

【ziplist结构】
Redis为了节约内存空间,zset和hash在元素个数较少的时候使用的是ziplist结构进行存储。zip+list,我们可以想到这应该是一系列的zip结构的数据链在了一起。压缩列表是一块连续的内存空间,元素之间紧挨着存储,没有任何冗余空隙。
struct ziplist<T>{ int32 zlbytes; //整个压缩列表占用的字节数 int32 zltail_offset; //最后一个元素距离压缩列表起始位置的偏移量,用于快速定位到最后一个节点 int16 zllength; //元素个数 T[] entries; //元素内容列表,紧密存储 int8 zlend; //标志压缩列表的结束,值恒为0XFF }
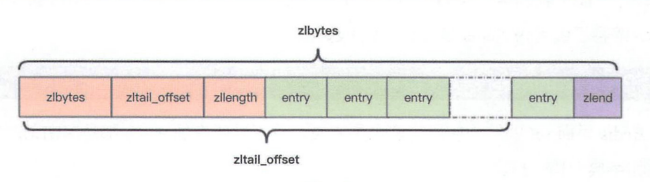
这个zltail_offset是为了支持双向遍历,快速定位最后一个元素而设置的。注意到T[] entries这个属性,容纳的元素类型不同,他们的结构也不同。
struct entry { int<var> prevlen; //前一个元素长度,用于快速定位到下一个元素的位置 int<var> encoding; //元素类型编码 optional byte[] content; //内容 }
prevlen是一个变长的整数,当字符串长度小于254时,就用1个字节表示,当长度大于254时,就用5个字节表示,第一个字节是0XFE,剩余四个字节表示字符串长度。
也就是说,程序可以只读第一个字节,如果大于0XFE,那么剩下四个字节就是长度,而如果小于OXFE,那么这个数值就是长度。
encoding存储了元素内容的编码类型信息,ziplist通过这个字段来决定后面的content形式。
如下图所示,说明了该协议的基本内容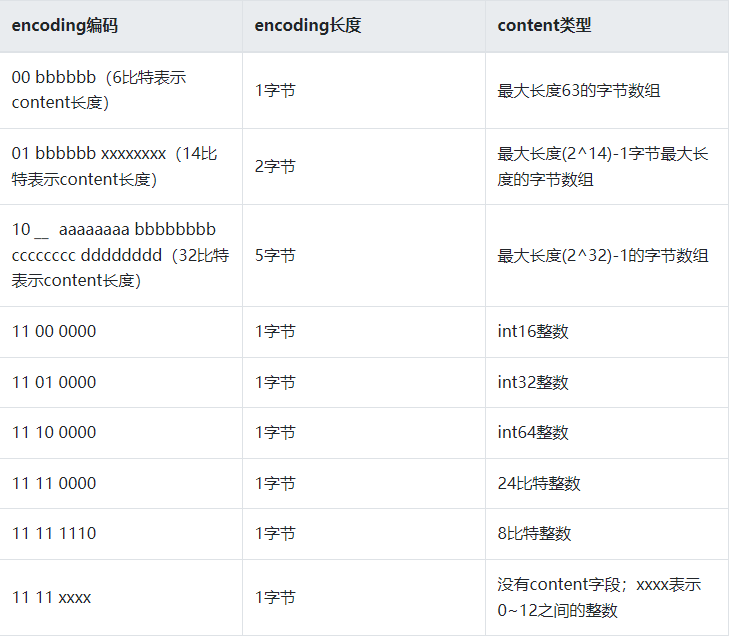
注意content字段在结构体中定义为optional类型,表示这个字段是可选的,对于很小的整数而言,它的内容已经内联到encoding字段的尾部了。
【增加元素时的处理】
ziplist都是紧凑存储,没有冗余空间,意味着插入一个新的元素就要调用realloc扩展内存。
可能会分配一个新的内存空间,将之前的内容一次性拷贝到新的地址;也有可能在原有地址上进行扩展,这时就不需要进行旧内容的内存拷贝。
如果ziplist占据内存太大,重新分配内存和拷贝内存就会有很大的消耗,ziplist不适合存储大型字符串,存储的元素也不宜过多。所以Redis的处理是,较少的元素时,hash和zset的结构才是ziplist。
【级联更新】
首先解释下什么叫做级联更新,简单说,就是因为插入了新的元素,导致后续prevlen发生了变化,如果这个长度大于254,那么prevlen的结构就会发生变化,比如从1个字节增加到了多个字节,如果后续的prevlen也因此而发生字节的增加,那么这种情况就属于级联更新。
下面整理了几种更新的情况:
A.插入元素不要更新的情形,prevlen 远小于254
红色entry插入到黄色entry前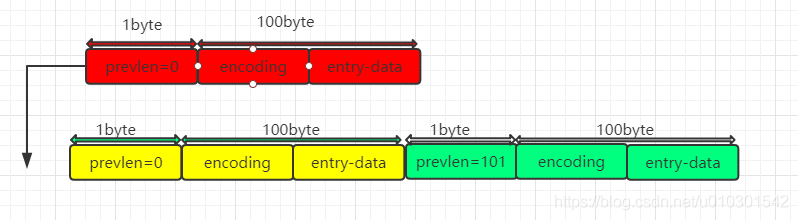
由于红色entry的长度为101,黄色entry的prevlen由0变成101,用1byte编码足够,不会发生更新。
B.当插入元素的长度大于等于254时,此时会发生更新
黄色节点的prevlen由1byte 增大到5 byte
C 当连续多个节点的数据接近254字节时,会发生级联更新,
注释:"…" 表示相同的节点,长度均和黄色节点相同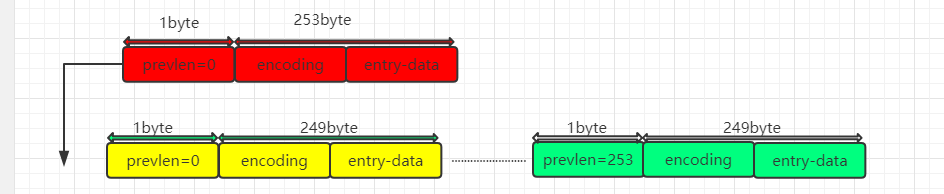
插入红色节点之后,黄色节点扩容达到254字节,导致后边的节点prevlen也需要扩容,这样连续的几个几点都需要更新,一直到绿色节点
下面是源代码:

/* When an entry is inserted, we need to set the prevlen field of the next * entry to equal the length of the inserted entry. It can occur that this * length cannot be encoded in 1 byte and the next entry needs to be grow * a bit larger to hold the 5-byte encoded prevlen. This can be done for free, * because this only happens when an entry is already being inserted (which * causes a realloc and memmove). However, encoding the prevlen may require * that this entry is grown as well. This effect may cascade throughout * the ziplist when there are consecutive entries with a size close to * ZIP_BIGLEN, so we need to check that the prevlen can be encoded in every * consecutive entry. * * Note that this effect can also happen in reverse, where the bytes required * to encode the prevlen field can shrink. This effect is deliberately ignored, * because it can cause a "flapping" effect where a chain prevlen fields is * first grown and then shrunk again after consecutive inserts. Rather, the * field is allowed to stay larger than necessary, because a large prevlen * field implies the ziplist is holding large entries anyway. * * The pointer "p" points to the first entry that does NOT need to be * updated, i.e. consecutive fields MAY need an update. */ static unsigned char *__ziplistCascadeUpdate(unsigned char *zl, unsigned char *p) { size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), rawlen, rawlensize; size_t offset, noffset, extra; unsigned char *np; zlentry cur, next; while (p[0] != ZIP_END) { cur = zipEntry(p); rawlen = cur.headersize + cur.len; rawlensize = zipPrevEncodeLength(NULL,rawlen); /* Abort if there is no next entry. */ if (p[rawlen] == ZIP_END) break; next = zipEntry(p+rawlen); /* Abort when "prevlen" has not changed. */ //如果prevlen的长度未变化,中断级联更新 if (next.prevrawlen == rawlen) break; if (next.prevrawlensize < rawlensize) { /* The "prevlen" field of "next" needs more bytes to hold * the raw length of "cur". */ //级联扩展 offset = p-zl; extra = rawlensize-next.prevrawlensize; //扩大内存 zl = ziplistResize(zl,curlen+extra); p = zl+offset; /* Current pointer and offset for next element. */ np = p+rawlen; noffset = np-zl; /* Update tail offset when next element is not the tail element. */ //更新zltail_offset指针 if ((zl+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))) != np) { ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+extra); } /* Move the tail to the back. */ //移动内存 memmove(np+rawlensize, np+next.prevrawlensize, curlen-noffset-next.prevrawlensize-1); zipPrevEncodeLength(np,rawlen); /* Advance the cursor */ p += rawlen; curlen += extra; } else { if (next.prevrawlensize > rawlensize) { /* This would result in shrinking, which we want to avoid. * So, set "rawlen" in the available bytes. */ //级联收缩,这里可以不用收缩,因为5个字节也是可以存储1个字节内容的 //虽然空间有些浪费,但是避免了级联更新的操作 zipPrevEncodeLengthForceLarge(p+rawlen,rawlen); } else { //大小没有变化,改一个长度值就可以了 zipPrevEncodeLength(p+rawlen,rawlen); } /* Stop here, as the raw length of "next" has not changed. */ break; } } return zl; }
【intset小整数集合】
当set集合容纳的元素都是整数并且元素个数较少时,Redis会使用intset来存储集合元素。
intset是紧凑的数组结构,同时支持16,32,64位整数。
struct intset<T> { int32 encoding; //决定整数位宽是16位,32位还是64位 int32 length; //元素个数 int<T> contents; //整数数组,可以是16位,32位还是64位 }

【参考】
《Redis深度历险 核心原理与应用实践》
https://blog.csdn.net/u010301542/article/details/100830218


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!