【入门】PyTorch安装及基础操作流程
1. 安装
默认安装的是 GPU-CUDA10.2 版本
pip install torch torchvision
如果是CPU:
pip install torch==1.6.0+cpu torchvision==0.7.0+cpu -f https://download.pytorch.org/whl/torch_stable.html
Windows/Mac平台或其他类型的CUDA,请参考官网。
2. 入门示例程序
2.1. Tensors, 张量
Numpy可以处理张量,但并不支持GPU进行运算。所以 torch 模块提供了numpy类似的张量运算接口。
Numpy is a great framework, but it cannot utilize GPUs to accelerate its numerical computations. For modern deep neural networks, GPUs often provide speedups of 50x or greater, so unfortunately numpy won’t be enough for modern deep learning.
import torch
import math
dtype = torch.float
device = torch.device("cpu")
# device = torch.device("cuda:0") # Uncomment this to run on GPU
# Create random input and output data
x = torch.linspace(-math.pi, math.pi, 2000, device=device, dtype=dtype)
y = torch.sin(x)
# Randomly initialize weights
a = torch.randn((), device=device, dtype=dtype)
b = torch.randn((), device=device, dtype=dtype)
c = torch.randn((), device=device, dtype=dtype)
d = torch.randn((), device=device, dtype=dtype)
learning_rate = 1e-6
for t in range(2000):
# Forward pass: compute predicted y
y_pred = a + b * x + c * x ** 2 + d * x ** 3
# Compute and print loss
loss = (y_pred - y).pow(2).sum().item()
if t % 100 == 99:
print(t, loss)
# Backprop to compute gradients of a, b, c, d with respect to loss
grad_y_pred = 2.0 * (y_pred - y)
grad_a = grad_y_pred.sum()
grad_b = (grad_y_pred * x).sum()
grad_c = (grad_y_pred * x ** 2).sum()
grad_d = (grad_y_pred * x ** 3).sum()
# Update weights using gradient descent
a -= learning_rate * grad_a
b -= learning_rate * grad_b
c -= learning_rate * grad_c
d -= learning_rate * grad_d
print(f'Result: y = {a.item()} + {b.item()} x + {c.item()} x^2 + {d.item()} x^3')
2.2. Autograd, 自动求导
在上面的例子里,需要我们手动实现神经网络的前向和后向传播。对于简单的两层网络,手动实现前向、后向传播不是什么难事,但是对于大型的复杂网络就比较麻烦了。
庆幸的是,我们可以使用自动微分来自动完成神经网络中反向传播的计算。PyTorch中autograd包提供的正是这个功能。当使用autograd时,网络前向传播将定义一个计算图;图中的节点是tensor,边是函数,这些函数是输出tensor到输入tensor的映射。这张计算图使得在网络中反向传播时梯度的计算十分简单。
这听起来复杂,但是实际操作很简单。如果我们想计算某些的tensor的梯度,我们只需要在建立这个tensor时加入这么一句:requires_grad=True 。这个tensor上的任何PyTorch的操作都将构造一个计算图,从而允许我们稍后在图中执行反向传播。如果这个tensorx的 requires_grad=True ,那么反向传播之后x.grad将会是另一个张量,其为x关于某个标量值的梯度。
有时可能希望防止PyTorch在 requires_grad=True 的张量执行某些操作时构建计算图;例如,在训练神经网络时,我们通常不希望通过权重更新步骤进行反向传播。在这种情况下,我们可以使用 torch.no_grad() 上下文管理器来防止构造计算图。
# 可运行代码见本文件夹中的 two_layer_net_autograd.py
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# N是批大小;D_in是输入维度;
# H是隐藏层维度;D_out是输出维度
N, D_in, H, D_out = 64, 1000, 100, 10
# 产生随机输入和输出数据
x = torch.randn(N, D_in, device=device)
y = torch.randn(N, D_out, device=device)
# 产生随机权重tensor,将requires_grad设置为True意味着我们希望在反向传播时候计算这些值的梯度
w1 = torch.randn(D_in, H, device=device, requires_grad=True)
w2 = torch.randn(H, D_out, device=device, requires_grad=True)
learning_rate = 1e-6
for t in range(500):
# 前向传播:使用tensor的操作计算预测值y。
# 由于w1和w2有requires_grad=True,涉及这些张量的操作将让PyTorch构建计算图,
# 从而允许自动计算梯度。由于我们不再手工实现反向传播,所以不需要保留中间值的引用。
y_pred = x.mm(w1).clamp(min=0).mm(w2)
# 计算并输出loss,loss是一个形状为()的张量,loss.item()是这个张量对应的python数值
loss = (y_pred - y).pow(2).sum()
print(t, loss.item())
# 使用autograd计算反向传播。这个调用将计算loss对所有requires_grad=True的tensor的梯度。
# 这次调用后,w1.grad和w2.grad将分别是loss对w1和w2的梯度张量。
loss.backward()
# 使用梯度下降更新权重。对于这一步,我们只想对w1和w2的值进行原地改变;不想为更新阶段构建计算图,
# 所以我们使用torch.no_grad()上下文管理器防止PyTorch为更新构建计算图
with torch.no_grad():
w1 -= learning_rate * w1.grad
w2 -= learning_rate * w2.grad
# 反向传播之后手动置零梯度
w1.grad.zero_()
w2.grad.zero_()
2.3. 定义自己的自动求导函数
在底层,每一个原始的自动求导运算实际上是两个在Tensor上运行的函数。其中,forward函数计算从输入Tensors获得的输出Tensors。而backward函数接收输出Tensors对于某个标量值的梯度,并且计算输入Tensors相对于该相同标量值的梯度。
在PyTorch中,我们可以很容易地通过定义torch.autograd.Function的子类并实现forward和backward函数,来定义自己的自动求导运算。之后我们就可以使用这个新的自动梯度运算符了。然后,我们可以通过构造一个实例并像调用函数一样,传入包含输入数据的tensor调用它,这样来使用新的自动求导运算。
这个例子中,我们自定义一个自动求导函数来展示ReLU的非线性。并用它实现我们的两层网络:
# 可运行代码见本文件夹中的 two_layer_net_custom_function.py
import torch
class MyReLU(torch.autograd.Function):
"""
我们可以通过建立torch.autograd的子类来实现我们自定义的autograd函数,
并完成张量的正向和反向传播。
"""
@staticmethod
def forward(ctx, x):
"""
在正向传播中,我们接收到一个上下文对象和一个包含输入的张量;
我们必须返回一个包含输出的张量,
并且我们可以使用上下文对象来缓存对象,以便在反向传播中使用。
"""
ctx.save_for_backward(x)
return x.clamp(min=0)
@staticmethod
def backward(ctx, grad_output):
"""
在反向传播中,我们接收到上下文对象和一个张量,
其包含了相对于正向传播过程中产生的输出的损失的梯度。
我们可以从上下文对象中检索缓存的数据,
并且必须计算并返回与正向传播的输入相关的损失的梯度。
"""
x, = ctx.saved_tensors
grad_x = grad_output.clone()
grad_x[x < 0] = 0
return grad_x
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# N是批大小; D_in 是输入维度;
# H 是隐藏层维度; D_out 是输出维度
N, D_in, H, D_out = 64, 1000, 100, 10
# 产生输入和输出的随机张量
x = torch.randn(N, D_in, device=device)
y = torch.randn(N, D_out, device=device)
# 产生随机权重的张量
w1 = torch.randn(D_in, H, device=device, requires_grad=True)
w2 = torch.randn(H, D_out, device=device, requires_grad=True)
learning_rate = 1e-6
for t in range(500):
# 正向传播:使用张量上的操作来计算输出值y;
# 我们通过调用 MyReLU.apply 函数来使用自定义的ReLU
y_pred = MyReLU.apply(x.mm(w1)).mm(w2)
# 计算并输出loss
loss = (y_pred - y).pow(2).sum()
print(t, loss.item())
# 使用autograd计算反向传播过程。
loss.backward()
with torch.no_grad():
# 用梯度下降更新权重
w1 -= learning_rate * w1.grad
w2 -= learning_rate * w2.grad
# 在反向传播之后手动清零梯度
w1.grad.zero_()
w2.grad.zero_()
2.4. 使用神经网络模块nn
计算图和autograd是十分强大的工具,可以定义复杂的操作并自动求导;然而对于大规模的网络,autograd太过于底层。
在构建神经网络时,我们经常考虑将计算安排成层,其中一些具有可学习的参数,它们将在学习过程中进行优化。
TensorFlow里,有类似Keras,TensorFlow-Slim和TFLearn这种封装了底层计算图的高度抽象的接口,这使得构建网络十分方便。
在PyTorch中,包nn完成了同样的功能。nn包中定义一组大致等价于层的模块。一个模块接受输入的tesnor,计算输出的tensor,而且还保存了一些内部状态比如需要学习的tensor的参数等。nn包中也定义了一组损失函数(loss functions),用来训练神经网络。
这个例子中,我们用nn包实现两层的网络:
# 可运行代码见本文件夹中的 two_layer_net_nn.py
import torch
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# N是批大小;D是输入维度
# H是隐藏层维度;D_out是输出维度
N, D_in, H, D_out = 64, 1000, 100, 10
# 产生输入和输出随机张量
x = torch.randn(N, D_in, device=device)
y = torch.randn(N, D_out, device=device)
# 使用nn包将我们的模型定义为一系列的层。
# nn.Sequential是包含其他模块的模块,并按顺序应用这些模块来产生其输出。
# 每个线性模块使用线性函数从输入计算输出,并保存其内部的权重和偏差张量。
# 在构造模型之后,我们使用.to()方法将其移动到所需的设备。
model = torch.nn.Sequential(
torch.nn.Linear(D_in, H),
torch.nn.ReLU(),
torch.nn.Linear(H, D_out),
).to(device)
# nn包还包含常用的损失函数的定义;
# 在这种情况下,我们将使用平均平方误差(MSE)作为我们的损失函数。
# 设置reduction='sum',表示我们计算的是平方误差的“和”,而不是平均值;
# 这是为了与前面我们手工计算损失的例子保持一致,
# 但是在实践中,通过设置reduction='elementwise_mean'来使用均方误差作为损失更为常见。
loss_fn = torch.nn.MSELoss(reduction='sum')
learning_rate = 1e-4
for t in range(500):
# 前向传播:通过向模型传入x计算预测的y。
# 模块对象重载了__call__运算符,所以可以像函数那样调用它们。
# 这么做相当于向模块传入了一个张量,然后它返回了一个输出张量。
y_pred = model(x)
# 计算并打印损失。我们传递包含y的预测值和真实值的张量,损失函数返回包含损失的张量。
loss = loss_fn(y_pred, y)
print(t, loss.item())
# 反向传播之前清零梯度
model.zero_grad()
# 反向传播:计算模型的损失对所有可学习参数的导数(梯度)。
# 在内部,每个模块的参数存储在requires_grad=True的张量中,
# 因此这个调用将计算模型中所有可学习参数的梯度。
loss.backward()
# 使用梯度下降更新权重。
# 每个参数都是张量,所以我们可以像我们以前那样可以得到它的数值和梯度
with torch.no_grad():
for param in model.parameters():
param.data -= learning_rate * param.grad
2.5. 设计你自己的CNN类
通过继承nn.Module并定义forward函数,这个forward函数可以使用其他模块或者其他的自动求导运算来接收输入tensor,产生输出tensor。
# 可运行代码见本文件夹中的 two_layer_net_module.py
import torch
class TwoLayerNet(torch.nn.Module):
def __init__(self, D_in, H, D_out):
"""
在构造函数中,我们实例化了两个nn.Linear模块,并将它们作为成员变量。
"""
super(TwoLayerNet, self).__init__()
self.linear1 = torch.nn.Linear(D_in, H)
self.linear2 = torch.nn.Linear(H, D_out)
def forward(self, x):
"""
在前向传播的函数中,我们接收一个输入的张量,也必须返回一个输出张量。
我们可以使用构造函数中定义的模块以及张量上的任意的(可微分的)操作。
"""
h_relu = self.linear1(x).clamp(min=0)
y_pred = self.linear2(h_relu)
return y_pred
# N是批大小; D_in 是输入维度;
# H 是隐藏层维度; D_out 是输出维度
N, D_in, H, D_out = 64, 1000, 100, 10
# 产生输入和输出的随机张量
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
# 通过实例化上面定义的类来构建我们的模型。
model = TwoLayerNet(D_in, H, D_out)
# 构造损失函数和优化器。
# SGD构造函数中对model.parameters()的调用,
# 将包含模型的一部分,即两个nn.Linear模块的可学习参数。
loss_fn = torch.nn.MSELoss(reduction='sum')
optimizer = torch.optim.SGD(model.parameters(), lr=1e-4)
for t in range(500):
# 前向传播:通过向模型传递x计算预测值y
y_pred = model(x)
#计算并输出loss
loss = loss_fn(y_pred, y)
print(t, loss.item())
# 清零梯度,反向传播,更新权重
optimizer.zero_grad()
loss.backward()
optimizer.step()
2.6. 控制流和参数共享
作为动态图和权重共享的一个例子,我们实现了一个非常奇怪的模型:一个全连接的ReLU网络,在每一次前向传播时,它的隐藏层的层数为随机1到4之间的数,这样可以多次重用相同的权重来计算。
因为这个模型可以使用普通的Python流控制来实现循环,并且我们可以通过在定义转发时多次重用同一个模块来实现最内层之间的权重共享。
我们利用Mudule的子类很容易实现这个模型:
# 可运行代码见本文件夹中的 dynamic_net.py
import random
import torch
class DynamicNet(torch.nn.Module):
def __init__(self, D_in, H, D_out):
"""
在构造函数中,我们构造了三个nn.Linear实例,它们将在前向传播时被使用。
"""
super(DynamicNet, self).__init__()
self.input_linear = torch.nn.Linear(D_in, H)
self.middle_linear = torch.nn.Linear(H, H)
self.output_linear = torch.nn.Linear(H, D_out)
def forward(self, x):
"""
对于模型的前向传播,我们随机选择0、1、2、3,
并重用了多次计算隐藏层的middle_linear模块。
由于每个前向传播构建一个动态计算图,
我们可以在定义模型的前向传播时使用常规Python控制流运算符,如循环或条件语句。
在这里,我们还看到,在定义计算图形时多次重用同一个模块是完全安全的。
这是Lua Torch的一大改进,因为Lua Torch中每个模块只能使用一次。
"""
h_relu = self.input_linear(x).clamp(min=0)
for _ in range(random.randint(0, 3)):
h_relu = self.middle_linear(h_relu).clamp(min=0)
y_pred = self.output_linear(h_relu)
return y_pred
# N是批大小;D是输入维度
# H是隐藏层维度;D_out是输出维度
N, D_in, H, D_out = 64, 1000, 100, 10
# 产生输入和输出随机张量
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
# 实例化上面定义的类来构造我们的模型
model = DynamicNet(D_in, H, D_out)
# 构造我们的损失函数(loss function)和优化器(Optimizer)。
# 用平凡的随机梯度下降训练这个奇怪的模型是困难的,所以我们使用了momentum方法。
criterion = torch.nn.MSELoss(reduction='sum')
optimizer = torch.optim.SGD(model.parameters(), lr=1e-4, momentum=0.9)
for t in range(500):
# 前向传播:通过向模型传入x计算预测的y。
y_pred = model(x)
# 计算并打印损失
loss = criterion(y_pred, y)
print(t, loss.item())
# 清零梯度,反向传播,更新权重
optimizer.zero_grad()
loss.backward()
optimizer.step()
3. Pytorch编写代码基本步骤思想
分为四大步骤:
- 输入处理模块(X 输入数据,变成网络能够处理的Tensor类型)
- 模型构建模块(主要负责从输入的数据,得到预测的y^, 这就是我们经常说的前向过程)
- 定义代价函数和优化器模块(注意,前向过程只会得到模型预测的结果,并不会自动求导和更新,是由这个模块进行处理)
- 构建训练过程(迭代训练过程,就是上图表情包的训练迭代过程)
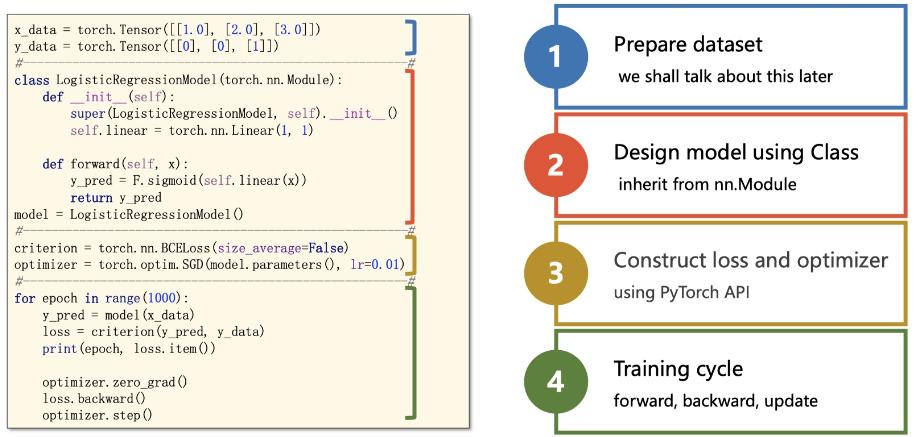
3.1. 数据处理
对于数据处理,最为简单的⽅式就是将数据组织成为⼀个Tensor。但许多训练需要⽤到mini-batch,直接组织成Tensor不便于我们操作。pytorch为我们提供了Dataset和Dataloader两个类来方便的构建。
torch.utils.data.Dataset
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False)
3.2. 模型构建
3.3. 前向传播与反向传播
所有的模型都需要继承 torch.nn.Module ,另需要定义前向传播函数 forward(),不需要考虑反向传播(模型自动完成)。
- 前向传播:即使用模型的当前参数值预测结果
- 反向传播:根据损失值,调整参数的过程
3.4. 激活函数
在神经网络中,对于图像,我们主要采用了卷积的方式来处理,也就是对每个像素点赋予一个权值,这个操作显然就是线性的。但是对于我们的样本来说,不一定是线性可分的,为了解决这个问题,我们可以进行线性变化,或者我们引入非线性因素,解决线性模型所不能解决的问题。
这就是为什么要有激活函数:激活函数是用来加入非线性因素的,因为线性模型的表达力不够。
所谓激活函数,并不是去激活什么,而是指如何把“激活的神经元的特征”通过函数把特征保留并映射出来(保留特征,去除一些数据中是的冗余),这是神经网络能解决非线性问题关键。
- sigmoid
- ReLU——“抹零”
- softmax
- log_softmax
3.5. 网络骨架:nn.Moudule
3.5.1. Backbone
3.6. 定义代价函数和优化器
3.6.1. 损失函数(loss function)
- 分类任务: 交叉熵_CrossEntropy
- 常规回归: MSELoss
criterion = torch.nn.MSELoss(reduction='sum')
3.6.2. 优化器(Optimizer)
梯度的方向指明了误差扩大的方向,因此在更新权重的时候需要对其取反,从而减小权重引起的误差。
- SGD(梯度下降)
- Adam
optimizer = torch.optim.SGD(model.parameters(), lr=1e-4, momentum=0.9)
3.7. 构建训练过程
def train(epoch): # 一个epoch的训练
for i, data in enumerate(dataloader, 0):
x, y = data # 取出minibatch数据和标签
y_pred = model(x) # 前向传播
loss = criterion(y_pred, y) # 计算代价函数
optimizer.zero_grad() # 清零梯度准备计算
1oss.backward() # 反向传播
optimizer.step() # 更新训练参数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号