

zset是一个符合结构,一方面需要一个hash结构来存储value和score的关系,另一方面需要提供按照score的排序,还需要能够指定score的范围来获取value列表的功能,这需要跳表结构来支持,即skiplist。
【基本结构】
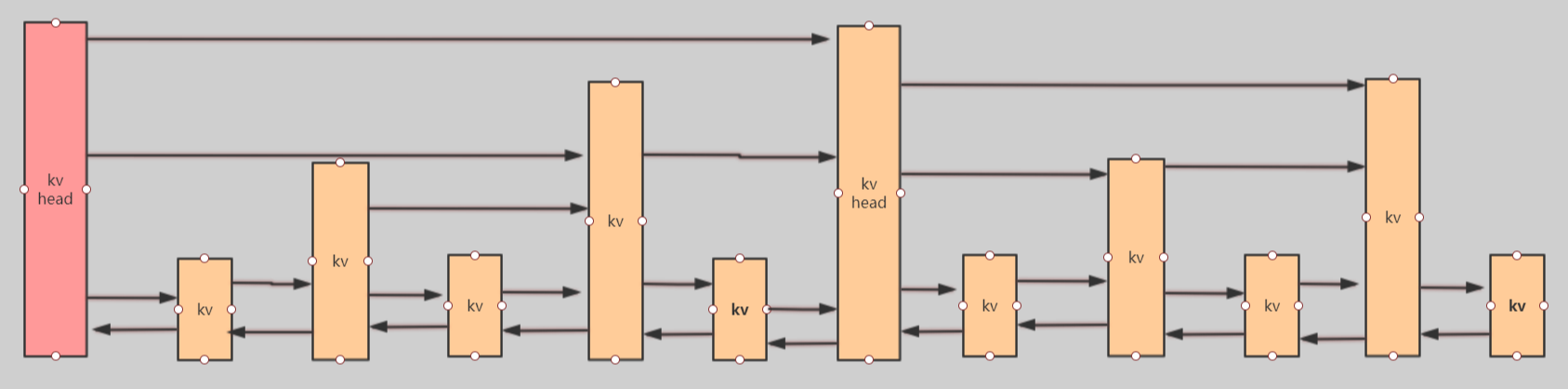
Redis的跳跃列表共有64层,每个kv块对应的结构如下面的代码中的zslnode结构,kv head也是这个结构,只不过value字段是NULL值,score是Double.MIN_VALUE,用来垫底。
kv之间使用指针串起来形成了双向链表,他们是有排序从小到大的。不同的kv层高可能不一样,层数越高的kv越少。同一层的kv会使用指针串起来。每一层元素的遍历都是从kv head出发。
struct zslnode { string value; double score; zslnode*[] forwards; //多层链接指针 zslnode* backward; //回溯指针 } struct zsl { zslnode* header; int maxLevel; //表头指针 map<string, zslnode*> ht; //hash结构的所有键值对 }
【查找过程】
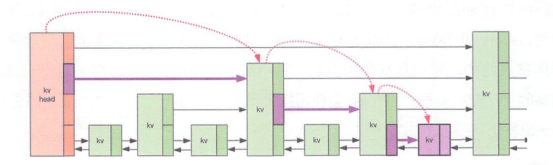
查找过程如图所示,从head的最高层出发,每次找到比自己小的前一个元素,然后降低一层,再继续,直到找到该元素或者到最底层找不到该元素返回NULL。
这种方法可以将原本链表遍历查询的O(n)复杂度降低到O(lg(n))。
【新增元素分配随机层数】
对于一个完美的跳表应该是按照规律,每隔固定几个元素就分配对应的层高,这样查找时不至于某一层元素分配在一层而导致查找复杂度O(n)化,但如果真的这么做,每次插入都会影响后续的所有元素,引发级联更新。
Redis采用一个随机算法给它分配一个合理地层数。直观上期望的目标是50%的概率被分配到level1,25%到level2,...,到顶层的概率只有2^(-63)。这里的算法如下:
int zslRandomLevel(void){ int level = 1; //random()与16个位的全1进行与运算,表示一个随机的0-65535之间的数字 //概率与65535相乘得到一个常数,范围内小于这个常数的概率就是给定的ZSKIPLIST_P //多轮比较之下,这个等式成立的概率就是(ZSKIPLIST_P)^N while(random()&0xFFFF < ZSKIPLIST_P*0xFFFF){ level += 1; } }
也就是说,这里是随机算出的层高,但是每一层的元素个数随着不断增多,他们的概率分布是趋近于这个给定的概率的。
Redis标准源码中的晋升率只有25%,所以官方的跳跃列表更加扁平,层高相对较低,在单层上需要遍历的节点数量会多一些。
【插入与删除】
在插入时,首先搜索合适的插入点,然后开始创建新节点,随机分配层数,再将搜索路径上前后的节点指针进行更新,与该新节点串联起来,如果分配新节点层高高于当前列表的最大高度,需要更新跳跃列表的最大高度。
删除就是插入的逆过程。
如果在zadd时,value不存在,那就是插入的流程,如果value存在,只是调整一下score的值,那就需要走一个更新流程。如果score的变化引起了排序的改变,那就要调整位置。
Redis的策略是删除这个元素,再重新插入,需要进行两次路径搜索,不会去判断这个元素是否需要调整。
【score全部相同】
极端情况下,score值相同,所以zset排序元素不只看score,如果score相同还会再比较value值。
【rank】
Redis在forward指针上增加了span属性,表示从前一个节点沿着当前层的forward指针跳到当前这个节点中间会跳多少个节点。这样只需要把搜索路径中的span相加就能知道这个节点的总rank。
Redis在插入、删除操作时会更新这个span的大小。
struct zslforward{ zslnode* item; long span; //跨度 }
【参考】
《Redis深度历险 核心原理与应用实践》

