Qt 学习(2)
Qt 学习(2)
Qt 的 QXmlStreamReader
在 Qt 应用程序中访问 XML 格式的文件数据,可以使用 [QXmlStreamReader][sreamreader] 对文件进行读取。关于 QXmlStreamReder 的使用,官方文档中有 QXmlStream Bookmarks Example 的示例可供参考。
常用的方法有:
- TokenType readNext()
读取下一个标记并返回它的类型 - bool readNextStartElement()
在当前元素内,读取到下一个开始元素,若找到开始元素,就返回真,否则返回假 - QXmlStreamAttributes attributes()
返回 StartElement 中的属性 - QString name()
返回标签名,比如读取标签<html>就会返回 html - void skipCurrentElement()
读取到当前元素的结尾,跳过它的子节点 - QString readElementText()
读取元素中间的文本,比如<p>test</p>将会返回 test
对于一个自定义结构的 XML 文件,文件名为 test.xml,如下:
<?xml version="1.0" encoding="UTF-8"?>
<Instructions version="2.0">
<Instruct identifier="#" set="MSP">
<row type="Offset" value="OFFSET_MODE">
<reply type="String" enum="true">
<accept value="AUTO" />
<accept value="MANUAL" />
</reply>
</row>
<row type="Buzzer" value="BUZZER" />
<row type="AC" value="SAG">
<reply type="Double" enum="false" bottom="0" />
</row>
</Instruct>
</Instructions>
首先构造一个 XmlStreamReader,它的构造函数可以接受一个 QIODevice 的指针,一般可以传递一个 QFile 指针,对 xml 文件进行解析:
// void InstructParser::parse(const QString &filename, const QString &set) {
// 打开并读取指令文件
QFile file( filename );
bool opened = file.open( QIODevice::ReadOnly );
if( !opened ) {
qDebug() << "[parse] file not open" ;
return;
}
m_xmlReader = new QXmlStreamReader( &file );
// ![1]
readInstructions();
// ![1]
file.close();
file.deleteLater();
delete m_xmlReader;
// }
构造了 XmlStreamReader 后,通过 readNext() 或者 readNextStartElement() 往下读取节点。
readNext 和 readNextStartElement 方法的使用有些差别,先来看看 readNext 方法:
// void InstructParser::readInstructions()
while( !m_xmlReader->atEnd() ) {
m_xmlReader->readNext();
qDebug() << "[readNext] "<< QString( "%0 %1").arg( m_xmlReader->lineNumber() ).arg( m_xmlReader->tokenString() ) << m_xmlReader->name().toString();
}
输出结果:
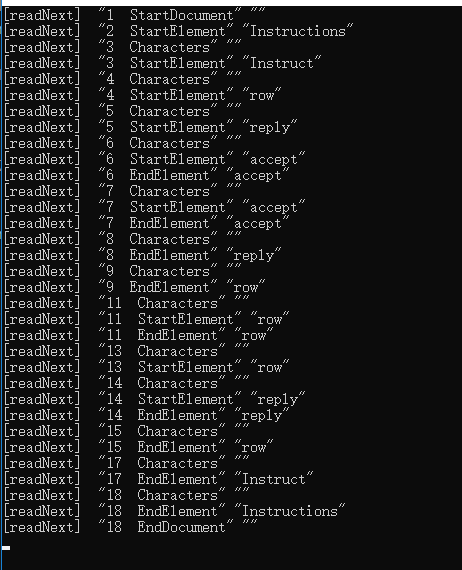
可以看到,对于空白行, readNext 函数将会跳过该行,而对于第 3 行 Instruct 起始标签,在它的前面是有一个 tab 缩进的,这里会显示一个类型为 Characters 的元素,然而在第 18 行 </Instructions> 标签前面,其实并没有 tab 缩进,然而这里仍然会显示一个 Characters 元素,并且 17 行的反尖括号后面是没有输入字符的,不知道是不是 Windows 平台下的回车换行符当成一个元素来进行解析的。
接下来是 readNextElement 方法:
// void InstructParser::readInstructions()
while( !m_xmlReader->atEnd() ) {
bool start = m_xmlReader->readNextStartElement();
qDebug() << "[readNextStartElement] "<< start
<< QString( "%0 %1").arg( m_xmlReader->lineNumber() ).arg( m_xmlReader->tokenString() )
<< m_xmlReader->name().toString();
}
输出结果:
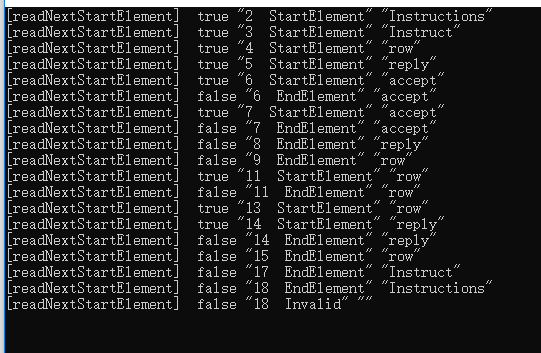
可以看到,对于空白行,该方法仍然会忽略掉,但是这个方法不会再出现一些奇怪的 Characters 标签,所有打印出来的元素都是所需要的,当然最后读到文件尾会显示 Invalid 标记。这个方法比 readNext 方法更好用。但是需要注意的是在第 6 行,读取 <accept value="AUTO" /> 时,这里开始标签和结束标签是合并着写的,所以在读到结束标签时,该函数会返回 false,如果 while 循环的判断条件是 m_xmlReader->readNextStartElement(),那么当它遇到结束标签时,将会结束循环。
在读取 XML 文件时,不仅需要针对特定标签做处理,有时还需要注意各个标签之间的层级关系(常见的如 HTML 中 div 标签),如果像前面一样,直接判断 m_xmlReader 是不是到达文件底部,那么就没有办法找出标签之间的层级关系了。
为了找出某个标签中的子标签,就需要在进入标签后,继续用循环进行判断,比如对于上面的 XML 文件:在 InstructParser 中分别有四个方法读取四个标签:
private:
void readInstructions(const QString &set);
void readInstruct(const QString &set, const bool stillRead = false);
void readRow();
void readReply(Instruct *ins);
在 readInstructions 中使用 while 循环对 readInstruct 进行重复调用,在 readInstruct() 中使用 while 循环对 readRow() 进行重新调用……最后其实得到的是一个树状结构,在 readInstruct() 中:
while( m_xmlReader->readNextStartElement() ) {
if( m_xmlReader->name() == "row" ) {
readRow();
}
else
m_xmlReader->skipCurrentElement();
}
在读取之前加上相应的输出语句:
qDebug() << "[reply]" << m_xmlReader->name() << m_attrib.value( "type" ) << m_xmlReader->tokenString();
可以得到以下输出:
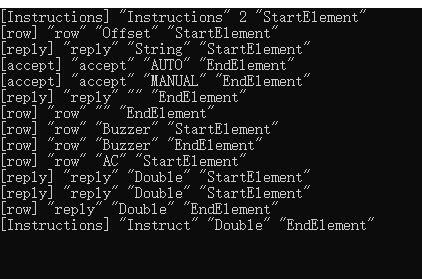
这样就得到了所有的节点,有时 m_xmlReader->readNextStartElement() 会跳出循环,可以在 readRow 等函数的结尾加上,以便读取到当前父节点的结束标签:
m_xmlReader->readElementText(); // skip to end tag of reply
本博客由 BriFuture 原创,并在个人博客(WordPress构建) BriFuture's Blog 上发布。欢迎访问。
欢迎遵照 CC-BY-NC-SA 协议规定转载,请在正文中标注并保留本人信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号