
Understanding TCP/IP Network Stack
from: 《理解TCP/IP协议栈,实现网络应用》 《How NICs Work》
数据的发送
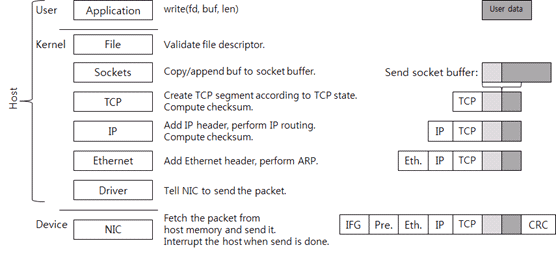
There are several layers and the layers are briefly classified into three areas:
- User area
- Kernel area
- Device area
在user area和kerne area处理的任务都是由CPU完成的,所以user area和kernel area统称为host来与device area加以区分。在这里的device是Network Interface Card(NIC),也就是网卡。
Host区域数据传递
首先应用程序准备好数据(右上角的user data灰色框),然后调用 write() 系统调用发送数据。假设所用的socket(图中write调用的参数fd)合法,那么当发起系统调用后,发送流程切换到kernel area。
内核中每个socket有两个buffer:
- 一个是send socket buffer,发送缓冲区,用于发送
- 一个是receive socket buffer,接收缓冲区,用于接收
当 write() 系统调用被调用时,待发送数据从用户空间复制到内核内存中,然后添加进发送缓冲区的链表末尾。这样就可以按顺序发出数据。图一中的’Sockets’那层对应的右边灰色的小格子指向socket send buffer中的数据。然后,调用TCP/IP协议栈。
每个tcp类型的socket都有一个TCP Control Block(TCB) 的数据结构,TCB包括了一个TCP连接所需要的成员,比如 connection state 连接状态(LISTEN, ESTABLISHED, TIME_WAIT等)、receive window 接收窗口,congestion window 拥塞窗口、sequence number 包序号和 resending timer 重传定时器等。可以认为一个TCB 代表一条TCP连接。
如果当前TCP状态允许数据传输,会新建一个新的TCP segment(或者称为 packet - 数据包);否则系统调用结束并返回错误码。
下图是一个TCP报文(TCP Frame Structure),包括两个TCP片段:TCP header和Payload

payload部分是待发送的数据,处于socket的未确认(unACK)发送缓冲区,每个包的payload的最大长度由对方接收窗口大小、拥塞窗口大小和maximum segment size(MSS,最大报文长度)共同决定。
然后计算packet的checksum校验码,实际上,checksum计算目前由NIC用硬件实现,放在这里只是为了逻辑通顺。
然后TCP报文进入下一层IP层处理,IP层添加IP头部和checksum,并进行IP路由选择。IP路由选择是选择下一跳的过程。当IP层计算并添加IP头部校验checksum后,将数据包发送到下一层Ethernet层,即数据链路层。Ethernet层采用ARP协议搜索查询下一跳IP的MAC地址,然后向报文添加Ethernet头部。添加完Ethernet头部后,host部分的报文就处理完毕了。
NIC的数据传输
在IP路由选择执行完毕后,根据结果选择哪个NIC作为传输接口;在host处理完报文后,调用NIC驱动发送数据。(一定要注意,NIC和NIC驱动不是一体的,前者是NIC网卡硬件,后者是运行在host和内核的驱动程序,硬件是CPU)
此时,如果一个抓包软件比如tcpdump或者wireshark正在运行,kernel将报文从内核态复制一份到这些软件内存中。同样的,如果是抓接收到的包,也同样是从NIC驱动这里抓取的。一般来说,流量整形工具也是在这一层实现的。
NIC驱动程序通过厂商制定的网卡与主机的通信协议向NIC请求发送packet。
NIC收到发送网络包请求后,将报文复制到自己的内存中然后发送到网络。发送前,为遵守以太网标准,还要修改一些标志,包括packet的CRC校验码,IFG(Inter-Frame Gap)包内间隔和报文头等标志;CRC校验码用于数据保真,其他二者用于区分其实包还是中间包(需要翻译调整)。数据包传输速度根据网络物理速度和以太网流控制条件来调整,一般取低值,并留有一定余量。
当NIC发出一个数据包,NIC向CPU发出中断;每个中断有其自己的中断号,操作系统根据中断号调用对应的驱动程序处理中断,驱动的中断处理函数是NIC驱动在OS启动时注册中断回调函数;当中断发生时,OS调用中断服务程序,然后中断服务程序向OS返回发送完成的数据包(编号)。
至此我们讨论了应用程序数据发送的流程,贯穿kernel和NIC设备。而且,即使没有应用程序的写请求,kernel可以调用TCP/IP协议栈直接发送数据包。例如,当收到一个ACK后并且得知对端接收窗口扩大,kernel将自动的把仍在发送缓存中的数据打包,直接发出。
数据的接收
现在我们看看数据的接收流程,当数据包到来的时候,网络栈是如何处理的:
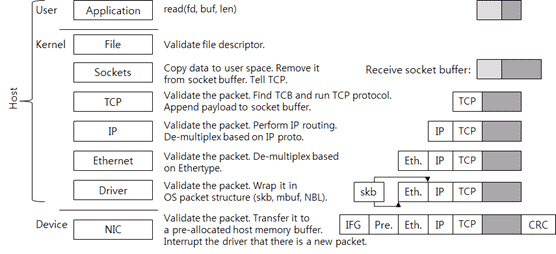
NIC层数据传递
首先,NIC将数据包写入自身内存,检查该包是否CRC合法,然后将该包发送给host的内存,host的内存是NIC驱动事先向kernel申请的内存,用于接收数据包,当host分配成功,通过NIC驱动告诉NIC这块内存的地址和大小。如果NIC driver没有实现分配好内存,NIC收到数据包后会直接丢弃。
当NIC将数据包写入到host的内存缓冲区后,NIC向host 操作系统发出中断信号。
然后,NIC驱动来确认它是否可以处理这个新包,这个过程使用的是NIC和NIC驱动之间的通信协议。
当驱动需要将数据包发送到上一层时,这个数据包必须被包装成OS可以理解的包格式。比如,linux上的sk_buff,BSD系列内核的mbuf结构,或者MS系统的NET_BUFFER_LIST结构。NIC驱动将封装后的数据包转给上层处理。
Host区域数据传递
链路层Ethernet层检查数据包是否合法,然后根据数据包头部的ethertype值选择上层网络协议。IPV4类型的值为0x0800。本层的工作就是去掉数据包的Ethernet头部,传送给上层IP层。
IP层同样首先检查数据包合法性,采用检查IP头部的checksum字段的方式。在逻辑上进行IP路由选择,决定是否本机操作系统处理这个包,还是转发给另一个系统。如果本机处理数据包,那么IP层将根据IP头部的协议proto值选择上层传输层协议(比如TCP协议的proto值是6),然后移除IP头部,发送给上层TCP层。
同样的,TCP层检查数据包的checksum是否正确。之前说过,TCP的checksum也是由NIC计算得到的。(可以理解这些CRC校验的工作都是由NIC硬件实现的,而不是通过CPU,如果硬件层没有校验通过,可以直接在网卡丢弃)。
然后开始采用IP:PORT四元组作为标志搜索这个数据包对应的TCP Control Block。找到TCP控制块后就找到了TCP连接,根据包协议处理数据包。如果是收到新数据,那么将其加入socket接收缓冲区中。根据TCP状态,协议栈发送TCP回复包(比如ACK包)。现在TCP/IP的接收数据流程完成了。
socket接收缓冲区的大小是TCP接收窗口大小。数据接收时,TCP接受窗口扩大时TCP的吞吐能力增大;在此之前,socket的缓冲区大小由应用程序或者操作系统配置来调整,而现在新的网络栈具有自动调整接受缓冲区大小的功能。
当应用程序调用 read() 系统调用时,从user area切换到kernel area,数据从socket的缓冲区复制到user area,然后从socket缓冲区中释放。然后调用TCP协议栈;因为socket缓冲区有了新的空间,所以TCP增大接受窗口;然后根据该连接的状态发送ACK包或者其他包比如RST。如果进行 read() 系统调用时没有新数据包,那么 read() 就终止返回。
总结
The Send Case

The Steps for Sending a Single Ethernet Frame
- The host operating system is informed that a frame is in host memory and is ready to be sent. The OS builds a buffer descriptor regarding this frame in host memory.
- The OS notifies the NIC that a new buffer descriptor is in host memory and is ready to be fetched and processed. This is typically referred to as a "mailbox" event.
- The NIC initiates a direct memory access (DMA) read of the pending buffer descriptor and processes it.
- Having determined the host address of the pending frame, the NIC initiates a DMA read of the frame contents.
- When the all segments of the frame (which may use several buffer descriptors and buffers) have arrived, the NIC transmits the frame out onto the Ethernet.
- Depending on how the OS has configured the NIC, the NIC may interrupt the host to indicate that the frame has completed.
The Receive Case

The Steps for Receiving a Single Ethernet Frame
For these steps, it's presumed that the OS has already created buffer descriptors that point to free regions in host memory and that the NIC has read these buffer descriptors into local NIC memory via DMA.
- The NIC receives a frame from the network into its local receive buffer.
- Presuming there is enough host memory available for this received frame, the NIC initiates a DMA write of the frame contents into host memory. The NIC determines what the starting host address is by examining the next free buffer descriptor (which it has previously fetched).
- The NIC modifies the previously fetched buffer descriptor regarding the space that the new frame now occupies; the NIC fills in the frame length and possibly checksum information. After modifying this buffer descriptor, the NIC initiates a DMA write of it to the host.
- Depending on how the OS has configured the NIC, the NIC may interrupt the host to indicate that a frame has arrived.
缓存和流控制
流控制是网络栈各层通力合作实现的。下图显示发送数据时网络栈的各级缓存:

首先,应用程序创建数据,添加到socket发送缓存中,如果缓存没有内存可用,则send/write系统调用返回失败或者堵塞。因此,应用程序流向kernel的数据流速由socket缓冲区大小来限制。
TCP协议栈创建和发送数据包,通过发送队列transmit queue(qdisc)向NIC驱动发送。这是个典型的FIFO队列,队列长度可以由ifconfig工具配置,执行ifconfig工具结果中的txqueuelen的值,一般为1000,意味着缓存1000个数据包。
环状发送队列(TX ring)处于NIC驱动和NIC之间。Tx ring可被认为是发送请求队列。如果Tx ring满,此时NIC驱动不能发出发送请求,那么待发送的数据包将会累积在TCP/IP协议栈和NIC驱动之间的qdisc中,如果累积数据包超过qdisc大小,那么再想发送新包,会被直接丢弃。
NIC将待发送数据包存储在自身缓存中,包速率主要由NIC的物理速度决定。而且由于链路层Ethernet layer的流控制,如果NIC的接收缓冲区没有空间,那么发送数据包也将停止(可以猜测原因是自身停止发送后,对端将不会再发送数据包过来,有助于NIC和NIC驱动将拥塞在接受缓冲区的数据包处理完)。
当发送自kernel的数据包速度大于发送自NIC的数据包速度时,包将拥堵在NIC的缓存中。如果NIC自身缓存没有多余空间,NIC将不会从Tx ring中去取发送请求request;这样的话,越来越多的发送请求累积在Tx ring中,最终Tx ring也堵满;此时NIC驱动再也不能发起新的发送请求,并且要发送的新包将堵塞在qdisc中;就这样,性能衰退从底向上传递。(感觉这里我们可以通过检测各级buffer的堵塞情况,判断程序堵塞在哪一步)
接下来是接受数据包的传递过程:
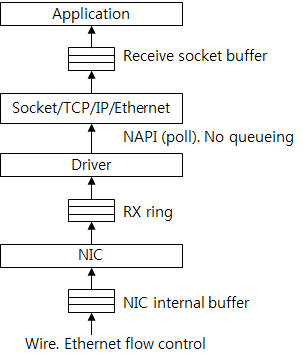
首先,收到的数据包将缓存在NIC自身缓存中。从流控制的角度来看,NIC和NIC驱动之间的Rx ring队列作为缓存,NIC驱动从Rx ring中将已接受数据包的请求取出,发给上层,在这里NIC驱动和协议栈之前没有缓冲区,因为这里是通过kernel调用NAPI去poll已收到的数据包的。(需要想想怎么翻译).这里可以认为上层直接从Rx ring中获取数据包。网络包的数据部分将上传缓存在socket的接收缓冲区中,应用程序随后从socket的接受缓冲区中读取数据。
思考
- 这里只是对数据的传递流程做了笔记,更多内容请阅读原文:
* 网络栈的控制流
* 处理中断
* sk_buff 数据结构
* TCP Control Block 数据结构
* Linux Kernel 源码分析:发送数据(TCP/IP协议栈的实现)
* NIC和NIC驱动是怎样通信的 - 全文描述的都是关于TCP的数据传输,那么对于UDP协议呢?
推测:UDP与TCP是传输层协议,也就意味着二者在传输层下的传递模式是一样的(均需要通过IP包),只是在传输层的验证不同而已。那么UDP同样需要将数据写入内核缓冲区,然后层层包装,再由NIC传递到其他主机。 - UDP的数据报与TCP的数据流,在内核缓冲区里有何不同呢?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号