Linux云计算运维架构师(连载)-K8S 网络详解
原文:https://zhuanlan.zhihu.com/p/420453435
一、K8S 网络概述
1、K8S 的网络特征
- 每个POD 一个IP (IP peer POD)
- 所有POD 通过IP 直接访问其他POD 而不管POD 是否在同一台物理机上
- POD 内的所有容器共享一个LINUX NET NAMESPACE (网络堆栈), POD 内的容器, 都可以使用localhost 来访问pod 内的其他容器.
2、K8S 对集群网络的要求
- 所有容器都可以在不用NAT 的方式下访问其他容器
- 所有节点都可以在不用NAT的方式下同所有容器通信,反之亦然
- 容器的地址和别人看到的地址是同一个地址
3、K8S网络通信模型
1、通信网络模型1
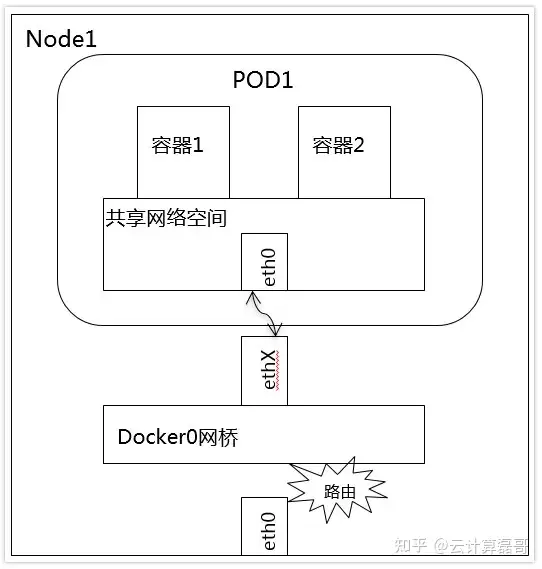
--pod上的container之间的通信
同一个Pod的容器共享同一个网络命名空间,它们之间的访问可以用localhost地址 + 容器端口就可以访问
2、通信网络模型2
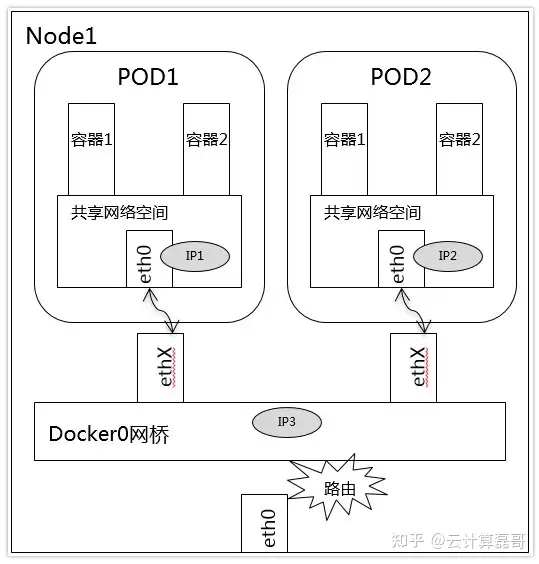
--pod和pod在同一个node
同一Node中Pod的默认路由都是docker0的地址,由于它们关联在同一个docker0网桥上,地址网段相同,它们之间应当是能直接通信的。
3、通信网络模型3
--pod和pod在不同的node
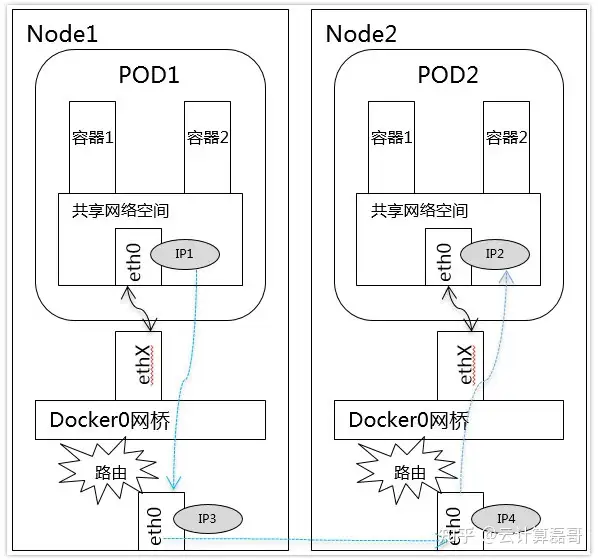
K8S 不同node 中pod 相互通信需要满足的条件如下
- 整个K8S集群中的POD IP 分配不能有冲突
- 找到一种办法,将 POD 的 IP 和所在的 NDOE 的 IP 关联起来, 通过这个关联让 POD 相互访问
条件1
要求NODE 中的docker0 的网桥地址不能冲突
条件2
要求 POD 中的数据在出发时,需要有一个机制能够知道对方 POD 的 IP 地址在哪个NODE上
4、Pod与Service通信
Pod IP <---> cluster IP
Service是一组Pod的服务抽象,相当于一组Pod的LB,负责将请求分发给对应的Pod;Service会为这个LB提供一个IP,一般称为ClusterIP。
5、Service 与集群外部客户端的通信
实现方式:Ingress、NodePort、Loadbalance
二、Kubernetes网络开源组件
1、技术术语
IPAM:IP地址管理;这个IP地址管理并不是容器所特有的,传统的网络比如说DHCP其实也是一种IPAM
主流的两种方法:
基于CIDR的IP地址段分配
精确为每一个容器分配IP
总之一旦形成一个容器主机集群之后,上面的容器都要给它分配一个全局唯一的IP地址,这就涉及到IPAM的话题。
Overlay:在现有二层或三层网络之上再构建起来一个独立的网络,这个网络通常会有自己独立的IP地址空间、交换或者路由的实现。
IPSesc:一个点对点的一个加密通信协议,一般会用到Overlay网络的数据通道里。
vxLAN:由VMware、Cisco、RedHat等联合提出的这么一个解决方案,这个解决方案最主要是解决VLAN支持虚拟网络数量(4096)过少的问题。
因为在公有云上每一个租户都有不同的VPC,4096明显不够用。就有了vxLAN,它可以支持1600万个虚拟网络,基本上公有云是够用的。
网桥Bridge: 连接两个对等网络之间的网络设备,但在今天的语境里指的是Linux Bridge,就是大名鼎鼎的Docker0这个网桥。
BGP: 主干网自治网络的路由协议,今天有了互联网,互联网由很多小的自治网络构成的,自治网络之间的三层路由是由BGP实现的。
SDN、Openflow: 软件定义网络里面的一个术语,比如说我们经常听到的流表、控制平面,或者转发平面都是Openflow里的术语。
2、容器网络方案
1、隧道方案( Overlay Networking )
隧道方案在IaaS层的网络中应用也比较多,大家共识是随着节点规模的增长复杂度会提升,而且出了网络问题跟踪起来比较麻烦,大规模集群情况下这是需要考虑的一个点。
- Weave:UDP广播,本机建立新的BR,通过PCAP互通
- Open vSwitch(OVS):基于VxLan和GRE协议,但是性能方面损失比较严重
- Flannel:UDP广播,VxLan
- Rancher:IPsec
2、路由方案
路由方案一般是从3层或者2层实现隔离和跨主机容器互通的,出了问题也很容易排查。
- Calico:基于BGP协议的路由方案,支持很细致的ACL控制,对混合云亲和度比较高。
- Macvlan:从逻辑和Kernel层来看隔离性和性能最优的方案,基于二层隔离,所以需要二层路由器支持,大多数云服务商不支持,所以混合云上比较难以实现。
3、CNM & CNI阵营
容器网络发展到现在,形成了两大阵营,就是Docker的CNM和Google、CoreOS、Kuberenetes主导的CNI。
首先明确一点:
CNM和CNI并不是网络实现,他们是网络规范和网络体系,从研发的角度他们就是一堆接口,你底层是用Flannel也好、用Calico也好,他们并不关心,CNM和CNI关心的是网络管理的问题。
CNM(Docker LibnetworkContainer Network Model)
Docker Libnetwork的优势就是原生,而且和Docker容器生命周期结合紧密;缺点也可以理解为是原生,被Docker“绑架”。
- Docker Swarm overlay
- Macvlan & IP networkdrivers
- Contiv
- Weave
CNI(Container NetworkInterface)
CNI的优势是兼容其他容器技术(e.g. rkt)及上层编排系统(Kubernetes & Mesos),而且社区活跃势头迅猛,Kubernetes加上CoreOS主推;缺点是非Docker原生。
- Kubernetes
- Weave
- Macvlan
- Calico
- Flannel
- Contiv
- Mesos CNI
本文档主要讲解的就是CNI
K8S加载CNI 的地方
kubelet
/etc/cni/net.d/
# cat /etc/cni/net.d/10-Flannel.conflist4、网络插件作用简述
- 对K8S集群中所有node上的pod做IP规划,防止IP冲突。因为Pod之间通过Pod IP通信。
- 保存规划的Pod IP与node IP映射关系。因为说到底node之间是通过node IP通信。
三、Flannel网络
1、简介
Flannel是 CoreOS 团队针对 Kubernetes 设计的一个覆盖网络(Overlay Network)工具,功能是让集群中的不同节点主机创建的Docker容器都具有全集群唯一的虚拟IP地址。
在默认的Docker配置中,每个Node的Docker服务会分别负责所在节点容器的IP分配。Node内部得容器之间可以相互访问,但是跨主机(Node)网络相互间是不能通信。Flannel设计目的就是为集群中所有节点重新规划IP地址的使用规则,从而使得不同节点上的容器能够获得"同属一个内网"且"不重复的"IP地址,并让属于不同节点上的容器能够直接通过内网IP通信。
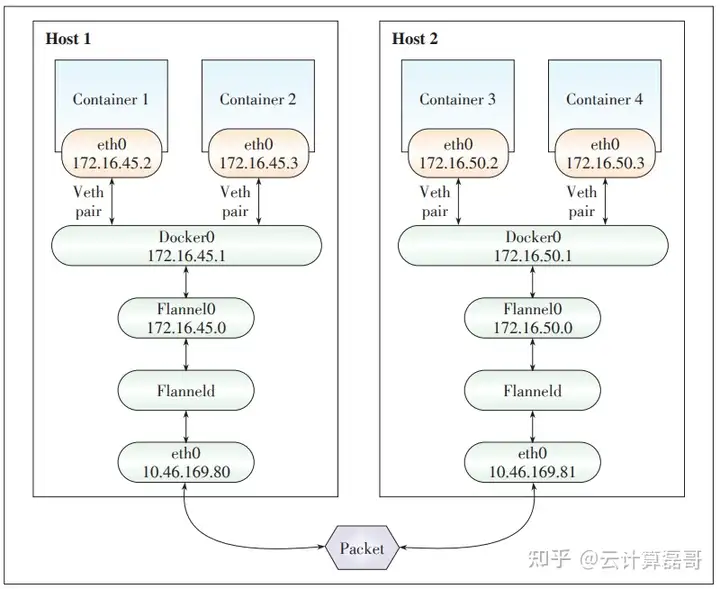
2、原理
首先,Flannel利用Kubernetes API或etcd用于存储整个网络的网络配置,其中最主要的内容为设置转换的网络地址空间。例如,设置整个内部所有容器的IP都取自网段的“ 10.1.0.0” / 16”。接着,Flannel在每个主机中运行Flanneld作为代理,它会为所在主机从托管的网络地址空间中,获取一个小的网段子网,本主机内部所有容器的IP地址都重置中分配。然后,Flanneld再将本主机获取的子网以及用作主机间通信的公用IP,同样通过kubernetes API或etcd存储起来。最后,Flannel利用各种后端,例如udp,vxlan,host-gw等,跨主机转发容器间的网络流量,完成容器间的跨主机通信。
3、后端模式
目前Flannel有多种backend管理网络,常用的有三种:hostgw,udp,vxlan,三者差异如下:

vxlan和UDP的区别是vxlan是内核封包,而UDP是Flanneld用户态程序封包,所以UDP的方式性能会稍差; hostgw模式是一种主机网关模式,容器到另外一个主机上容器的网关设置成所在主机的网卡地址,这个和calico非常相似,只不过calico是通过BGP声明,而hostgw是通过中心的etcd分配,所以hostgw是直连模式,不需要通过overlay封包和拆包,性能比较高,但hostgw模式最大的缺点是必须是在一个二层网络中,毕竟下一跳的路由需要在邻居表中,否则无法通行。
在实际的生产环境总值,最常用的还是vxlan模式。
4、部署
4.1、master初始化
[root@localhost ~]# kubeadm init --apiserver-advertise-address=自己IP --kubernetes-version v1.18.1 --pod-network-cidr=10.244.0.0/16 (Flannel默认范围)4.2、 Flannel yaml文件下载
[root@localhost ~]# wget https://raw.githubusercowget https://raw.githubusercontent.com/coreos/Flannel/master/Documentation/kube-Flannel.yml kube-Flannel.yml 中后端选择方式 ,默认为vxlan

4.3、应用Flannel
[root@localhost ~]# kubectl apply -f kube-Flannel.yml 注意:node节点在master应用Flannel之前需要kubeadm reset ,重新join
4.4、部署成功
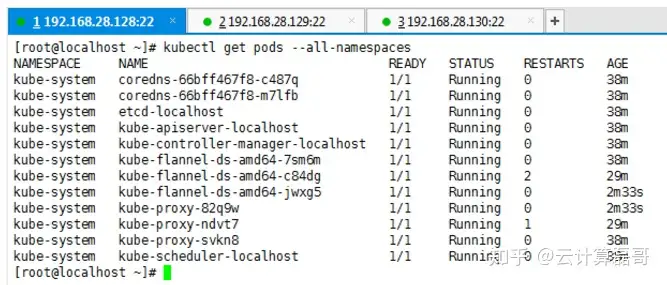
4.5、验证网络可以使用
如图,创建两个nginx deployment,用来创建两个nginx pod:
[root@localhost ~]# cat nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
namespace: policy-demo
labels:
app: nginx
spec:
replicas:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
应用nginx.yaml
[root@localhost ~]# kubectl apply -f nginx.yaml 结果如下:
[root@localhost ~]# kubectl get pods --all-namespaces -o wide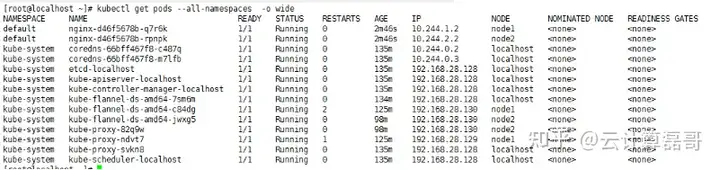
在node1上访问node2上的nginx pod,可以访问
[root@localhost ~]# curl http://10.244.2.2:80 ##自己node2上nginx ip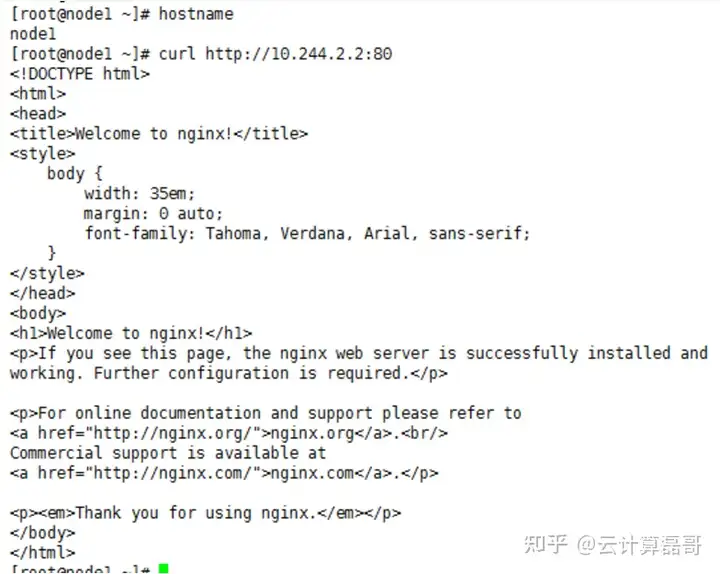
同理,在node2上也访问成功
[root@localhost ~]# curl http://10.244.2.1:80 ##自己node1上nginx ip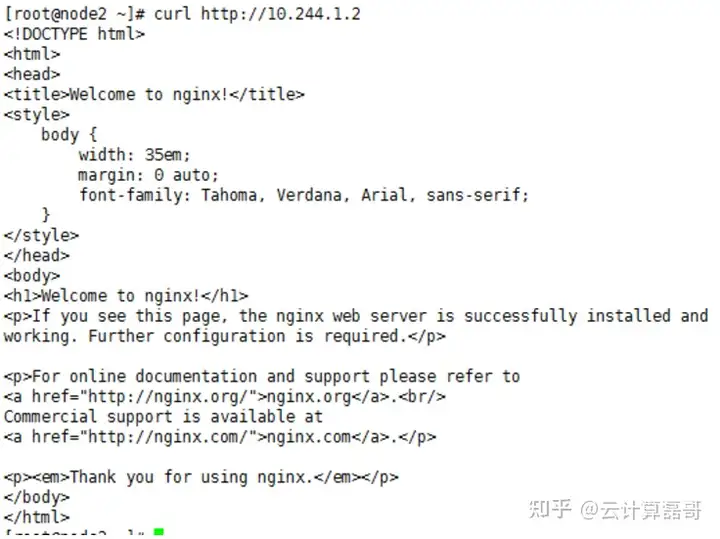
四、NetworkPolicy
1、起因
默认情况下,kubernets集群中所有pod之间、pod与节点之间可以互相通信。因此集群虽然提供namesapce用来做多租户隔离,但是如果不配置网络策略,namespace的隔离也仅仅是作用于在kubernetes编排调度时的隔离,实际上不同namespace下的pod还是可以相互串通的。那么我们该如何限制pod的网络通信,防止非法访问呢?
此时就需要使用Kubernetes提供的networkPolicy,用于隔离不同租户的应用并减少攻击面。networkpolicy通过标签选择器来模拟传统的网络物理隔离,并通过不同的策略完成访问方向的管控。
2、简介
Network Policy是kubernetes中的一种资源类型,它从属于某个namespace。
其内容从逻辑上看包含两个关键部分
一是pod选择器,基于标签选择相同namespace下的pod,将其中定义的规则作用于选中的pod。
另一个就是规则了,就是网络流量进出pod的规则,其采用的是白名单模式,符合规则的通过,不符合规则的拒绝。
3、NetworkPolicy资源
主要由三个主要部分构成
podSelector: 根据命名空间和label来选择需要应用网络策略的pod
policyTypes: 网络策略类型,数组类型,可选值为Ingress(为入Pod的规则),engress(为出Pod得规则)或者两个都填写.如果未指定则默认值为ingress,engress。
ingress: 入口白名单规则,可以通过from设置允许进入的流量,子字段ipBlock,namespaceSelector,podSelector等字段提供了对于来源的灵活选择,也可以通过ports可以设置从哪些端口进入的流量。
engress: 同ingress基本一致,但是from修改为了to,定义的是pod想要访问的外部destination
4、规则介绍
4.1、默认禁止所有入Pod流量
[root@localhost ~]# vi default-deny.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny
spec:
podSelector: {}
policyTypes:
- Ingress ###无规则 上例中没有定义pod选择器,表示如果namespace下的某个pod没有被任何Network Policy对象选中,则应用此对象,如果被其它Network Policy选中则不应用此对象。
policyTypes的值为Ingress,表示本例启用Ingress规则。但是本例没有定义具体的Ingress,那就应用默认规则。默认规则禁止所有入pod流量,但例外情况是如果source就是pod运行的节点,则允许通过。
4.2、默认允许所有入pod流量
[root@localhost ~]# vi allow-all.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all
spec:
podSelector: {}
ingress:
- {} ####有规则,规则为空
同样没有定义pod选择器,意义与上例同。注意ingress的定义,这个是有规则的,只是规则中的条目为空,与默认规则不同,表示全部允许通过。
4.3、默认禁止所有出pod流量
[root@localhost ~]# vi allow-all.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all
spec:
podSelector: {}
policyTypes:
- Egress与默认允许所有入pod流量,只是流量由入变成出。
4.4、默认禁止所有入出pod流量
[root@localhost ~]# vi default-deny.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny
spec:
podSelector: {}
policyTypes:
- Ingress
- Egress4.5、策略模型
[root@localhost ~]# vi test-network-policy.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector:
matchLabels:
role: db #default namespace下label包含role=db的pod,都会被隔绝
policyTypes:
- Ingress
- Egress
#以下为规定入口和出口的流量
ingress:
- from:
- ipBlock:
cidr: 172.17.0.0/16 #允许入口的流量
except: #除此之外的IP
- 172.17.1.0/24
- namespaceSelector:
matchLabels:
project: myproject
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 6379
egress:
- to:
- ipBlock:
cidr: 10.0.0.0/24
ports:
- protocol: TCP
port: 5978模型策略:
1)、default namespace下label包含role=db的pod,都会被隔绝,他们只能建立“满足networkPolicy的ingress和egress描述的连接”。
2)、所有属于172.17.0.0/16网段的IP,除了172.17.1.0/24中的ip,其他的都可以与上述pod的6379端口建立tcp连接。
3)、所有包含label:project=myproject的namespace中的pod可以与上述pod的6379端口建立tcp连接;
4)、所有default namespace下的label包含role=frontend的pod可以与上述pod的6379端口建立tcp连接;
5)、允许上述pod访问网段为10.0.0.0/24的目的IP的5978端口。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号