011771号
浙公网安备 33010602011771号