【笔记】经典的5种架构模型
1. 分层架构
分层架构(layered architecture)是最常见的软件架构,也是事实上的标准架构。
- 解耦方式:每一层都有清晰的角色和分工,而不需要知道其他层的细节。
- 通讯方式:层与层之间通过接口通信。
1.1. 架构模型
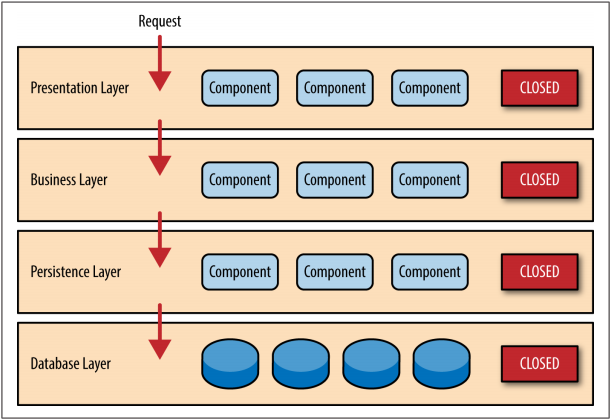
通常结构可分为4个标准层级,各层级的定义如下:
- 表现层(presentation):用户界面,负责视觉和用户互动
- 业务层(business):实现业务逻辑
- 持久层(persistence):提供数据,SQL 语句就放在这一层
- 数据库(database) :保存数据
So why not allow the presentation layer direct access to either the persistence layer or database layer? After all, direct database access from the presentation layer is much faster than going through a bunch of unnecessary layers just to retrieve or save database information. The answer to this question lies in a key concept known as layers of isolation.
The layers of isolation concept means that changes made in one layer of the architecture generally don’t impact or affect components in other layers: the change is isolated to the components within that layer, and possibly another associated layer (such as a persistence layer containing SQL).
The layers of isolation concept also means that each layer is independent of the other layers, thereby having little or no knowledge of the inner workings of other layers in the architecture.
层级隔离的设计理念,使得层与层之间实现了高内聚、低耦合。
Creating a services layer is usually a good idea in this case because architecturally it restricts access to the shared services to the business layer (and not the presentation layer). Without a separate layer, there is nothing architecturally that restricts the presentation layer from accessing these common services, making it difficult to govern this access restriction.
层级架构也使得增加新的业务层更加容易——因为层级(模块)间的耦合度很低,新的层级只需要处理层与层之间的接口就OK了。
1.1.1. 示例
调整业务结构,我们增加一个新的层级——服务层。
The services layer in this case is marked as open, meaning requests are allowed to bypass this open layer and go directly to the layer below it.
In the following example, since the services layer is open, the business layer is now allowed to bypass it and go directly to the persistence layer, which makes perfect sense.
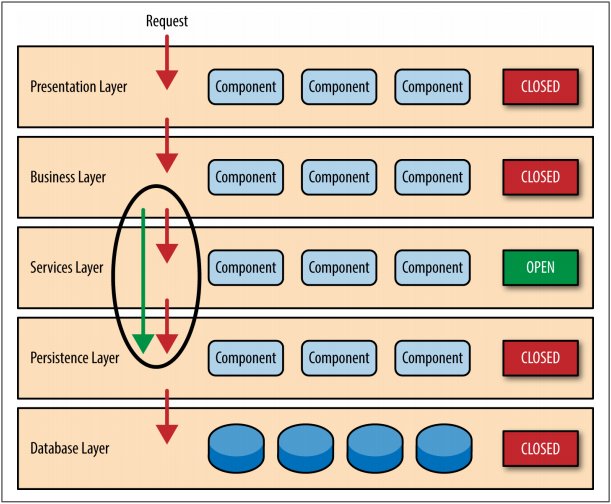
由于新的层级是开放的而非闭合的,它允许上游层越过自身,实现直接对下游层数据的访问。
1.2. 小结
分层架构可以直观的实现不同层级逻辑代码的解耦合,除此之外:
- 结构简单,容易理解和开发
- 不同技能的程序员可以分工,负责不同的层,天然适合大多数软件公司的组织架构
- 每一层都可以独立测试,其他层的接口通过模拟解决
缺点:
- 一旦环境变化,需要代码调整或增加功能时,通常比较繁杂和费时
- 部署很麻烦:即使只修改一个小地方,往往需要整个软件重新部署,不容易做持续发布
- 软件升级时,可能需要整个服务暂停
- 扩展性差:用户请求大量增加时,必须依次扩展每一层,由于每一层内部是耦合的,扩展会很困难
模式分析:
- 总体灵活性: 低
- 发布易用性: 低
- 可测试性: 高
- 性能: 低
- 规模扩展性: 低
- 开发容易度: 高
2. 事件驱动架构
事件驱动架构(Event-Driven Architecture)是一个流行的分布式异步架构模式。基于这种架构模式应用可大可小。它由高度解耦、单一目的的事件处理组件组成,可以异步地接口和处理事件。
事件:系统或组件的状态发生变化时,系统层发出的通知。
解耦方式:每个对象都通过与中间件(Mediator or Broker)实现与外界的沟通,而不是相互依赖(迪米特法则)。
通讯方式:以消息为载体、通过中间件传递通讯。
2.1. 拓扑结构 - 分类
The event-driven architecture pattern consists of two main topologies, the mediator and the broker. The mediator topology is commonly used when you need to orchestrate multiple steps within an event through a central mediator, whereas the broker topology is used when you want to chain events together without the use of a central mediator. Because the architecture characteristics and implementation strategies differ between these two topologies, it is impor‐tant to understand each one to know which is best suited for your particular situation.
2.2. Broker拓扑架构
相比于后面讲到的Mediator,Broker是一种更本质也更简洁的EDA(不知道作者为何选择先讲解复杂的Mediator,个人认为应该将这个顺序调整过来)。
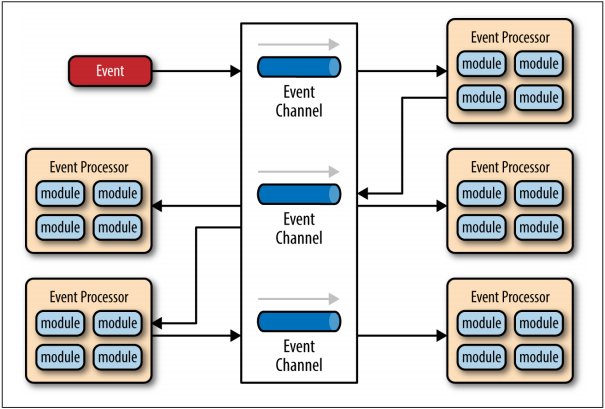
该结构包含了三个组件:
- Event:事件消息;
- Event Channel:消息队列或者是Topic,根据订阅推送(或是转发)消息;消息可能被转发到Event Processor,或是其他的Event Channel中。
- Event Processor:获得消息后执行处理。它可能是一个消息的处理终结点,也可能在处理过程中继续下发消息,或生成新的事件,并被再次提交到Event Channel中,继续下一轮的转发和处理。
2.2.1. 示例
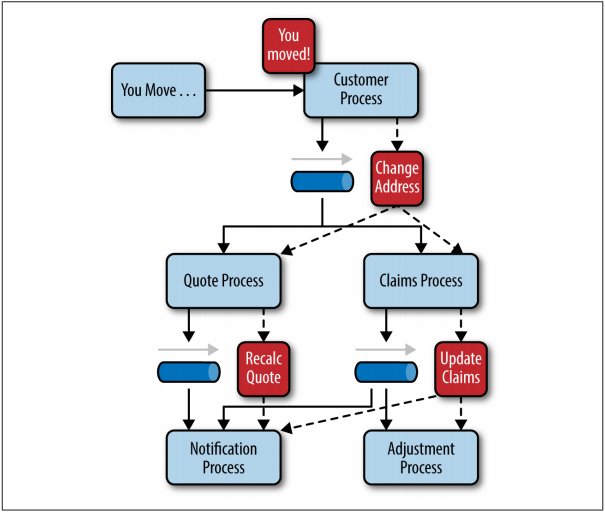
如上图:当系统中的某个对象触发了某个事件,事件被提交到Custormer Process,然后派送到Broker。Broker将解析事件并转发到相关的Processor中执行处理(注意,两个Processor是各自独立进行的,不存在任何耦合)。而在Processor中又触发了新的事件(“责任链”模式),并通过各自的Channel转发到另外的Processor中完成处理。
在Mediator中,我们将看到Mediator模式对该问题的另外一种处理方式。
2.3. Mediator拓扑结构
Mediator可以说是Broker的一种拓展,更适用于粗粒度事件的处理——由于业务逻辑更复杂,细粒度的拓扑结构将造成消息臃肿而混乱,当然,粗粒度也增加了EDA架构的复杂度。
采用Mediator模式的架构中,事件一般是复杂的(包含多个执行单元的合集),而Mediator的责任就是将该复合事件拆解为独立的子事件,然后发送到不同类型的子事件处理系统中,由子系统完成独立子事件的分发和处理。
在结构上,Mediator的EDA架构包括4个组件:
- event queues:用于原始事件(分类)存储,并转发给Event Mediator,一般是以MQ的形式存在。
- event mediator:用于原始事件的拆解(成为多个独立子事件),并转发给相关的Channel;
- event channels:通道(可以理解为细分的Event Queue),按照事件的类型不同作以划分。它可以是一个消息队列,提供给特定的Processor查询,或是消息Topic,发送特定的广播。
- event processors:事件处理器,监听特定的Channel,并在捕获事件后进行处理
在逻辑上,Mediator的处理过程如下:
The event flow starts with a client sending an event to an event queue, which is used to transport the event to the event mediator. The event mediator receives the initial event and orchestrates that event by sending additional asynchronous events to event channels to execute each step of the process. Event processors, which listen on the event channels, receive the event from theevent mediator and execute specific business logic to process the event.
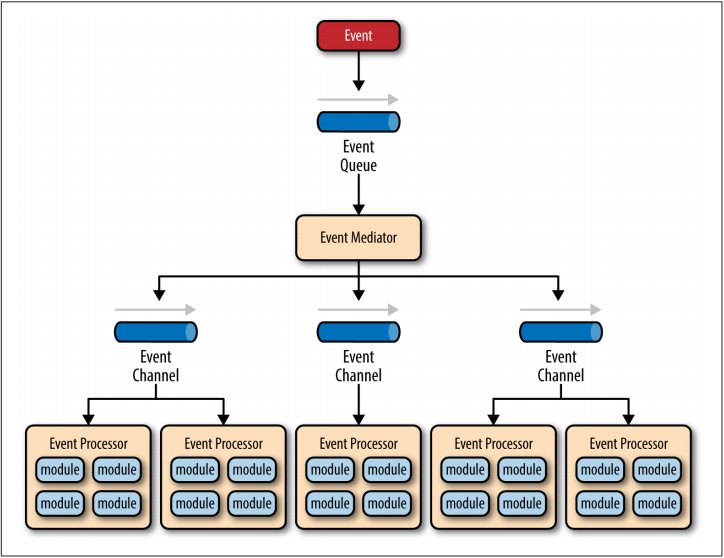
It is common to have anywhere from a dozen to several hundred event queues in an event-driven architecture. The pattern does not specify the implementation of the event queue component; it can be a message queue, a web service endpoint, or any combination thereof.
EDA对 Event Queues 并没有特定的实现要求,无论是数量还是类型,都可以根据实际需要确定。
There are two types of events within this pattern: an initial event and a processing event. The initial event is the original event received by the mediator, whereas the processing events are ones that are generated by the mediator and received by the event-processing components.
对应于 Event Queues 和 Event Channel,也同样存在着两种事件类型:原始事件(或者称为:复合事件)和处理事件。
呃,这句话倒过来说更合适:因为有不同的事件类型,所以需要对应存在不同的队列。
Event channels are used by the event mediator to asynchronously pass specific processing events related to each step in the initial event to the event processors. The event channels can be either message queues or message topics, although message topics are most widely used with the mediator topology so that processing events can be processed by multiple event processors (each performing a different task based on the processing event received).
The event processor components contain the application business logic necessary to process the processing event. Event processors are self-contained, independent, highly decoupled architecture components that perform a specific task in the application or system. While the granularity of the event-processor component can vary from fine-grained (e.g., calculate sales tax on an order) to coarsegrained (e.g., process an insurance claim), it is important to keep in mind that in general, each event-processor component should perform a single business task and not rely on other event processors to complete its specific task.
事件处理器包含实际的业务逻辑。每个消息处理器都是自包含的,独立的,高度解耦的,执行单一的任务(高内聚低耦合的要求使然)。这部分是我们开发和拓展业务的主要战场。
有一些开源的框架实现了这种架构,如Spring Integration, Apache Camel, 或者 Mule ESB。
当然,这种架构包含了多种形式的变种,你应当能够根据需要,灵活的替换相应的子模块以适配需求。
2.3.1. 示例
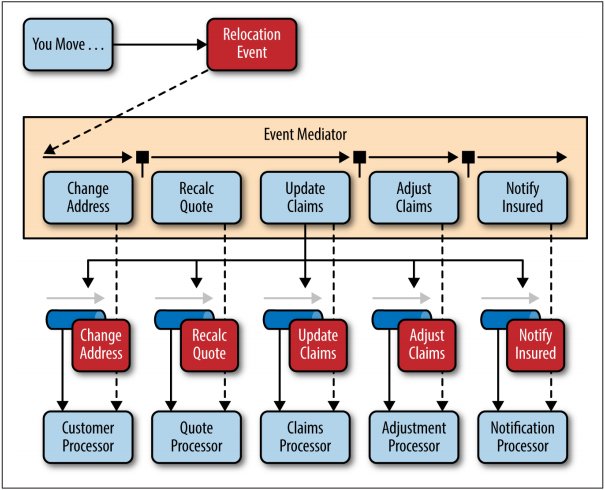
还是刚才的Move的例子,在Broker的架构中,事件以递归方式,实现自包含,通过Processor与Channel的互相调用完成消息的传递。这是所谓“责任链”模式的体现。
而Mediator则是通过统一的封装性,将本身的Move事件封装成若干子事件,每个子事件由不同的Event Channel在子系统内实现派发。这样的模式效率无疑是更高的,但它要求固定的问题域——这就导致其可拓展性较差,一旦体系需要拓展,或原Event结构出现变化,子系统也必须全盘修改。
2.4. 小结
架构考量:
事件驱动架构模式实现起来相对复杂,主要是由于它的异步和分布式特性。这可能会带来一些分布式的问题,比如远程处理的可用性,缺乏响应,broker重连等问题。
优点:
- 分布式的异步架构,事件处理器之间高度解耦,软件的扩展性好
- 适用性广,各种类型的项目都可以用
- 性能较好,因为事件的异步本质,软件不易产生堵塞
- 事件处理器可以独立地加载和卸载,容易部署
缺点:
- 涉及异步编程(要考虑远程通信、失去响应等情况),开发相对复杂
- 难以支持原子性操作,因为事件通过会涉及多个处理器,很难回滚
- 分布式和异步特性导致这个架构较难测试
模式分析
- 总体灵活性: 高
- 发布易用性: 高
- 可测试性: 低
- 性能: 高
- 规模扩展性: 高
- 开发容易度: 低
3. 微内核架构
微核架构(microkernel architecture)又称为"插件架构"(plug-in architecture),指的是软件的内核相对较小,主要功能和业务逻辑都通过插件实现。
内核(core)通常只包含系统运行的最小功能。插件则是互相独立的,插件之间的通信,应该减少到最低,避免出现互相依赖的问题。
解耦方式:业务相关项以插件的形式发布,可以选择动态加载。业务插件只与内核交互,实现业务间的低耦合。
通讯方式:插件与内核,通过内核发布的特定接口进行通讯(通讯样式无限制)
3.1. 架构模型
The microkernel architecture pattern consists of two types of architecture components: a core system and plug-in modules. Application logic is divided between independent plug-in modules and the basic core system, providing extensibility, flexibility, and isolation of application features and custom processing logic.
由于许多的系统都是采用的类似架构设计,该架构模式因此得名。
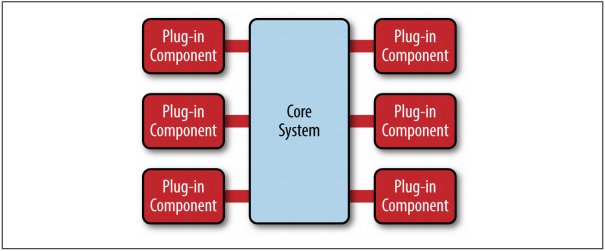
The microkernel architecture pattern consists of two types of architecture components: a core system and plug-in modules. Application logic is divided between independent plug-in modules and the basic core system, providing extensibility, flexibility, and isolation of application features and custom processing logic.
内核系统是一种最小化开发的、能够保证程序基本运行的应用。一般不包含业务层,基本的业务逻辑也是抽象化的通用性规则。而具体规则和业务逻辑,则通过不同的插件拓展实现。
The plug-in modules are stand-alone, independent components that contain specialized processing, additional features, and custom code that is meant to enhance or extend the core system to produce additional business capabilities. Generally, plug-in modules should be independent of other plug-in modules, but you can certainly design plug-ins that require other plug-ins to be present. Either way, it is important to keep the communication between plug-ins to a minimum to avoid dependency issues.
想要插件之间完全没有耦合是不合理的,但尽可能的减少插件之间的耦合,关系到整个体系的运转与维护。
The core system needs to know about which plug-in modules are available and how to get to them. One common way of implementing this is through some sort of plug-in registry. This registry contains information about each plug-in module, including things like its name, data contract, and remote access protocol details (depending on how the plug-in is connected to the core system). For example, a plug-in for tax software that flags high-risk tax audit items might have a registry entry that contains the name of the service (AuditChecker), the data contract (input data and output data), and the contract format (XML). It might also contain a WSDL (Web Services Definition Language) if the plug-in is accessed through SOAP.
一般的,插件通过注册机制挂载到内核上。内核将维持一个插件列表,以了解当前系统中的每一个组件。插件的挂载方式可以有多种,例如通过 dlopen( ) 将lib库载入内核进程内存;或是通过 SOA 模式加载服务项,并执行服务调用;或是通过点对点 socket 建立 romote object proxy 的队列,并执行RPC调用,等等。更多的方式见下一段:
Plug-in modules can be connected to the core system through a variety of ways, including OSGi (open service gateway initiative), messaging, web services, or even direct point-to-point binding (i.e., object instantiation). The type of connection you use depends on the type of application you are building (small product or large business application) and your specific needs (e.g., single deploy or distributed deployment). The architecture pattern itself does not specify any of these implementation details, only that the plug-in modules must remain independent from one another.
插件架构模式本身并没有限定core与module的连接方式——连接方式一般需要根据具体的应用场景选择不同的方案。
The contracts between the plug-in modules and the core system can range anywhere from standard contracts to custom ones. Custom contracts are typically found in situations where plug-in components are developed by a third party where you have no control over the contract used by the plug-in. In such cases, it is common to create an adapter between the plug-in contact and your standard contract so that the core system doesn’t need specialized code for each plug-in. When creating standard contracts (usually implemented through XML or a Java Map), it is important to remember to create a versioning strategy right from the start.
插件之间的通信方式也可以有多种实现,一般的建议使用通用协议,如HTTP或标准socket消息结构。
3.2. 小结
架构考量:
微内核的架构模式可以嵌入到其它的架构模式之中。微内核架构通过插件还可以提供逐步演化的功能和增量开发。所以如果你要开发基于产品的应用,微内核是不二选择。
模式分析:
- 总体灵活性: 高
- 发布易用性: 高
- 可测试性: 高
- 性能: 高
- 规模扩展性: 低
- 开发容易度: 低
优点:
- 良好的功能延伸性(extensibility),需要什么功能,开发一个插件即可
- 功能之间是隔离的,插件可以独立的加载和卸载,使得它比较容易部署,
- 可定制性高,适应不同的开发需要
- 可以渐进式地开发,逐步增加功能
缺点:
- 内核扩展性差:内核通常是一个独立单元,不容易做成分布式
- 开发难度相对较高,因为涉及到插件与内核的通信,以及内部的插件登记机制

 浙公网安备 33010602011771号
浙公网安备 33010602011771号