Python网络爬虫
引自:《手把手教你写网络爬虫》
页面数据提取
简单的text文本提取
通过 F12, Ctrl+Shift+C 快捷键从网页中直接抓取数据


代码如下:
from urllib.request import urlopen from bs4 import BeautifulSoup html = urlopen("http://jr.jd.com") html_content = html.read() html.close() # 关闭url # 利用bs4解析html文本 bsoup = BeautifulSoup(html_content, "html.parser") # 解析全部class="nav-item-primary"的<a>标签 bs_elem_set = bsoup.find_all("a", "nav-item-primary") # <class 'bs4.element.ResultSet'> for elem_tag in bs_elem_set: # print(type(elem_tag)) # <class 'bs4.element.Tag'> print("Debug::title_elem -->> ", elem_tag.get_text())
测试结果:
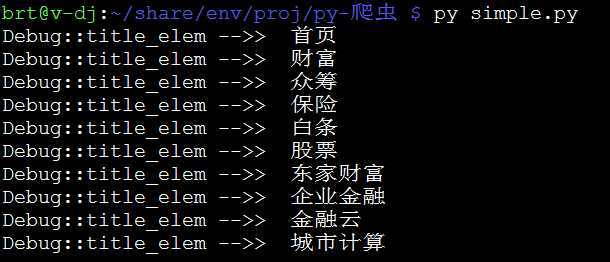
动态网页的数据提取
案例:我们想从网易歌单 https://music.163.com/#/discover/playlist 中查询播放次数超过500万的全部歌单,查找关键字
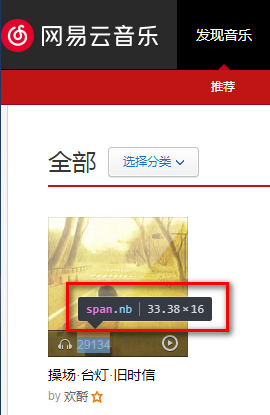
但事实上,通过 <span class="nb">29135</span> 我们什么也没有提取到……
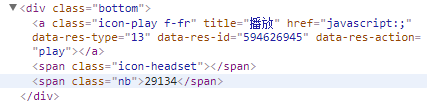
从网页源码中我们可以知道,该网页通过javascript动态更新数据,我们得到的 nb=29135 数据行在 urlopen() 时尚未被js代码更新……
用Python 解决这个问题只有两种途径:
- 直接从 JavaScript 代码里采集内容;
- 或者用 Python 的第三方库运行 JavaScript,直接采集你在浏览器里看到的页面。
通过 Selenium 运行Js脚本,模拟浏览器载入动态网页。代码如下:
from selenium import webdriver browser = webdriver.PhantomJS() # deprecated... replace by webdriver.Chrome() or Firefox() browser.get("https://music.163.com/#/discover/playlist") browser.switch_to.frame("contentFrame") list_elems = browser.find_element_by_id("m-pl-container")\ .find_elements_by_tag_name("li") for elem in list_elems: # print(type(elem)) # <class 'selenium.webdriver.remote.webelement.WebElement'> str_nb = elem.find_element_by_class_name("nb").text print(str_nb) # I don't care the name, but just print the <nb> browser.close()
首先需要 pip3 install selenium 模块;加载动态网页用的是 Headless 的 PhantomJS 浏览器,需要单独安装:choco install PhantomJS。
ps:最新版本的 selenium 弃用了 PhantomJS,呃...不过忽略那个报警,我们这里还是可以继续执行的。
PySpider 应用
安装 PySpider
通过 pip3 install pyspider 即可。过程中遇到过以下问题,作以记录:
Linux 无法顺利安装,pip failed...
----------------------------------------
Cleaning up...
Command python setup.py egg_info failed with error code 1 in /tmp/pip-build-8q7t0vuz/pycurl
Storing debug log for failure in /root/.pip/pip.log
解决方案:既然 pip3 无法成功安装 pycurl,那就用其他的方式:apt install python3-pycurl,然后再次 pip3 install pyspider,即可顺利完成 PySpider 的安装。
Windows 的问题不在安装,而是启动 pyspider 时报错:
failed to create process.
通过 where pyspider,定位到程序位置:C:\Program Files\Python3\Scripts\pyspider.exe(由此可见,PySpider不能称之为框架,而是一个实在的爬虫工具/程序),在同目录下查询到 pyspider-script.py 脚本,第一行是shebang:
#!c:\program files\python3\python.exe 改为: #!"c:\program files\python3\python.exe"
这就解释了为什么 Linux 环境可以顺利运行,而 Windows 则失败了—— shebang不支持含有空格的路径!
一方面,我们得说是 PySpider 自动安装脚本的bug,另一方面,也的确是 Windows 系统的特殊性——路径中允许空格可以说是一个欠考虑的设计,至少在兼容性上它不够完善。更严重的是,C:\Program Files\ 这个使用最频繁的路径,导致现在想要变更设计几乎不可能了!这也提醒我们,如果重新装系统,把 Python/JVM 装到其他路径下吧,例如 C:\usr\Python3\ (曾经我还想过,为什么Python在Windows上的安装路径默认会是C盘根目录……)。
PySpider 的使用
具体步骤可以参考:《Python爬虫-pyspider框架的使用》https://www.jianshu.com/p/1f166f320c66
PySpider常见错误以及解决方案
整数错误
HTTP 599: SSL certificate problem: self signed certificate in certificate chain
这是因为https协议需要对证书进行验证导致,解决方法是,在crawl()方法中使用validate_cert参数:
self.crawl(url, callback=self.last_page, validate_cert=False)
无法使用全局变量传递参数值
crawl()方法中有专门的save参数解决变量传递的问题:
self.crawl(url, callback=self.last_page, save={'current_url': url, 'path': path_dir})
即可在目标函数中使用变量:response.save['current_url'] 和 response.save['path']

 浙公网安备 33010602011771号
浙公网安备 33010602011771号