
Git设计浅析
Git在今天已经是一个非常流行甚至说是普及的一个工具了,但如果考虑到它是诞生在2005年,可以说它在当时是非常超前的一个作品。
要了解它的设计和设计背后的考量,我们需要先穿越回到15年前,来看一看Git出生前的背景。
最近有一个很热的网剧,就是以2005年作为故事的背景。2005年时的电脑还有很多是大屁股,但是液晶显示器也开始出现了。
手机可能是这样的

或者是这样的

家用电脑和网络已经比较普及,但是网速和计算机处理速度和今天差距依然很大。
但是WIFI还不是那么普及,手机不限流量量套餐还很昂贵,速度也很慢,网络还不是随时随地可用。
而Git设计之初,想要解决的是Linux内核的软件版本控制,下图只是Debian系的不同发行版的发布状况。
而Linux的内核,可想而知应该是相当规模的一个项目。

整个开发团队处于一个比较分布式的状态。,使用中心化的版本控制,不可避免的就是慢,提交多的时候服务器必然会慢,特别是有CI/CD的情况。
所以就必须解决分布式团队使用的效率问题,因此Git引入了一个暂存区的概念:
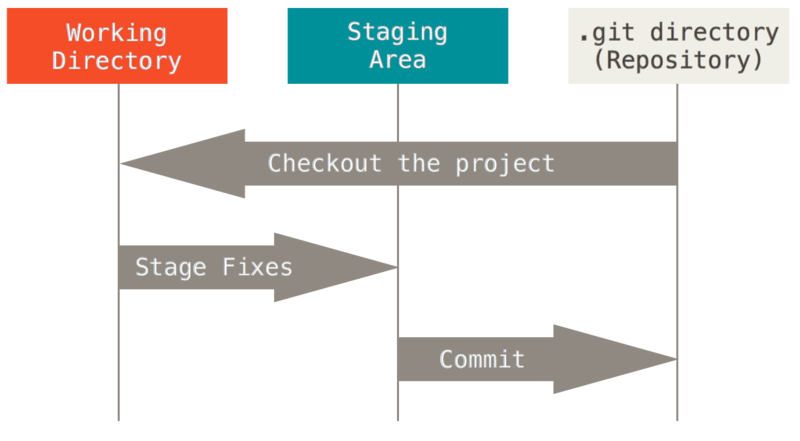
通过暂存区,可以对比本地修改和已有记录的区别,并将这部分修改提交到本地仓库。
以前需要在服务器才能做对比,进行的冲突处理,可以在本地的暂存区处理好之后再进行提交。
至此,使用Git的开发者可以在坐火车坐飞机等等一系列没有网络的环境里提交代码了。
为了实现这样的功能,Git使用了怎样的设计呢?
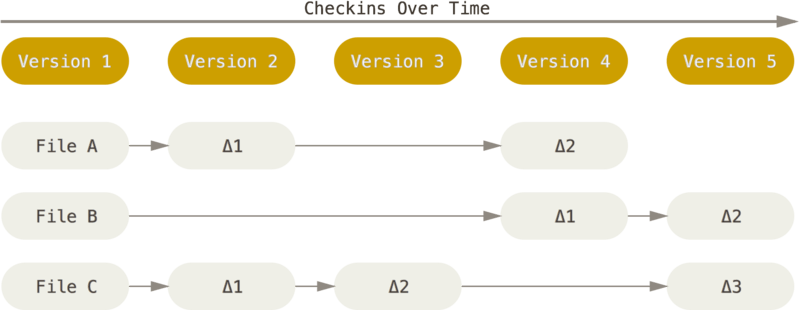
下图是增量式存取的版本控制系统的处理方式,在文件出现的最初版本,存取文件的完整内容,此后存取每个版本改变的内容。
而Git使用了一种快照流的设计,每一版本,存取的都是文件的完整内容的快照,即使A1只是A文件修改了一行,也存取A1的完整内容的快照。
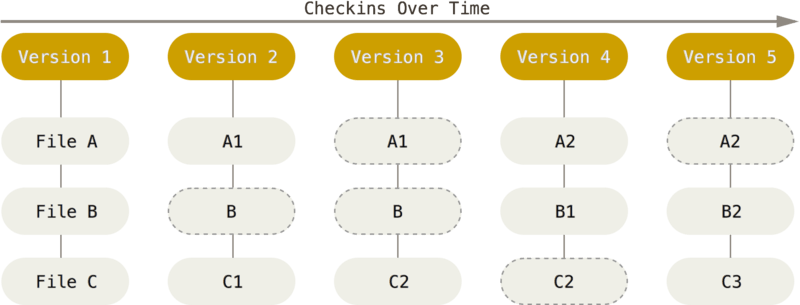
这样的设计,可以更快速的获取特定版本的所有文件。
看起来占用的空间会大很多,特别在A1和A差异小的情况,解决这个问题,git使用了打包的方式,或者说是gc。
git隔一段时间就会将文件名相同或类似的文件对比,打包压缩存储,从而节省空间。
这部分的详细介绍,可以参考 https://git-scm.com/book/zh/v2/Git-%E5%86%85%E9%83%A8%E5%8E%9F%E7%90%86-%E5%8C%85%E6%96%87%E4%BB%B6
那git是怎么管理这一系列快照流的呢?
参考 https://git-scm.com/book/zh/v2/Git-%E5%86%85%E9%83%A8%E5%8E%9F%E7%90%86-Git-%E5%AF%B9%E8%B1%A1
在网络传输不可靠的时候,常见的做内容校验的方法就是检查消息摘要,常见的是md5sum,现在很多网站仍然会提供下载文件的md5sum值。
关于散列函数的简单介绍可以参考 https://www.cnblogs.com/liyutian/p/9525173.html
Git将一般的文件内容存储为blob对象,blob对象的文件名用文件内容+Git特有的头部信息做Sha1运算,得到一个hash,前两位用作Git对象的目录名,后面的用作blob对象的文件名。
但这只保存了内容,后面介绍文件名的处理。
sha1算法原理简介 https://www.cnblogs.com/scu-cjx/p/6878853.html
在05年,SHA1还是一个性能不错,安全性很好的安全散列算法。虽然后面提出Sha1的碰撞问题,因为Git会加自己的首部,所以这个也并不会成为一个安全上的问题。
详细的解释,可以参考 https://stackoverflow.com/questions/9392365/how-would-git-handle-a-sha-1-collision-on-a-blob/9392525#9392525
简单结论是,Sha1的碰撞不会成为Git仓库的一个安全上的问题。
因为替换也需要一个成本,所以到现在也一直没有替换这个散列算法。
类似的,git引入了tree对象,解决文件名的保存和文件的组织问题(类似与Unix系统的文件夹)
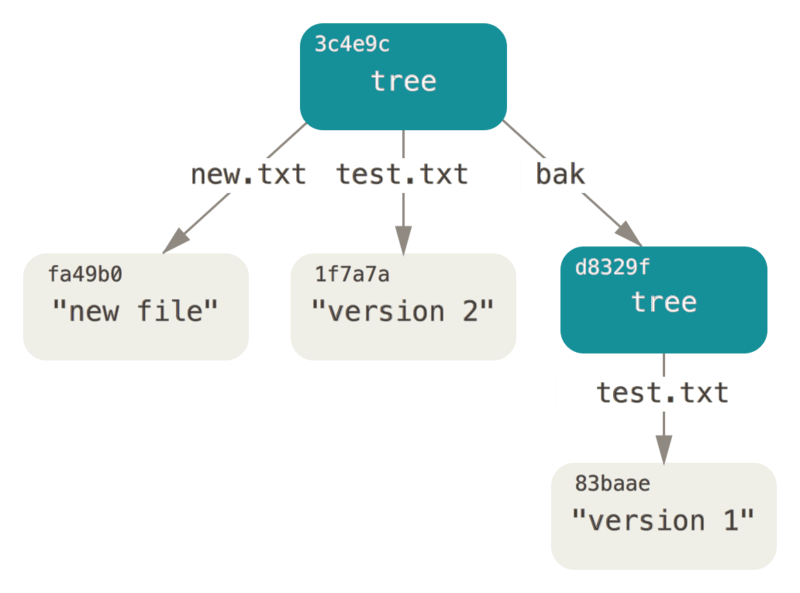
这个tree对象,底层的数据结构就是Merkle tree,Merkle是一个著名的密码学家,这个数据结构是以他的名字命名的。
Merkle tree的详细介绍网上很多,推荐这篇 https://www.cnblogs.com/fengzhiwu/p/5524324.html ,Merkle tree对一个信息的完整性和可信性校验,是很多现代技术的基础,比如P2P,区块链,等等。
这样可以让Git比较快速和方便的确定整个代码仓库的内容是正确可靠的,是Git实现分布式的基础。
类似的commit的对象,在tree对象的基础之上,增加了一些作者,提交信息,时间戳等信息,方便查询和管理。
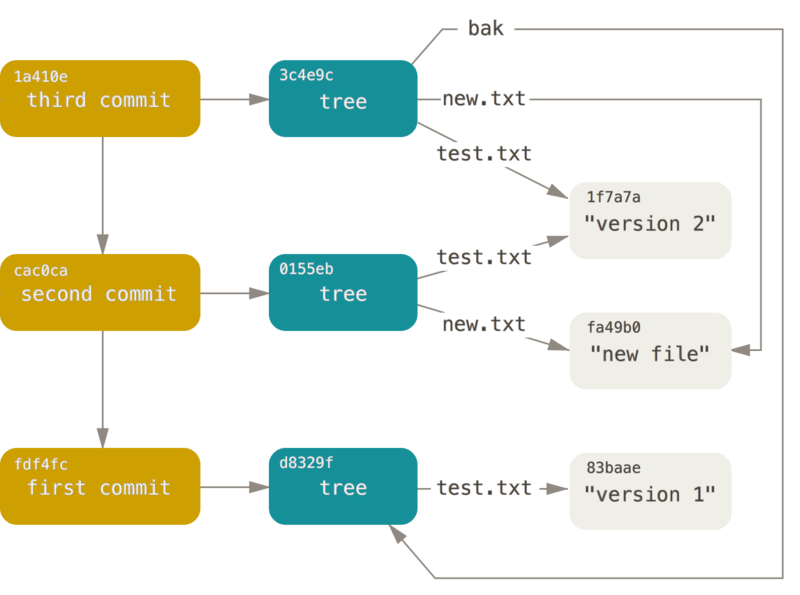
类似与上图不同commit之间也是类似于树形的关系,就形成了一个仓库的提交记录。
blob,tree和commit就是git最基础,最核心的对象。
有了这些做基础,基本上快照链就实现了,但是快照链只是工具,是过程,目标是多分支。
那么多分支是如何设计实现的呢?
因为Sha1产生的消息摘要有40位,而且可读性很差,不方便交流使用,所以git在很多地方,用hash值的前几位,常见的是6位,如上图来做别名。
而为了更方便的使用,Git设计了引用,用一个引用文件,来记录分支信息和commit的关系。
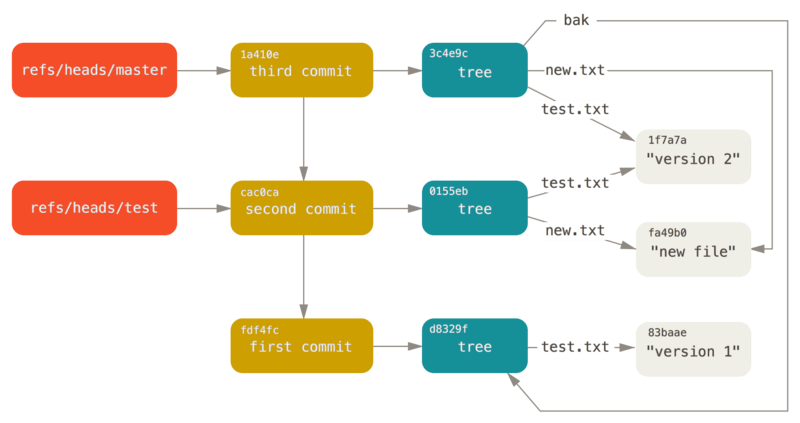
这样即使分支众多,只是增加了存储对应关系的部分,不会增加很多存储成本,而且切换速度很快。
在Git中标签和分支是类似的,也属于引用,主要是记录commit的关联关系,但和分支不同,tag是作为git对象存储的。
至此,Git就解决了多分支,分布式和性能的问题了。
至于后面分支合并,git work flow那就是用户的使用问题了。
参考资料:
https://git-scm.com/book/zh/v2
本文图片来源于网络如有侵权,请告知删除

