第二周 词频统计
原需求
1.读取文件,文件内包可含英文字符,及常见标点,空格级换行符。
2.统计英文单词在本文件的出现次数
3.将统计结果排序
4.显示排序结果
新需求:
1.小文件输入. 为表明程序能跑
2.支持命令行输入英文作品的文件名
3. 支持命令行输入存储有英文作品文件的目录名,批量统计
4. 从控制台读入英文单篇作品,重定向输出
1.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <ctype.h>
int main()
{
char name[100];
FILE *fp;
char **string1, ch, *string;
int len, i, j, k;
int sign, same;
if((fp = fopen("c://special.txt", "rb")) == NULL)
printf("打不开\n");
/*移到文件尾*/
if(!fseek(fp, 0, 2))// 找到为0 执行 未找到不执行
{
len = ftell(fp); // 获取文件长度
}
else
{
fclose(fp);
printf("找不到尾\n");
}
/*移到文件头*/
if(fseek(fp, 0, SEEK_SET)) //找到不执行 未找到执行
{
fclose(fp);
printf("找不到头\n");
}
int number=0, num = 0;
if(string = (char *)malloc(sizeof(char) * (len+ 1))) // +1是为了把buf分配的足够大
{
memset(string, 0, (len + 1)); // 把buf清0
fread(string, 1, len, fp); // 把文件内容全部读到buf中
fclose(fp);
}
else
{
fclose(fp);
fprintf(stderr, "分配空间错误\n");
}
/*统计总的单词个数*/
sign= 1;
for(i = 0; i < len; i++)
{
ch = *(string + i);
if((ch >= 'A' && ch <= 'Z') || (ch >= 'a' && ch <= 'z'))
{
sign= 0;
}
else if(!sign)
{
number++;
sign= 1;
}
}
string1 = (char **)malloc(number* sizeof(char *));
for(i = 0; i < number; i++)
{
string1[i] = (char *)malloc(20 * sizeof(char));
memset(string1[i], 0, 20);
}
sign = 1;
k = 0;
j = 0;
for(i = 0; i < len; i++)
{
ch = *(string + i);
if((ch >= 'A' && ch <= 'Z') || (ch >= 'a' && ch <= 'z'))
{
string1[k][j++] = ch;
sign= 0;
}
else if(!sign)
{
k++;
j = 0;
sign = 1;
}
}
free(string);
/*计算每个单词的个数*/
for(i = 0; i < number; i++)
{
/*判断此单词是否和前面统计过的单词相同*/
same = 0;
for(j = 0; j < i; j++)
{
if(!strcmp(string1[i], string1[j]))
{
same = 1;
break;
}
}
/*统计单词个数*/
if(!same)
{
num = 0;
for(j = i; j < number; j++)
{
if(!strcmp(string1[i], string1[j]))
{
num++;
}
}
printf("%s : %d\n", string1[i], num);
}
}
free(string1);
return 1;
}
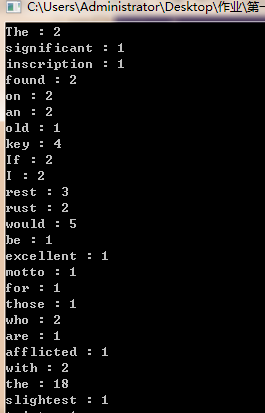
1.
2、
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <ctype.h>
int main()
{
char name[100];
printf("请输入");
gets(name);
strcat(name, ".txt");
FILE *fp;
char **string1, ch, *string;
int len, i, j, k;
int sign, same;
if((fp = fopen(name,"rb")== NULL)
printf("打不开\n");
/*移到文件尾*/
if(!fseek(fp, 0, 2))// 找到为0 执行 未找到不执行
{
len = ftell(fp); // 获取文件长度
}
else
{
fclose(fp);
printf("找不到尾\n");
}
/*移到文件头*/
if(fseek(fp, 0, SEEK_SET)) //找到不执行 未找到执行
{
fclose(fp);
printf("找不到头\n");
}
int number=0, num = 0;
if(string = (char *)malloc(sizeof(char) * (len+ 1))) // +1是为了把buf分配的足够大
{
memset(string, 0, (len + 1)); // 把buf清0
fread(string, 1, len, fp); // 把文件内容全部读到buf中
fclose(fp);
}
else
{
fclose(fp);
fprintf(stderr, "分配空间错误\n");
}
/*统计总的单词个数*/
sign= 1;
for(i = 0; i < len; i++)
{
ch = *(string + i);
if((ch >= 'A' && ch <= 'Z') || (ch >= 'a' && ch <= 'z'))
{
sign= 0;
}
else if(!sign)
{
number++;
sign= 1;
}
}
string1 = (char **)malloc(number* sizeof(char *));
for(i = 0; i < number; i++)
{
string1[i] = (char *)malloc(20 * sizeof(char));
memset(string1[i], 0, 20);
}
sign = 1;
k = 0;
j = 0;
for(i = 0; i < len; i++)
{
ch = *(string + i);
if((ch >= 'A' && ch <= 'Z') || (ch >= 'a' && ch <= 'z'))
{
string1[k][j++] = ch;
sign= 0;
}
else if(!sign)
{
k++;
j = 0;
sign = 1;
}
}
free(string);
/*计算每个单词的个数*/
for(i = 0; i < number; i++)
{
/*判断此单词是否和前面统计过的单词相同*/
same = 0;
for(j = 0; j < i; j++)
{
if(!strcmp(string1[i], string1[j]))
{
same = 1;
break;
}
}
/*统计单词个数*/
if(!same)
{
num = 0;
for(j = i; j < number; j++)
{
if(!strcmp(string1[i], string1[j]))
{
num++;
}
}
printf("%s : %d\n", string1[i], num);
}
}
free(string1);
return 1;
}
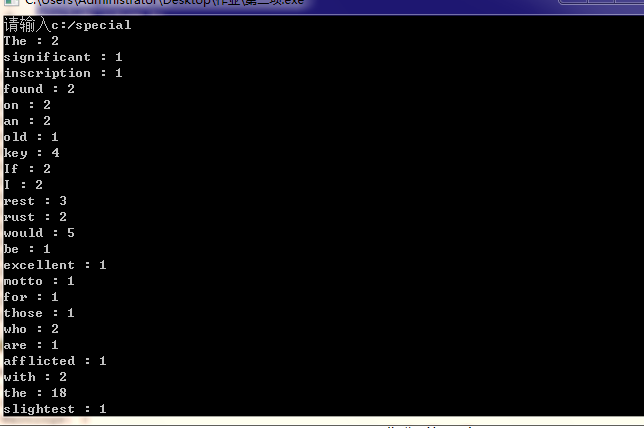
4.
#include<stdio.h>
#include<string.h>
#define max 100
int main()
{
char str[max][max];
char str1[max][max];
int num[max];
char string[max];
int i,j,k,l,n,m;
int t;
gets(string);
n = 0;
k = 0;
for(m = 1;m<strlen(string);m++)
{
if(string[m] ==' ')
{
strncpy(str[k++],string+n,m-n);
n = m+1;
}
}
strncpy(str[k++],string+n,m-n);
l = 0;
for(i=0;i<k;i++)
{
if(i==0)
{
strcpy(str1[l++],str[i]);
}
else
{
t = 0;
for(j=0;j<l;j++)
{
if(strcmp(str1[j],str[i])==0)
{
t = 1;
break;
}
}
}
if(t==0)
strcpy(str1[l++],str[i]);
}
for(i=0;i<l;i++)
{
printf("%s\n",str1[i]);
}
for(i=0;i<l;i++)
{
num[i] = 0;
}
for(i=0;i<l;i++)
{
for(j=0;j<k;j++)
{
if(strcmp(str1[i],str[j])==0)
{
num[i]++;
}
}
}
for(i=0;i<l;i++)
{
printf("%d\n",num[i]);
}
return 0;
}
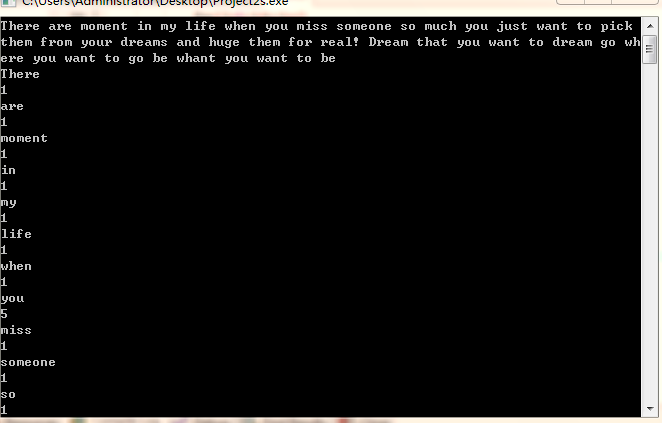
、
coding.net的地址为 https://git.coding.net/brilliant/cptj2.git
git@git.coding.net:brilliant/cptj2.git
小结:这个大概花了3天的时间。学习文件的知识,之前一直奇怪别人做的时候为什么没有用if(==“ ”)判断空格的语句就能完成对单词的分割,后来才发现文件的fscanf语句特别强大。后来又学fseek等语句,知道if还可以在if(=)中使用等等,总之收获颇丰。在操作台中输入就不能用文件了,就用了之前词频统计的改进版。最近学习经常弄到12点,可能是我基础薄弱,努力学习掌握方法应该就会好了。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号