
Spark standalone运行模式

Spark Standalone 部署配置
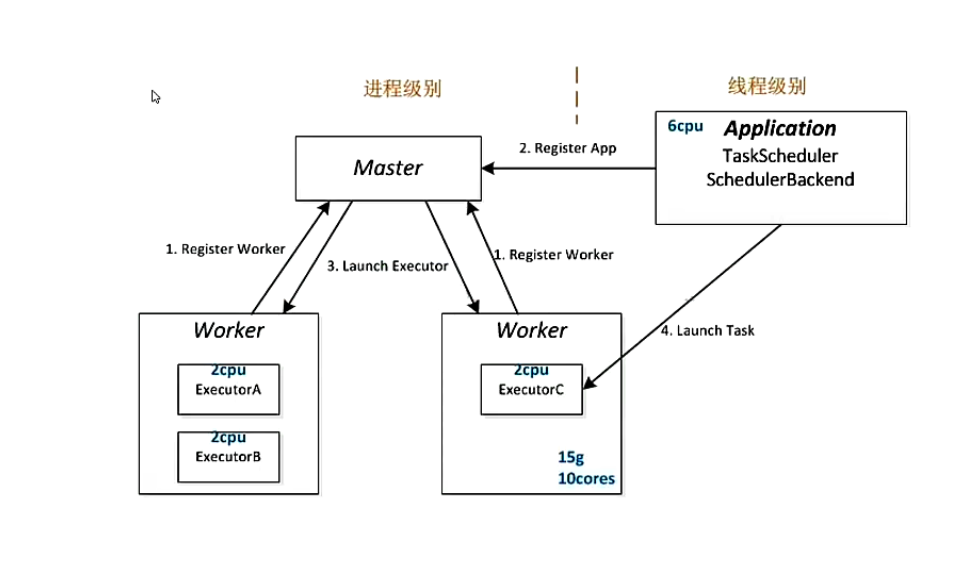
Standalone架构
手工启动一个Spark集群
https://spark.apache.org/docs/latest/spark-standalone.html
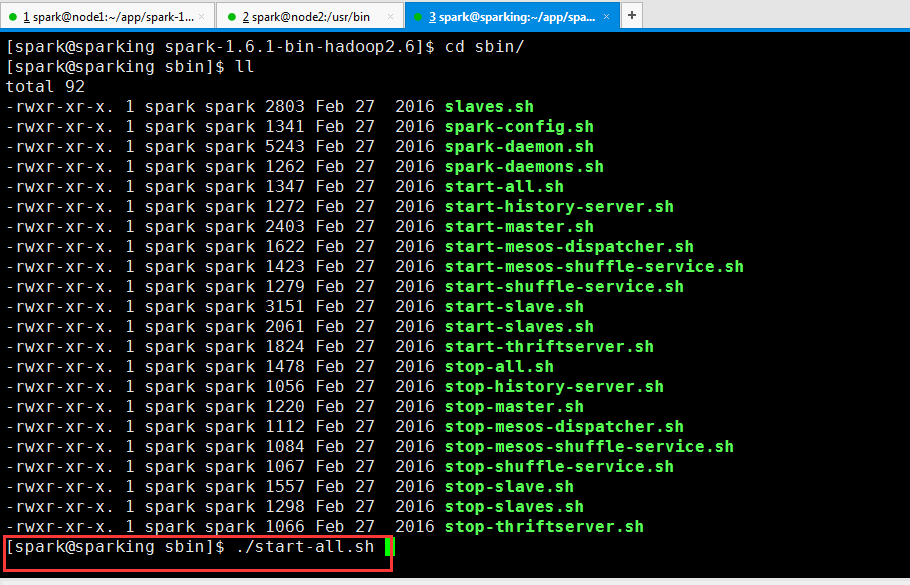
通过脚本启动集群


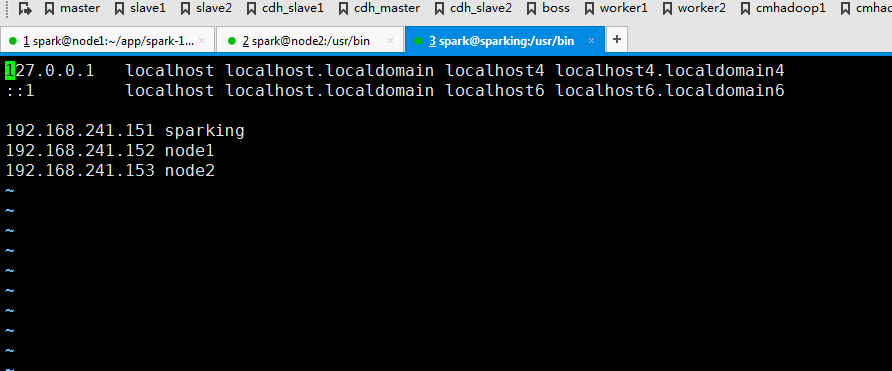
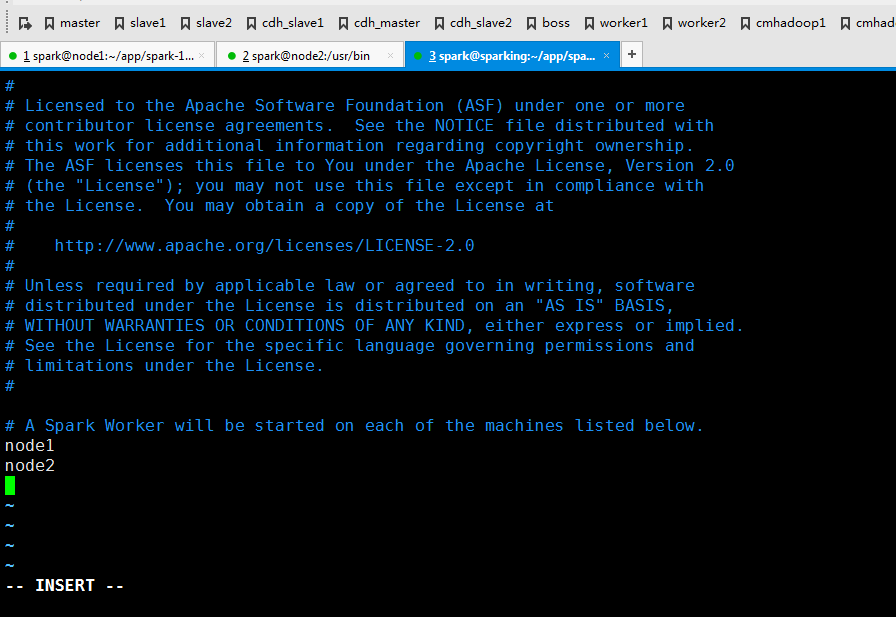
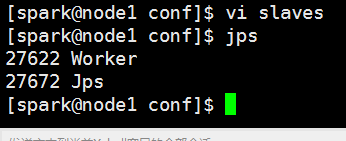
编辑slaves,其实把worker所在节点添加进去

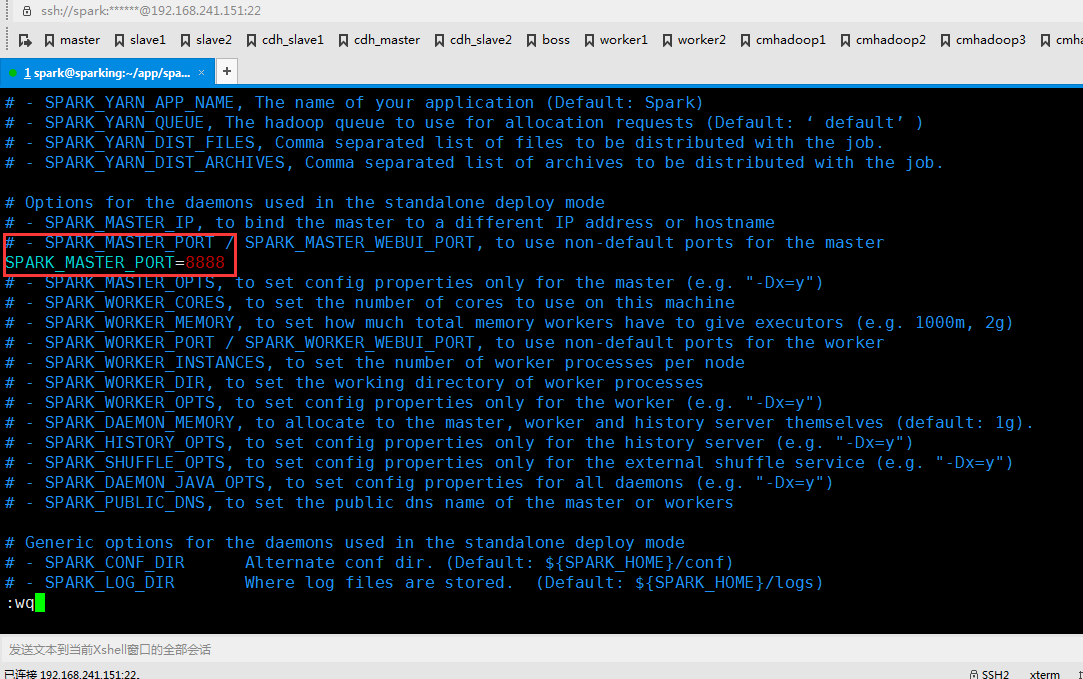
配置spark-defaults.conf


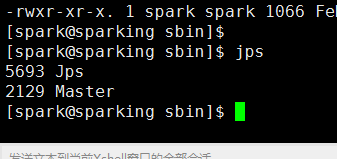
启动集群(我这里是三节点集群)

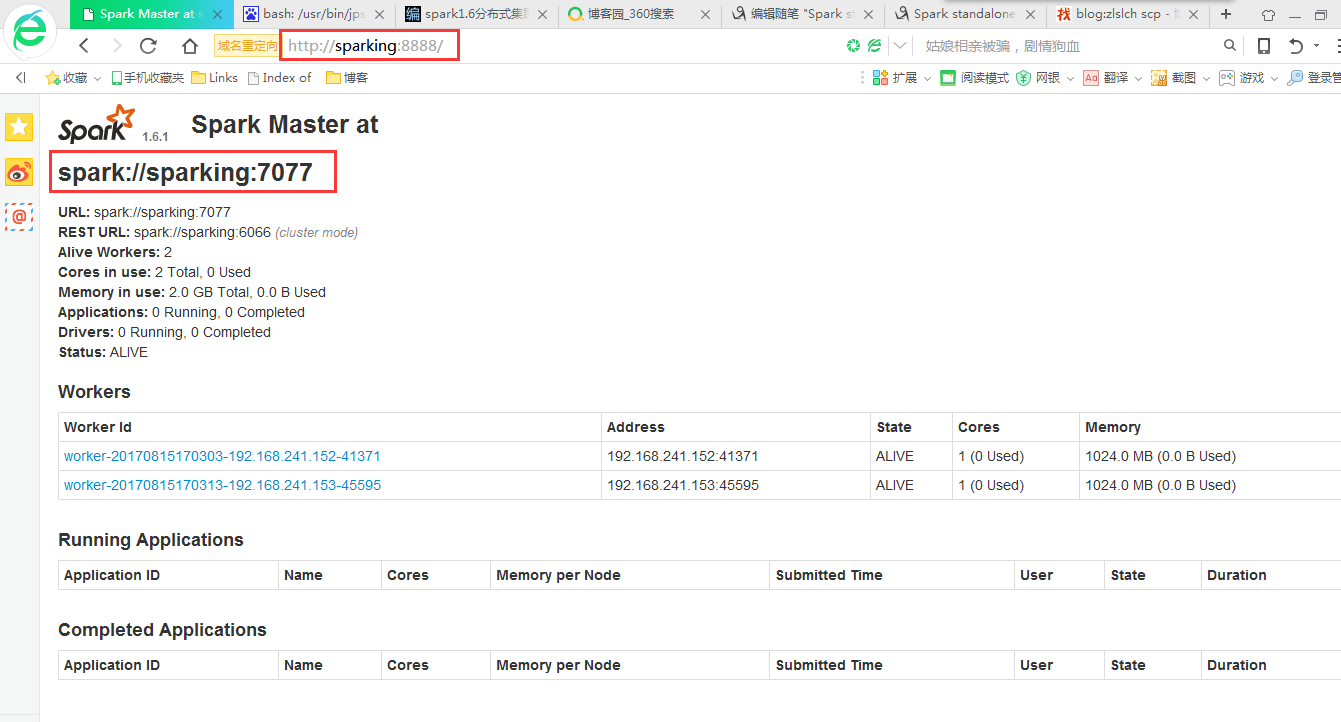
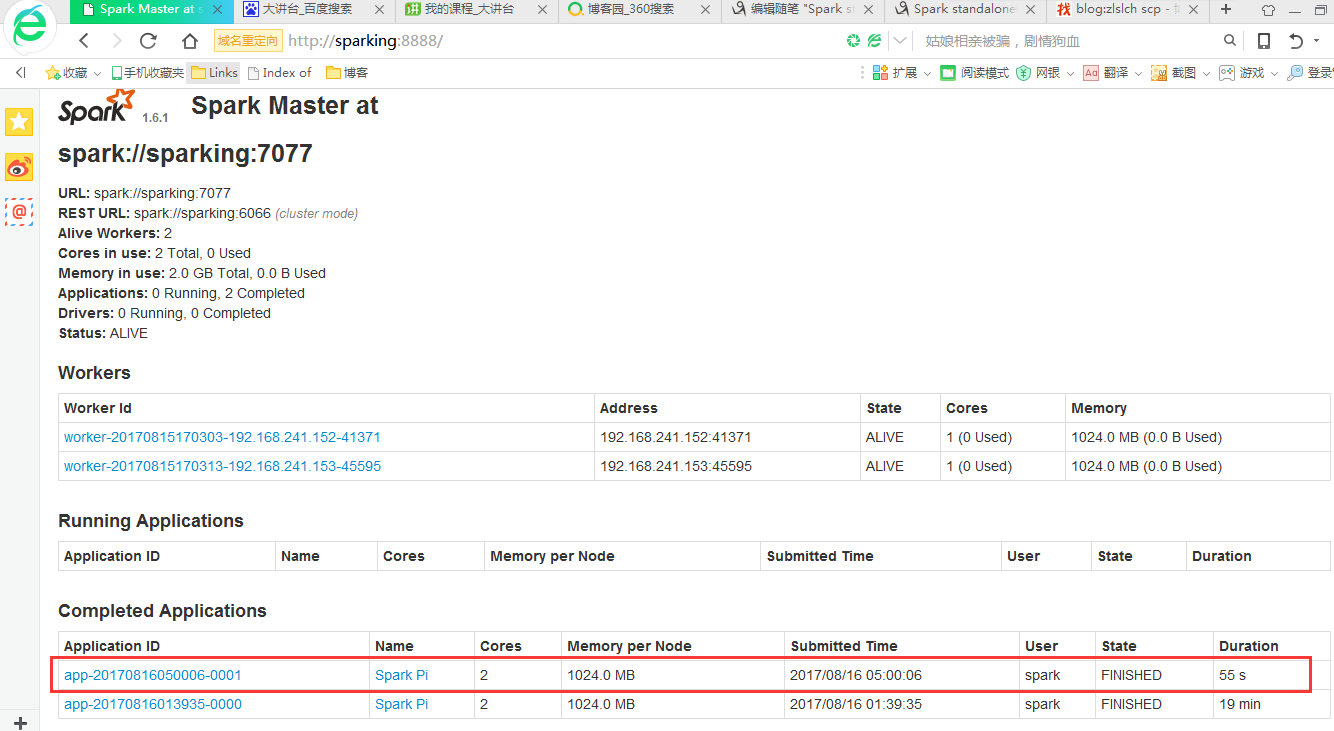
在浏览器打开页面
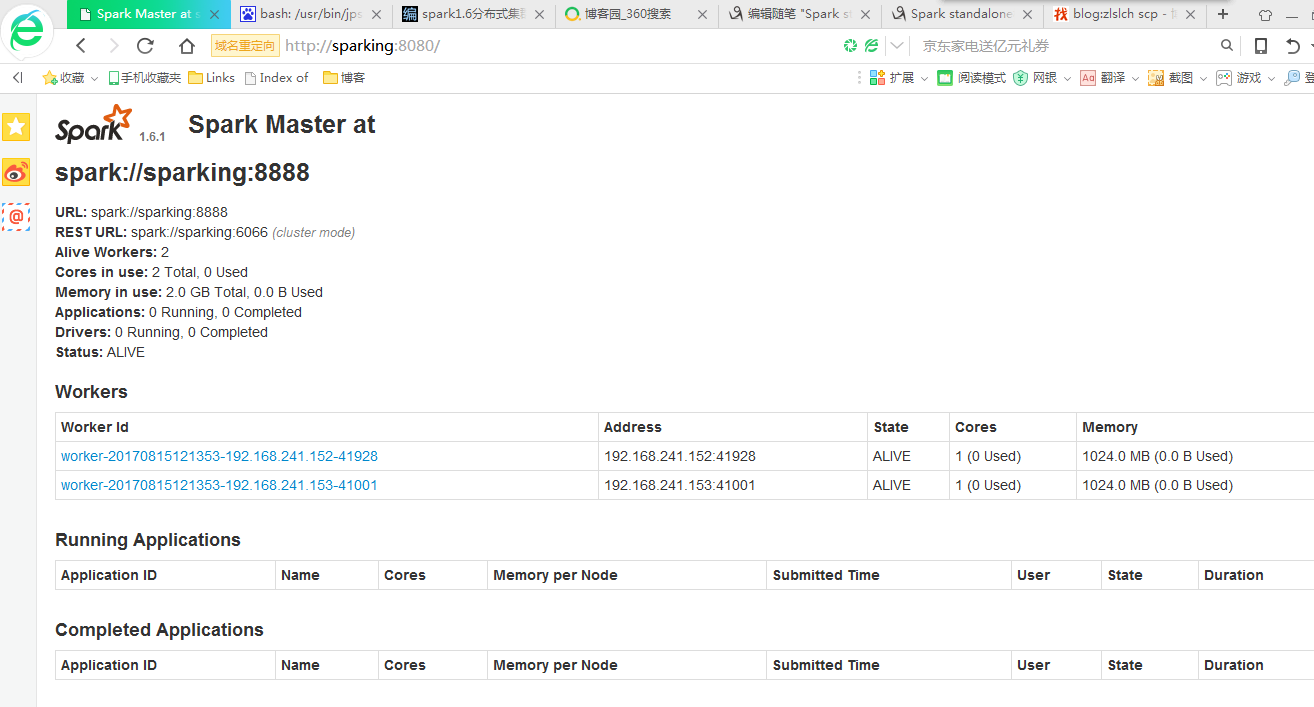
修改 spark-env.sh 文件
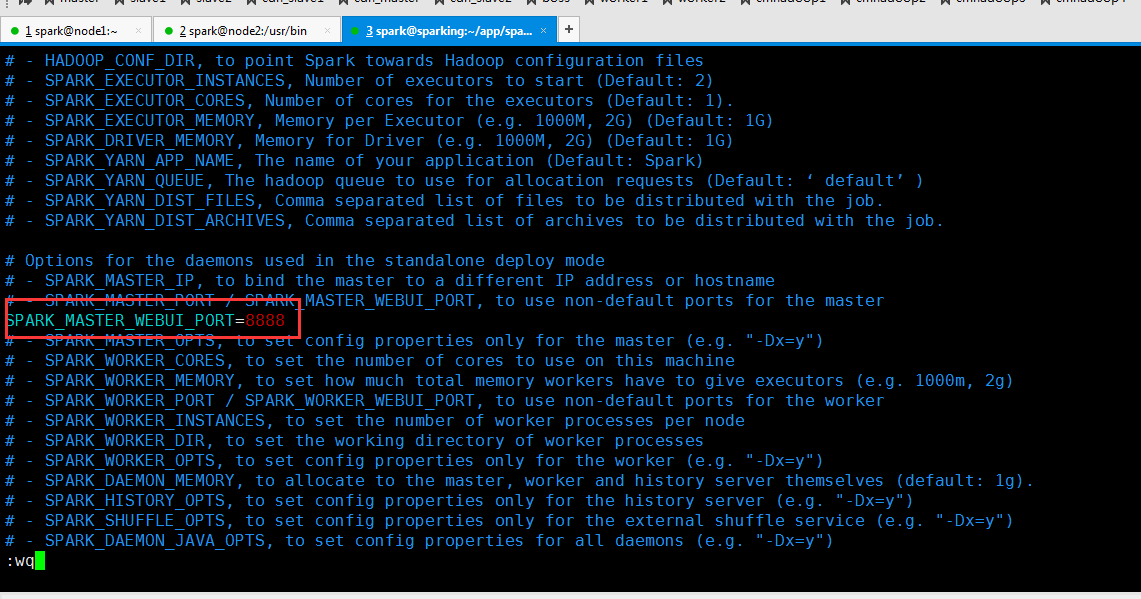
先停止
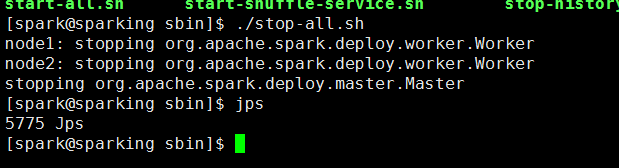
在重新启动一下
再次访问网页
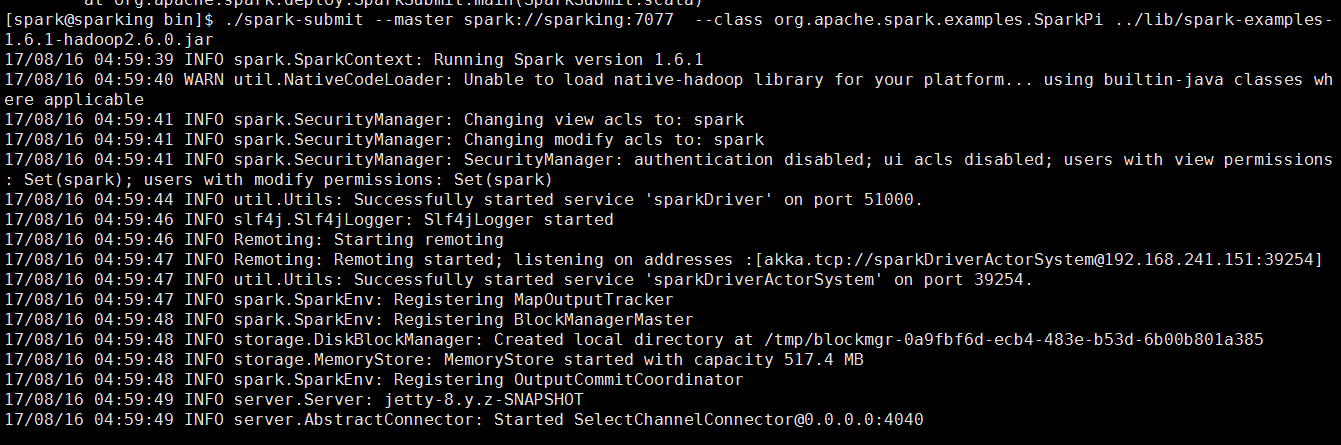
下面跑一个Job实例
./spark-submit --master spark://sparking:7077 --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.1-hadoop2.6.0.jar
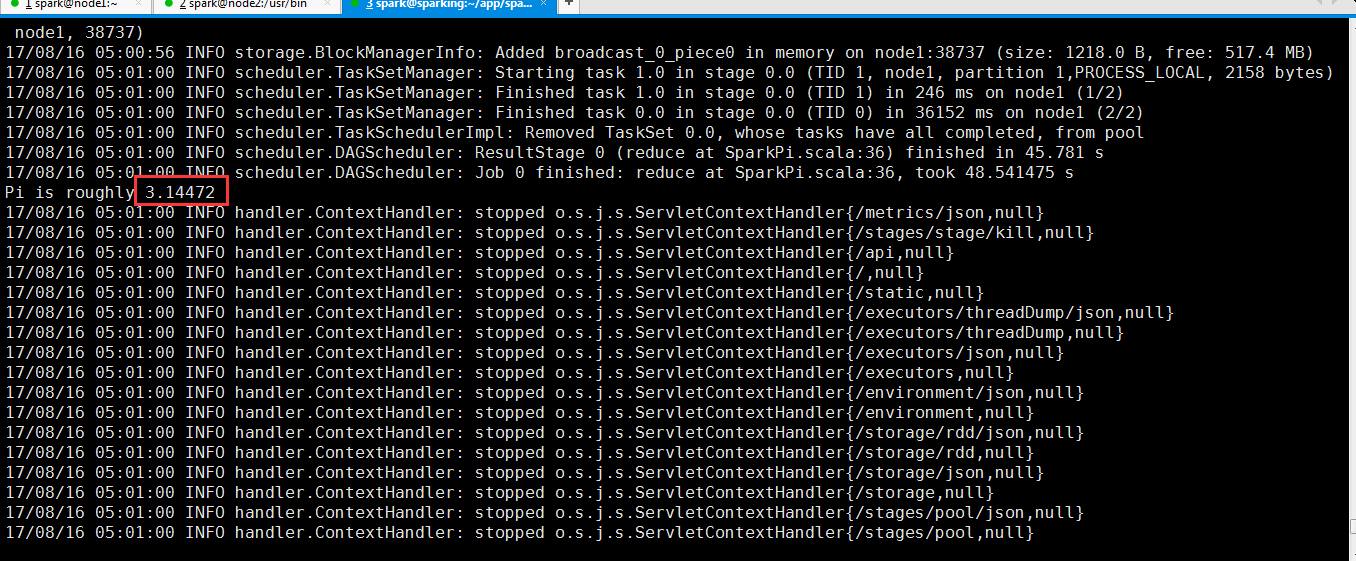
从过程反馈信息可以看出来计算Pi的值
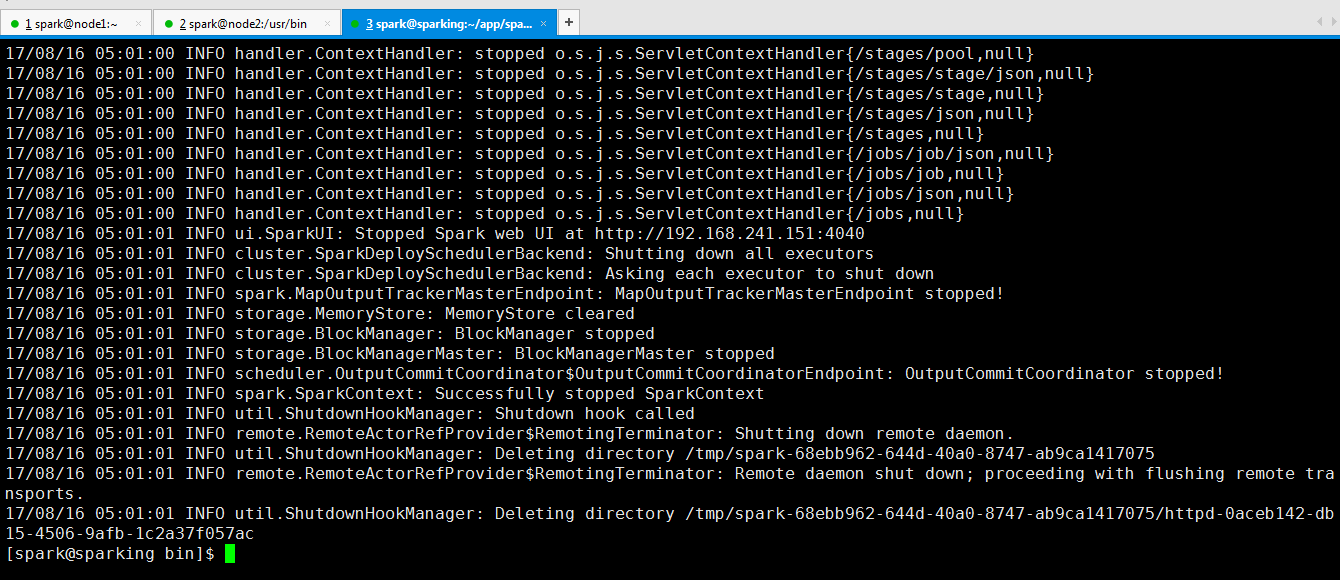
可以看到运行完成了。
从页面也可以看出来
Spark Standalone HA

官方参考地址
https://spark.apache.org/docs/latest/spark-standalone.html#high-availability

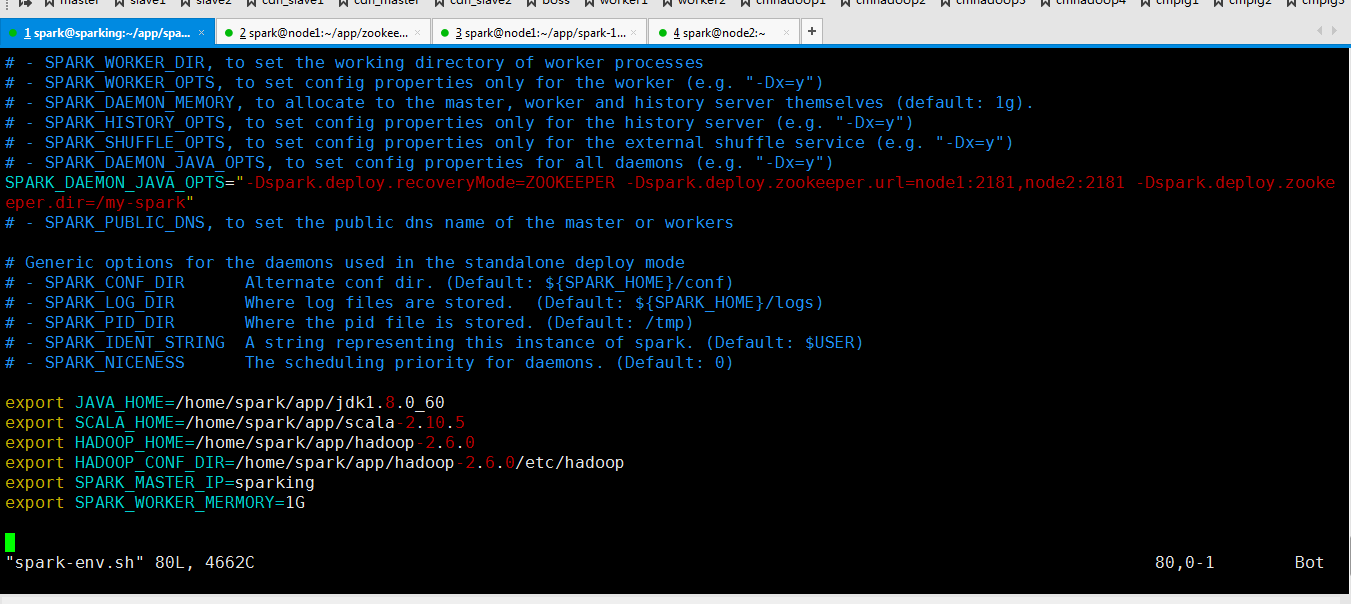
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181 -Dspark.deploy.zookeeper.dir=/my-spark"
默认是这样连接的。
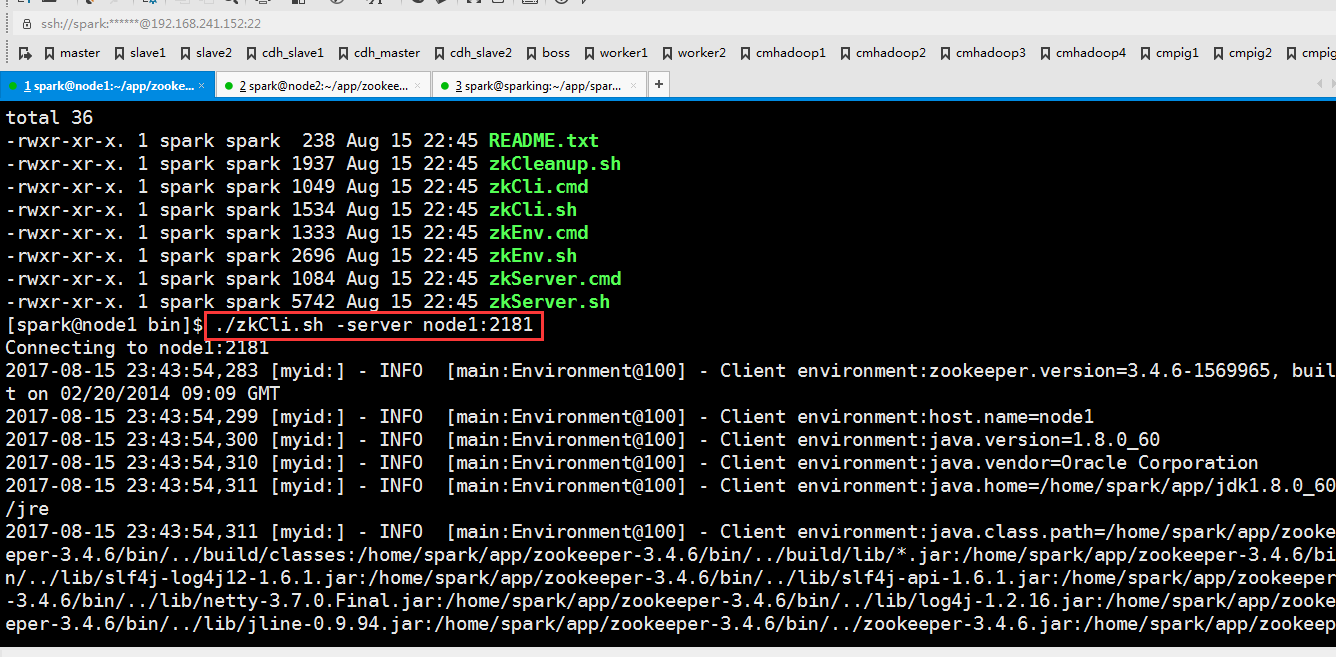
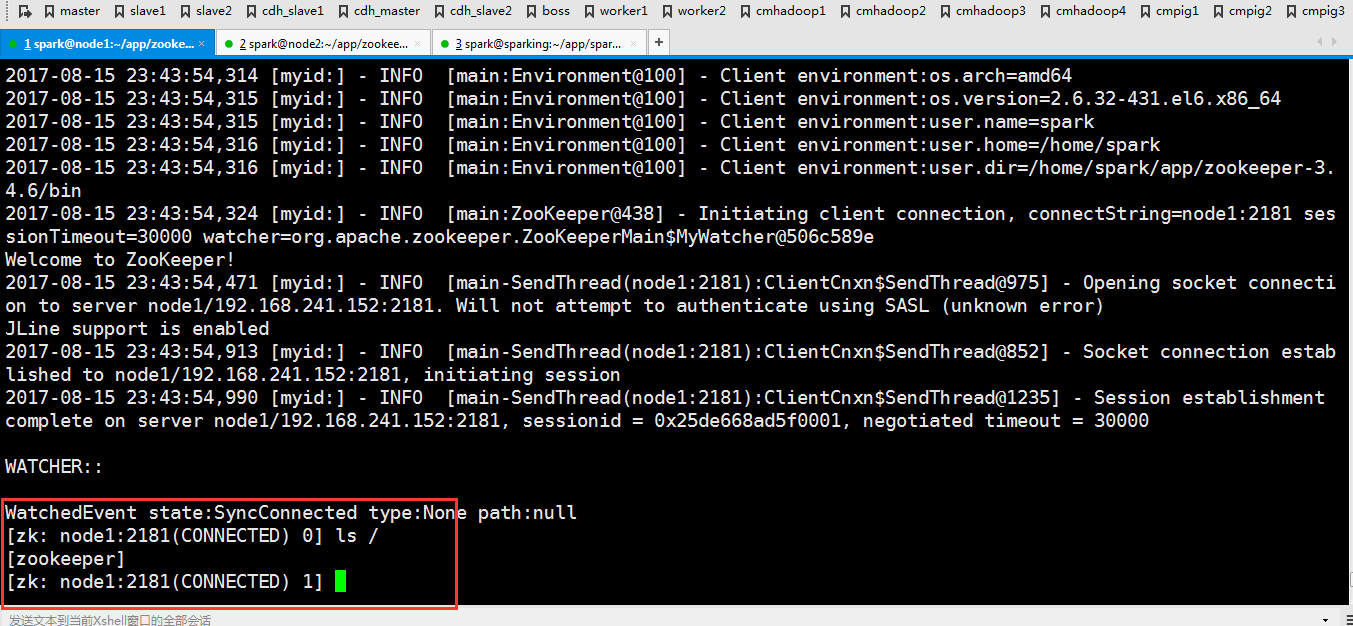
因为刚才修改了文件,现在把修改好的文件分发到另外两个节点去

scp -r spark-env.sh spark@node1:/home/spark/app/spark-1.6.1-bin-hadoop2.6/conf/ scp -r spark-env.sh spark@node2:/home/spark/app/spark-1.6.1-bin-hadoop2.6/conf/
然后重新启动一下
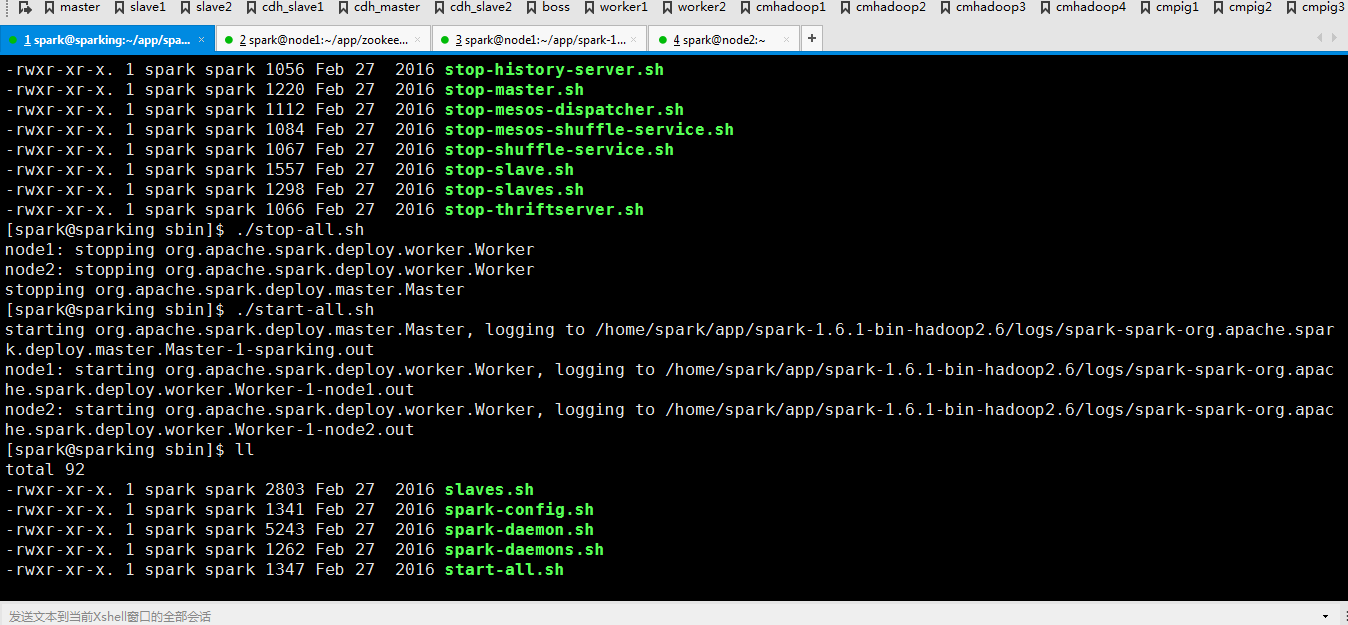
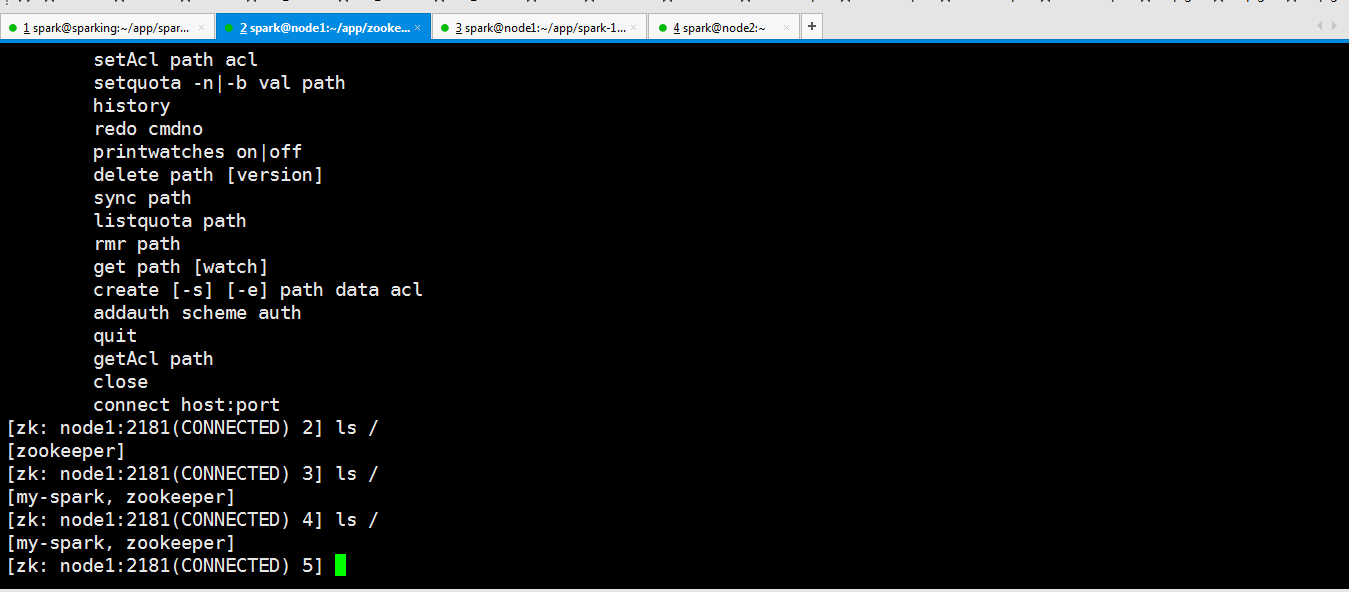
可以看到起来了
Spark Standalone 运行架构解析
Spark基本工作流程
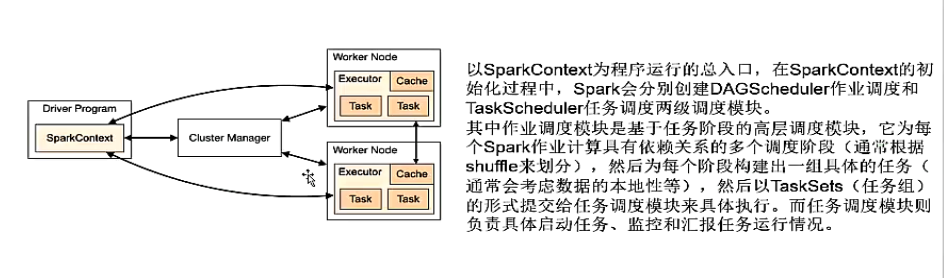
Spark Local模式

Spark Local cluster 模式

Spark standalone 模式

Spark standalone 详细过程解析
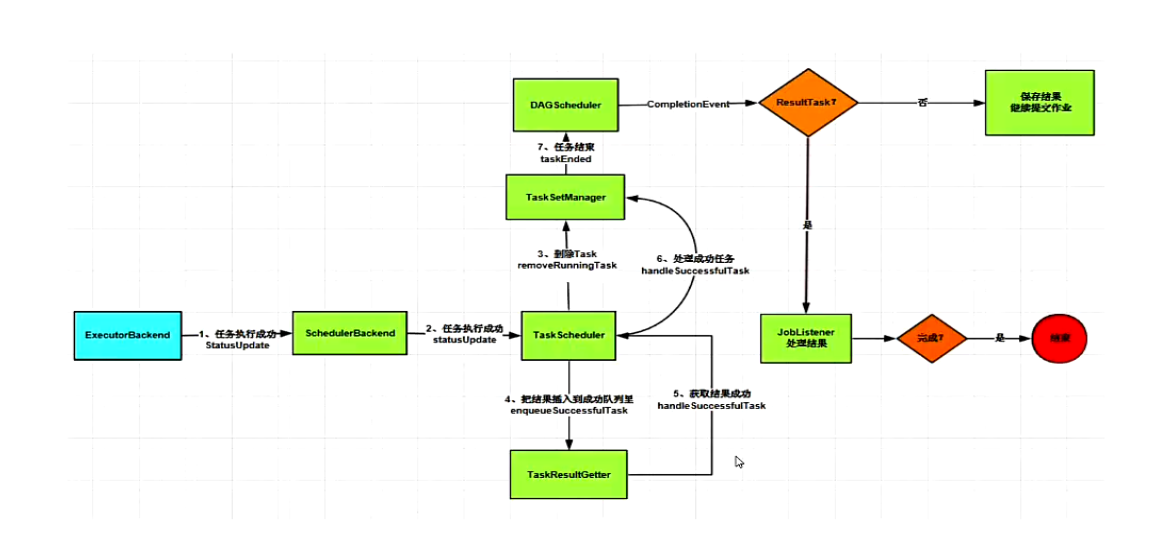
Spark standalone 模式下运行WordCount
在IDEA里把写好的wordcount程序打包(我这里用的是scala版本写的)
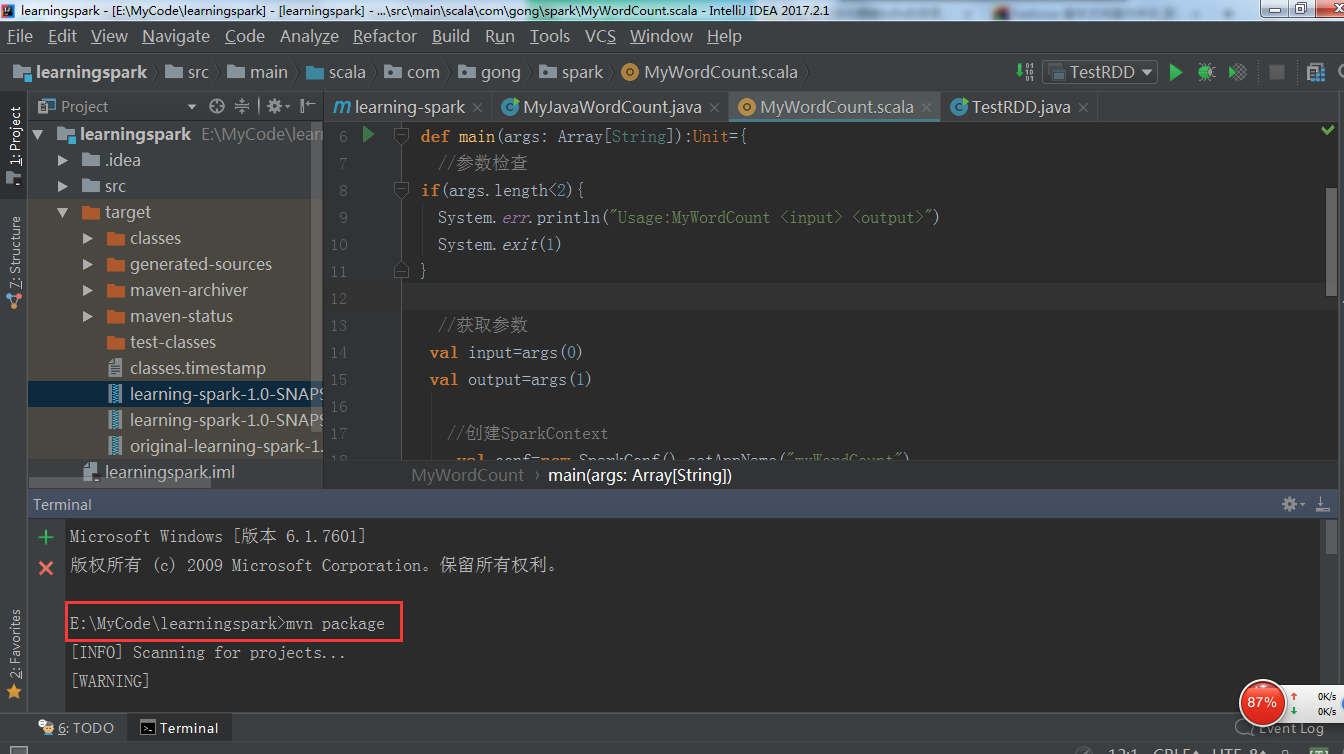
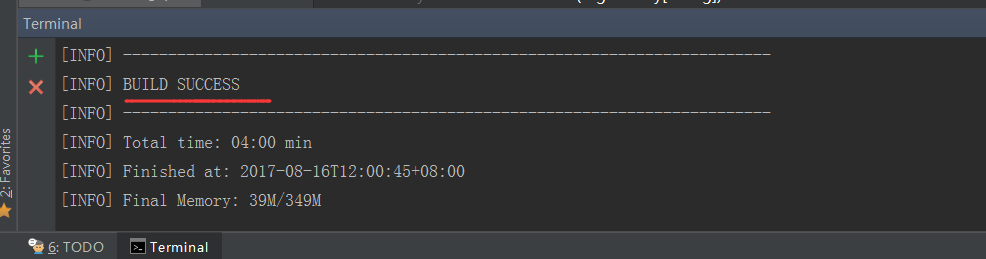
可以看到打包成功!
参考代码
package com.gong.spark import org.apache.spark.{SparkConf, SparkContext} object MyWordCount { def main(args: Array[String]):Unit={ //参数检查 if(args.length<2){ System.err.println("Usage:MyWordCount <input> <output>") System.exit(1) } //获取参数 val input=args(0) val output=args(1) //创建SparkContext val conf=new SparkConf().setAppName("myWordCount") val sc=new SparkContext(conf) //读取数据 val lines=sc.textFile(input) //进行相关计算 val resultRdd=lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_) //保存结果 resultRdd.saveAsTextFile(output) sc.stop() } }
把包上传到集群上(用rz命令就可以了)
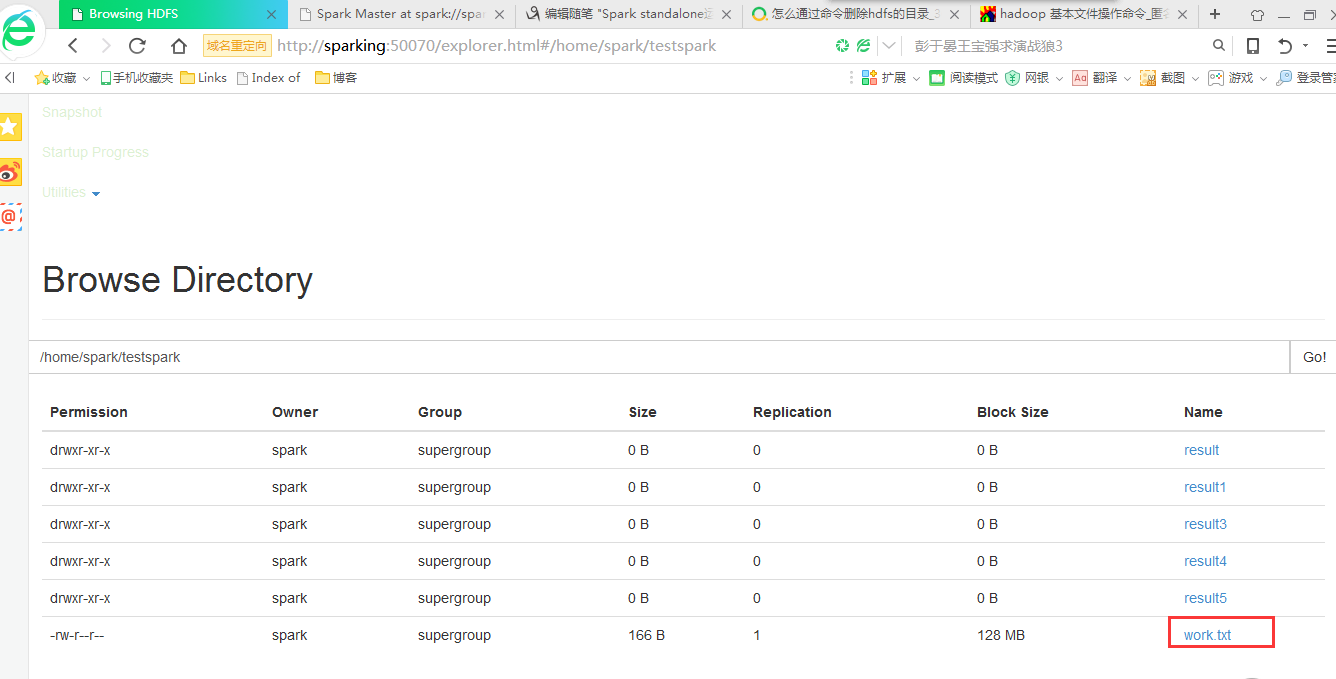
在这之前我已经在我的hdfs上上次了work.txt文件
下面在集群里跑一下程序
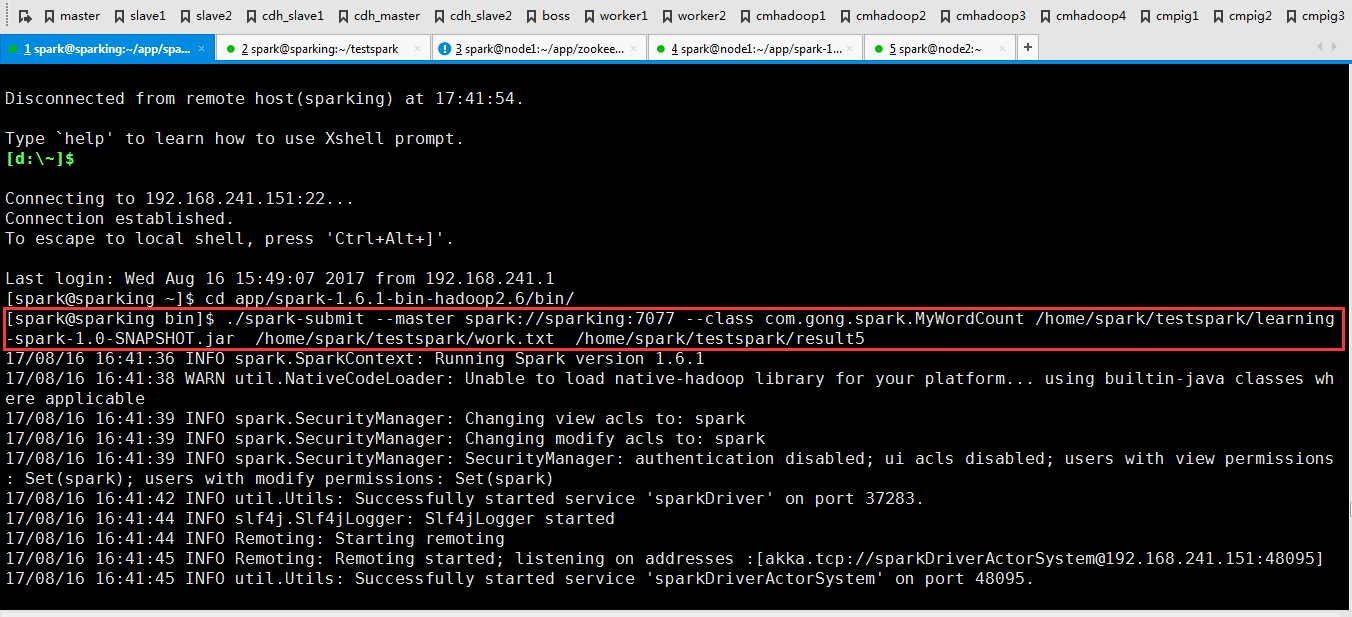
./spark-submit --master spark://sparking:7077 --class com.gong.spark.MyWordCount /home/spark/testspark/learning-spark-1.0-SNAPSHOT.jar /home/spark/testspark/work.txt /home/spark/testspark/result5
可以看到运行完成了(在这里我说下运行这个程序需要网络良好才可以,因为我的实验室的网络非常差,所以我试了好多次)!!!!!
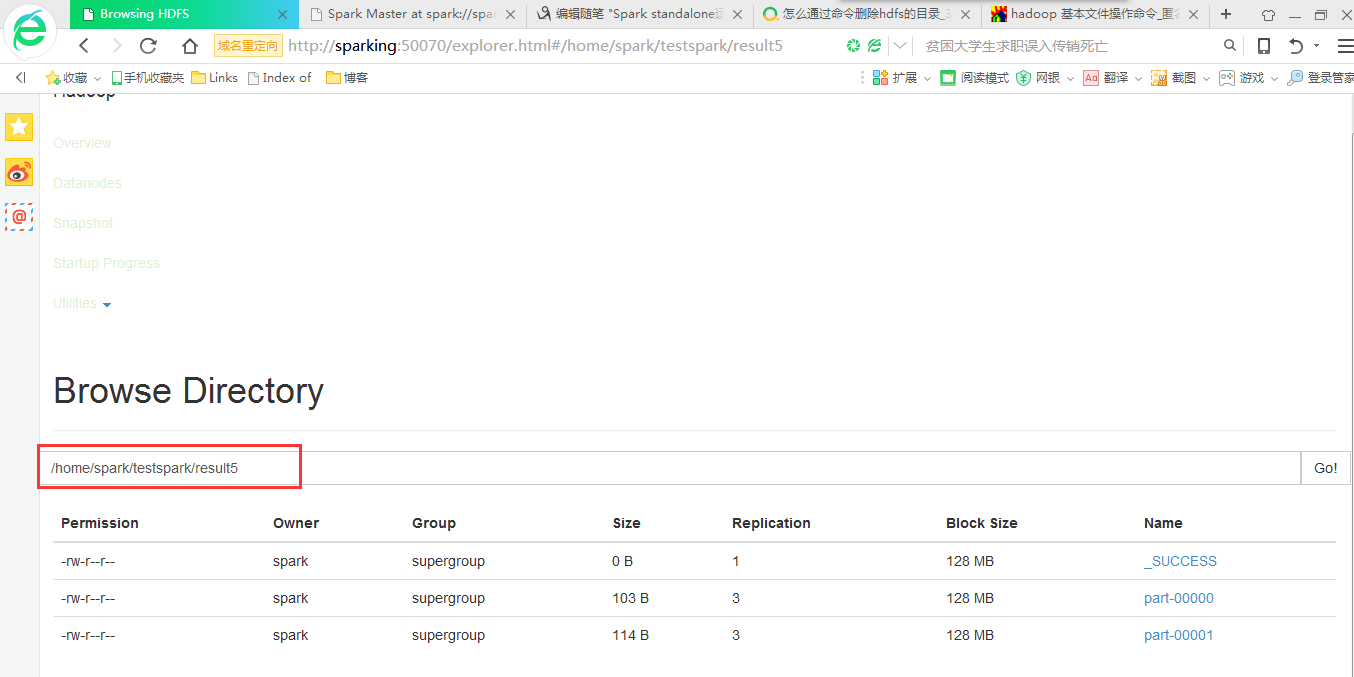
在hdfs上查看运行结果
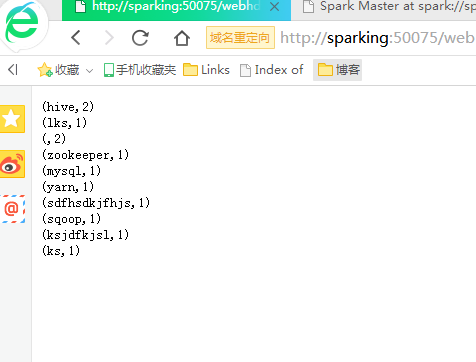

 浙公网安备 33010602011771号
浙公网安备 33010602011771号