
Python正则表达式
什么是正则表达式?
正则表达式是一组由字母和符号组成的特殊文本,可以帮助我们从某个复杂的字符串中,提取出满足我们要求的特殊文本。
用一个形象的比喻大致体会一下正则匹配的过程。苹果相当于写的“正则表达式”,字符串相当于“水果市场”,“正则匹配的过程”就相当于拿着苹果去“水果市场”找苹果的过程,每找到一个就返回一个,否则就什么也没有。
为什么要使用正则表达式?
接下来,我们看一个实例,找出所有的薪资数字:
content = ''' Python3高级开发工程师上海互教教育科技有限公司上海-浦东新区2万/月02-18满员 测试开发工程师(C++/python)上海墨鹖数码科技有限公司上海-浦东新区2.5万/每月02-18未满员 Python3高级开发工程师上海互教教育科技有限公司上海-浦东新区2万/月02-18满员测试开发工程师(C++/python)上海墨鹖数码科技有限公司上海-浦东新区2.5万/每月02 -18未满员 Python3开发工程师上海德拓信息技术股份有限公司上海-徐汇区1.3万/每月02-18剩余11人 测试开发工程师(Python)赫里普(上海)信息科技有限公司上海-浦东新区1.1万/每月e2-18剩余5人Python高级开发工程师上海行动教育科技股份有限公司上海-闵行区2.8万/月02-18剩余255人 python开发工程师上海优似腾软件开发有限公司上海-浦东新区2.5万/每月02-18满员 ''' #将文本内容按行放入列表 lines = content.splitlines() for line in lines: pos2 = line.find('万/月') #查找 万/月 在字符串中什么地方 if pos2< 0: pos2 = line.find('万/每月') #查找 万/每月 在字符串中什么地方 if pos2 <0:#都找不到 continue #跳过执行下一步 #执行到这里,说明可以找到薪资的关键字 #接下来分析 薪资 数字的起始位置 #方法事找到 pos2 前面薪资数字的位置 idx = pos2 -1 #只要事数字或者小数点,就继续往前面找 while line[idx].isdigit() or line[idx]=='.': idx -= 1 # 现在 idx 指向 薪资数字前面的那个字 # 所以薪资开始的 索引 就是 idx+1 pos1 = idx + 1 print(line[pos1:pos2])
运行一下,是完全可以的,就是还挺麻烦的,是不是?接下来我们来看下用上正则表达式后会是怎么样:
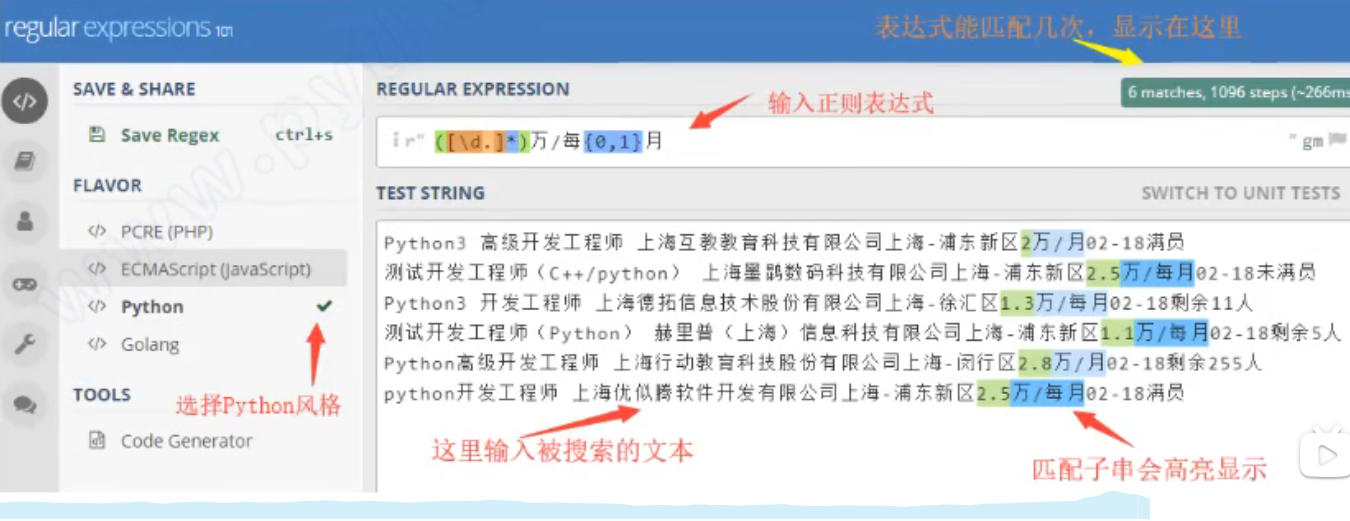
content = ''' Python3高级开发工程师上海互教教育科技有限公司上海-浦东新区2万/月02-18满员 测试开发工程师(C++/python)上海墨鹖数码科技有限公司上海-浦东新区2.5万/每月02-18未满员 Python3高级开发工程师上海互教教育科技有限公司上海-浦东新区2万/月02-18满员测试开发工程师(C++/python)上海墨鹖数码科技有限公司上海-浦东新区2.5万/每月02 -18未满员 Python3开发工程师上海德拓信息技术股份有限公司上海-徐汇区1.3万/每月02-18剩余11人 测试开发工程师(Python)赫里普(上海)信息科技有限公司上海-浦东新区1.1万/每月e2-18剩余5人Python高级开发工程师上海行动教育科技股份有限公司上海-闵行区2.8万/月02-18剩余255人 python开发工程师上海优似腾软件开发有限公司上海-浦东新区2.5万/每月02-18满员 ''' import re p = re.compile(r'([\d.]+)万/每{0,1}月') #([\d.]+)万/每{0,1}月 正则表达式的语法 for one in p.findall(content): print(one) #结果 2 2.5 2 2.5 1.3 1.1 2.8 2.5
在线验证表达式是否能正确匹配到搜索的字符串:https://regex101.com/
常用操作符介绍
正则表达式之所以这么强大,是因为拥有这么多专用操作符。为了方便大家记忆,我特意将操作符分为三类:
- 第一,元字符;
- 第二,量化符;
- 第三,特殊符;
1. 常用元字符
所谓“元字符”,指的是那些不仅仅可以表示字符本身含义、并且还可以表示其他特殊含义的字符。
常用的元字符有. [ ] () ^ $ | \ ? * + { }共11种,为了更清楚地说明每个元字符的含义,我这里整理了一张表格供大家参考。
| 元字符 | 含义 |
| . | 点号,可以匹配(除了换行符以外的)任意单个字符 |
| [] | 方括号,可以匹配括号内的任意字符,括号中的每个字符是 or 的含义 |
| () | 组,可以匹配括号内的表达式,括号中的每个字符是 and 含义 |
| ^ | 乘方符号,表示以......开头 |
| $ | 美元符号,表示以......结尾 |
| | | 或运算符,用于匹配符号前或符号后的字符 |
| \ | 转义字符,可以让某些字母表示特殊含义 |
可以看到,上面一共说明了7种元字符的含义,还有4种并没有说明。那是为了方便大家记忆,我特意将上述最后4个元字符分类到了“量化符”中,这个将在下面一小节中进行讲述。
2. 常用量化符
所为“量化符”,指的就是将紧挨着量化符前面的那个字符,匹配0次、1次或者多次,详细说明见下表。
| 量化符号 | 含义 | 数学表达式 |
| ? | 前面紧挨的元素,最多匹配 1 次 | 0<= x <=1 |
| * | 前面紧挨的元素,匹配 0 次或多次 | x >= 0 |
| + | 前面紧挨的元素,匹配 1 次或多次 | x >= 1 |
| {n} | 前面紧挨的元素,正好匹配 n 次 | x = n |
| {n,} | 前面紧挨的元素,至少匹配 n 次 | x >= n |
| {n,m} | 前面紧挨的元素,至少匹配 n 次,至多匹配 m 次 | n <= x <= m |
3. 常用特殊符
所为“特殊符”,指的就是由转义字符加某些字母组合而成的具有特殊意义的特殊字符,详细说明见下表。
| 特殊符 | 含义 |
| \d | 匹配一个数字字符——等价于[0-9] |
| \D | 匹配一个非数字字符——等价于[^0-9] |
| \s | 匹配任何空字符,包括空格、制表符、换页符等等——等价于[\f\n\r\t\v] |
| \S | 匹配任何非空白字符——等价于[^\f\n\r\t\v] |
| \w | 匹配包括下划线的任何单词字符——等价于[A-Za-z0-9] |
| \W | 匹配任何非单词字符——等价于[^A-Za-z0-9_] |
常用方法介绍
在re库中,一共提供了三个函数用于查找匹配,分别是match()、search()还有findall(),下面我们分别对他们进行讲述。
1. 三大函数含义对比
在这三个函数中,用的最多的是findall()这个函数,其次是search()函数,match()函数则用的很少。下面我们一一说明它的含义:
- match(pattern,string):匹配字符串的开头,如果开头匹配不上,则返回None;
- seach(pattern,string):扫描整个字符串,匹配后立即返回,不在往后面匹配;
- findll(pattern,string):扫描整个字符串,以列表形式返回所有的匹配值;
其中,pattern表示用于匹配的正则表达式,string表示待匹配的字符串。
2. 三大函数用法对比
前面我们已经介绍了这三个函数的具体含义,现在用一个案例对比说明它们的不同之处。导入相关库。
import re
如果有如下两个字符串。
s = "黄同学喜欢唱歌,黄同学喜欢写作,黄同学喜欢吃火锅!" s1 = "喜欢唱歌,喜欢写作,喜欢吃火锅"
① 使用match()函数
首先我们使用直接匹配s字符串中的“喜欢”二字。
re.match("喜欢",s)
这行代码没有返回结果,表示返回结果是None值,那是由于match()只匹配开头,如果开头不是“喜欢”二字,那么就返回None。
re.match("喜欢",s) == None
返回结果是:True。如果我们再使用match()函数,匹配s1字符串中的“喜欢”二字。
re.match("喜欢",s1)
返回结果是:<re.Match object; span=(0, 2), match='喜欢'>。上述结果得到的是一个匹配对象,如果我们想要获取其中的匹配值,就必须调用匹配对象的group()方法,获取具体的匹配值。
re.match("喜欢",s1).group()
返回结果是:’喜欢’
② 使用search()函数
接着我们使用直接匹配s字符串中的“喜欢”二字。
re.search("喜欢",s)
返回结果是:<re.Match object; span=(3, 5), match='喜欢'>。上述结果同样返回的是一个匹配对象,仍然需要调用group()方法,获取到具体的匹配值。
re.search("喜欢",s).group()
返回结果是:'喜欢'
③ 使用finall()函数
最后我们再使用直接匹配s字符串中的“喜欢”二字。
re.findall("喜欢",s)
返回结果是:['喜欢', '喜欢', '喜欢']
3. 其他常用方法
除了上述三个用于查找匹配的函数之外,还有用于切分的split()函数,有用于替换的sub()函数。另外还有两个常用修饰符re.I和re.S,简单了解一下。下面我们一一介绍它们的含义:
- split(pattern,string):按照某个匹配的正则表达式,将整个字符串切分后,以列表返回;
- sub(pattern,repl,string):按照某个匹配的正则表达式,将整个字符串的某个字串替换为另外一个字串;
- re.I:让正则表达式自动忽略大小写;
- re.S:让“.”能够匹配包括换行符在内的任意字符;
其中,pattern表示用于匹配的正则表达式,string表示待匹配的字符串,repl表示替换后的字串。假如有这样3个字符串:
s = "赵1钱2孙4李8周16吴32郑64王128黄" s1 = "Huang是huang" s2 = "黄\n同学"
需求1:将字符串s按照数字切分,以一个汉字组成的列表返回。
- 我们知道\d是匹配某一个数字,但是上述字符串里面,有2位的数字还有3位的数字,于是你会想到使用\d+表示匹配>=1个数字,因此整个代码如下:
re.split("\d+",s)
返回结果是:['赵', '钱', '孙', '李', '周', '吴', '郑', '王', '黄']。
需求2:将字符串s中的数字部分,全都替换为空。
- 同样我们仍然用\d+表示匹配>=1个数字,这道题的代码如下:
re.sub("\d+"," ",s)
返回结果是:'赵 钱 孙 李 周 吴 郑 王 黄'
需求3:将字符串s1中的h匹配出来,不区分大小写;
- 如果不加re.I,系统会将它们看待成不同的字符。
re.findall("h",s1)
返回结果是:['h']如果加了re.I,系统会忽略大小写,那么h和H就是同一个字符。
re.findall("h",s1,re.I)
返回结果是:['H', 'h']
需求4:将字符串s2整个匹配出来,包括换行符;
- 如果不加re.S,“.”不能匹配“\n”换行符。
re.findall(".+",s2)
返回结果是:['黄', '同学']如果加了re.S,“.”此时能够匹配“\n”换行符。
re.findall(".+",s2,re.S)
返回结果是:['黄\n同学']
本文来自博客园,作者:他还在坚持嘛,转载请注明原文链接:他还在坚持嘛 https://www.cnblogs.com/brf-test/p/15844697.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号