
SQL语句
登录数据库:
使用【Navicat】或是【SQLyog Community】登录下我们的数据库
面试题链接:https://blog.csdn.net/sublime_k/article/details/105645525
写sql语句:

mysql语句三部分:
- DDL:数据定义语句 create、drop、alter——定义语言【建数据库、建表、删除表、删除数据库】
- DML:数据操纵语句 select、insert、update、delete——操作语言【操作数据库】
- DCL: 数据控制语句 grant——是用来设置或更改数据库用户或角色权限的语句【控制数据库权限】
【-- or # —— 注释】
数据库操作: create database db_name charset utf8;——创建数据库,【db_name】自定义的数据库名字 drop database db_name;——删除数据库 use db_name;——切换数据库 show databases;——查看所有数据库 表操作: 创建表: 数据类型: 整形(int): tinyint——最大存127
smallint——最大存几千
int——最大存几十万
bigint——几十亿
——根据数据库实际的大小情况具体的指定所要使用的整形类型
浮点型(float)【看小数点后边有多少位】: float——小数点后边几十位 double——小数点后边几百位 字符串: char——不可变字节长度大小,无论是几个字节都是站固定的长度【定长】
varchar——【变长】,存的是多长就会占多长,一般都会使用这个
text——常用的文本类型 日期类型: date——年月日
datetime——年月日时分秒
timestamp——时间戳 约束【建表时指定好】: 1、主键约束 唯一、非空 primary key【类似于身份证,是唯一的】 2、外键约束 foreign key 3、唯一约束 unique 【在这个表里,不可以是重复的】 4、非空约束 not null【插入数据时,不可以为空】 5、默认值约束 default 【默认值】 6、自增长 auto_increment【每来一条数据,就自动的+1】
建表 & SQL语句
create table brf_student ( id int primary key auto_increment, name varchar(20) not null ,——()内表示指定的长度,not null表示不可以为空 phone varchar(11) unique not null,——unique表示是唯一的 sex tinyint default 0,——default 0,表示默认是0 name varchar(20) not null, addr varchar(30) , brith datetime default current_timestamp, index(name) , key(name)——加上索引,相当于字典的目录 ); ——int、float不需要指定字长,varchar需要指定字长 create table brf_score ( id int primary key auto_increment, score float not null, sid int not null ——sid是这个表的外键,加上外键就可以和其他的表关联起来了,也就是上个表的学生id ); create table student_new like student; -- 快速创建一个和student表结构一样的表 修改表: alter table student(表名) add class2 before(指定加到哪个字段前面) addr int not null; -- 增加字段 alter table student drop addr; -- 删除字段 alter table student change name new_name varchar(20) not null; -- 修改字段 alter table student modify name varchar(30) ; 删除表: drop table student; 清空表: truncate table student; -- 自增长id会重新开始 其他操作(命令行中): show tables;-- 查看当前所有表 show create table student; -- 查看建表语句 desc student; -- 查看表结构
SELECT DISTINCT score FROM brf_hhh -- 去重(根据score 去重) 数据操作: 增: insert into student values ('','python','11111111111',0,'北京','2019-01-03 18:39:23'); --写全 insert into student (name,phone) values ('mysql','12345678901'); -- 指定字段 insert into student (name,phone) values ('mysql1','12345678902'),('mysql2','22345678901'); --多条 insert into student_new select * from student; -- 把一个表的数据快速导出到另外一个表 修改: update student set name='mysql3' ; --修改全表数据 update student set name'mysql2',sex=1; --修改多个字段 update student set name='mysql3' where id = 1; #指定修改某条数据
【指定下where 条件,不然会全部修改】 删除: delete from student; --整表数据删除 delete from student where id = 3; --指定数据删除 查询: 基本查询 select * from student; select id,name,addr from student; --指定字段【id、name等是指定查询的字段】 【指定范围】 第一种‘in’方法:select * id,name from student where id in('xiaohei',1,2,4,5); select * id,name from student where id not in('xiaohei',1,2,4,5); ——【同Python,可以 not in】 第二种‘BETWEEN’方法:select id,username from app_myuser BETWEEN 80 and 90 and sex= 0;——可以and加多个条件 select id as 编号, addr 地址 , name 姓名 from student; --字段加别名 where条件 select * from student where id=1; --where条件 >,<,>=,<=,!=,<>也是不等于 select * from student where id in (1,2,3) and id != 5; -- in和and条件 select * from student where id between 1 and 5; -- 范围 select * from student where id between 1 and 5 or id > 10; -- or 排序 select * from student where id between 1 and 5 order by id desc; -- 一起用的话,order by必须写在where条件后面 select * from student order by id desc ; -- 降序排序,按照id,升序的话是asc【默认是升序,加上desc就是降序】——可多个字段 select * from student order by id,name asc ; -- 升序,按照id和name排序,asc可以省略不写 分组 select * from student group by sex; -- 按照某个字段分组,可以写多个字段 select * from student group by sex having addr !='北京'; select * from student where id >5 group by sex having addr !='北京'; -- 如果有where条件,必须写在group by前面,group by后面不能再写where条件,如果有条件必须用having子句 limit select * from limit 5;——limit后跟多少就是要查询多少条数据 select * from limit 2,5;——2和5:表示从第2行开始查询5条数据 select id as 编号, addr 地址 , name 姓名 from student limit 2; -- 前N条数据 select id as 编号, addr 地址 , name 姓名 from student limit 1,5; -- 从第一行开始,向后取5行,不包含第一行的数据 select * from student where id >0 group by sex having addr !='北京' limit 5; -- limit必须写在最后面 select * from student where id >0 group by sex having addr !='北京' order by id desc limit 5; -- limit必须写在最后面 #如果一个sql里面有where、group by、排序、limit,顺序一定是1、where 2、group by 3、order by 4、limit 聚合函数 select count(*) from student; -- 多少条数据 select count(addr) from student; -- 某个字段不为空的有多少条 select count(*) 人数 ,sex 性别 from student group by sex; -- 多少条数据 select avg(age) from student; -- 平均值 select sum(score) from score; -- 和 select min(score) from score; select max(score) from score; 子查询,一个字段的结果是从另外一个sql语句中查询出来的: select * from student where id in (select sid from score where score >= 60); 多表查询 select * from student a ,score b where a.id = b.sid and a.score>90; select a.name,b.score,a.class2 from student a ,score b where a.id = b.sid and a.score>90; select a.name ,b.score,a.class2 from student a inner join score b on a.id = b.sid where a.score > 90; select a.name ,b.score,a.class2 from student a left join score b on a.id = b.sid where a.score > 90; 授权【给数据库加用户,设置权限】时: (1)GRANT ALL privileges ON *.* TO 'root'@'localhost' IDENTIFIED BY '123456'; 【ALL 也可以是select insert delete,是select只会有select权限,ALL是有所有的权限】 ——第一个 * 代表哪个数据库,如是 * 代表是授权可以操作所有的,后边的是可以操作哪些表, 'root'是代表加了一个什么用户,'localhost'是一个IP地址,可以限制IP地址登录, 写了某个IP就是只可以某个IP登录,'localhost'代表只可以本机登录,远程登录不了,BY'123456'是密码。 (2)GRANT ALL privileges ON byz.* TO 'byz'@'%' IDENTIFIED BY '123456';【指定 某个值 操作 某个数据库】 ——byz代表指定的某个数据库,* 代表某个表,如是*则查看全部,‘byz'就是个表名,%代表所有的IP都可以,也可以指定 (3)flush privileges; 【刷新下权限】
下面是Linux命令,不是sql语句,在命令行里面执行的:
mysql常用命令: (1)mysql -uroot -p123456 -h192.168.1.1 -P3306 #登录mysql ——uroot指定那个用户;-p123456指定密码;-h192.168.1.1指定的IP,登录当前自己的数据库时,就不用指定IP,-P3306端口号,如果数据库没有更改过端口号,可不用填写,默认就是3306 (2)mysqldump -uroot -p123456 -h192.168.1.1 -P3306 -A > /tmp/all_data.sql #备份所有数据库【会把数据库所有的表转化为sql语句,放到一个文件里面,到时执行下文件】就可以了 —— -A代表所有的数据库;-d 代表指定的数据库,如:-d jxz,就是指定 jxz这个数据库 >all_data.sql:会把所有的数据库的所有表操作成select语句; (3)mysqldump -uroot -p123456 -h192.168.1.1 -P3306 --add-drop-table --add-drop -A > /tmp/all_data.sql #导出带有删除表和删除库的sql —— add-drop 导出数据库,代表删除数据库的sql语句也要给我备份下,这样就会把之前的数据库删掉,不需要手动删掉了,可以直接使用备份的数据库了 (4)mysqldump -uroot -p123456 -h192.168.1.1 -P3306 --no-data -d nhy_db > /tmp/all_data.sql #只导出表结构 (5)mysql -uroot -p123456 -h192.168.1.1 -P3306 nhy_db < all_data.sql #恢复数据库 (6)less jxz.sql #指定数据库分屏显示,jxz代表指定的数据库 (7)ls P*——模糊查询,*就是查询出包含P的文件 …… 还有很多命令,可以搜索:mysqldump查看 备份脚本: command = 'mysqldump -uroot -p123456 -A >all_data%s.sql'【%s,可以设置成时间戳,每天文件名就变了,不会被覆盖了】 os.system('command')——可以设置下多久执行一次,然后在发送到邮箱
练习:
- 分组:查询一个数据库的表可以分为几个不同组,分别每个组有多少条数据
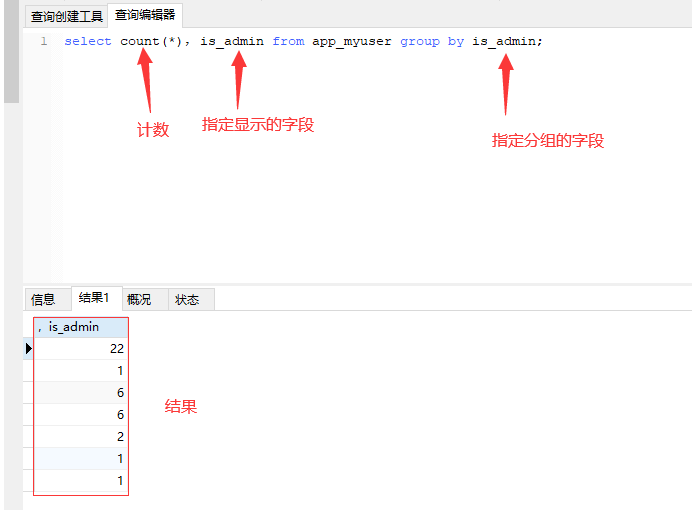
- 多个字段连用分组——需求:先找出班级中大于90分以上的,然后在进行分组
select * from app_myuser WHERE score >= 90 GROUP BY class2;——GROUP BY必须写到where后边 select * from app_myuser GROUP BY class2 HAVING score>=90;——如果想要在【GROUP BY】后边加条件,使用HAVING,后边可以继续加 and 条件
select * from app_myuser WHERE id>5 GROUP BY sex HAVING score>5 ORDER BY score; ——多个字段使用顺序【where】——【GROUP BY】——【GROUP BY】——【ORDER BY】
-
统计数据
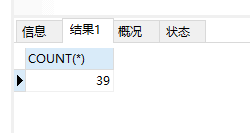
SELECT COUNT(*) FROM app_myuser;app_myuser——指定的任意表名
加别名:
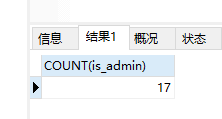
SELECT COUNT(*) AS 条数,is_admin 账户 FROM app_myuser;——可加多个指定的字段别名后统计【AS可省略不写】 SELECT COUNT(is_admin) FROM app_myuser;——is_admin指定统计的字段,只是统计字段中不为空的,为空的不包含在内

-
模糊查询
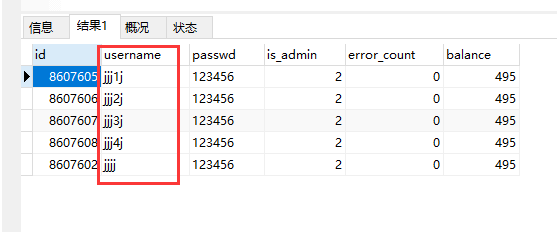
SELECT * FROM app_myuser WHERE username LIKE "jjj%"—— 【 jjj% 】开头是jjj的全部查询出来
-
多表关联查询
select * from app_myuser,app_myuser_2 WHERE app_myuser.id = app_myuser_2.id select * from app_myuser as a,app_myuser_2 as b WHERE a.id = b.id——当表名长时,可以加别名

【多表关联】指定字段查询(效果较高):
select a.username,a.passwd,b.username from app_myuser as a,app_myuser_2 as b WHERE a.id =b.id;——后边可以追加where and or 条件

(1)【多表关联】左连接查询:
左连接是左边表的所有数据都有显示出来,右边的表数据只显示共同有的那部分,没有对应的部分只能补空显示,所谓的左边表其实就是指放在left join的左边的表
用韦恩图表示如下:
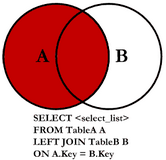
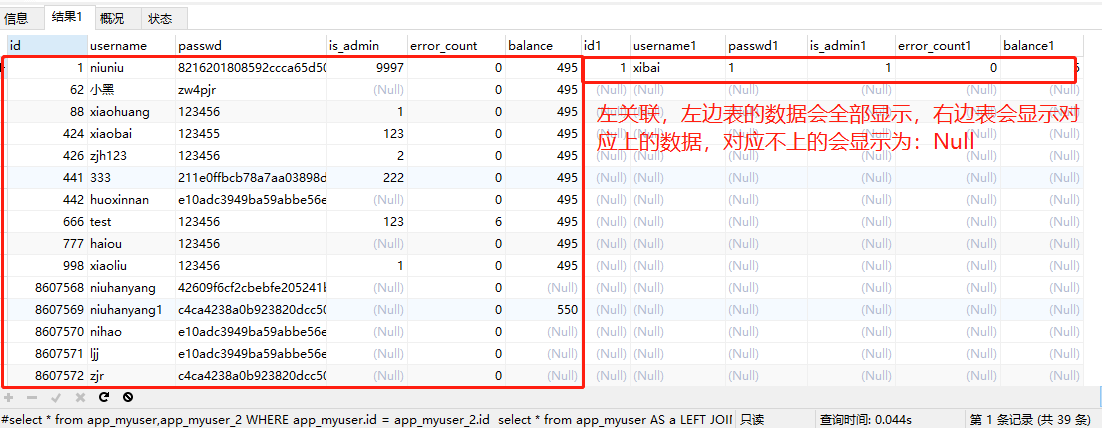
select * from app_myuser AS a LEFT JOIN app_myuser_2 b ON a.id = b.id;
(2)【多表关联】右连接查询:
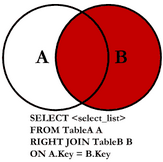
select * from app_myuser AS a RIGHT JOIN app_myuser_2 b ON a.id = b.id;

(3)【多表关联】内连接查询:
——内连接是一种一一映射关系,就是两张表都有的才能显示出来:
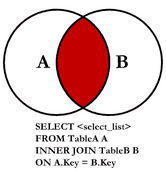
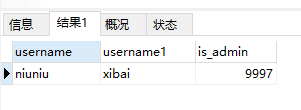
select a.username ,b.username,a.is_admin from app_myuser a inner join app_myuser_2 b on a.id = b.id;——最后边可以继续接:where条件之类的
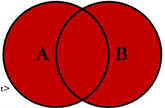
(4)OUTER JOIN(外连接、全连接)
查询出左表和右表所有数据,但是去除两表的重复数据
韦恩图表示如下:

(5)如果没有此表则创建:if not exists
create table if not exists file_name6666( id int primary key auto_increment, sex tinyint default 0, name varchar(20) not null, addr varchar(30) , brith datetime default current_timestamp, index(name) , key(name) )
(5)通配符:
- %s & { }
sql = 'select * from %s'%name sql = f'select * from {name}' #这种方式在Python3.6以上的版本可用
本文来自博客园,作者:他还在坚持嘛,转载请注明原文链接:他还在坚持嘛 https://www.cnblogs.com/brf-test/p/14129170.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号