MySQL学习笔记
第一章 了解SQL
1.1数据库的基本概念
数据库(database):存储和管理数据的系统,保存有组织数据的容器。
1.2 数据库软件
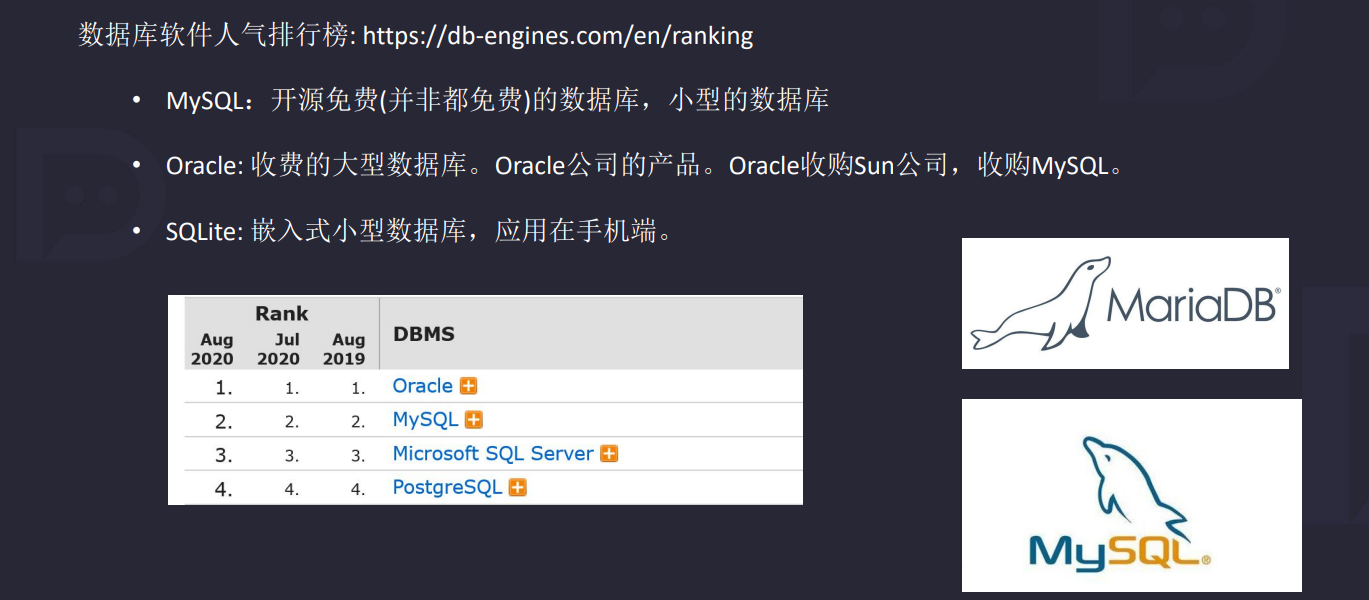
1.3 MySQL的特点和优势

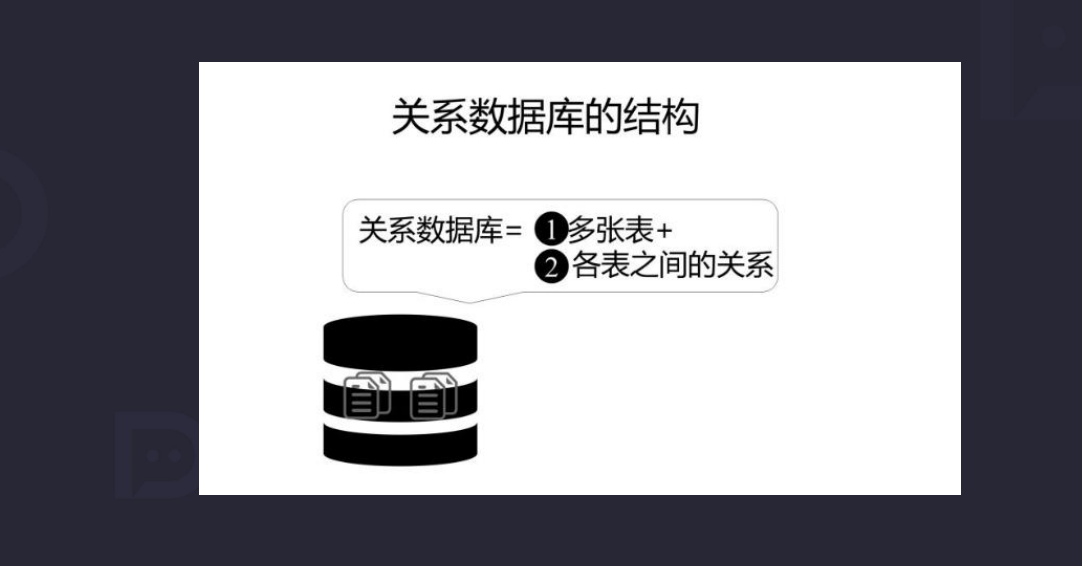
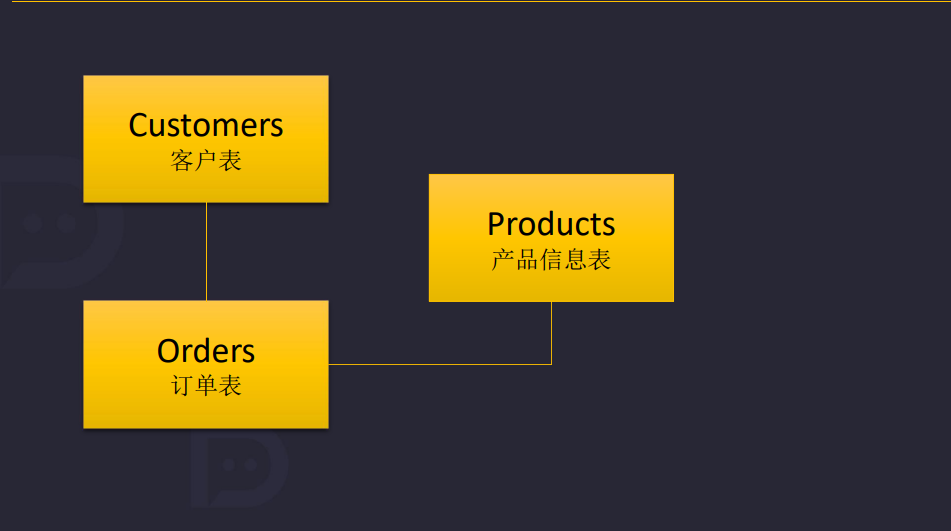
1.4 数据库如何存放数据
第二章 数据定义语言DDL
数据定义语言(DDL).pdf-MySQL文档类资源-CSDN文库
2.1 SQL语句
SQL(Struct Query Language,结构化查询语句)就是对数据库进行操作的一种语言。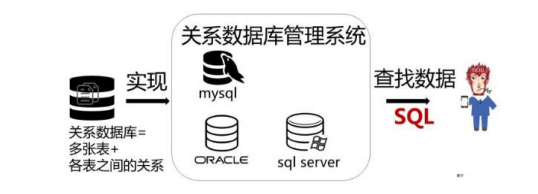
2.2 SQL语言分类

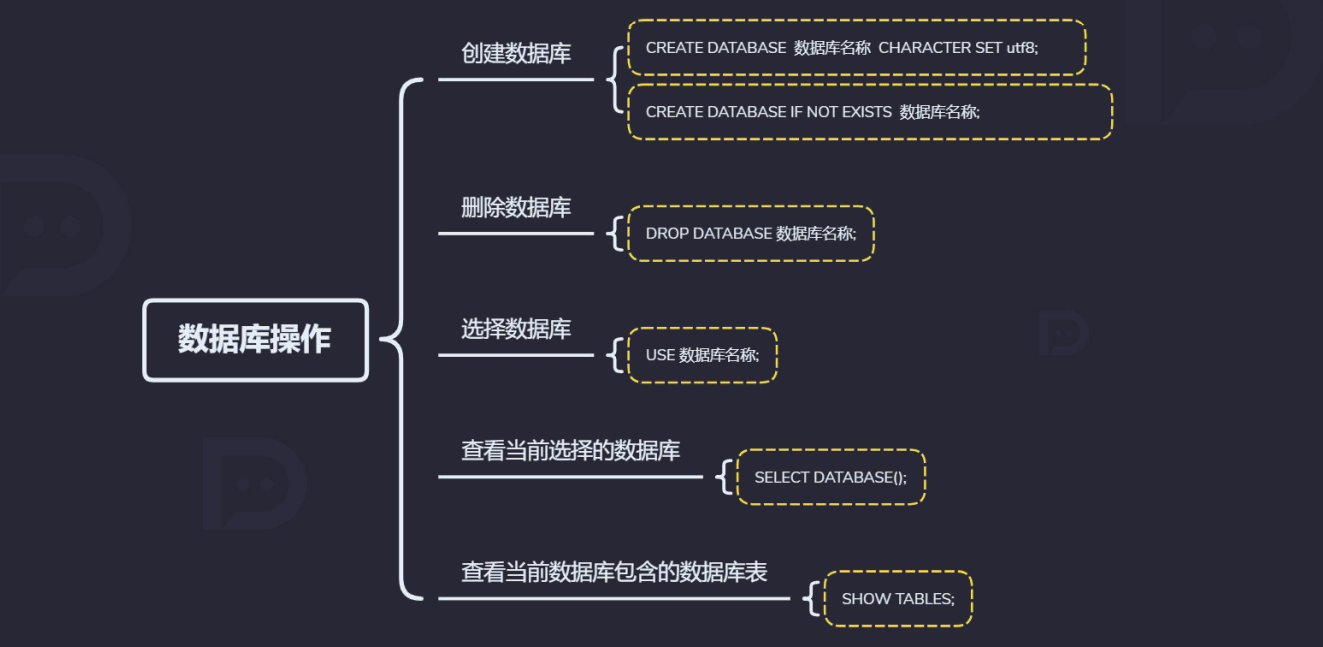
2.3 数据库操作
注释的使用:
# ctrl+/:行注释
/*ctrl+shift+/:块注释 */
数据库操作
# 显示所有数据库
show databases;
# 创建数据库
create database if not exists test;
use test;
# 删除数据库
drop database test
2.4 表操作
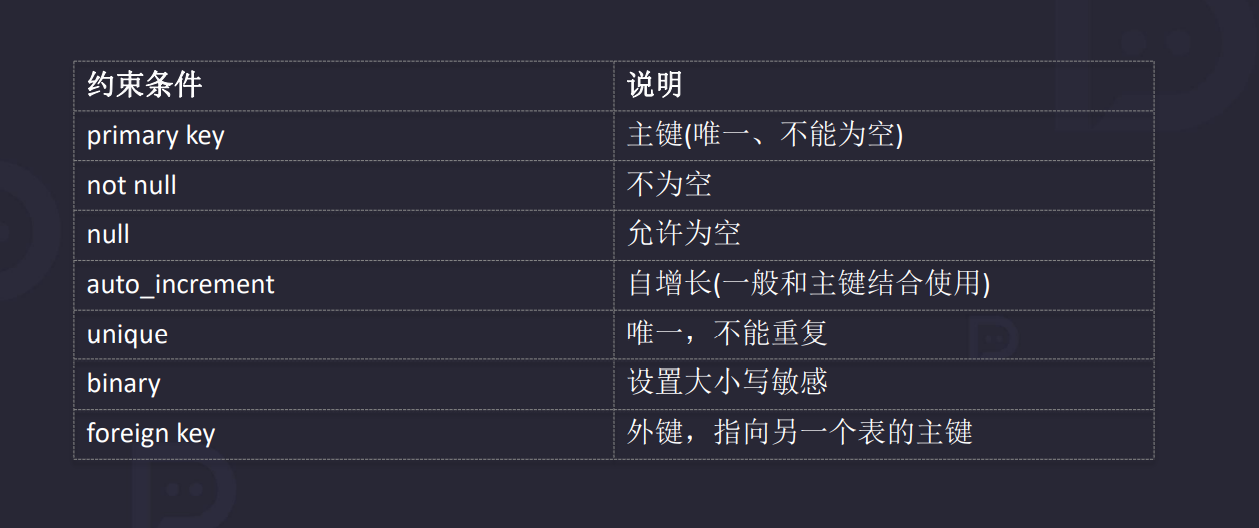
主键:一个表里面只允许有一个主键列,往往是整形,自增长,不允许为空的列。
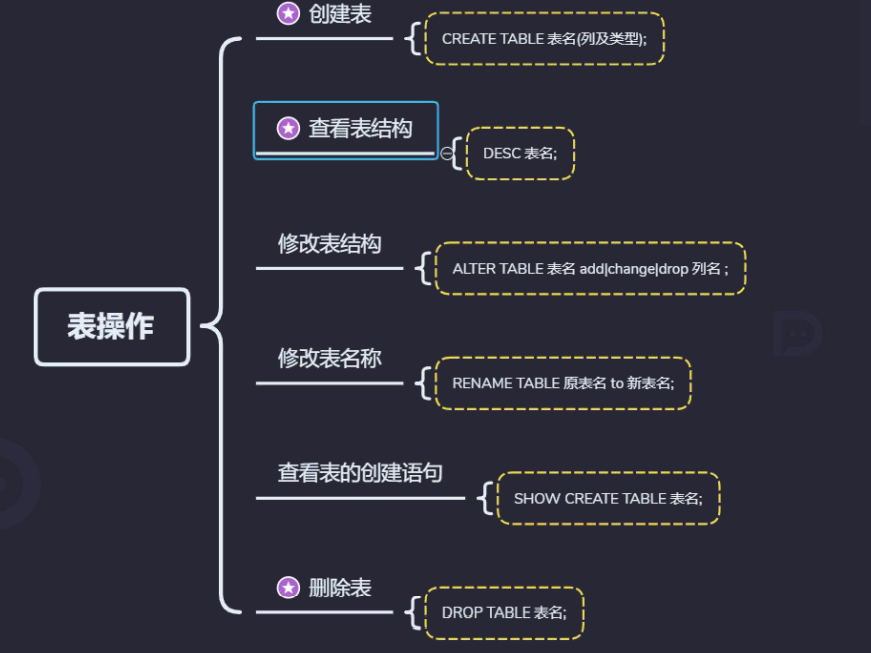
# 创建表
create table student
(
sid int(11) primary key auto_increment,# 整形,如:0,1,2,3,4
name varchar(255) unique ,# 字符类型
age int(11) not null
)
# 查看表结构
desc test.student;
# 修改表结构
alter table student add tel char(11); # 添加一列
alter table student drop age; # 删除类
alter table student modify column tel int(11);# 修改类数据类型
alter table student change tel telephone char(11); # 修改tel列为telephone
# 修改表明
rename table student to t_stu;
# 查看建表语句
show create table t_stu;
# 查看建库语句
show create database test;
# CREATE TABLE `t_stu` (
# `sid` int DEFAULT NULL,
# `name`varchar(255 ) DEFAULT NULL,
# `telephone` char(11) DEFAULT NULL
# ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
# CREATE DATABASE `huzi` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */
# 插入一条数据
insert into `student` (sid, name, age) values (0,"王五",23);
mysql8默认字符集是utf8
schemas:数据库
collations:校对规则,理解为排序规则,公司中比较常见的是utf8_general_ci
users:数据库用户
2.5 数据类型

2.6约束条件
第三章 数据操作语言DML
3.1 数据库存储引擎

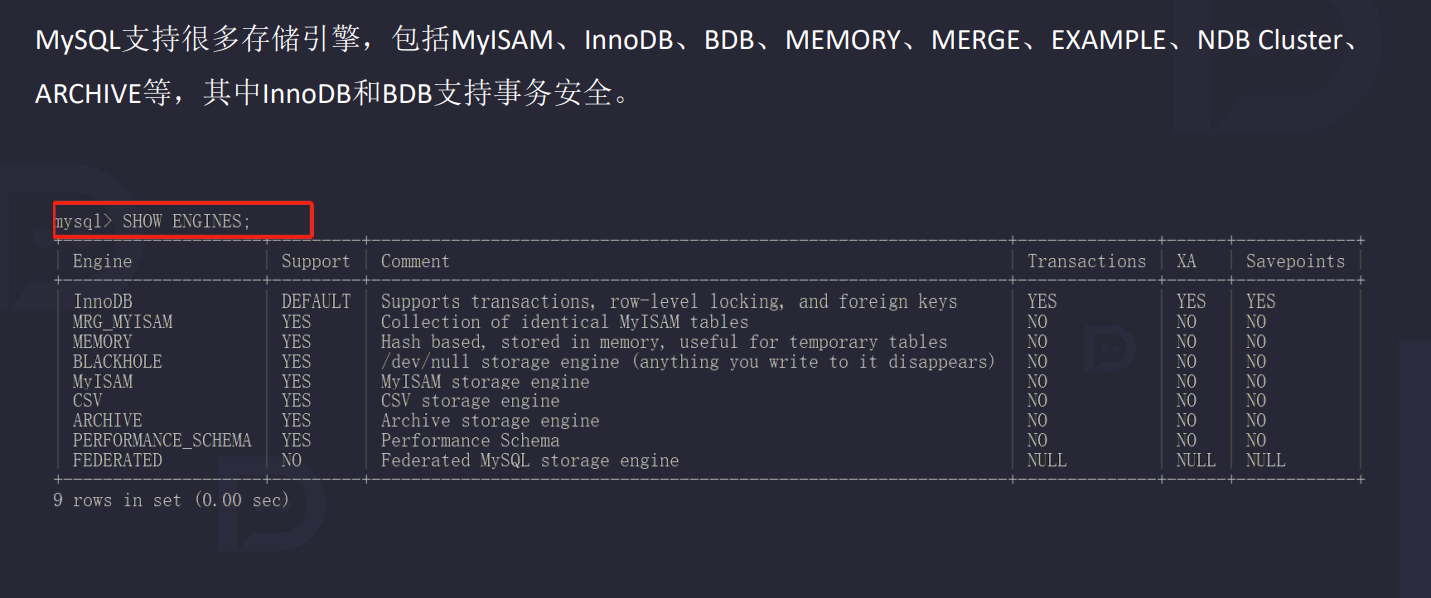
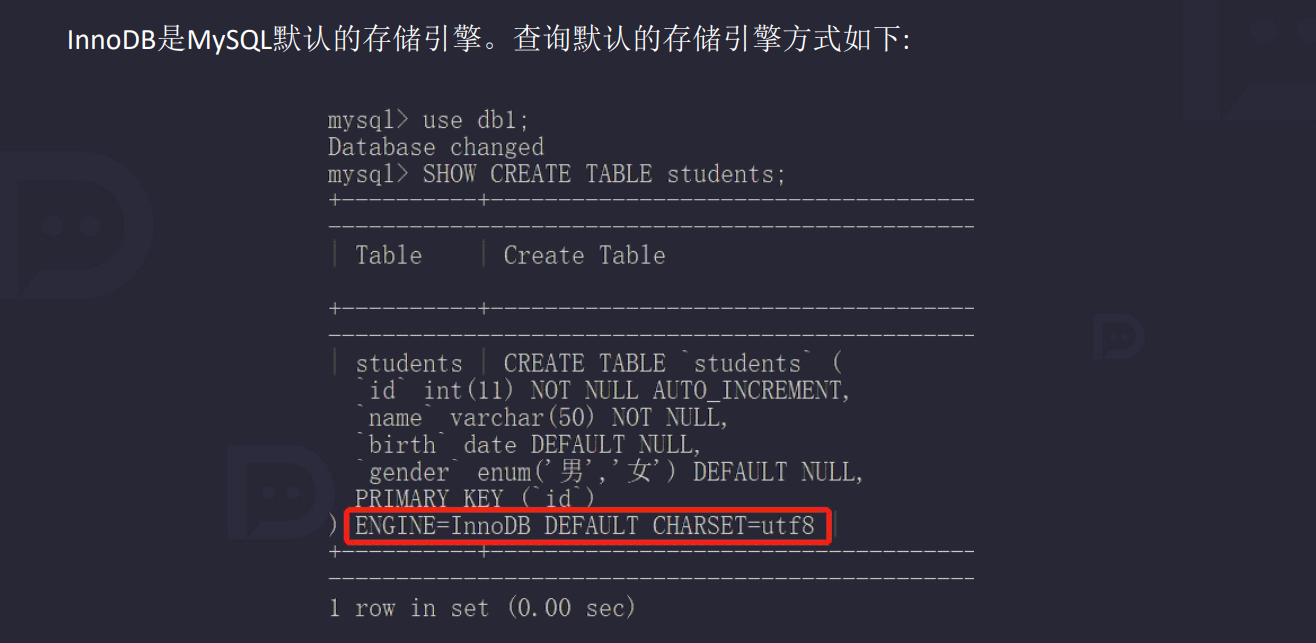
查看当前数据库支持的引擎有哪些
show engines ;
# 行锁:锁住一行数据,只有等当前连接操作完,别的连接才可以进行此行数据操作;
# 表锁:锁住整张表,只有等当前连接操作完,别的连接才可以进行表数据操作;
# 大小写问题(window下和linux下的大小写有区别;可以通过修改配置文件去让数据库区分大小写问题)
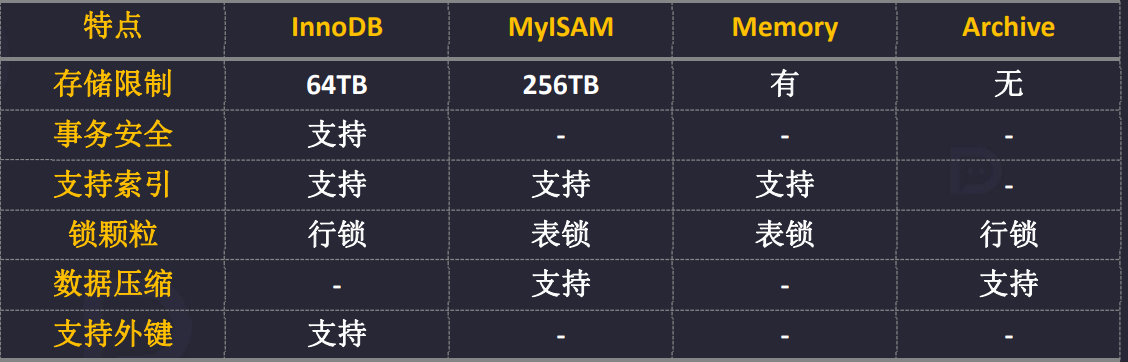
3.2 存储引擎对照
事务:是数据库操作的最小工作单元,是作为单个逻辑工作单元执行的一系列操作;这些操作作为一个整体 一起向系统提交,要么都执行、要么都不执行。
3.3 DML操作
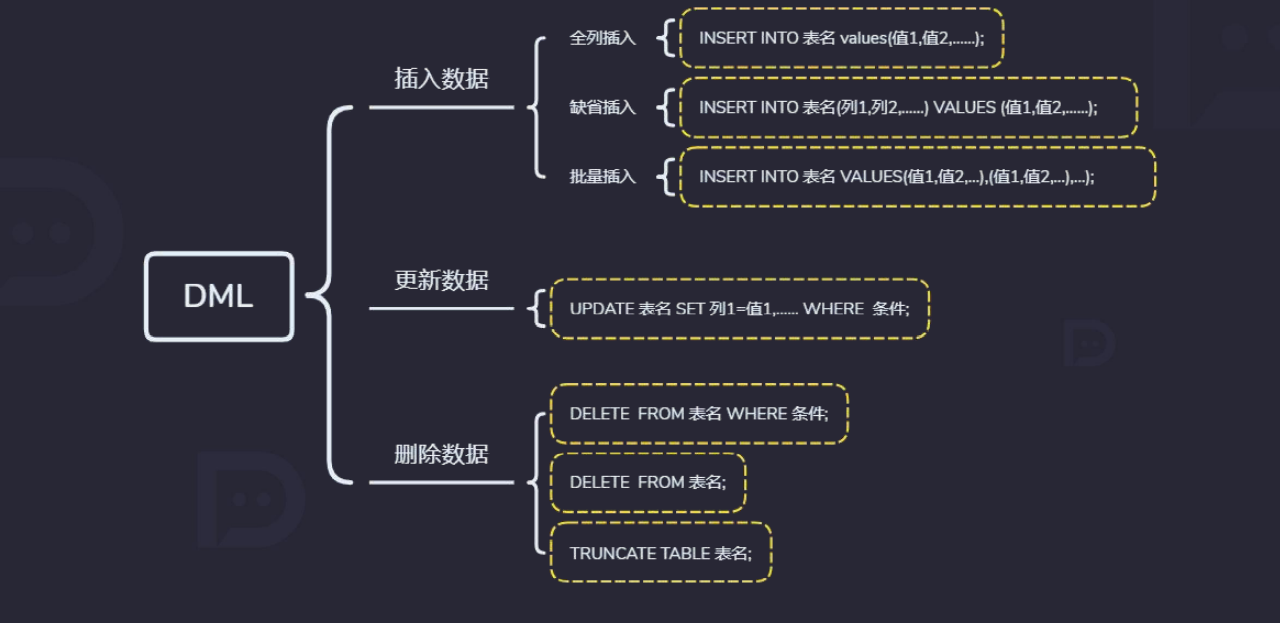
# 建表
use huzi;
# 插入:全列插入
insert into huzi.student values (0,"lisi");
# 缺省插入
insert into huzi.student (`name`) values ("wang");
# 批量插入
insert into huzi.student (`name`) values
("sun"),("xue"),("zhao");
# 更新/全部更新
update huzi.student set name="sun" where name="lisi";
update huzi.student set name='xue';
# 利用工具实现表数据的导入和导出功能:
# 导出:在库或者表上右键,选择导出到文件即可
# 导入:在库或者表上右键,选择导入数据(如果表不存在,会自动建表;如果存在,会直接插入数据)
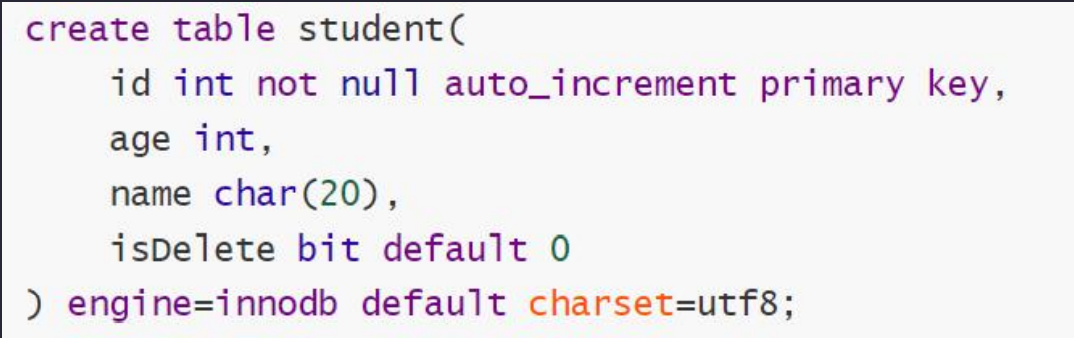
3.4 物理删除与逻辑删除
-
物理删除:
就是将数据从数据库中彻底删除。DELETE操作属于物理删除,物理删除的数据无法 恢复,对于一些重要的数据,以后建议使用逻辑删除。
-
逻辑删除:
本质是修改(UPDATE)操作,对于重要数据表,增加一个isDelete字段,一般默认为0(没有被 删除的的意思),该字段逻辑上表示该条数据是否被删除,真实情况是在数据库中本条数据还存在
3.5 DELETE PK TRUNCATE
【DELETE PK TRUNCATE】
- truncate不能加where条件,而delete可以加where条件
- truncate的效率高一丢丢
- runcate 删除带自增长的列的表后,如果再插入数据,数据从1开始 delete 删除带自增长列的表后,如果再插入数据,数据从上一次的断 点处
- truncate删除没有返回值,delete删除有返回值(返回多少列收到影响)
- truncate删除不能回滚,delete删除可以回滚
# 删除数据:delete,删除表:drop
delete from huzi.student where id=4;
delete from huzi.student;
# truncat:也是删除行数据,但是不可以加where,执行效率比delete要高。
truncate table huzi.student;
# 删除表
drop table huzi.student;
第四章 数据查询语句DQL
4.1 条件查询
-
比较查询:=,>,<,>=,<=,<>,!=
-
逻辑运算符
-
范围查询
- in 非连续区域查询
- between…and…连续区域查询
-
空判断
- is null 判空
- is not null 判非空
- “” 空字符串
4.2 其他查询
4.2.1 模糊查询
like
% 任意字符
_任意单个字符
4.2.2 分页查询
limit [start] count 从start开始获取count条数据
limit count offset start 从start 开始跳过offset个数据,获取count 条数据
4.2.3 排序查询
升序
order by 列1 asc, [列2 asc]
降序
order by 列2 desc, [列2 desc]
4.3 聚合查询
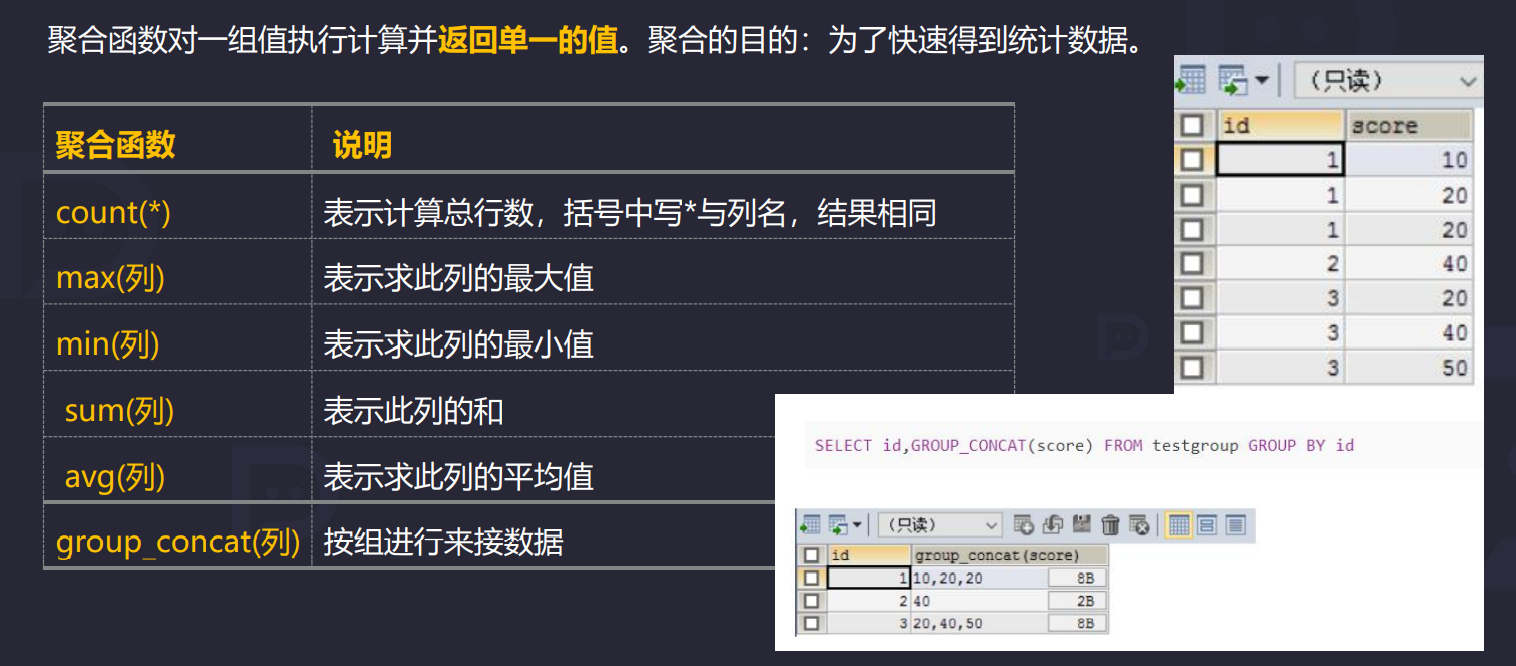
# count(*) < count(1) < count(列名,索引列效率高)
use huzi;
#查询员工人数
select count(1)
from employee;
# 分组统计男女生人数
select count(1), gender
from employee
group by gender;
4.4分组查询

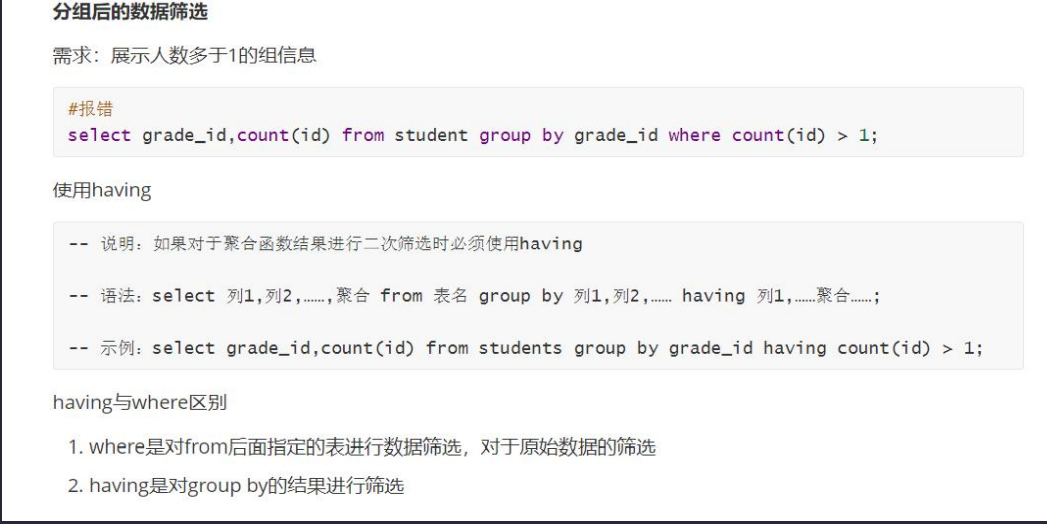
select 列1,列2,……,聚合 from 表名 group by 列1,列2,…… having 列1,…
练习测试
# 练习:查询每个班级最大分数
# 1、建表语句
CREATE TABLE `student5`
(
`id` int(11) primary key AUTO_INCREMENT,
`name` varchar(50) NOT NULL COMMENT '姓名',
`score` int(11) NOT NULL COMMENT '成绩',
`classid` int(11) NOT NULL COMMENT '班级'
);
# 2、插入数据
insert into student5(Name, Score, ClassId)
values ("lqh", 60, 1);
insert into student5(Name, Score, ClassId)
values ("cs", 99, 1);
insert into student5(Name, Score, ClassId)
values ("wzy", 62, 1);
insert into student5(Name, Score, ClassId)
values ("zqc", 88, 2);
insert into student5(Name, Score, ClassId)
values ("bll", 100, 2);
select max(s.score) as "最高分", s.classid
from student5 s
group by s.classid;
# 显然实际中不符合场景,只能看到班级最高分,但是看不到是谁拿了最高分
#改正后
select *
from student5
where score in
(select max(s.score) as "最高分" from student5 s group by s.classid);
4.5 外键
主键:一个表里可以有或没有,但最多只能有一个
外键:一个表里可以有或没有,可以有多个.
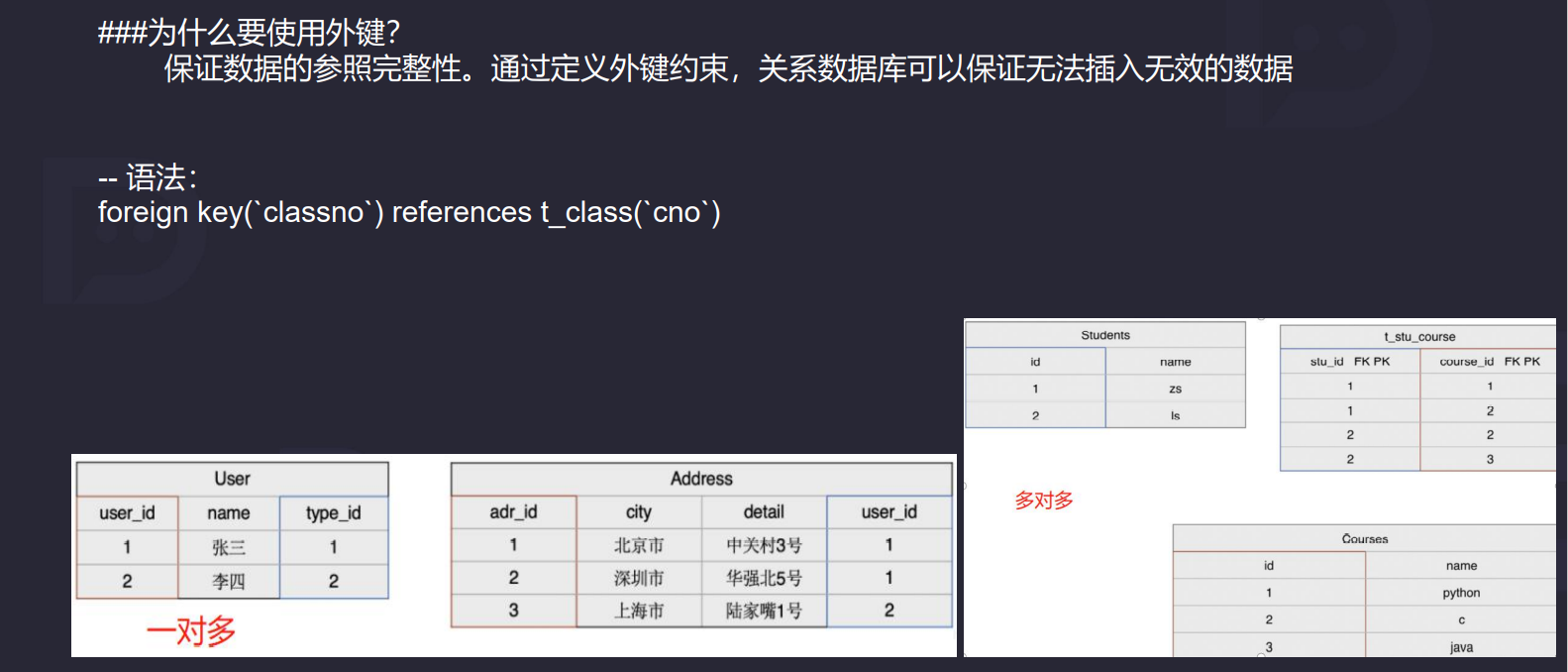
#创建语法
constraint [外键名] foreign key (列名) references 另外表(列名)
#也可以直接放在列名后面
create table t_user ( -- 主键表
uid int primary key auto_increment,
name varchar(255) not null
);
create table t_order( #外键表
oid int primary key auto_increment,
price int not null ,
count int not null , -- 下单量
uid int not null ,
constraint fk_order_user foreign key(uid) references t_user(uid) -- 外键
);
4.6 多表查询
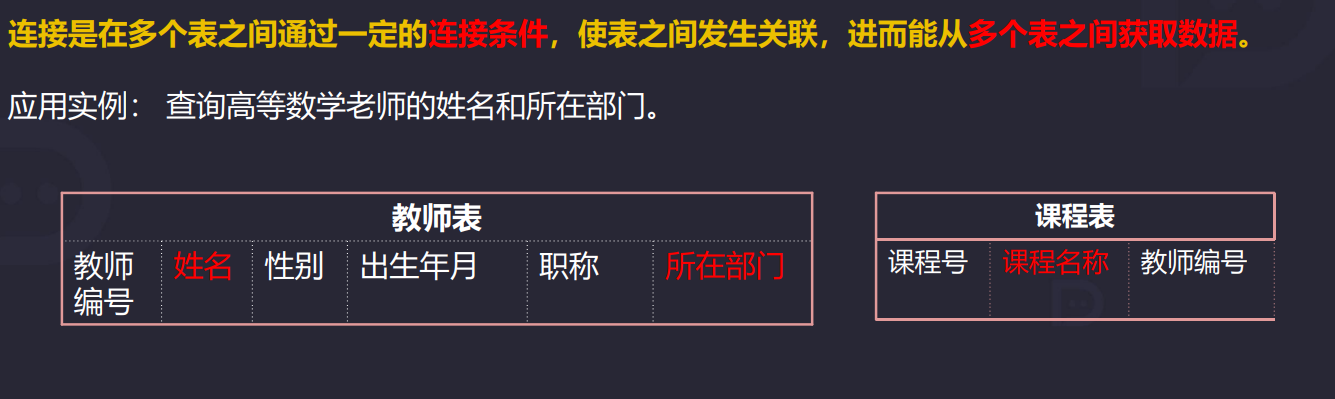
4.6.1 笛卡尔积现象
笛卡尔积现象在多表进行联合查询时会出现。表一有5条记录,表二有3条记录,第一张表有5种选择, 第二张表有3种选择。所以结果就是5*3种选择了,也就是笛卡尔积现象。
select * from emp,dept;
如何解决

4.6.2 内连接
- 隐式内连接
内连接用左边表的记录去匹配右边表的记录,如果符合条件的则显示。如:emp.dept_id=dept.id
隐式内连接: 看不到 join 关键字,条件使用 where 指定
select */字段列表 from 左表,右表 where 条件表达式;
select * from emp,dept where emp.dept_id=dept.id;
- 显示内连接
显式内连接: 使用inner join…on语句,可以省略inner
select */字段列表 from 左表 [inner] join 右表 on 条件表达式;
#例如
select emp.name,emp.salary,dept.name from emp join dept on emp.dept_id=dept.id;
select e.name,e.salary,d.name from emp e join dept d on e.dept_id=d.id
4.6.3 外连接
- 左外连接:
用左边表的记录去匹配右边表的记录,如果符合条件的则显示;否则,显示 NULL(左边全部
select */字段列表 from 左表 left [outer] join 右表 on 条件表
#左表独有数据
select *
from t1
left join t2 on t1.id = t2.id
where t2.id is null;
- 右外连接:
用右边表的记录去匹配左边表的记录,如果符合条件的则显示;否则,显示 NULL(右边全部显示)
select */字段列表 from 左表 right [outer] join 右表 on 条件表
#右表独有数据
select *
from t1
right join t2 on t1.id = t2.id
where t1.id is null;
4.6.4 全连接
# 全连接(mysql不支持全连接,但是可以通过union变相实现全连接;oracle支持全连接)
# 含义:两表关联,查询出所有数据
select *
from t1
left join t2 on t1.id = t2.id
union
select *
from t1
right join t2 on t1.id = t2.id;
# 结论:union和union all都可以完成两个表连接,union可以自动对数据去重,union all不去重;
# union all 比 union 效率高很多。
4.7 子查询

#练习:都用子查询实现
# 1. 查询渠道部有所有员工信息。(位于不同表)
select *
from emp
where dept_id = (select dept.id from dept where dept.name = "渠道部");
# 2. 查询工资最高的员工信息。
select *
from emp
where salary = (select max(salary) from emp);
# 3. 查询工资小于平均工资的员工信息。
select *
from emp
where salary < (select avg(salary) from emp);
select avg(salary)
from emp;
# 4. 查询工资大于 5000 的员工,来自哪些部门?
select *
from dept
where id in (select dept_id from emp where salary > 5000);
# 5. 查询研发部与渠道部所有的员工信息。
select *
from emp
where dept_id in (
select id
from dept
where name in ('研发部', '渠道部')
);
第五章 事务
5.1 什么是事务

5.2 事务的特征
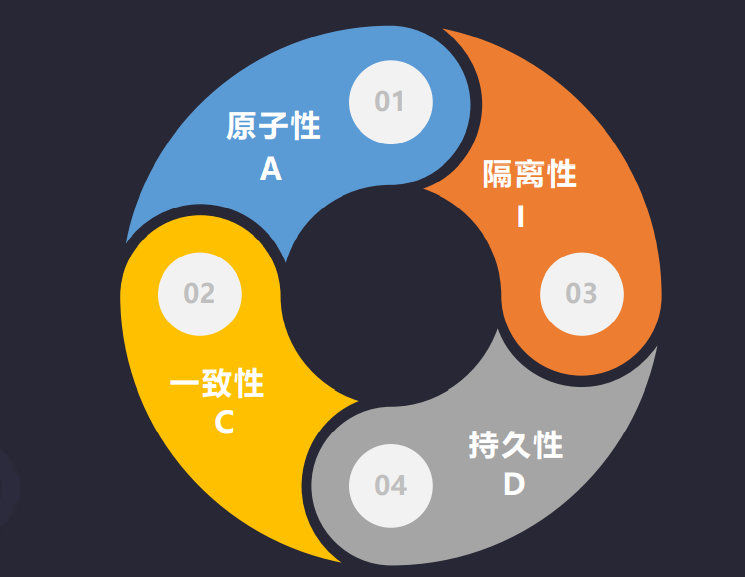
- 原子性(Atomicity,或称不可分割性)
一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样
- 一致性(Consistency)
在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作
- 隔离性(Isolation,又称独立性)
数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)
- 持久性(Durability)
事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失
5.3 事务控制语句
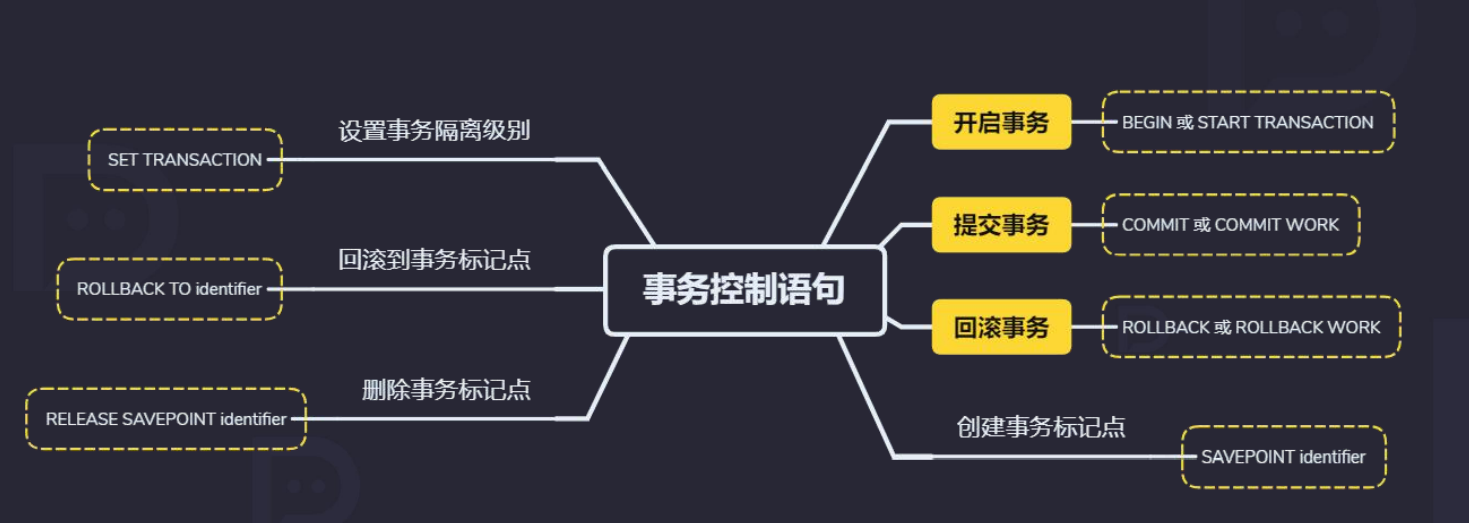
标记点作用:当你一个事物中有大量sql操作的时候,如果rollback(默认回到原始状态)效率极低,可以考虑回到某个标记点
# mysql数据库默认自动提交事物:
begin;
insert into test.student (name, sex) values ('zhangsan',0);
savepoint p1;
insert into test.student (name, sex) values ('lisi',0);
rollback to p1;
commit ;
autocommit:

mysql> show variables like ‘autocommit’;
直接用 SET 来改变 MySQL 的自动提交模式(自动模式)
配置仅临时有效
-
SET AUTOCOMMIT=0 禁止自动提交,可在黑窗口下操作,每个SQL语句或者语句块所在的事务都需要显示"commit"才能提交事务。
-
SET AUTOCOMMIT=1 开启自动提交
5.4 事务中常见现象
5.4.1 脏读

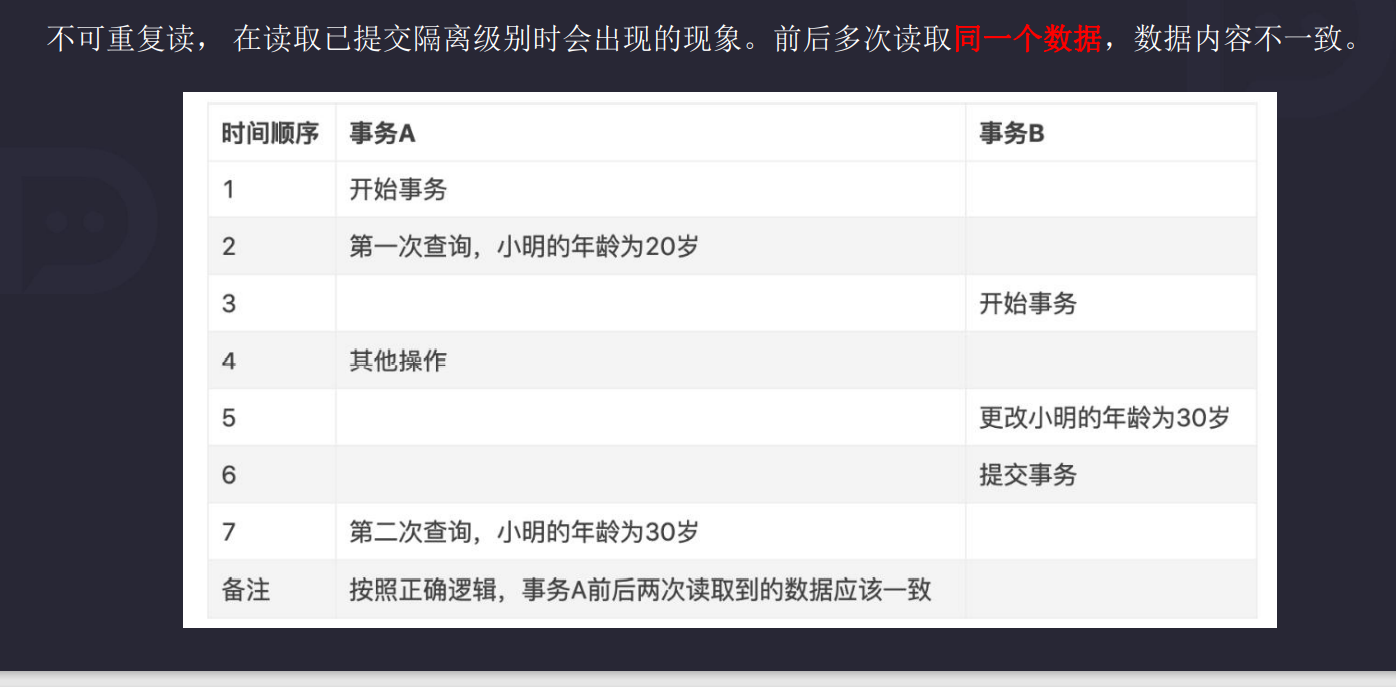
5.4.2 不可重复读
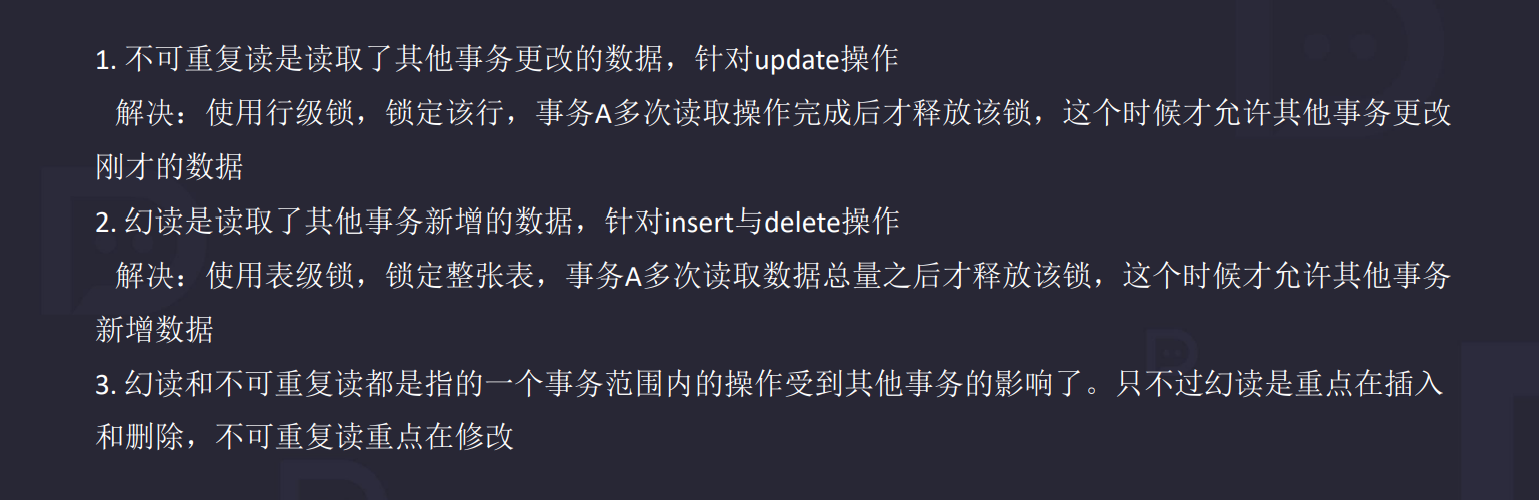
5.4.3 幻读

不可重复读与幻读区别
第六章 视图
6.1 什么是视图

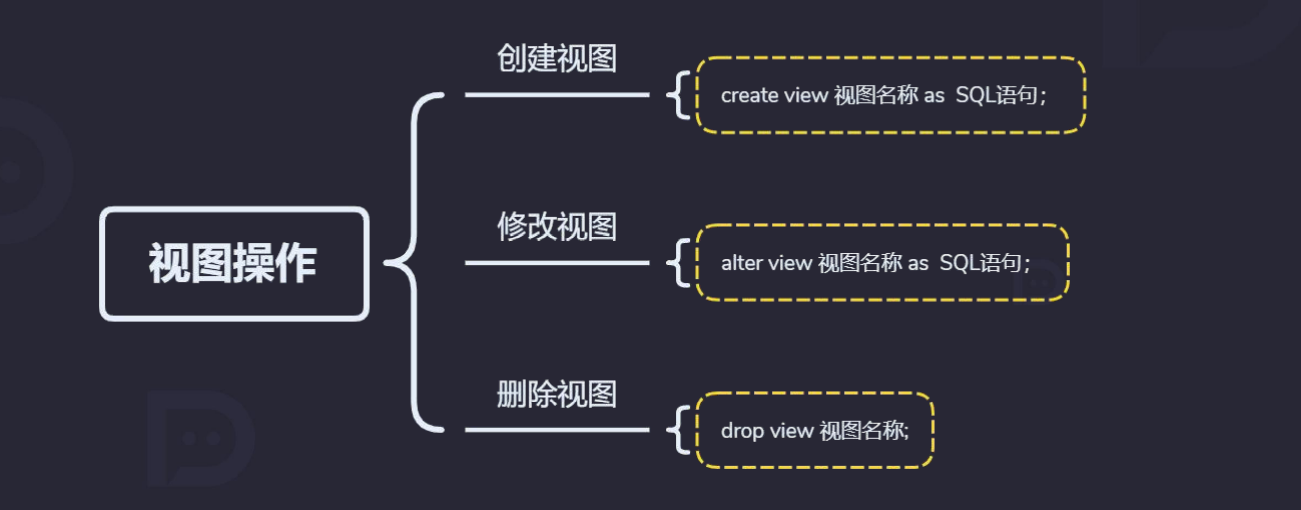
6.2 视图操作
# 视图练习:
use test;
create table student(
id int not null auto_increment primary key,
age int,
sid char(20),
sex bit,
name char(20),
isDelete bit default 0
) ;
insert into student(age,sex,name) values (18, 1, "liudehua");
insert into student(age,sid,sex,name) values (18, '', 1, "liudehua");
insert into student(age,sex,name) values (36, 1, "高磊"),(20, 1, "高鹏鹏"),(30, 1, "高子龙"),(30, 1, "高兴");
insert into student(age,sex,name) values (34, 1, "高%");
# 假设:需要经常过滤id大于3的学生中,对年龄过滤20、30、40
select * from (select * from student where id > 3) as st where age > 20;
select * from (select * from student where id > 3) as st where age > 30;
select * from (select * from student where id > 3) as st where age > 40;
# 视图写法:
create view v_stu as select * from student where id > 3;
select * from v_stu where age>20;
select * from v_stu where age>30;
select * from v_stu where age>40;
# 修改视图:
alter view v_stu as (select * from student where student.name like '高%');
select * from v_stu;
# 删除视图:
drop view v_stu;
# 总结:视图多用于查询频次较高的语句或者逻辑较为复杂的场景,可以考虑建立视图
# 比如:网站首页数据;网站顶部筛选过滤;
第七章 存储过程
7.1 什么是存储过程

7.2 操作
要求 : 创建一个名称为dba的库文件,在dba库中创建一张名称为tb1的表,表中有id、name这两个 字段。创建一个名称为ad1的存储过程,ad1存储过程的功能是插入三条记录到tb1表中。
create database dba;
use dba;
create table tb1(id int ,name varchar(255));
delimiter $$ -- 修改结尾符为
create procedure ad1() -- 定义存储过程
begin
declare i int default 1; -- 声明一个变量i,默认值为1
while (i<=3)do
insert into tb1 (id, name) VALUES (i,'zhangsan');
set i = i+1; -- 每执行一次,i值加1
end while;
end;$$
delimiter ;
call ad1(); -- 调用存储过程
第八章 触发器
8.1 什么是触发器
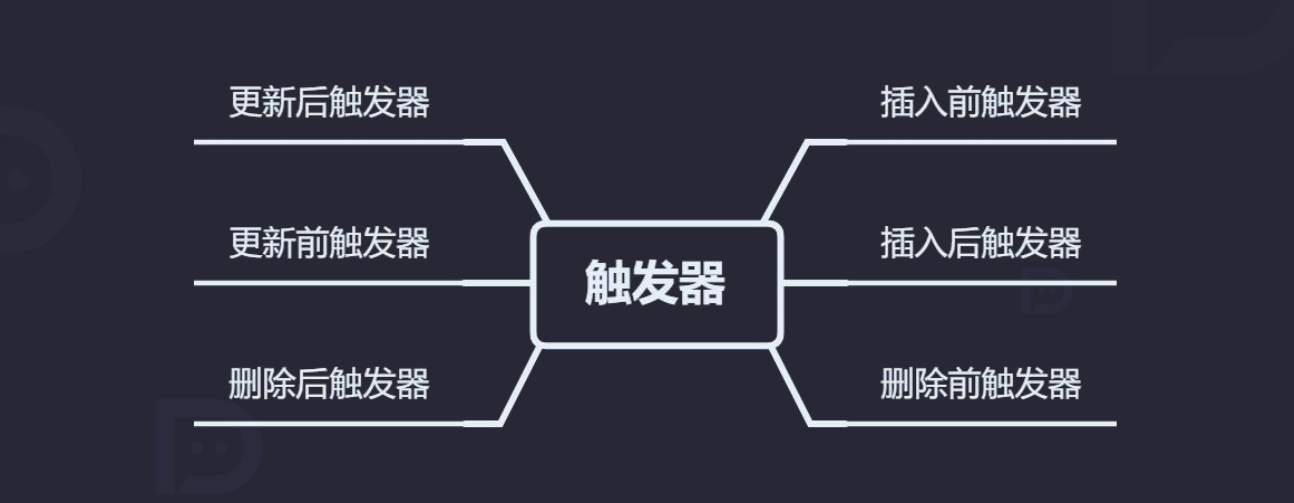
8.2 触发器类别
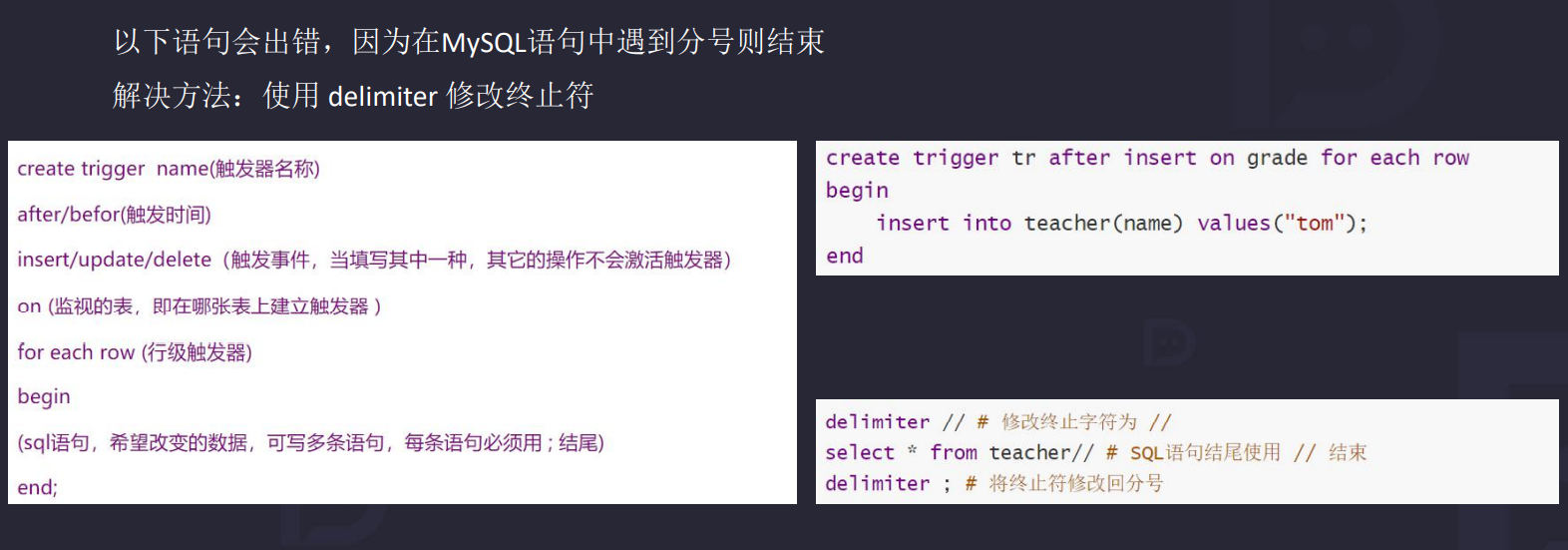
8.3 触发器常见错误
练习
use test;
# 触发器的使用
# 1.创建富豪榜
create table wealthy(
id int primary key auto_increment,
age int,
name varchar(20),
money int
);
# 2.插入数据
insert into wealthy values(1,20,'张三',110);
insert into wealthy values(2,35,'李四',110);
insert into wealthy values(3,35,'王五',90);
insert into wealthy values(4,20,'赵六',90);
# 3.创建平民
create table person(
id int primary key auto_increment,
age int,
name varchar(20),
money int);
# 4.插入平民
insert into person values(0,20,'十一',30);
# 5.编写触发器
drop trigger if exists peopel_trigger_update_after; -- 如果存在则删除
delimiter $$
create trigger peopel_trigger_update_after after update on person for each row
begin
if new.money >200 then -- 资金来路不明
signal sqlstate 'ERR10' set message_text ='资金可能来路不明'; -- 抛出异常信息
elseif new.money>50 then -- 如果大于50,将这条数据插入到富豪榜
insert into wealthy (age, name, money) VALUES (old.age,old.name,new.money);
end if;
end;$$
delimiter ;
show triggers ; -- 查看所有触发器
# 演示触发触发器
update person set money=150 where id=1;
第九章 函数
9.1 什么是函数


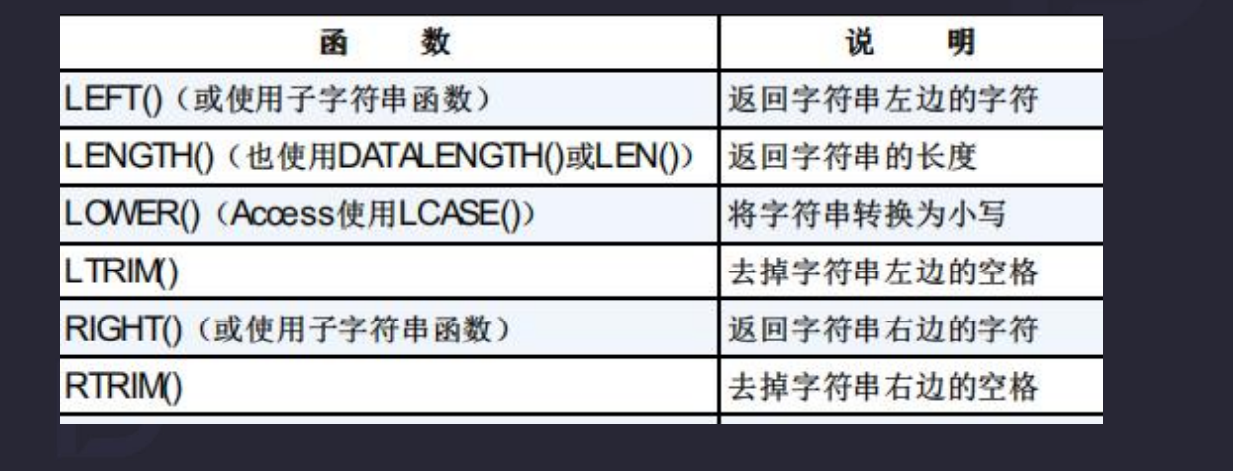
9.2 文本函数
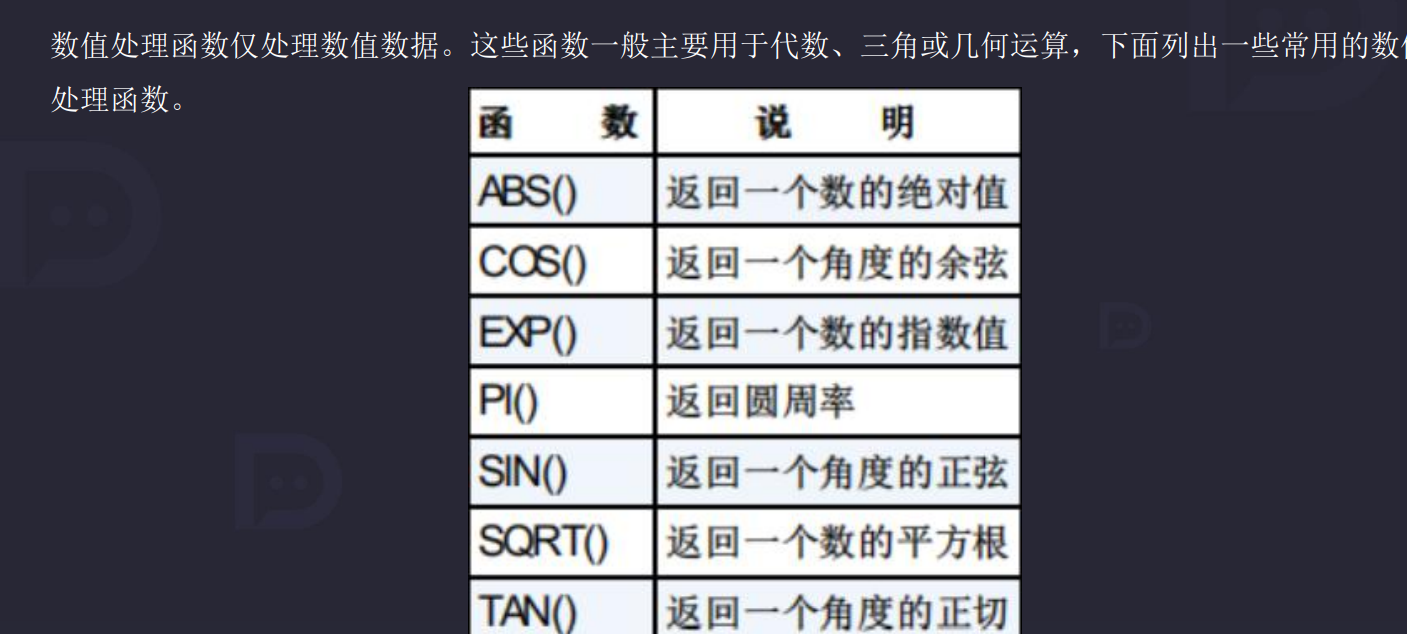
9.3 数值处理函数
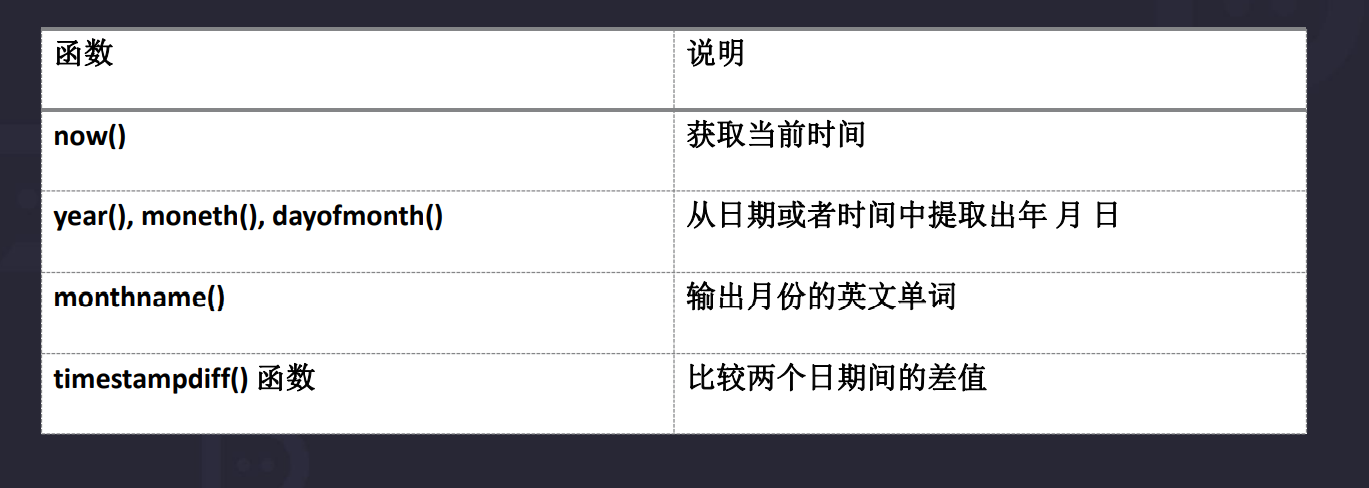
9.4 日期时间函数
select now();
select curdate(),curtime();
select year(now()),year('2020-06-06');
select dayofmonth(now()),dayofyear(now());
select monthname(now());
select timestampdiff(hour ,'2003-2-1',now()); -- 计算两个日期时间差,可以是年月日时分秒
# 假如给你一个日期,再给你个天数,让你求日期
select date_sub(now(),INTERVAL -200 day ); -- 整数:向历史的时间去数,负数:向未来的时候计算;可以是年月日十分秒
9.5 窗口函数
9.5.1 基本语法
- MySQL从8.0开始支持开窗函数,这个功能在大多商业数据库中早已支持,也 叫分析函数。
- 开窗函数与分组聚合比较像,分组聚合是通过制定字段将数据分成多份,每 一份执行聚合函数,每份数据返回一条结果。
- 开窗函数也是通过指定字段将数据分成多份,也就是多个窗口,对每个窗口 的每一行执行函数,每个窗口返回等行数的结果.
语法: 往往结合COUNT、SUM、MIN、MAX、AVG等聚合函数使用
分析函数的语法为:
函数名 over(partition by 列名1 order by 列名2 ),括号中的两个关键词partition by 和order by 可以只出现一个。

9.5.2 四大排名函数
NTILE

ROE_NUMBER

RANK&DENSE_RANK

9.6 窗口函数练习
# 窗口函数
create database if not exists cookie;
use cookie;
drop table if exists cookie1;
create table cookie1(cookieid varchar(255), createtime date, pv int);
insert into cookie1 (cookieid, createtime, pv) VALUES
('cookie1','2015-04-10',1),
('cookie1','2015-04-11',5),
('cookie1','2015-04-12',7),
('cookie1','2015-04-13',3),
('cookie1','2015-04-14',2),
('cookie1','2015-04-15',4),
('cookie1','2015-04-16',4);
# 基本语法+边界练习
select cookieid,createtime,pv,
sum(pv) over(partition by cookieid order by createtime asc ) as pv1,
sum(pv) over(partition by cookieid order by createtime asc
rows between unbounded preceding and current row ) as pv2,
sum(pv) over(partition by cookieid order by createtime asc
rows between 3 preceding and current row ) as pv3,
sum(pv) over(partition by cookieid order by createtime asc
rows between 1 preceding and 1 following ) as pv4
from cookie1;
# sql四大排名函数
use cookie;
drop table if exists cookie2;
create table cookie2(cookieid varchar(255), createtime date, pv int);
insert into cookie2 (cookieid, createtime, pv) VALUES
('cookie1','2015-04-10',1),
('cookie1','2015-04-11',5),
('cookie1','2015-04-12',7),
('cookie1','2015-04-13',3),
('cookie1','2015-04-14',2),
('cookie1','2015-04-15',4),
('cookie1','2015-04-16',4),
('cookie2','2015-04-10',2),
('cookie2','2015-04-11',3),
('cookie2','2015-04-12',5),
('cookie2','2015-04-13',6),
('cookie2','2015-04-14',3),
('cookie2','2015-04-15',9),
('cookie2','2015-04-16',7);
select cookieid,createtime,pv,
ntile(2) over (partition by cookieid order by createtime asc) as rn1, -- 每组切成2片
ntile(3) over (partition by cookieid order by createtime asc) as rn2
from cookie2;
-- ntile非常强大,比如取出一定比例的数据,如组内的1/2数据
# row_number
select cookieid,createtime,pv,
row_number() over (partition by cookieid order by pv desc ) as rn
from cookie2;
# rank
select cookieid,createtime,pv,
rank() over (partition by cookieid order by pv desc ) as rn1, -- 留空位
dense_rank() over (partition by cookieid order by pv desc ) as rn2 -- 不留空位
from cookie2;
第十章 用户消费情况分析
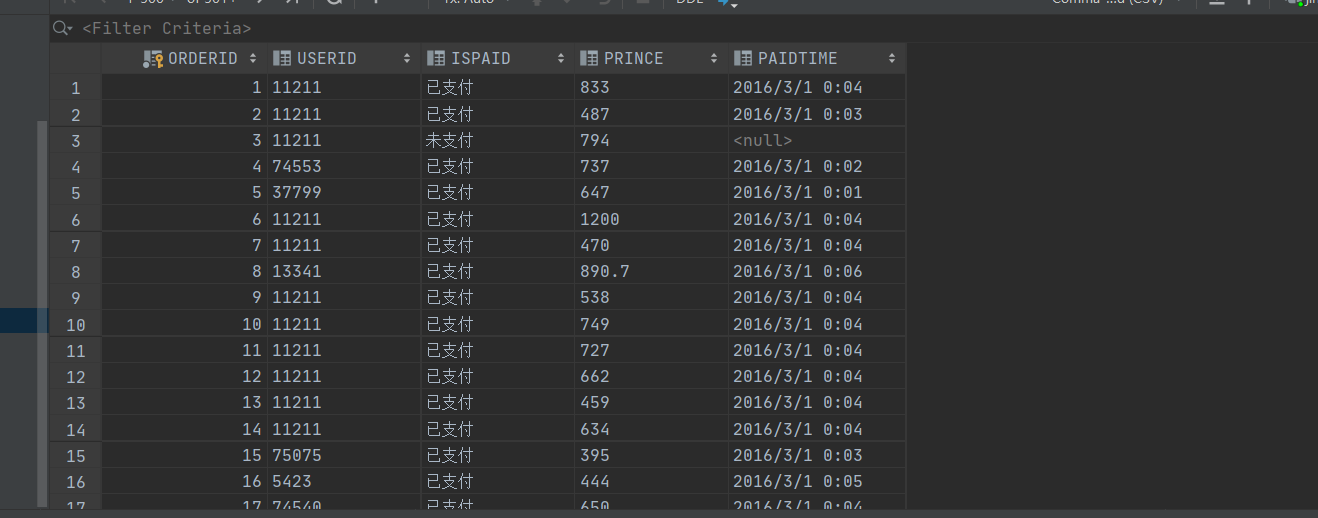
10.1 数据源
1.表【orderinfo】
2.表【userinfo】
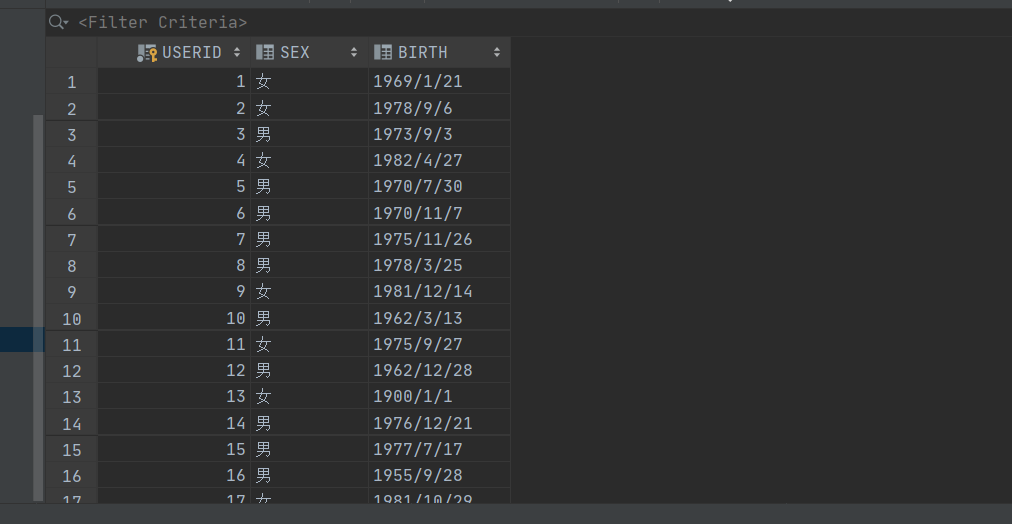
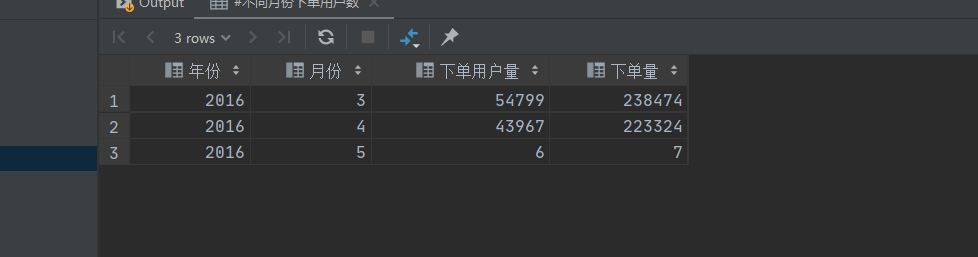
10.2 统计不同月份的下单情况
即统计不同月份的下单USERID和不同月份的下单总量
思路:按年,月将表【orderinfo】进行分组,筛选出‘已支付’用户
最后统计总单量和去重的总用户。
select year(PAIDTIME) as 年份, month(PAIDTIME) as 月份, count(distinct USERID) as 下单用户量, count(1) as 下单量
from orderinfo
where ISPAID = '已支付'
group by year(PAIDTIME), month(PAIDTIME);
查询结果:
10.3 统计3月份(plus:各月份)的复购率
月度复购率:指在本月中一人多次消费的人数占比
思路:将3月份的’已支付‘的用户筛选出来,将USERID分组,判断消费次数是否大于1,对这些用户求和。再除总用户。
select count(t.USERID) as 3月份下单用户数, sum(t.是否复购) as 3月份复购用户数, sum(t.是否复购) / count(t.USERID) as 复购率
from (
select USERID, case when count(USERID) > 1 then 1 else 0 end as 是否复购
from orderinfo
where ISPAID = '已支付'
and month(PAIDTIME) = 3
group by USERID) as t;
查询结果:

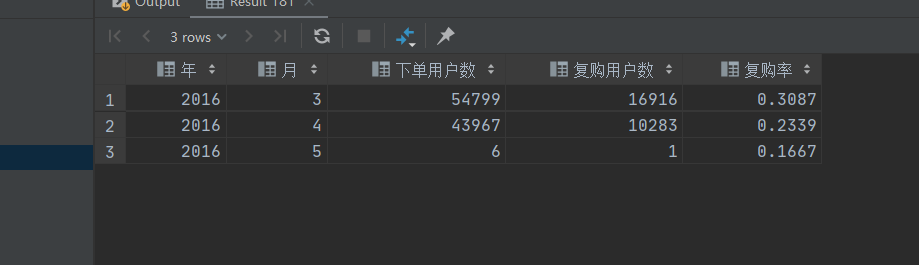
统计各月份的复购率
select year(t.PAIDTIME) as 年,month(t.PAIDTIME) as 月, count(t.USERID) as 下单用户数, sum(t.是否复购) as 复购用户数, sum(t.是否复购) / count(t.USERID) as 复购率
from (
select USERID, PAIDTIME , case when count(USERID) > 1 then 1 else 0 end as 是否复购
from orderinfo
where ISPAID = '已支付'
group by USERID, year(PAIDTIME), month(PAIDTIME)) as t
group by year(t.PAIDTIME),month(t.PAIDTIME);
查询结果:
10.4 各个月份的回购率
各月份的回购率,即求连续两个月的用户是否购买
思路:将已支付的用筛选出来,按照USRID和月份分组,最后把相同USEID的客户且月份相差一个月的客户连接。
select year(a_time) as 年,
month(a_time) as 月,
count(t.a_uid) as 总的消费用户数量,
count(t.b_uid) as 回购用户数量
from (
select a.USERID as a_uid, a.PAIDTIME as a_time, b.USERID as b_uid
from (select USERID, PAIDTIME
from orderinfo
where ISPAID = '已支付'
group by USERID, month(PAIDTIME)) a
left join
(select USERID, PAIDTIME
from orderinfo
where ISPAID = '已支付'
group by USERID, month(PAIDTIME)) b
on a.USERID = b.USERID and month(a.PAIDTIME) = month(b.PAIDTIME) + 1
) as t
group by year(a_time), month(a_time);
验证数据正确性
# 获取5月份消费用户数
select distinct USERID
from orderinfo
where month(PAIDTIME) = 4
and USERID in (
select distinct USERID
from orderinfo
where month(PAIDTIME) = 5 -- 发现有6个用户下单
);
10.5 统计男女的消费频次差异
将【orderinfo】表性别不为空的筛选出来,将其与【userinfo】表连接。
统计总的同一ID的消费次数,,将其总和除以USEID总人数。(男女分组)
select t.sex, sum(t.次数), count(t.SEX), avg(t.次数)
from (select a.USERID, SEX, count(1) as 次数
from orderinfo as a
join
(SELECT USERID, SEX
FROM userinfo
WHERE SEX <> ''
group by USERID) as b
on a.USERID = b.USERID
group by USERID) t
group by t.sex;
10.6 统计多次消费的用户消费时间差
统计多次消费的用户,第一次和最后一次消费时间
select USERID, max(PAIDTIME), min(PAIDTIME), timestampdiff(day, min(PAIDTIME), max(PAIDTIME)) as 消费时间差
from orderinfo
where ISPAID = '已支付'
group by USERID
having count(1) > 1;
10.7 统计不同年龄段的用户消费金额差异
将各已支付用户的年龄算出来
用case语句进行分组
select cast(sum(PRINCE) as decimal(12, 2)) as 总金额,
case
when age between 10 and 19 then '10-19岁'
when age between 20 and 29 then '20-29岁'
when age between 30 and 39 then '30-39岁'
when age between 40 and 49 then '40-49岁'
when age between 50 and 59 then '50-59岁'
when age between 60 and 69 then '60-69岁'
when age between 70 and 79 then '70-79岁'
else null
end as age_group
from (select * from orderinfo where ISPAID = '已支付') a -- 已支付
join
(select USERID, year(now()) - year(BIRTH) as age from userinfo where BIRTH is not null) b -- 生日不为空的人的年龄
on a.USERID = b.USERID
group by age_group
order by age_group asc;
10.8 -统计消费的二八法则
-统计消费的二八法则,消费的top20%用户,贡献了多少额度
选出各个ID的消费金额 取20%求和
select sum(sum_price)
from (select *, row_number() over (order by sum_price desc) as 排序
from (select USERID, sum(cast(PRINCE as double)) as sum_price
from orderinfo
where ISPAID = '已支付'
group by USERID) aa) tt
where tt.排序 < (select count(distinct USERID) * 0.2 from orderinfo where ISPAID = '已支付');
-- 已支付用户总量的20%的人数
select count(distinct USERID) * 0.2
from orderinfo
where ISPAID = '已支付';
een 60 and 69 then ‘60-69岁’
when age between 70 and 79 then ‘70-79岁’
else null
end as age_group
from (select * from orderinfo where ISPAID = ‘已支付’) a – 已支付
join
(select USERID, year(now()) - year(BIRTH) as age from userinfo where BIRTH is not null) b – 生日不为空的人的年龄
on a.USERID = b.USERID
group by age_group
order by age_group asc;
## 10.8 -统计消费的二八法则
-统计消费的二八法则,消费的top20%用户,贡献了多少额度
选出各个ID的消费金额 取20%求和
```mysql
select sum(sum_price)
from (select *, row_number() over (order by sum_price desc) as 排序
from (select USERID, sum(cast(PRINCE as double)) as sum_price
from orderinfo
where ISPAID = '已支付'
group by USERID) aa) tt
where tt.排序 < (select count(distinct USERID) * 0.2 from orderinfo where ISPAID = '已支付');
-- 已支付用户总量的20%的人数
select count(distinct USERID) * 0.2
from orderinfo
where ISPAID = '已支付';
