mysql中exit和in的区别
参考网址:https://blog.csdn.net/cool_wayen/article/details/79614806
提前准备
为了大家学习方便,北哥在这里面建立两张表并为其添加一些数据
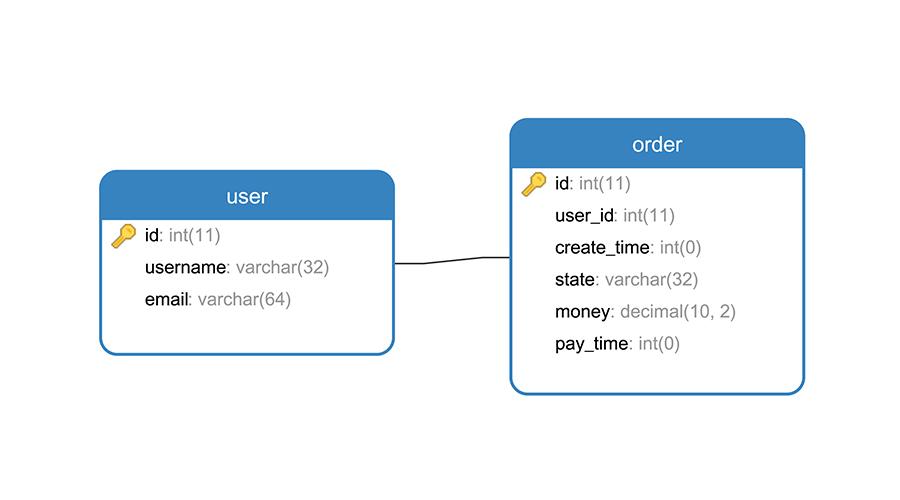
一张会员表,一张会员下单表。
会员表数据
| id | user | |
|---|---|---|
| 1 | abei | abei@nai8.me |
| 2 | wh | abei@maige123.com |
| 3 | liuhuan | 267765@qq.com |
订单表
| id | user_id | create_time | ... |
|---|---|---|---|
| 1 | 1 | 1489579802 | ... |
| 2 | 2 | 1489579802 | ... |
| 3 | 1 | 1489579802 | ... |
| 4 | 3 | 1489579802 | ... |
| 5 | 2 | 1489579802 | ... |
| 6 | 1 | 1489579802 | ... |
我们将用这两张表做演示。
什么是exists
exists表示存在,它常常和子查询配合使用,例如下面的SQL语句
-
SELECT * FROM `user`
-
WHERE exists (SELECT * FROM `order` WHERE user.id = order.user_id)
exists用于检查子查询是否至少会返回一行数据,该子查询实际上并不返回任何数据,而是返回值True或False。
当子查询返回为真时,则外层查询语句将进行查询。
当子查询返回为假时,外层查询语句将不进行查询或者查询不出任何记录。
因此上面的SQL语句旨在搜索出所有下过单的会员。需要注意的是,当我们的子查询为 SELECT NULL 时,MYSQL仍然认为它是True。
exists和in的区别和使用场景
是的,其实上面的例子,in这货也能完成,如下面SQL语句
-
SELECT * FROM `user`
-
WHERE id in (SELECT user_id FROM `order`)
那么!in和exists到底有啥区别那,要什么时候用in,什么时候用exists那?接下来阿北一一教你。
我们先记住口诀再说细节!“外层查询表小于子查询表,则用exists,外层查询表大于子查询表,则用in,如果外层和子查询表差不多,则爱用哪个用哪个。”
In关键字原理
-
SELECT * FROM `user`
-
WHERE id in (SELECT user_id FROM `order`)
in()语句只会执行一次,它查出order表中的所有user_id字段并且缓存起来,之后,检查user表的id是否和order表中的user_id相当,如果相等则加入结果期,直到遍历完user的所有记录。
in的查询过程类似于以下过程
-
$result = [];
-
$users = "SELECT * FROM `user`";
-
$orders = "SELECT user_id FROM `order`";
-
for($i = 0;$i < $users.length;$i++){
-
for($j = 0;$j < $orders.length;$j++){
-
// 此过程为内存操作,不涉及数据库查询。
-
if($users[$i].id == $orders[$j].user_id){
-
$result[] = $users[$i];
-
break;
-
}
-
}
-
}
我想你已经看出来了,当order表数据很大的时候不适合用in,因为它最多会将order表数据全部遍历一次。
如:user表有10000条记录,order表有1000000条记录,那么最多有可能遍历10000*1000000次,效率很差.
再如:user表有10000条记录,order表有100条记录,那么最多有可能遍历10000*100次,遍历次数大大减少,效率大大提升.
exists关键字原理
-
SELECT * FROM `user`
-
WHERE exists (SELECT * FROM `order` WHERE user.id = order.user_id)
在这里,exists语句会执行user.length次,它并不会去缓存exists的结果集,因为这个结果集并不重要,你只需要返回真假即可。
exists的查询过程类似于以下过程
-
$result = [];
-
$users = "SELECT * FROM `user`";
-
for($i=0;$i<$users.length;$i++){
-
if(exists($users[$i].id)){// 执行SELECT * FROM `order` WHERE user.id = order.user_id
-
$result[] = $users[$i];
-
}
-
}
你看到了吧,当order表比user表大很多的时候,使用exists是再恰当不过了,它没有那么多遍历操作,只需要再执行一次查询就行。
如:user表有10000条记录,order表有1000000条记录,那么exists()会执行10000次去判断user表中的id是否与order表中的user_id相等.
如:user表有10000条记录,order表有100000000条记录,那么exists()还是执行10000次,因为它只执行user.length次,可见B表数据越多,越适合exists()发挥效果.
但是:user表有10000条记录,order表有100条记录,那么exists()还是执行10000次,还不如使用in()遍历10000*100次,因为in()是在内存里遍历,而exists()需要查询数据库,我们都知道查询数据库所消耗的性能更高,而内存比较很快.
因此我们只需要记住口诀:“外层查询表小于子查询表,则用exists,外层查询表大于子查询表,则用in,如果外层和子查询表差不多,则爱用哪个用哪个。”

 浙公网安备 33010602011771号
浙公网安备 33010602011771号