
基于mapreduce实现图的三角形计数
源代码放在我的github上,想细致了解的可以访问:TriangleCount on github
一、实验要求
1.1 实验背景
图的三角形计数问题是一个基本的图计算问题,是很多复杂网络分析(比如社交网络分析)的基础。目前图的三角形计数问题已经成为了 Spark 系统中 GraphX 图计算库所提供的一个算法级 API。本次实验任务就是要在 Hadoop 系统上实现图的三角形计数任务。
1.2 实验任务
一个社交网络可以看做是一张图(离散数学中的图)。社交网络中的人对应于图的顶点;社交网络中的人际关系对应于图中的边。在本次实验任务中,我们只考虑一种关系——用户之间的关注关系。假设“王五”在 Twitter/微博中关注了“李四”,则在社交网络图中,有一条对应的从“王五”指向“李四”的有向边。图 1 中展示了一个简单的社交网络图,人之间的关注关系通过图中的有向边标识了出来。本次的实验任务就是在给定的社交网络图中,统计图中所有三角形的数量。在统计前,需要先进行有向边到无向边的转换,依据如下逻辑转换:
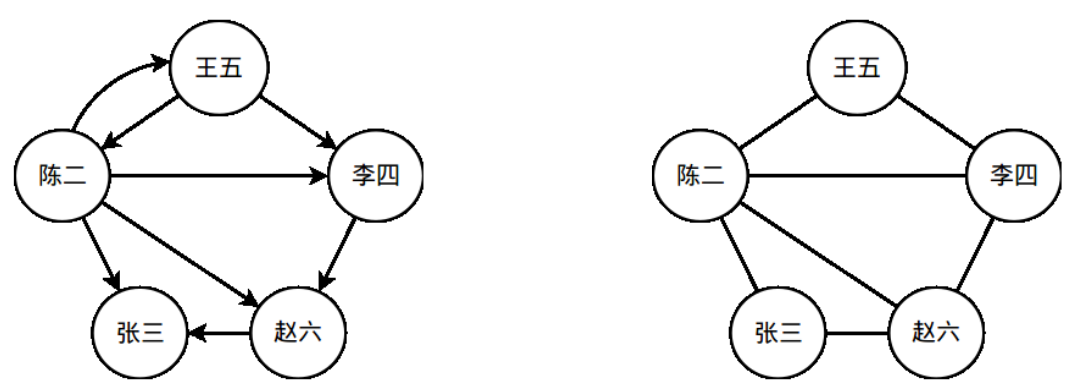
图 1 一个简单的社交网络示例。左侧的是一个社交网络图,右侧的图是将左侧图中的有向边转换为无向边后的无向图。
1.3 输入说明
输入数据仅一个文件。该文件由若干行组成,每一行由两个以空格分隔的整数组成:
A,B 分别是两个顶点的 ID。这一行记录表示图中具有一条由 A 到 B 的有向边。整个图的结构由该文件唯一确定。
下面的框中是文件部分内容的示例:
87982906 17975898
17809581 35664799
524620711 270231980
247583674 230498574
348281617 255810948
159294262 230766095
14927205 5380672
1.4 扩展
-
扩展一:挑战更大的数据集!使用 Google+的社交关系网数据集作为输入数据集。
-
扩展二:考虑将逻辑转换由or改为and的三角形个数是多少,改变后的逻辑转换如下:
二、实验设计与实现
2.1 算法设计
- step1:统计图中每一个点的度,不关心是入度还是出度,然后对统计到的所有点的度进行排序
- step2:将图中每一条单向边转换成双向边,对于图中a->b and b->a的两条边,分别转换后需要去重,在转换后的图中筛选出小度指向大度的边来建立邻接表,然后对每个点的邻接点按从小到大进行排序
- step3:对原图中的边进行转换,确保每条边是由数值小的点指向数值大的点并去重,然后遍历每一条边:求边的两个端点对应的邻接点集的交集大小即为包含这条边的三角形个数。对每条边对应的三角形个数进行累加即可得到全图包含的三角形个数。
2.2 程序设计
- 根据算法步骤将程序设计成4个job来实现:
- job:OutDegreeStat用于对每个点的度进行统计,在类OutDegreeStat中实现
- job:SortedOutDegree用于对所有点的度进行排序,在类OutDegreeStat中实现,在job1之后运行
- job:EdgeConvert用于建立存储小度指向大度的边的邻接表,在类EdgeConvert中实现
- job:GraphTriangleCount用于遍历每条边求端点对应邻接点集的交集来对三角形进行计数,在类GraphTriangleCount中实现
2.3 程序实现
-
job:OutDegreeStat的实现:
-
Map阶段:(vertex1: Text, vertex2: Text) -> (vertex1: Text, 1: IntWritable) and (vertex2: Text, 1: IntWritable),实现代码如下:
public static class OutDegreeStatMapper extends Mapper<Object, Text, Text, IntWritable> { private final IntWritable one = new IntWritable(1); @Override public void map(Object key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); StringTokenizer itr = new StringTokenizer(line); Text vertex1 = new Text(itr.nextToken()); Text vertex2 = new Text(itr.nextToken()); if (!vertex1.equals(vertex2)) { context.write(vertex1, one); context.write(vertex2, one); } } } -
Reduce阶段:(vertex: Text, degree: Iterable<IntWritable>) -> (vertex: Text, degreeSum: IntWritable),实现代码如下:
public static class OutDegreeStatReducer extends Reducer<Text, IntWritable, Text, IntWritable> { @Override public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val: values) { sum += val.get(); } context.write(key, new IntWritable(sum)); } } -
Combiner阶段:Combiner逻辑与Reduce逻辑一致,只是为了减少数据量从而减少通信开销
-
-
job:SortedOutDegree的实现:
- Map阶段:由于mapreduce的reduce阶段会按key进行排序,为了按度进行排序,只需用hadoop自带的InverseMapper类对键值对做逆映射(vertex: Text, degree: IntWritable) -> (degree: IntWritable, vertex: Text)即可。
- Reduce阶段:无需设置Reducer类,hadoop的Reduce阶段自动会对degree进行排序
-
job:EdgeConvert的实现:
-
Map阶段:(vertex1: Text, vertex2: Text) -> (vertex1: Text, vertex2: Text) and (vertex2: Text, vertex1: Text),实现代码如下:
public static class EdgeConvertMapper extends Mapper<Object, Text, Text, Text> { @Override public void map(Object key, Text value, Context context) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); Text vertex1 = new Text(itr.nextToken()); Text vertex2 = new Text(itr.nextToken()); if (!vertex1.equals(vertex2)) { context.write(vertex1, vertex2); context.write(vertex2, vertex1); } } } -
Reduce阶段:在setup函数中读取存储节点度的文件,在reduce函数中(vertex1: Text, vertex2List: iterable<Text>) -> (vertex1 with minimal degree: Text, vertex2 with maximal degree: Text),在对邻接表节点进行排序时,要重写一个String Comparator,让String按它所表示的数值大小进行比较,实现代码如下:
public static class EdgeConvertReducer extends Reducer<Text, Text, Text, Text> { private Map<String, Integer> degree; private Map<String, Boolean> edgeExisted; private URI[] cacheFiles; @Override public void setup(Context context) throws IOException, InterruptedException { degree = new HashMap<String, Integer>(); //读取存储节点度的文件 Configuration conf = context.getConfiguration(); cacheFiles = context.getCacheFiles(); for (int i = 0; i < cacheFiles.length; i++) { SequenceFile.Reader reader = new SequenceFile.Reader(conf, SequenceFile.Reader.file(new Path(cacheFiles[i]))); IntWritable key = new IntWritable(); Text value = new Text(); int cnt = 0; while (reader.next(key, value)) { degree.put(value.toString(), cnt); cnt++; } reader.close(); } } @Override public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException{ Text vertex = new Text(); List<String> outvertex = new ArrayList<String>(); edgeExisted = new HashMap<String, Boolean>(); //记录已处理边以避免重复统计 for (Text val: values) { if (!edgeExisted.containsKey(val.toString())) { edgeExisted.put(val.toString(), true); //比较边两个端点的度大小 if (degree.get(val.toString()) > degree.get(key.toString())) { outvertex.add(val.toString()); } } } //对邻接节点从小到大进行排序,方便后续求交集 Collections.sort(outvertex, new ComparatorString()); for (String vt: outvertex) { vertex.set(vt); context.write(key, vertex); } } } //继承String比较器按它所表示的数值大小进行比较 public static class ComparatorString implements Comparator<String> { public int compare(String a, String b) { if (a.length() > b.length()) { return 1; } else if (a.length() < b.length()){ return -1; } else { return a.compareTo(b); } } }
-
-
job:GraphTriangleCount的实现:
-
Map阶段:以job:EdgeConvert的输出文件作为读入,该文件不包含重复边因此无需判断转换,直接按原样映射(vertex1: Text, vertex2: Text) -> (vertex1: Text, vertex2: Text)即可,实现代码如下:
public static class GraphTriangleCountMapper extends Mapper<Text, Text, Text, Text> { @Override public void map(Text key, Text value, Context context) throws IOException, InterruptedException{ context.write(key, value); } } -
Reduce阶段:在setup函数中读取存储小度指向大度的邻接表文件,在reduce函数中(vertex1: Text, vertex2List: Iterable<Text>) -> ("TriangleNum": Text, triangleNum: LongWritable),在cleanup函数中写当前这个reducer的三角形计数结果,实现代码如下:
public static class GraphTriangleCountReducer extends Reducer<Text, Text, Text, LongWritable> { private final static String edgePath = TriangleCountDriver.HDFS_PATH + TriangleCountDriver.EdgeConvertPath; //邻接表文件路径 private Map<String, Integer> vexIndex; //存储节点的邻接表索引 private ArrayList<ArrayList<String>> vec = new ArrayList<ArrayList<String>>(); //存储全局邻接表 private long triangleNum = 0; @Override public void setup(Context context) throws IOException, InterruptedException { int cnt = 0; String lastVertex = ""; String sv, tv; ArrayList<String> outVertices = new ArrayList<String>(); vexIndex = new TreeMap<String, Integer>(); //获取文件系统的接口 Configuration conf = context.getConfiguration(); FileSystem fs = FileSystem.get(conf); //读取小度指向大度的边邻接表 for (FileStatus fst: fs.listStatus(new Path(edgePath))) { if (!fst.getPath().getName().startsWith("_")) { SequenceFile.Reader reader = new SequenceFile.Reader(conf, SequenceFile.Reader.file(fst.getPath())); Text key = new Text(); Text value = new Text(); while (reader.next(key, value)) { sv = key.toString(); tv = value.toString(); if (!sv.equals(lastVertex)) { if (cnt != 0) vec.add(outVertices); vexIndex.put(sv, cnt); cnt++; outVertices = new ArrayList<String>(); outVertices.add(tv); } else { outVertices.add(tv); } lastVertex = sv; } reader.close(); } } vec.add(outVertices); } @Override public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException{ for (Text val: values) if (vexIndex.containsKey(val.toString())) //调用求交集函数获取包含边(key,val)的三角形个数 triangleNum += intersect(vec.get(vexIndex.get(key.toString())), vec.get(vexIndex.get(val.toString()))); } @Override public void cleanup(Context context) throws IOException, InterruptedException{ //将计数结果写入文件 context.write(new Text("TriangleNum"), new LongWritable(triangleNum)); } //求有序集合的交集 private long intersect(ArrayList<String> avex, ArrayList<String> bvex) { long num = 0; int i = 0, j = 0; int cv; while (i != avex.size() && j != bvex.size()) { if (avex.get(i).length() > bvex.get(j).length()) { cv = 1; } else if (avex.get(i).length() < bvex.get(j).length()) { cv = -1; } else { cv = avex.get(i).compareTo(bvex.get(j)); } if (cv == 0) { i++; j++; num++; } else if (cv > 0) { j++; } else { i++; } } return num; } }
-
2.4 扩展2的设计与实现
-
对于a->b and b->a then a-b的条件,只需改变job:EdgeConvert的实现即可,新建一个job:UndirectionalEdgeConvert:
-
Map阶段:以原数据文件作为输入进行映射转换:(vertex1: Text, vertex2: Text) -> ((vertex1, vertex2): Text, flag: Text) and ((vertex2, vertex1): Text, flag:Text),按vertex1进行分区,其中flag作为节点序标记,用于帮助在Reducer中对双向边进行判断,如果输入的vertex1 > vertex2则flag置1,如果vertex1 < vertex2则flag置0,实现代码如下:
public static class UndirectionalEdgeConvertMapper extends Mapper<Object, Text, Text, Text> { @Override public void map(Object key, Text value, Context context) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); String vertex1 = itr.nextToken(); String vertex2 = itr.nextToken(); String flag = "0"; //节点序标记,帮助Reducer判断双向边 if (!vertex1.equals(vertex2)) { if (vertex1.compareTo(vertex2) > 0) flag = "1"; context.write(new Text(vertex1 + '\t' + vertex2), new Text(flag)); context.write(new Text(vertex2 + '\t' + vertex1), new Text(flag)); } } } -
Reduce阶段:((vertex1, vertex2): Text, flagList: Iterable<Text>) -> (vertex1 with minimal degree: Text, vertex2 with maximal degree: Text),如果flagList既包含0又包含1,则(vertex1, verex2)属于双向边,然后判断如果vertex2的度大于vertex1,则将vertex2加入到vertex1的邻接表中,reduce函数部分的实现代码如下:
@Override public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException{ String[] term = key.toString().split("\t"); //如果邻接表出点变了则写出lastkey为出点的邻接表 if (!lastKey.equals(term[0])) { if (outvertex.size() != 0) { Text vertex = new Text(); Text lastKeyText = new Text(lastKey); Collections.sort(outvertex, new EdgeConvert.ComparatorString()); for (String vt: outvertex) { vertex.set(vt); context.write(lastKeyText, vertex); } outvertex = new ArrayList<String>(); } } //判断(term[0], term[1])是否是双向边 boolean flag0 = false, flag1 = false; for (Text val: values) { if (val.toString().equals("0")) flag0 = true; else flag1 = true; } if (flag0 && flag1) { if (degree.get(term[1]) > degree.get(term[0])) { outvertex.add(term[1]); } } lastKey = term[0]; }
-
三、性能分析与优化
3.1 性能分析
- 该算法的性能瓶颈在遍历每一条边然后边两个端节点对应邻接表的交集,然后对每个顶点出发的邻接表进行排序也比较耗时,算法整体的时间复杂度是O(E1.5),E为边的数目
- 目前这个1.0版本的实现鲁棒性比较好,节点编号用Text存储,所以无论节点编号多大都可以存储以及比较,输入的图可以允许重复边的出现,不会影响结果的正确性。但由于mapreduce涉及大量的排序过程,用Text存储节点也就意味着使用字符串排序,字符串之间的比较当然比整型比较开销大,从而会影响程序的整体性能。除此之外,hadoop需要对数据进行序列化之后才能在网络上传输,数据以文本文件输入导致大量的数据序列化转换也会降低程序性能。
3.2 性能优化
2.0版本,在1.0的版本上进行了数据储存和表示方面的优化,相同实验环境(6个Reducer,每个Reducer2G物理内存,Reducer中的java heapsize -Xmx2048m)跑Goolge+数据能快50s左右,具体优化细节如下:
- 将离散化稀疏的节点转换成顺序化的,这样就可以用IntWritabel表示节点(前提是节点数未超过INT_MAX)而不用Text来表示节点编号,这样就可以避免字符串排序,减少map和reduce阶段的排序开销
- 将原始Text输入文件转换成Sequence,因为hadoop传输在网络上的数据是序列化的,这样可以避免数据的序列化转换开销。但是由于数据是串行转换的,影响整体性能,但是可以在第一次运行过后存起来,以后运行直接加载sequence的数据文件即可。这一步是和第一步顺序化节点一起完成的,转换后的sequence文件存储的是顺序化的节点表示的边。
- 在a->b and b->a then a-b的条件下,在获取小度指向大度的边集任务中,mapper需要将一条边的点对合并为key以在reducer中判断是否是双向边,看似只能用Text来存储了,实则这里有一个trick,在对节点顺序化之后的节点数通常不会超过INT_MAX,因此可以使用考虑将两个int型表示的节点转换成long,key存储在高32位,value存储在低32位,通过简单的位操作即可实现,这样mapper输出的key就是long而非Text,从而避免了字符串的比较排序,由于mapreduce涉及大量排序过程,因此在涉及程序的时候尽量用一些trick避免用Text表示key.
四、程序运行结果及时耗
实验环境:CPU型号Intel(R) Xeon(R) CPU E5-2630 v2 @ 2.60GHz,双物理CPU,单CPU6核12线程,所以一共24个虚拟核,程序设置6个reducer,每个reducer配置2GB物理内存,reducer中的java heapsize配置-Xmx2048m
"or"表示if a->b or b->a then a-b的情况,"and"表示if a->b and b->a then a-b的情况
- 1.0版本的测试结果:
| 数据集 | 三角形个数 | Driver程序在集群上的运行时间(秒) |
|---|---|---|
| Twitter(or) | 13082506 | 127s |
| Google+(or) | 1073677742 | 278s |
| Twitter(and) | 1818304 | 125s |
| Goolge+(and) | 27018510 | 156s |
- 2.0版本的测试结果(不包含输入文件转换的时间):
| 数据集 | 三角形个数 | Driver程序在集群上的运行时间(秒) |
|---|---|---|
| Twitter(or) | 13082506 | 115s |
| Google+(or) | 1073677742 | 230s |
| Twitter(and) | 1818304 | 118s |
| Goolge+(and) | 27018510 | 181s |
评估:2.0版本相对1.0版本在节点数据类型上作了优化,当数据量很大的时候,or情况的性能有显著的提升,Google+数据比1.0版本快了差不多50s左右,但是and情况下2.0版本跑Google+数据性能却下降了,个人猜测可能是job:UnidirectionalEdgeConvert中的Mapper,Reducer,Partitioner,比较函数中涉及大量的位操作或者int与long之间的类型转换,这个开销比1.0版本的对字符串排序开销更大。目前没有很好的想法来避免频繁的位操作与类型转换,有idea的朋友可以给我留言~
作者:brooksj —— XDU->NJU
出处:http://www.cnblogs.com/brooksj
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则我特么还能打你啊,强烈谴责。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号