Kubernetes Service
基本概念
当应用由单体架构转向微服务架构时,应用被拆成很多小的互相协作的微服务,每个服务会以多个副本运行,副本数量会随着系统所需的处理能力进行变化,这就是微服务的伸缩性。 微服务的负载均衡器对实现伸缩性起了十分重要的作用。
Service是Kubernetes最重要的资源对象。Kubernetes中的Service对象可以对应微服务架构中的微服务。Service定义了服务的访问入口,服务的调用者Pod通过这个地址访问Service后端的Pod副本实例。 Service通过Label Selector同后端的Pod副本建立关系,Replication Controller保证后端Pod副本的数量,也就是保证服务的伸缩性。
service代理模式
我们知道,kubernetes的node节点运行的时候,需要启动两个进程,分别是kubelet和kube-proxy。其中kubeproxy实际上就是一个智能的负载均衡器。发送到service的请求由kube-proxy转发到后端在的某个pod实例上。
kubernetes为每个service分配一个全局唯一的虚拟IP,叫做ClusterIP,这样在整个集群中,服务的调用者都通过ClusterIP和服务进行通信。
在Service的整个生命周期内Service的名称和ClusterIP保持不变,因此通过引入域名服务将Service的名称和ClusterIP建立DNS域名映射,服务的调用者可以通过使用服务的名称来访问服务。
kube-proxy作为一个集群内部的负载均衡器,支持多种代理模式:
- userspace代理模式
- iptables代理模式
- ipvs代理模式
userspace代理模式
这是kubernetes 1.1版本之前支持的模式,当前基本已弃用。

这种模式下,kube-proxy会watch kube-apiserver对Service对象和Endpoints对象的添加和移除。 并在所有node上为每一个service打开一个本地的随机端口。然后在每个node上配置iptables规则来捕获到达service的请求,并将其重定向至本地为该service打开的随机端口,完成代理访问。
iptables代理模式
这是当前kubernetes默认使用的service的代理模式。
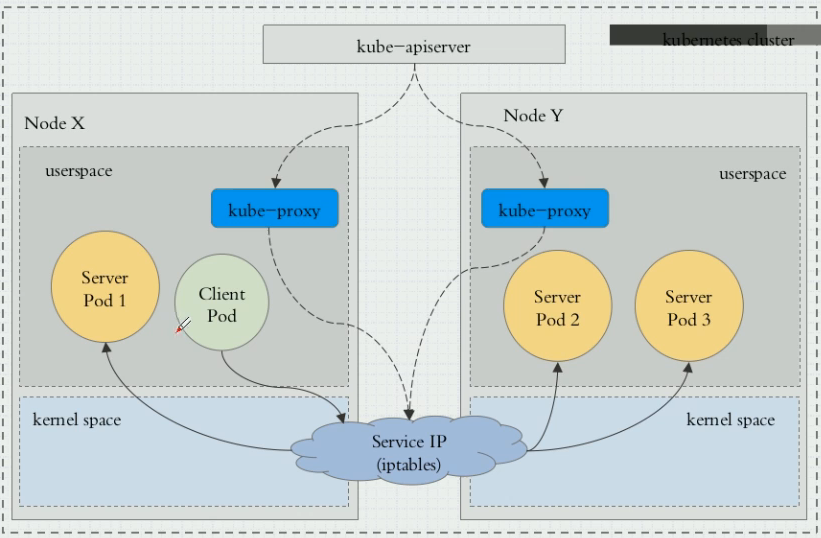
和userspace模式一样,其也使用iptables规则来捕获对cluster ip的访问,但是它会通过iptables的dnat规划直接请请求转发至具体的backend pod,而不需要在node为每个service打开一个本地随机端口。相对于userspace,其拥有更好的转发性能,同时如果初始转发的pod失败没有响应,Iptables代理能够自动的重试另一个pod。
ipvs代理模式
ipvs模式在kubernetes 1.8版本开始引入,1.11版本正式GA。不过要启用该模式,仍然需要修改kube-proxy配置。
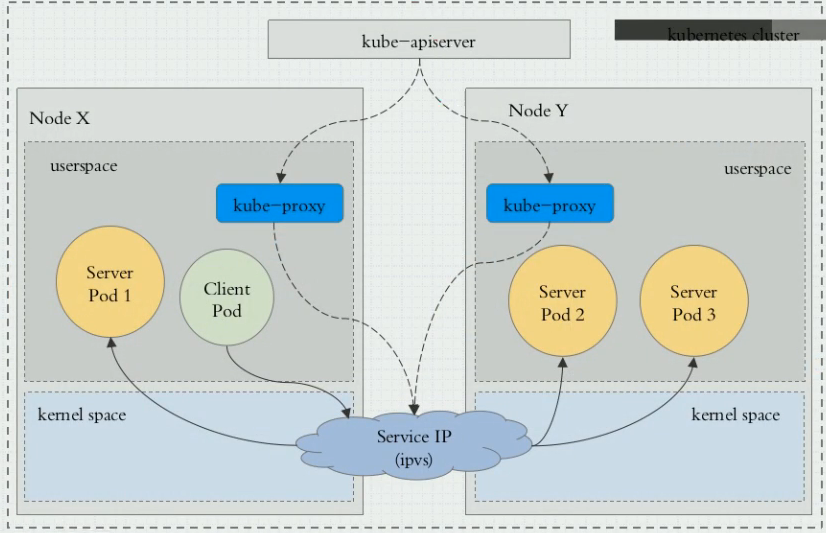
这种模式通过ipvs实现转输层的负载均衡。相对于iptables代理模式,其优势如下:
- 为大型集群提供了更好的可扩展性和性能
- 支持比iptables更复杂的复制均衡算法(最小负载、最少连接、加权等等)
- 支持服务器健康检查和连接重试等功能
ipvs也依赖iptables,ipvs会使用iptables进行包过滤、SNAT、masquared(伪装)。
配置Service
kubrenetes支持四种类型的service,可以通过ServicesTypes指定:
- ClusterIP:仅仅使用一个集群内部的地址,这也是默认值,使用该类型,意味着,service只能在集群内部被访问
- NodePort:在集群内部的每个节点上,都开放这个服务。可以在任意的
:NodePort地址上访问到这个服务 - LoadBalancer:这是当kubernetes部署到公有云上时才会使用到的选项,是向云提供商申请一个负载均衡器,将流量转发到已经以NodePort形式开放的service上。
- ExternalName:ExternalName实际上是将service导向一个外部的服务,这个外部的服务有自己的域名,只是在kubernetes内部为其创建一个内部域名,并cname至这个外部的域名。
下面示例创建一个nginx的deployment,包含三个pod,后面所有创建的service都会与之关联:
创建一个nginx的Deployment:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort:80
可以通过如下指令查看创建的pod:
kubectl get pod -l app=nginx -o wide
创建ClusterIP类型的Service
普通ClusterIP类型的Service
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
ports:
- port: 80
targetPort: 80
selector:
app: nginx
需要说明下三个端口的意义,其中port表示service监听的端口,targetPort表示后端Pod监听的端口,nodePort表示如果要将service暴露出来,外部访问的端口。不指定ClusterIP,则默认使用ClusterIP方式创建Service,并自动生成一个ClusterIP。可以通过查看service来看到ClusterIP。
查看service:
kubectl get svc nginx
指定ClusterIP的Service
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
clusterIP: 10.254.0.100
ports:
- port: 80
targetPort: 80
selector:
app: nginx
默认情况下,ClusterIP的值是由k8s自动创建的,我们可以通过ClusterIP指定,在创建k8s中的dns的时候会用到。
headless service
创建一个headless service,即指定ClusterIP为None,这个时候,创建的Service没有IP地址。
我们知道,在默认情况下创建的service,k8s会自动为其生成一个ip地址,并在dns中生成一条域名记录指向该ip,当外部有请求到达时,由kubeproxy组件接受请求并转发到后端的pods。而当ClusterIP为None时,k8s并不会为service生成一个IP,但是仍然会往dns里生成一条域名记录,而这个域名的值会直接指向service所关联的pods的IP地址,有多个pods,就会生成多条A记录。这样的好处是,当有请求到达时,会直接请求到指定的pods,而无需再通过kubeproxy转发,从而提高了响应效率。缺点是负载均衡依赖于dns轮循,没有更灵活的均衡方案。
示例:
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
clusterIP: None
ports:
- port: 80
targetPort: 80
selector:
app: nginx
创建NodePort类型的service
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
type: NodePort
ports:
- port: 80
targetPort: 80
nodePort: 80
selector:
app: nginx
创建ExternalName类型的service
下面直接给个示例:
kind: Service
apiVersion: v1
metadata:
name: database
spec:
type: ExternalName
externalName: database.example.com
创建一个service名为database,指向一个外部的服务,这个服务的域名为database.example.com。我们在集群内部访问database.default.svc可直接跳转至database.example.com。实际就是个dns别名。
扩展service
sessionAffinity
主要是用于基于userspace(当前基本已废弃)和iptables转发模式下的pod调度算法,默认为none,此时的调度算法为轮询, 可通过将设置为ClientIP以实现基于客户端ip的亲和性调度,但也会导致负载不均。
apiVersion: v1
kind: Service
metadata:
name: nginx-app
labels:
app: nginx-app
tier: nginx-app
spec:
ports:
- port: 80
targetPort: 80
selector:
app: nginx-app
tier: nginx-app
type: LoadBalancer
sessionAffinity: ClientIP
externalTrafficPolicy
默认情况下,目标容器看到的源Ip不是客户端的源ip,如果要保留客户端的源ip,可以配置externalTrafficPolicy选项如下:
- service.spec.externalTrafficPolicy - 如果这个服务需要将外部流量路由到 本地节点或者集群级别的端点,那么需要指明该参数。存在两种选项:Cluster(默认)和 Local。 Cluster隐藏源 IP 地址,可能会导致第二跳(second hop)到其他节点,但是全局负载效果较好。Local保留客户端源 IP 地址,避免 LoadBalancer 和 NodePort 类型服务的第二跳,但是可能会导致负载不平衡。
- service.spec.healthCheckNodePort - 定义服务的 healthCheckNodePort (数字端口号)。 如果没有声明,服务 API 后端会用分配的 nodePort 创建 healthCheckNodePort。如果客户端 指定了 nodePort,则会使用用户自定义值。这只有当类型被设置成 LoadBalancer并且 externalTrafficPolicy被设置成 Local时,才会生效。
ExternalIP
kind: Service
apiVersion: v1
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- name: http
protocol: TCP
port: 80
targetPort: 9376
externalIPs:
- 80.11.12.10
当从集群外部请求80.11.12.10这个Ip时,如果集群收到该请求,就会将流量转发至my-service这个service。但这里有个前提, 即80.11.12.10这个Ip的流量能正确的路由到这个service上来,而这部分路由的功能kubernetes并不保证,需要集群管理人员自行做路由处理。
一般来讲,externalIPs通常会与loadbalancer类型的service配合使用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号