
某站视频python抓取: m3u8转mp4
之前利用python简单爬虫抓过一些图片,最近想到了抓取视频。由于很多地方视频不提供下载。所以觉得有必要学习一下,以备不时之需。备注:这里仅记录碰到的网站视频实例,不保证适用所有情况。
基本概念与思路
目标问题是,在某视频网站下载喜欢的视频文件并保存为MP4格式。这里涉及到几种文件格式。一般网络视频都采用的流协议,具体内容非专业领域不是很了解,不深入讨论。在我想抓取的视频站中,发现原视频数据分割为很多个TS流,每个TS流的地址记录在m3u8文件列表中,如图所示:
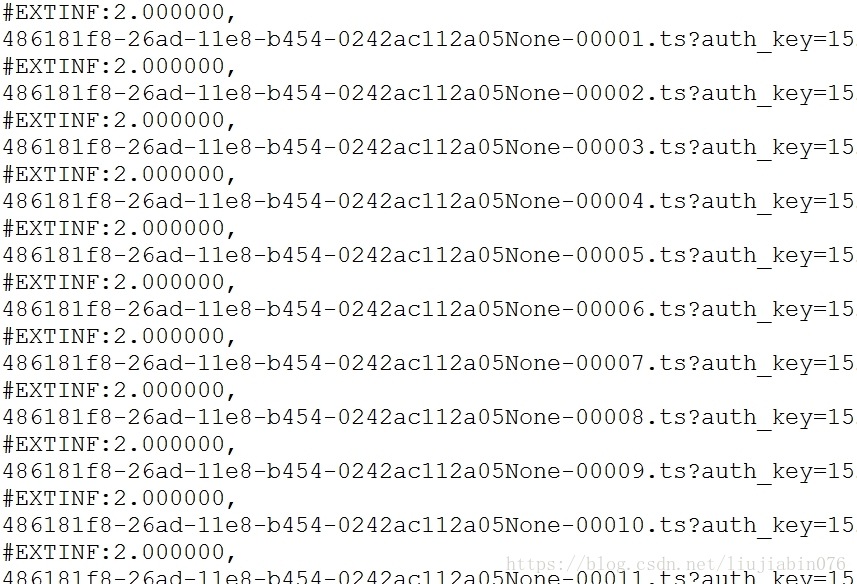
所以解决问题的思路边是:第一步,抓取目标视频的m3u8的地址URL;第二步,提取提取TS流;最后,合并流成MP4格式。 在搜素相关解决办法时,发现可以利用FFMPEG可以直接实现m3u8 转MP4。流程图如下:
代码实现:
import re
import uuid
import subprocess
import requests
QUALITY = 'ld' # video quality maybe 'ld' 'sd' or 'hd'
def get_video_ids_from_url(url):
html = requests.get(url, headers=HEADERS).text
video_ids = re.findall(r'data-lens-id="(\d+)"', html)
#print(video_ids)
if video_ids:
return set([int(video_id) for video_id in video_ids])
return []
def yield_video_m3u8_url_from_video_ids(video_ids):
for video_id in video_ids:
api_video_url = 'https://lens.zhihu.com/api/videos/{}'.format(int(video_id)) # 下载的是知乎视频
#print(api_video_url)
r = requests.get(api_video_url, headers=HEADERS)
playlist = r.json()['playlist']
print(playlist)
m3u8_url = playlist[QUALITY]['play_url']
yield m3u8_url
def download(url):
video_ids = get_video_ids_from_url(url)
m3u8_list = list(yield_video_m3u8_url_from_video_ids(video_ids))
filename = '{}.mp4'.format(uuid.uuid4())
path = ""
for idx, m3u8_url in enumerate(m3u8_list):
# here \" and \" is important!
cmd_str = 'ffmpeg -i \"' + m3u8_url + '\" ' + '-acodec copy -vcodec copy -absf aac_adtstoasc ' + path + filename.format(str(idx))
print(cmd_str)
subprocess.call(cmd_str,shell=True )
if __name__ == '__main__': # 贴上你需要下载的 回答或者文章的链接
url = 'your video page url'
download(url)上面代码自动搜素m3u8文件链接,如果不是批处理,可手动查询地址然后进行后续转码。在方法windows 与linux 均有效。
