准确率(Accuracy)+精确率(Precision)+召回率(Recall)
准确率、精确率和召回率,这三个就像是咱们评价分类模型好坏的三个关键指标,就像是给模型打分用的尺子。
- 准确率:看看模型整体做得多好,它就像是咱们考试的总分,关心的是模型判断的所有结果里,有多少是真正正确的,就像是看看咱们答对了多少题。
- 精确率:就像是咱们要挑出一堆东西里面的好东西,它更关注模型说是某一类的东西里,到底有多少是真正属于那一类的,就像是咱们挑出来的好东西里面,有多少是真的好的。
- 召回率:就像是咱们要找全一类东西,它关心的是真正属于那一类的东西,模型找出来了多少,就像是咱们要找的是苹果,召回率就看看模型找出来的苹果有多少个是真正的苹果。
这三个指标,经常用在机器学习、数据挖掘和统计分类这些领域,就像是给模型做体检的医生,帮咱们看看模型哪里做得好,哪里还需要改进。
1、准确率(Accuracy)
准确率是最直观的性能度量,它是被正确分类的样本(正类和负类)与总样本数的比例。用公式表示为:
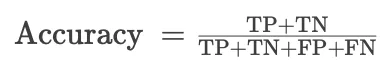
- TP:就是真正例,意思就是说,本来是对的(正类),模型也判它是对的(正类),这样的有多少个,就是多少个TP。
- TN:是真负例,这个说的是,本来是错的(负类),模型也判它是错的(负类),这样的有多少个,就是多少个TN。
- FP:是假正例,就是说,本来是错的(负类),但模型却判它是对的(正类),这样的有多少个,就是多少个FP,这就像是咱们把坏人当成好人了一样。
- FN:是假负例,这个说的是,本来是对的(正类),但模型却判它是错的(负类),这样的有多少个,就是多少个FN,这就像是咱们把好人当成坏人了一样。
这几个概念,在评估模型好坏的时候特别重要,就像是咱们看一个人有没有分清楚好坏人一样。
2、精确率 (Precision)
精确率是对正类预测的准确性的度量,它是正确预测为正类的样本数与所有预测为正类的样本数的比例。用公式表示为:

精确率高意味着误报(将负类错误判定为正类)的数量较少。
3、召回率 (Recall)
召回率是对模型识别出的正类样本的完整性的度量,它是正确预测为正类的样本数与实际为正类的样本数的比例。用公式表示为:
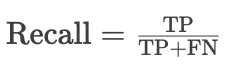
召回率高意味着漏报(将正类错误判定为负类)的数量较少。
4、区别
-
准确率:所有类别被正确分类的比例,是一个全局的度量。
-
精确率:被预测为正类的样本中真正为正类的比例,它更关注模型在正类预测上的性能。
-
召回率:所有真正的正类样本中,被模型正确识别出的比例,它更关注模型对正类样本的覆盖程度。
在实际应用中,根据问题的具体需求,可能会更关注某一个或几个指标。例如,在医学检测中,可能更关注召回率,以确保尽可能少地漏检;而在垃圾邮件识别中,可能更关注精确率,以避免误将正常邮件判定为垃圾邮件。
5、这三个指标是不是都是越高越好?
是的,一般来说,准确率(Accuracy)、精确率(Precision)、召回率(Recall)这三个指标都是越高越好。每个指标的提高都意味着模型在某方面的性能提升:
-
准确率(Accuracy)高意味着模型在所有预测中的正确率更高,无论是正类还是负类,模型都能更准确地进行分类。
-
精确率(Precision)高意味着模型在预测为正类的样本中,实际为正类的比例更高,减少了误将负类判定为正类的情况,这对于那些误报(假正例)的成本很高的应用场景尤为重要。
-
召回率(Recall)高意味着模型能够捕获更多的真正的正类样本,减少了漏报(假负例)的情况,这在需要尽可能不遗漏任何正类样本的场景(如疾病筛查)中非常关键。
然而,精确率和召回率之间往往存在权衡(trade-off)。在许多情况下,提高精确率可能会降低召回率,反之亦然。例如,如果模型被设计得过于谨慎,只有在非常确定的情况下才将样本分类为正类,这可能提高精确率,但同时也可能导致许多正类样本被遗漏,从而降低了召回率。相反,如果模型过于宽松,轻易就将样本分类为正类,可能会捕获到更多的正类样本(提高召回率),但同时也会增加误将负类判定为正类的情况(降低精确率)。
因此,在实际应用中,需要根据具体问题的需求和背景来决定最优的平衡点。在某些情况下,可能需要优先提高精确率(如在误报的成本很高的场景中),而在另一些情况下,则可能需要优先提高召回率(如在漏报的成本很高的场景中)。F1分数是一个常用的指标,用于综合考虑精确率和召回率,尤其是当需要平衡这两者时。
6、实操
在某些任务中,我们可能对识别特定类别的能力更感兴趣。例如,在垃圾邮件检测中,我们可能更关心模型能否准确识别出垃圾邮件(正类),而不是将所有邮件都正确分类。如果一个模型将大量的正常邮件错误地分类为垃圾邮件(即高假正例率),即使总体准确率较高,用户体验也会大打折扣。在这种情况下,精确率和召回率是更为重要的指标。
在垃圾邮件检测中,假设有100封邮件,其中20封是垃圾邮件(正类),80封是正常邮件(负类)。
假设一个垃圾邮件检测模型的结果如下:
-
TP = 15(正确识别出15封垃圾邮件)
-
TN = 75(正确识别出75封正常邮件)
-
FP = 5(错误地将5封正常邮件标记为垃圾邮件)
-
FN = 5(5封垃圾邮件被漏识别)
-
准确率计算为:
在某些任务中,我们可能对识别特定类别的能力更感兴趣。例如,在垃圾邮件检测中,我们可能更关心模型能否准确识别出垃圾邮件(正类),而不是将所有邮件都正确分类。如果一个模型将大量的正常邮件错误地分类为垃圾邮件(即高假正例率),即使总体准确率较高,用户体验也会大打折扣。在这种情况下,精确率和召回率是更为重要的指标。
在垃圾邮件检测中,假设有100封邮件,其中20封是垃圾邮件(正类),80封是正常邮件(负类)。
假设一个垃圾邮件检测模型的结果如下:
-
TP = 15(正确识别出15封垃圾邮件)
-
TN = 75(正确识别出75封正常邮件)
-
FP = 5(错误地将5封正常邮件标记为垃圾邮件)
-
FN = 5(5封垃圾邮件被漏识别)
-
准确率计算为:
![]()
-
精确率(Precision)计算为:
![]()
=75%
-
召回率(Recall)计算为:
![]()
=75%
-
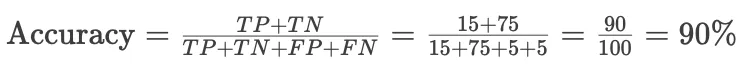
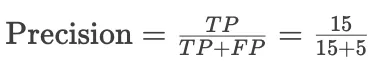
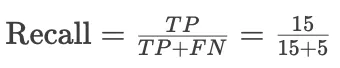
即使准确率达到90%,模型仍然将5封正常邮件误判为垃圾邮件,可能导致重要信息的丢失,同时也有5封垃圾邮件漏过筛选,这在实际应用中可能是不可接受的。
这些例子说明,在评估模型性能时,不能仅仅依赖准确率,还需要结合实际应用场景的特定需求和约束,综合考虑精确率、召回率以及其他可能的评估指标(如F1分数),来全面评估模型的性能。
本文来自博客园,作者:他还在坚持嘛,转载请注明原文链接:他还在坚持嘛 https://www.cnblogs.com/brf-test/p/18579956

 浙公网安备 33010602011771号
浙公网安备 33010602011771号