

tensorflow目标检测API之建立自己的数据集
1 收集数据
为了方便,我找了11张月儿的照片做数据集,如图1,当然这在实际应用过程中是远远不够的
2 labelImg软件的安装
使用labelImg软件(下载地址:https://github.com/tzutalin/labelImg)为图片做标签
下载下来之后解压缩,用Anaconda Prompt cd到解压缩后的labelImg文件目录下,例如 cd C:\Users\admin\Desktop\labelImg-master
然后安装pyqt,输入命令 conda install pyqt=5(注意:一定要使用管理员方式运行命令)
完成后输入命令 pyrcc5 -o resources.py resources.qrc,这个命令没有返回
最后执行 python labelImg.py,如果提示缺少包则安装就行
运行结果如图2
3 labelImg软件的使用
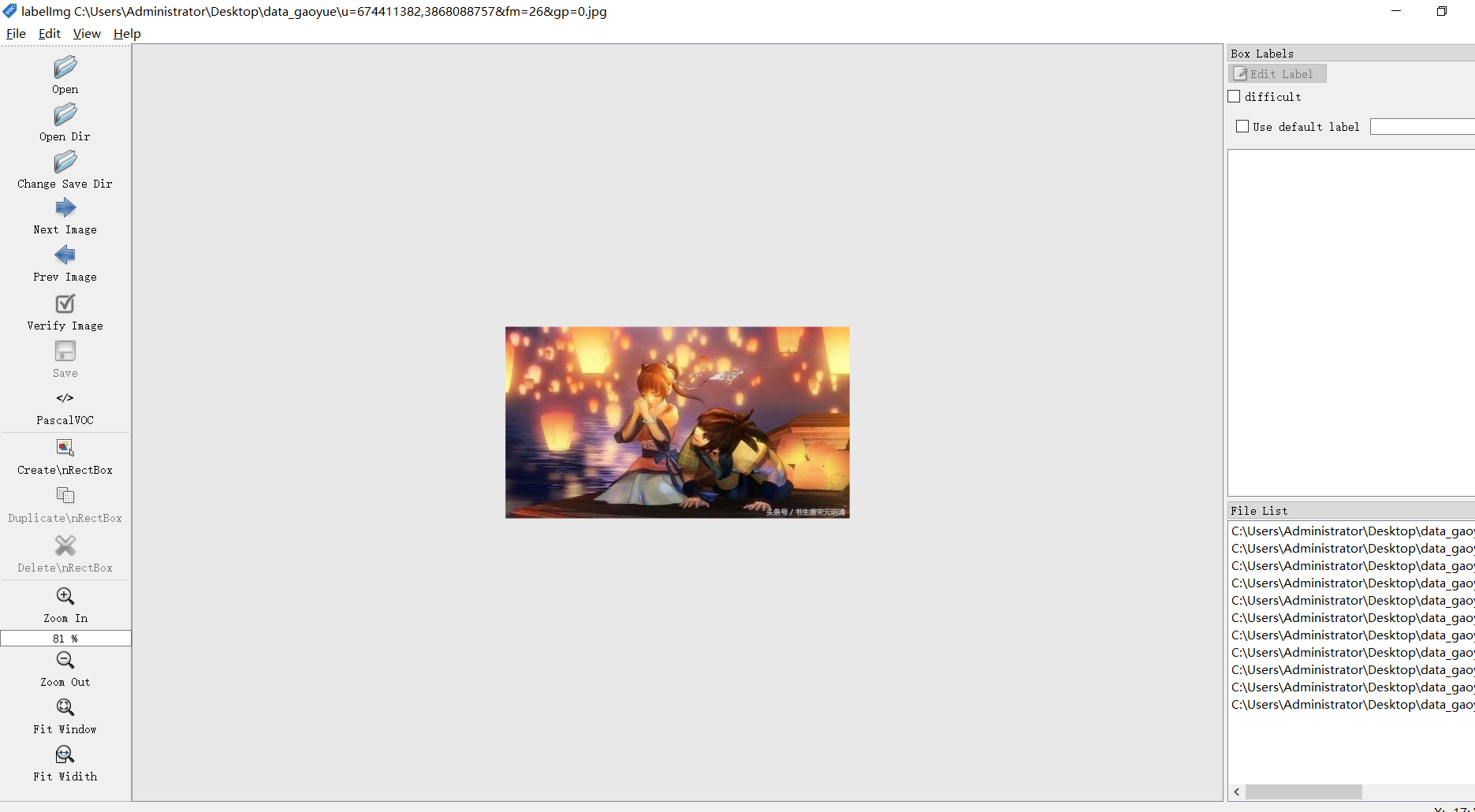
点击Open Dir打开数据集所在的文件夹,将图片导入。如图3所示。
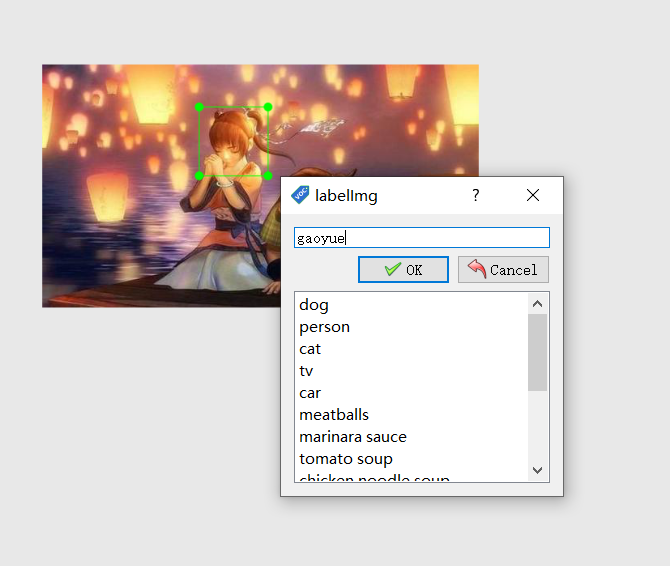
在界面中按下w键,选择你的目标,然后在弹出的框中为你的目标确定一个名字。如图4
标记完之后每张图片都有一个对应的xml文件,如图5所示
4 标签文件的格式转换(一定要将这一步中的代码放在object_detection文件夹下)
(1)xml转csv
代码(xml_to_csv.py)
# -*- coding: utf-8 -*- import os import glob import pandas as pd import xml.etree.ElementTree as ET os.chdir('C:/Code/models-master/research/object_detection/my_train_images/train') # 这个是我文件夹的目录,改成你自己的 path = 'C:/Code/models-master/research/object_detection/my_train_images/train' # 训练图片的路径,改成你自己的 def xml_to_csv(path): xml_list = [] for xml_file in glob.glob(path + '/*.xml'): tree = ET.parse(xml_file) root = tree.getroot() for member in root.findall('object'): value = (root.find('filename').text, int(root.find('size')[0].text), int(root.find('size')[1].text), member[0].text, int(member[4][0].text), int(member[4][1].text), int(member[4][2].text), int(member[4][3].text) ) xml_list.append(value) column_name = ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax'] xml_df = pd.DataFrame(xml_list, columns=column_name) return xml_df def main(): image_path = path xml_df = xml_to_csv(image_path) xml_df.to_csv('gaoyue_train.csv', index=None) # 输出xsv文件的名字,改成你自己的 print('Successfully converted xml to csv.') main()
运行之后可以看到train文件夹下多了一个gaoyue.csv文件,重复上面的代码,更改文件夹,将test数据也生成一个.csv文件。

(2)csv转tfrecord
代码(csv_to_tfrecord.py)
# -*- coding: utf-8 -*- """ Usage: # From tensorflow/models/ # Create train data: python generate_tfrecord.py --csv_input=data/tv_vehicle_labels.csv --output_path=train.record # Create test data: python generate_tfrecord.py --csv_input=data/test_labels.csv --output_path=test.record """ import os import io import pandas as pd import tensorflow as tf from PIL import Image from object_detection.utils import dataset_util from collections import namedtuple, OrderedDict os.chdir('C:/Code/models-master/research/object_detection') # 当前工作目录 flags = tf.app.flags flags.DEFINE_string('csv_input', '', 'Path to the CSV input') flags.DEFINE_string('output_path', '', 'Path to output TFRecord') FLAGS = flags.FLAGS # TO-DO replace this with label map def class_text_to_int(row_label): if row_label == 'gaoyue': return 1 # elif row_label == 'vehicle': # return 2 else: return 0 def split(df, group): data = namedtuple('data', ['filename', 'object']) gb = df.groupby(group) return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)] def create_tf_example(group, path): with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid: encoded_jpg = fid.read() encoded_jpg_io = io.BytesIO(encoded_jpg) image = Image.open(encoded_jpg_io) width, height = image.size filename = group.filename.encode('utf8') image_format = b'jpg' xmins = [] xmaxs = [] ymins = [] ymaxs = [] classes_text = [] classes = [] for index, row in group.object.iterrows(): xmins.append(row['xmin'] / width) xmaxs.append(row['xmax'] / width) ymins.append(row['ymin'] / height) ymaxs.append(row['ymax'] / height) classes_text.append(row['class'].encode('utf8')) classes.append(class_text_to_int(row['class'])) tf_example = tf.train.Example(features=tf.train.Features(feature={ 'image/height': dataset_util.int64_feature(height), 'image/width': dataset_util.int64_feature(width), 'image/filename': dataset_util.bytes_feature(filename), 'image/source_id': dataset_util.bytes_feature(filename), 'image/encoded': dataset_util.bytes_feature(encoded_jpg), 'image/format': dataset_util.bytes_feature(image_format), 'image/object/bbox/xmin': dataset_util.float_list_feature(xmins), 'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs), 'image/object/bbox/ymin': dataset_util.float_list_feature(ymins), 'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs), 'image/object/class/text': dataset_util.bytes_list_feature(classes_text), 'image/object/class/label': dataset_util.int64_list_feature(classes), })) return tf_example def main(_): writer = tf.python_io.TFRecordWriter(FLAGS.output_path) # path = os.path.join(os.getcwd(), 'images/train') path = os.path.join(os.getcwd(), 'my_train_images/train') # 当前路径加上你图片存放的路径 examples = pd.read_csv(FLAGS.csv_input) grouped = split(examples, 'filename') for group in grouped: tf_example = create_tf_example(group, path) writer.write(tf_example.SerializeToString()) writer.close() output_path = os.path.join(os.getcwd(), FLAGS.output_path) print('Successfully created the TFRecords: {}'.format(output_path)) if __name__ == '__main__': tf.app.run()
然后打开Anaconda Prompt cd到你csv_to_tfrecord.py文件所在的地方
输入命令
python csv_to_tfrecord.py --csv_input=my_train_images/test/gaoyue_test.csv --output_path=gaoyue_train.record (csv_to_tfrecord.py为转换的代码文件,csv_input是你要转换的csv文件所在的路径,output_path是你输出tfrecord文件的路径)
运行结果如图所示

生成 gaoyue_train.csv文件

