
爬取漫画
网页的爬取方式主要分为两种。
1. 模拟Http请求,分析获取的json内容或者html内容,进行分析得到想要的数据。由于要读取内容,所以该方式适用于内容结构简单,不涉及到内容加密的场景。
2.模拟用户操作行为(如输入内容、点击按钮)来获取内容。所有的操作都是模拟用户行为,所以可以适用于内容加密的场景,如模拟用户登录。
现以爬取漫画为例。
现在要爬取的网址为 https://manhua.dmzj.com/lanqiufeirenquancai/
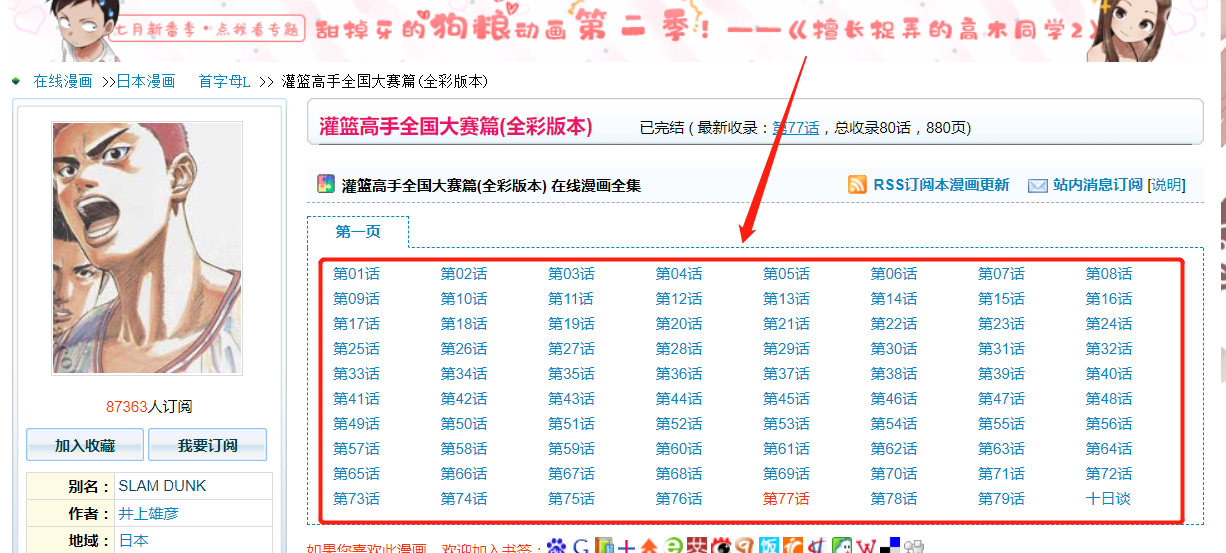
红框中的内容为漫画的目录结构。
查看网页源代码(不是已经渲染好的html),通过简单的分析,就可以看到目录相关的html标签结构,可以快速提取去目录名称和对应的跳转页面。例如第一页 https://manhua.dmzj.com/lanqiufeirenquancai/12515.shtml

获取到目录结构后,就可以依次去访问具体的漫画内容了。
在获取具体图片内容的时候,发现图片标签不是在服务端渲染好下发,是通过js的eval来完成,有一定的解析难度。
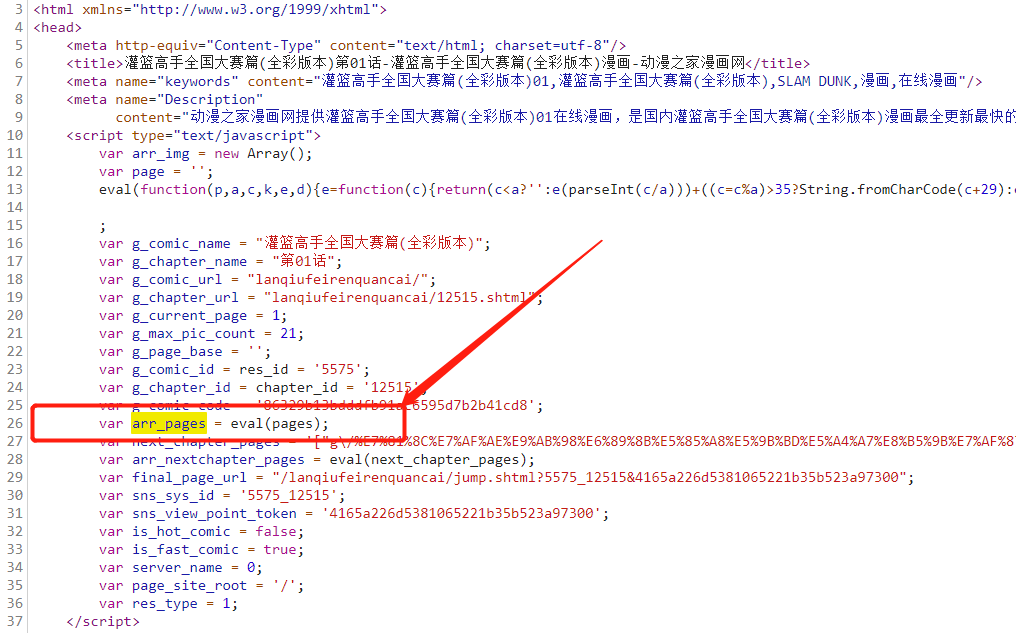
不过这时候发现,图片的js对象是一个全局对象,可以直接通过调用脚本获取到,这样就可以借助selenium工具获取到图片链接内容了。拼接好图片链接就可以进行下载操作了。
最后一步,将下载好的图片,整理成pdf文档。
附上python爬取的源码https://github.com/WangxuHub/CartoonDownload
python、selenium、reportlab


 浙公网安备 33010602011771号
浙公网安备 33010602011771号