Web服务的请求方式
要想真正的学习到一些关于web的东西 我们就首先要知道web服务的http具体的请求过程 ,那么一次完整的请求过程是怎么做到了呢,下面进行一下简单的介绍:
1、拓扑图:
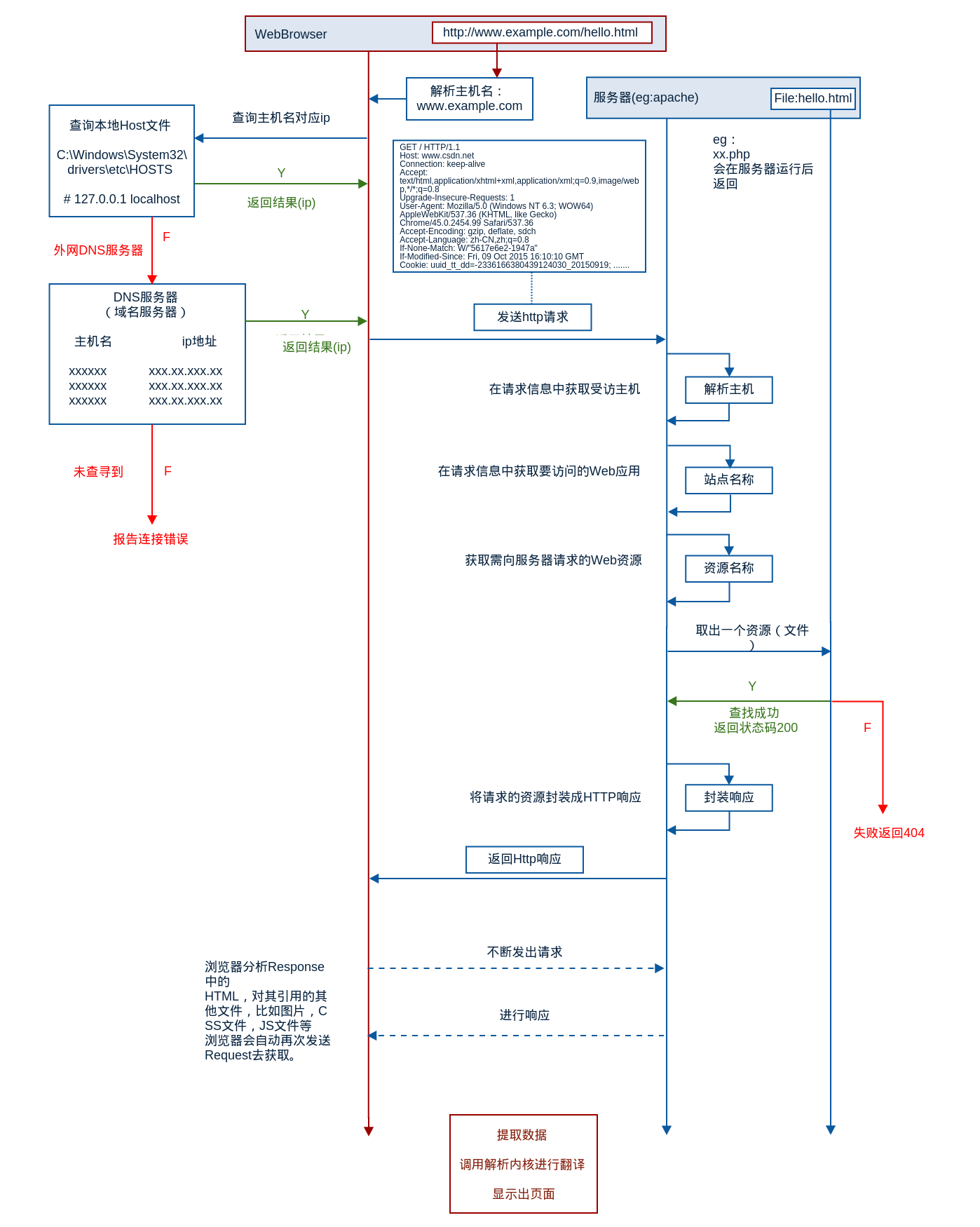
2、文字描述:
首先了解一次完整的HTTP请求到响应的过程需要的步骤
域名解析 发起TCP的3次握手 建立TCP连接后发起http请求 服务器端响应http请求,浏览器得到html代码 浏览器解析html代码,并请求html代码中的资源 浏览器对页面进行渲染呈现给用户
2.1 域名解析
什么是域名解析?
域名解析就是将网站的链接地址(网址)转换成IP地址,www.baidu.com转换成220.181.112.244
实现域名解析的方式:
常见的就是本地的hosts文件
DNS域名解析
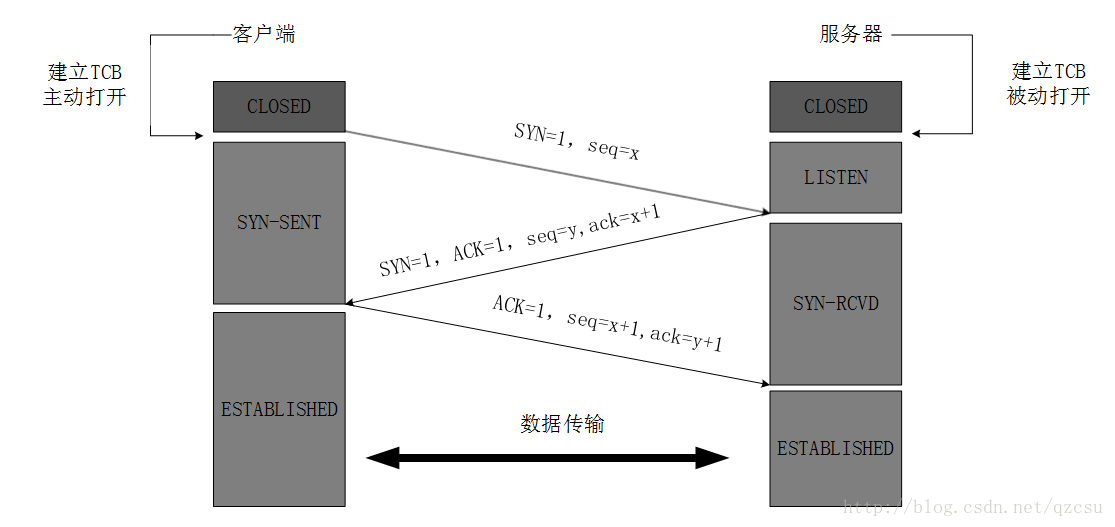
2.2 发起TCP的3次握手
什么是TCP的3次握手?
TCP的3次握手是客户端与服务端建立连接的必经之路,整个过程的实现是:
1、建立连接时,客户端首先会发出一个SYN的消息,并进入SYN_SENT状态,等待服务器确认(SYN消息是同步序列编号)
2、服务器收到客户端的SYN消息,必须确认这个SYN消息,并且自己也会发送一个SYN的消息即SYN+ACK包,此时服务器进入SYN_RECV状态
3、客户端收到服务器的SYN+ACK的消息,向服务器发送确认ACK消息,此消息发送完毕,客户端和服务器进入ESTABLISHED(TCP连接成功)状态,完成三次握手
2.3 建立连接
所谓的建立连接就是发起HTTP请求(HTTP Request)
一段话来简述建立连接的整个过程:
拿到域名对应的IP地址之后,User-Agent(一般是指浏览器)会以一个随机端口(1024 < 端口 < 65535)向服务器的WEB程序(常用的有httpd,nginx等)80端口发起TCP的连接请求。这个连接请求(原始的http请求经过TCP/IP4层模型的层层封包)到达服务器端后(这中间通过各种路由设备,局域网内除外),进入到网卡,然后是进入到内核的TCP/IP协议栈(用于识别该连接请求,解封包,一层一层的剥开),还有可能要经过Netfilter防火墙(属于内核的模块)的过滤,最终到达WEB程序(本文就以Nginx为例),最终建立了TCP/IP的连接。
这里涉及到端口的问题,我就对此做个简单的描述吧:
1-1024:众所周知端口,永久分配给固定的应用程序使用,属于特权端口,只有root有权使用
1024-4195:注册端口,要求略宽松,分配给某程序注册使用
41952-65535:客户端程序使用的随机端口,动态端口,又叫私有端口或随机端口
所谓的HTTP请求,也就是Web客户端向Web服务器发送信息,这个信息由如下三部分组成:
1、请求头
HTTP头在HTTP请求可以是3种HTTP头:1. 请求头(request header) 2. 普通头(general header) 3. 实体头(entity header)
通常来说,由于Get请求往往不包含内容实体,因此也不会有实体头。
2、请求行
例如:GET www.baidu.com HTTP/1.1
请求行写法是固定的,由三部分组成,
第一部分是请求方法:
除了常见的只有Get和Post方法,实际上HTTP请求方法还有很多,比如: PUT方法,DELETE方法,HEAD方法,CONNECT方法,TRACE方法
第二部分是请求网址:www.baidu.com
第三部分是HTTP版本:HTTP/1.1
3、请求内容
只在POST请求中存在,因为GET请求并不包含任何实体
2.4 服务器响应
所谓的服务器响应就是服务器端HTTP响应(HTTP Response)请求
当Web服务器收到HTTP请求后,会根据请求的信息做某些处理(这些处理可能仅仅是静态的返回页,或是包含Asp.net, PHP, Jsp等语言进行处理后返回),相应的返回一个HTTP响应。HTTP响应在结构上很类似于HTTP请求,也是由三部分组成:
1、响应头:
HTTP响应中包含的头包括:1. 响应头(response header) 2. 普通头(general header) 3. 实体头(entity header)。
2、响应行:
例如:HTTP/1.1 200 OK
第一部分是HTTP版本:HTTP/1.1
第二部分是响应状态码:200
第三部分是状态码的描述:OK
信息类 (100-199)
响应成功 (200-299)
重定向类 (300-399)
客户端错误类 (400-499)
服务端错误类 (500-599)
3、响应的内容
HTTP响应内容就是HTTP请求所请求的信息。这个信息可以是一个HTML,也可以是一个图片。响应的数据格式通过Content-Type字段来获得:Content-Type:image/png;或者我们熟悉的Content-Type:text/html
我们常见的Content-Type字段的值有:
text/plain
text/html
text/css
image/jpeg
image/png
image/svg+xml
audio/mp4
video/mp4
application/javascript
application/pdf
application/zip
application/atom+xml
这些都是响应内容的部分
2.5 解析html代码,请求html资源
2.6 返回数据
3、模拟请求过程并进行分析:
我们使用Linux中的curl来进行模拟get的请求过程,进一步直观的做下分析:
[root@BrianZhu Xuexiao]# curl -v "http://www.baidu.com" # 执行的命令
* About to connect() to www.baidu.com port 80 (#0)
* Trying 61.135.169.125...
* Connected to www.baidu.com (61.135.169.125) port 80 (#0)
> GET / HTTP/1.1 # 使用GET方法请求服务器端的主页
> User-Agent: curl/7.29.0 # 请求方式
> Host: www.baidu.com # 请求地址
> Accept: */*
>
< HTTP/1.1 200 OK # 响应行(包括了HTTP的版本、状态码、状态的描述)
< Server: bfe/1.0.8.18
< Date: Thu, 15 Mar 2018 03:59:24 GMT # 回应报文的其它字段
< Content-Type: text/html # 响应的Content-Type值
< Content-Length: 2381
< Last-Modified: Mon, 23 Jan 2017 13:27:32 GMT
< Connection: Keep-Alive
< ETag: "588604c4-94d"
< Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform
< Pragma: no-cache
< Set-Cookie: BDORZ=27315; max-age=86400; domain=.baidu.com; path=/
< Accept-Ranges: bytes
<
<!DOCTYPE html> # 响应的内容(具体的html代码)
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css><title>百度一下,你就知道</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn"></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>新闻</a> <a href=http://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视频</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>贴吧</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录</a>');</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">更多产品</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>关于百度</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使用百度前必读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>意见反馈</a> 京ICP证030173号 <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>
4、其实HTTP的连接有两种方式:
(1)短连接:非保持连接
(2)长连接:保持连接(持久连接)
数量限制:多少个资源
时间限制:最长可以保持长连接多长时间
短连接就不用过多的解释了
持久连接就是:
有时候我们获取一个HTML页面,在对浏览器对HTML解析的过程中,如果发现额外的URL需要获取的内容,会再次发起HTTP请求去服务器获取,比如样式文件,图片。许多个HTTP请求,只依靠一个TCP连接就够了,这就是所谓的持久连接。也是所谓的一次HTTP请求完成。
朱敬志(brian),成功不是将来才有的,而是从决定去做的那一刻起,持续累积而成。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号