spark处理嵌套json
json文件数据如下:
{“avg_orders_count”: [{“count”: 1.0, “days”: 3}, {“count”: 0.6, “days”: 5}, {“count”: 0.3, “days”: 10}, {“count”: 0.2, “days”: 15}, {“count”: 0.1, “days”: 30}, {“count”: 0.066, “days”: 45}, {“count”: 0.066, “days”: 60}, {“count”: 0.053, “days”: 75}, {“count”: 0.044, “days”: 90}], “m_hotel_id”: “92500636”}
{“avg_orders_count”: [{“count”: 0.666, “days”: 3}, {“count”: 0.4, “days”: 5}, {“count”: 0.4, “days”: 10}, {“count”: 0.266, “days”: 15}, {“count”: 0.33, “days”: 30}, {“count”: 0.466, “days”: 45}, {“count”: 0.583, “days”: 60}, {“count”: 0.68, “days”: 75}, {“count”: 0.6111, “days”: 90}], “m_hotel_id”: “92409831”}
spark读json文件:
from pyspark.sql import SparkSession, Row, functions
session = SparkSession.builder.appName("sort").getOrCreate()
data = session.read.json('test1')
data.head()
mydata = data.select(explode(data.avg_orders_count), data.m_hotel_id).toDF('my_count', 'id')
mydata.head()
mydata = mydata.select(mydata.id, 'my_count.days', 'my_count.count')
mydata.show()
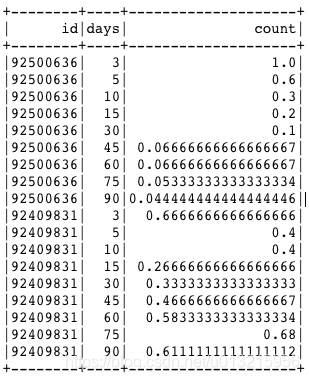
这样就把json展开了,可以做自己想做的操作了~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号