

浅谈count(1),count(*)和count(column_name)
最近看到群里有位仁兄,问到关于count(column_name)和count(*),还有count(1)效率和不同点的问题,我记得,在很久之前提到过关于这块的问题,很多人对怎么用这三个统计都模糊不清的,所以,今天抽个空,自己做个实验,测试测试这种情况,我测试的思路是从执行效率上和输出的数据量这两方面。
如果有不到之处,还敬请拍砖!!
--建立测试环境 create table test_a ( a int ) declare @max int ,@rc int set @max =10000000 set @rc =1
while @rc<=@max begin insert into test_a select @max set @rc=@rc+1 end --数据量太大,插的时候太慢了,所以只插了8034568条数据,大约半小时,嘻嘻
--没有NULL值得情况下,有NULL值得情况我会在后面再讨论,现在情况为表为单列的且没有索引的情况 declare @time_first datetime declare @time_end datetime declare @sql varchar(20) select @time_first = GETDATE() select COUNT(1) from test_a select @time_end=GETDATE() --print @time_first set @sql= DATEDIFF(MILLISECOND,@time_first,@time_end) print @sql set @time_first =GETDATE() select COUNT(a) from test_a set @time_end=GETDATE() set @sql= DATEDIFF(MILLISECOND,@time_first,@time_end) print @sql set @time_first =GETDATE() select COUNT(*) from test_a set @time_end=GETDATE() set @sql= DATEDIFF(MILLISECOND,@time_first,@time_end) print @sql /* 在没有索引的情况下,我多次执行,得到如下结果(这边就不一一列举): 第一次: ----------- 8034568 (1 行受影响) 366 ----------- 8034568 (1 行受影响) 803 ----------- 8034568 (1 行受影响) 400 第二次: ----------- 8034568 (1 行受影响) 360 ----------- 8034568 (1 行受影响) 820 ----------- 8034568 (1 行受影响) 396 --第三次: ----------- 8034568 (1 行受影响) 386 ----------- 8034568 (1 行受影响) 816 ----------- 8034568 (1 行受影响) 370 */
为了避免偶然性,我再本机上多次执行了,从得出的结果上很容易得出来,count(column_name)从时间上来看的话,是最慢的,count(1)和count(*)时间上是差不多的。
--我们看看他们各自的执行计划,如图一:
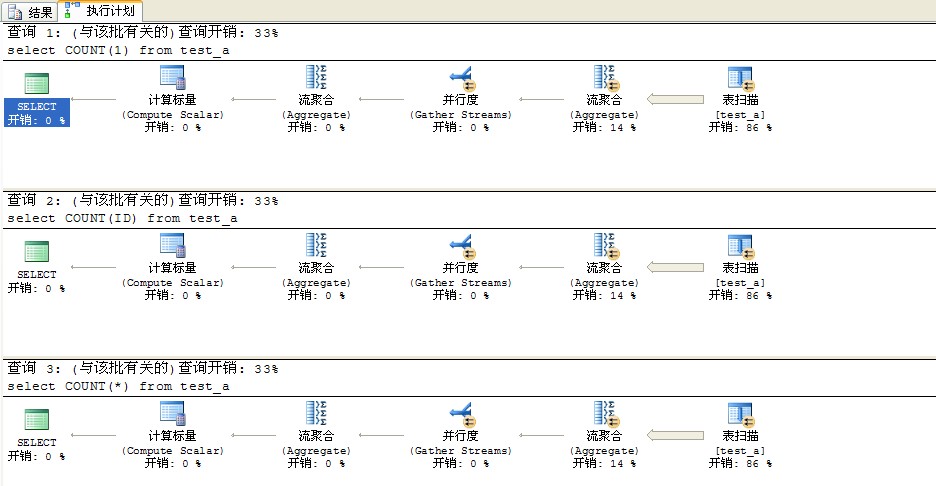
由上面的图片可以看的出来,在没有索引的情况下他们的执行计划是一样的。
我们再来看看磁盘盒CPU的开销情况。
set statistics time on go select COUNT(1) from test_a select COUNT(a) from test_a select COUNT(*) from test_a set statistics time off go /* 表 'test_a'。扫描计数 3,逻辑读取 13572 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 SQL Server 执行时间: CPU 时间 = 688 毫秒,占用时间 = 344 毫秒。 ----------- 8034568 (1 行受影响) 表 'test_a'。扫描计数 3,逻辑读取 13572 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 SQL Server 执行时间: CPU 时间 = 1562 毫秒,占用时间 = 774 毫秒。 ----------- 8034568 (1 行受影响) 表 'test_a'。扫描计数 3,逻辑读取 13572 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 SQL Server 执行时间: CPU 时间 = 688 毫秒,占用时间 = 347 毫秒。 */
从上可以看的出来,在没有索引的情况下,他们的逻辑读取和物理读取是一样的,但在CPU的输入输出上不同,所以,可以得出以下结论,在相同条件下,如果表只有一列,且没有索引的情况下,count(column_name)的开销是最大的,而count(1)和count(*)区别不是很大,这种区别在将近900W的数据量的情况下是可以忽略的。
下面我们讨论讨论如果有索引的情况下是怎么样的。
在原来的环境情况下,增加一个列,和一个索引。
--增加一个标识列 alter table test_a add id int identity(1,1) --建立一个聚集索引 create clustered index index_id on test_a(id)
declare @time_first datetime declare @time_end datetime declare @sql varchar(20) select @time_first = GETDATE() select COUNT(1) from test_a select @time_end=GETDATE() --print @time_first set @sql= DATEDIFF(MILLISECOND,@time_first,@time_end) print N'执行count(1)所花费的时间:'+ @sql set @time_first =GETDATE() select COUNT(ID) from test_a set @time_end=GETDATE() set @sql= DATEDIFF(MILLISECOND,@time_first,@time_end) print N'执行count(ID)所花费的时间(其中ID为索引列):'+@sql set @time_first =GETDATE() select COUNT(ID) from test_a set @time_end=GETDATE() set @sql= DATEDIFF(MILLISECOND,@time_first,@time_end) print N'执行count(a)所花费的时间(其中a为非索引列):'+@sql set @time_first =GETDATE() select COUNT(*) from test_a set @time_end=GETDATE() set @sql= DATEDIFF(MILLISECOND,@time_first,@time_end) print N'执行count(*):'+@sql /* 第一次: ----------- 8034568 (1 行受影响) 执行count(1)所花费的时间:353 ----------- 8034568 (1 行受影响) 执行count(ID)所花费的时间(其中ID为索引列):406 ----------- 8034568 (1 行受影响) 执行count(a)所花费的时间(其中a为非索引列):350 ----------- 8034568 (1 行受影响) 执行count(*)所花费的时间:370 第二次: ----------- 8034568 (1 行受影响) 执行count(1)所花费的时间:376 ----------- 8034568 (1 行受影响) 执行count(ID)所花费的时间(其中ID为索引列):380 ----------- 8034568 (1 行受影响) 执行count(a)所花费的时间(其中a为非索引列):353 ----------- 8034568 (1 行受影响) 执行count(*):360 第三次: ----------- 8034568 (1 行受影响) 执行count(1)所花费的时间:360 ----------- 8034568 (1 行受影响) 执行count(ID)所花费的时间(其中ID为索引列):403 ----------- 8034568 (1 行受影响) 执行count(a)所花费的时间(其中a为非索引列):360 ----------- 8034568 (1 行受影响) 执行count(*):360 */
很奇怪,为什么加了索引之后反而比没有加索引的快呢?我们在来看看他们各自的执行计划。
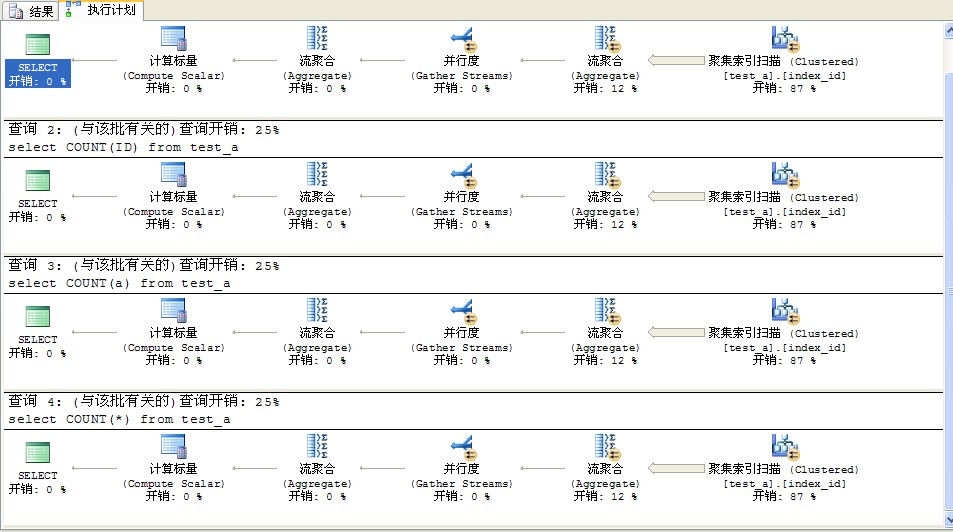
四个的执行计划是一样的,但是与之前的是有区别的,加了索引之后,无论你是否是指定索引列还是非索引列,它都默认的走索引列。
我们再看看磁盘以及CPU的开销情况。
set statistics time on go select COUNT(1) from test_a select COUNT(ID) from test_a select COUNT(a) from test_a select COUNT(*) from test_a set statistics time off go /* SQL Server 分析和编译时间: CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 ----------- 8034568 (1 行受影响) 表 'test_a'。扫描计数 3,逻辑读取 17021 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 SQL Server 执行时间: CPU 时间 = 702 毫秒,占用时间 = 348 毫秒。 ----------- 8034568 (1 行受影响) 表 'test_a'。扫描计数 3,逻辑读取 17021 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 SQL Server 执行时间: CPU 时间 = 720 毫秒,占用时间 = 403 毫秒。 ----------- 8034568 (1 行受影响) 表 'test_a'。扫描计数 3,逻辑读取 17021 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 SQL Server 执行时间: CPU 时间 = 1624 毫秒,占用时间 = 825 毫秒。 ----------- 8034568 (1 行受影响) 表 'test_a'。扫描计数 3,逻辑读取 17021 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 SQL Server 执行时间: CPU 时间 = 782 毫秒,占用时间 = 394 毫秒。 */
从上面的磁盘和CPU的开销来看,如果是多列有索引的情况下,并非count(索引列)最快,反而最慢,当然其中也不含有null统计的情况。
下面我们来讨论,有NULL值得情况下,数据量的问题。
--数据准备,执行如下语句: update test_a set a=null where id %5=0 select count(*) from test_a /* ----------- 8034568 (1 行受影响) */ select COUNT(*) from test_a where A is null /* --为空的数据为 ----------- 1606913 (1 行受影响) */
数据环境出来了,我们来做个统计。
--我们执行以下语句 select COUNT(1) from test_a select COUNT(*) from test_a select COUNT(id) from test_a select COUNT(a) from test_a /* ----------- 8034568 (1 行受影响) ----------- 8034568 (1 行受影响) ----------- 8034568 (1 行受影响) ----------- 6427655 警告: 聚合或其他 SET 操作消除了 Null 值。 (1 行受影响) */
我们不忙分析,请看下面的执行,能更加加固我们对count()的用法的意思。
--我们在原来的基础上执行以下语句,建立环境。 begin tran drop index test_a.index_id-- 删除索引 alter table test_a drop column id --删除列 commit
--我们再次执行上面的查询语句: select COUNT(1) from test_a select COUNT(*) from test_a --select COUNT(id) from test_a select COUNT(a) from test_a /* ----------- 8034568 (1 行受影响) ----------- 8034568 (1 行受影响) ----------- 6427655 警告: 聚合或其他 SET 操作消除了 Null 值。 (1 行受影响) */
到此为止,我们应该清晰的明白了count()的用法了吧。
以上仅一家之言,如有不对的地方请各位指教,若有转载,请注明出处。
posted on 2013-01-25 16:48 breeze_day 阅读(11399) 评论(27) 编辑 收藏 举报

