
8、Wormhole流处理平台
一、Wormhole概述
1、Wormhole是什么 

2、为什么会有Wormhole 
3、设计理念 

4、主要特性

5、核心概念
参考:https://edp963.github.io/wormhole/concept.html
Namespace(命名空间)
Namespace是Wormhole定义的唯一定位数据系统上数据表的规范,由七部分组成。
[Datastore].[Datastore Instance].[Database].[Table].[Table Version].[Database Partition].[Table Partition]
- Datastore 代表数据存储系统类型,如 Oracle,Mysql,Hbase,Elasticsearch,Kafka 等
- Datastore Instance 代表数据存储系统物理地址别名
- Database 代表 RDBS 中的数据库,Hbase 中的命名空间,Elasticsearch 中的索引,Kafka 中的主题
- Table 代表 RDBS 中的数据表,Hbase 中的数据表,Elasticsearch 中的文档,Kafka 中的某主题下的数据
- Table Version 代表Table 的表结构版本,一般情况下 Table Version 的值应随表结构的变化递增(目前Wormhole 中处理时用“*”匹配所有版本的数据)
- Database Partition 代表 Database 的分区名称(目前 Wormhole 中处理时用“*”匹配所有分区的数据)
- Table Partition 代表 Table 的分表名称(目前 Wormhole 中处理时用“*”匹配所有分表的数据)
例如:mysql.test.social.user.*.*.* kafka.test.social.user.*.*.*
UMS(统一消息规范)
UMS 是 Wormhole 定义的消息规范(JSON 格式),UMS 试图抽象统一所有结构化消息,通过自身携带的结构化数据 Schema 信息,来实现一个物理 DAG 同时处理多个逻辑 DAG 的能力,也避免了和外部数据系统同步元数据的操作。
{ "protocol": { "type": "data_increment_data" }, "schema": { "namespace": "kafka.kafka01.datatopic.user.*.*.*", "fields": [ { "name": "ums_id_", "type": "long", "nullable": false }, { "name": "ums_ts_", "type": "datetime", "nullable": false }, { "name": "ums_op_", "type": "string", "nullable": false }, { "name": "key", "type": "int", "nullable": false }, { "name": "value1", "type": "string", "nullable": true }, { "name": "value2", "type": "long", "nullable": false } ] }, "payload": [ { "tuple": [ "1", "2016-04-11 12:23:34.345123", "i", "23", "aa", "45888" ] }, { "tuple": [ "2", "2016-04-11 15:23:34.345123", "u", "33", null, "43222" ] }, { "tuple": [ "3", "2016-04-11 16:23:34.345123", "d", "53", "cc", "73897" ] } ] }
protocol 代表消息协议
- data_increment_data 代表增量数据
- data_initial_data 代表全量数据
- data_increment_heartbeat 代表增量心跳数据
- data_increment_termination 代表增量数据结束
schema 代表消息来源及表结构信息
namespace 指定消息的来源,fields 指定表结构信息,其中 ums_id_,ums_ts_,ums_op_ 三个字段是必需的三个系统字段,Wormhole 使用这三个字段实现幂等写数据的逻辑。
- ums_id_: long 类型,用来唯一标识消息,须根据消息生成的顺序递增
- ums_ts_: datetime 类型,每一条消息产生的时间
- ums_op_: string 类型,指定每条消息生成的方式,值为 “i” 或 “u” 或 “d” ,分别代表新增,更新,删除操作
payload 代表数据本身
- tuple:一个tuple对应一条消息
UMS_Extension (UMS 扩展格式)
除 UMS 格式外,Wormhole 支持 UMS_Extension(UMS扩展格式),用户可自定义数据格式,且支持嵌套结构。使用时须将 Kafka 消息的 key 设置为 data_increment_data.sourceNamespace,然后在 Wormhole 页面上粘贴数据样式简单配置即可。如 sourceNamespace 为 kafka.kafka01.datatopic.user.*.*.*,则 Kafka 消息的 key 须为 data_increment_data.kafka.kafka01.datatopic.user.*.*.*。
若一个 sourceNamespace 的消息需要随机分配到多个 partition,消息的 key 可设置为data_increment_data.kafka.kafka01.datatopic.user.*.*.*...abc 或 data_increment_data.kafka.kafka01.datatopic.user.*.*.*...bcd,即在 sourceNamespace 后面添加“…”,之后可添加随机数或任意字符。
若 UMS_Extension 类型数据有增删改操作且需要幂等写入,也须配置 ums_id_,ums_ts_,ums_op_ 三个字段。具体配置方式请参考 Admin-Guide Namespace章节。
Stream
Stream 是在 Spark Streaming 上封装的一层计算框架,消费的数据源是 Kafka。Stream 作为 Wormhole 的流式计算引擎,匹配消息的 key,sourceNamespace 和其对应处理逻辑,可将数据以幂等的方式写入多种数据系统中。处理过程中 Stream 会反馈错误信息、心跳信息、处理数据量及延时等信息。
一个 Stream 可以处理多个 Namespace 及其处理逻辑,共享计算资源。
Flow
Flow 关注的是数据从哪来(sourceNamespace),到哪去(sinkNamespace),及中间的处理逻辑。
Flow 支持 SQL 配置,自定义UDF,自定义 Class,且可以关联其他 RDBS/Hbase/Phoenix/Redis/Es 等系统中的数据。
Flow 配置好后可以注册到 Stream,Stream 接收 Flow 指令后,根据指令中的 sourceNamespace,sinkNamespace 及业务逻辑处理数据。
Job
Job 相当于 Spark Job,其数据源是 HdfsLog Stream 备份在 Hdfs 上的数据。Stream/Flow/Job 组合可实现 Lambda 架构和 Kappa 架构。
Kafka 中数据有一定的生命周期,可通过 Stream 将 Kafka 中数据备份到 Hdfs 上。后续需要从某个时间节点重新计算或者补充某个时间段的数据,可通过 Job 读取 Hdfs上 的备份数据,配置与 Flow 相同的处理逻辑,将数据写入目标表。
注意:目前 UMS_Extension 类型数据只支持通过 Stream 将 Kafak 中数据备份到 Hdfs 上,Job 还不支持读取 UMS_Extension 类型数据。
二、wormhole编译
1、克隆源代码
git clone https://github.com/edp963/wormhole.git cd wormhole
2、切换tag
git checkout 0.6.2
我个人是直接下载0.6.2版本的代码下来
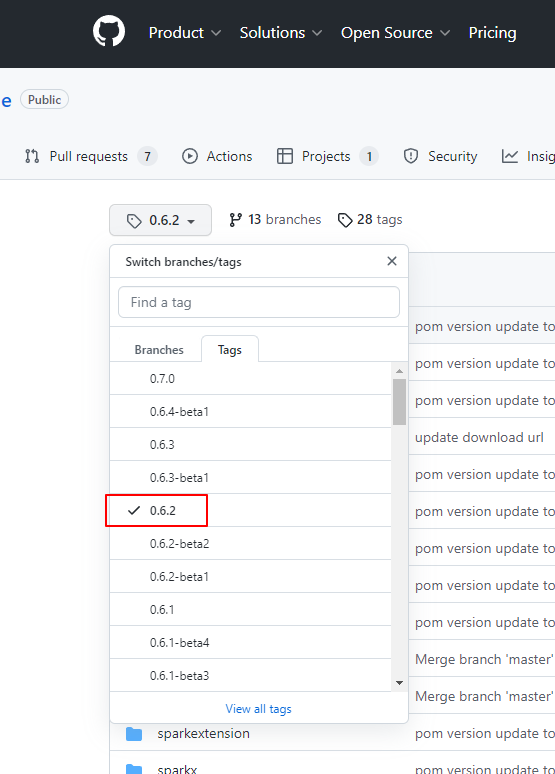
3、导入idea,修改pom.xml
修改以下部分:
<!-- <distributionManagement>-->
<!-- <repository>-->
<!-- <id>dist-nexus</id>-->
<!-- <url>${release.url}</url>-->
<!-- </repository>-->
<!-- </distributionManagement>-->
<!-- common repositories -->
<!-- <repositories>-->
<!-- <repository>-->
<!-- <id>alimaven</id>-->
<!-- <url>http://maven.aliyun.com/nexus/content/groups/public/</url>-->
<!-- </repository>-->
<!-- <!–<repository>–>-->
<!-- <!–<id>hortonworks</id>–>-->
<!-- <!–<url>http://repo.hortonworks.com/content/repositories/releases/</url>–>-->
<!-- <!–</repository>–>-->
<!-- <repository>-->
<!-- <id>conjars</id>-->
<!-- <url>http://conjars.org/repo/</url>-->
<!-- </repository>-->
<!-- <repository>-->
<!-- <id>creditease</id>-->
<!-- <url>${public.url}</url>-->
<!-- </repository>-->
<!-- </repositories>-->
4、新增kafka2.0.0支持 
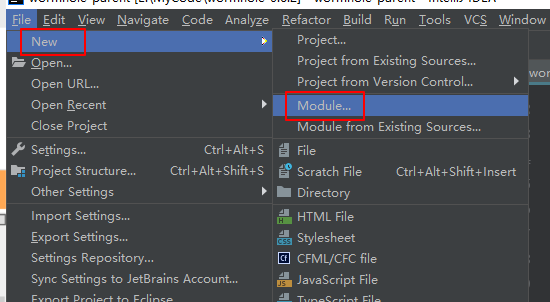

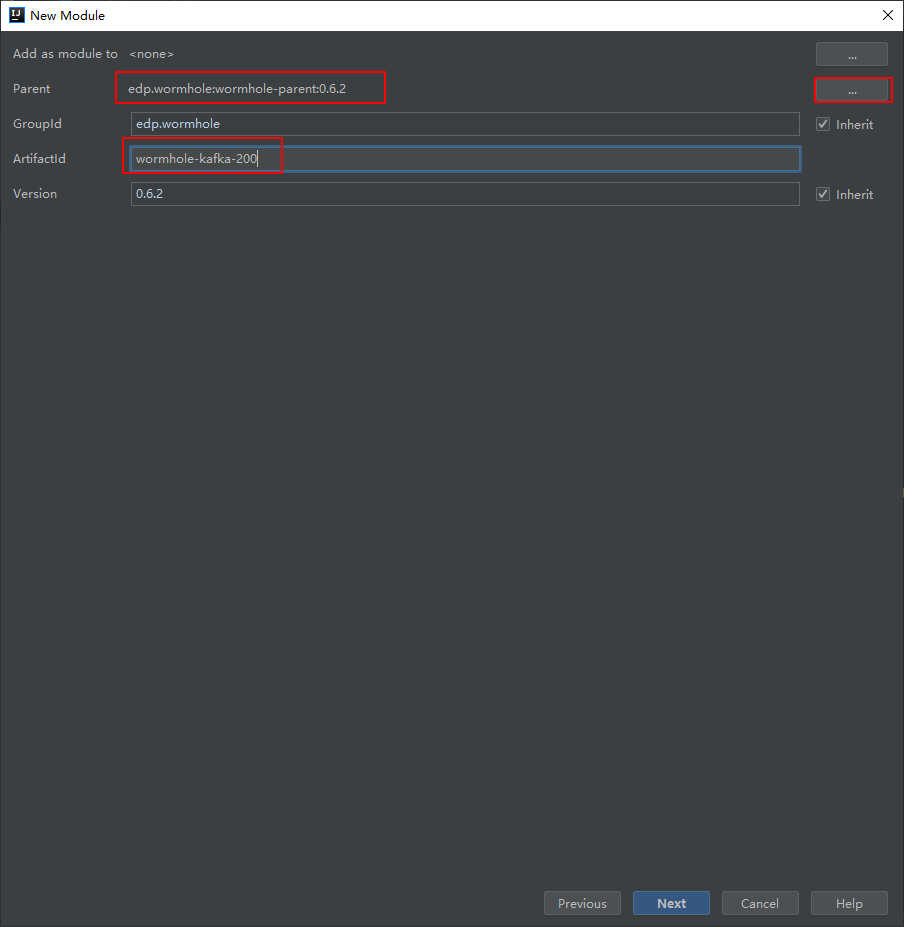


注册新加模块
修改最外层的pom.xml
<modules>
<module>ums</module>
<module>kafkatool/kafka08</module>
<module>kafkatool/kafka010</module>
<module>kafkatool/kafka010-2</module>
<module>kafkatool/kafka200</module>
<module>util</module>
<module>externalclient/zookeeper</module>
<module>externalclient/hadoop</module>
<module>dbdriver/dbpool</module>
<module>dbdriver/sql4es5</module>
<module>dbdriver/sql4es2</module>
<module>dbdriver/redispool</module>
<module>dbdriver/kuduconnection</module>
<module>dbdriver/hbaseconnection</module>
<!--<module>dbdriver/phoenix-jdbc</module>-->
<module>interface/sparkxinterface</module>
<module>interface/flinkxinterface</module>
<module>interface/publicinterface</module>
<module>sinks</module>
<module>common</module>
<module>swifts</module>
<module>reporter</module>
<module>flinkx</module>
<module>sparkextension/spark_extension_2_2</module>
<module>sparkextension/spark_extension_2_3</module>
<module>sparkextension/spark_extension_2_4</module>
<module>sparkx</module>
<!--<module>rider/common/haservice</module>-->
<module>rider/rider-server</module>
<!--<module>rider/mad-server</module>-->
<module>rider/rider-assembly</module>
</modules>
修改新模块pom文件
修改本模块的pom.xml
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <parent> <artifactId>wormhole-parent</artifactId> <groupId>edp.wormhole</groupId> <version>0.6.2</version> <relativePath>../../pom.xml</relativePath> </parent> <modelVersion>4.0.0</modelVersion> <artifactId>wormhole-kafka-200</artifactId> <packaging>jar</packaging> <properties> <main.basedir>${project.parent.basedir}</main.basedir> </properties> <dependencies> <dependency> <groupId>edp.wormhole</groupId> <artifactId>wormhole-util</artifactId> <version>${project.version}</version> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.11</artifactId> <version>2.0.0</version> <exclusions> <exclusion> <groupId>junit</groupId> <artifactId>junit</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>2.0.0</version> <exclusions> <exclusion> <groupId>junit</groupId> <artifactId>junit</artifactId> </exclusion> </exclusions> </dependency> </dependencies> </project>
复制代码
把kafka010-2的源代码目录全部拷贝过来,并设置为source root目录: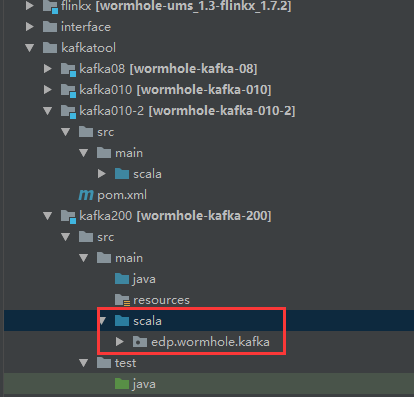
修改源代码
修改edp.wormhole.kafka.WormholeGetOffsetUtils:
#删掉如下三行
import kafka.api.{OffsetFetchRequest, OffsetFetchResponse}
import kafka.common.TopicAndPartition
import kafka.network.BlockingChannel
5、适配HDP3.1
修改最外层pom.xml以适配HDP3.1:
<!-- <kafka.version>0.10.2.2</kafka.version>--> <!-- <hadoop.version>2.7.1</hadoop.version>--> <!-- <hbase.version>1.1.3</hbase.version>--> <!-- <hive.version>1.2.1</hive.version>--> <kafka.version>2.0.0</kafka.version> <hadoop.version>3.1.1</hadoop.version> <hbase.version>2.0.2</hbase.version> <hive.version>3.1.0</hive.version> <flink.version>1.7.2</flink.version> <zookeeper.version>3.4.6</zookeeper.version> <jackson.version>2.6.5</jackson.version> <kudu.version>1.8.0</kudu.version> <clickhouse.version>0.1.54</clickhouse.version> <fastjson.version>1.2.58</fastjson.version> <!-- <spark.extension.version>2.2</spark.extension.version>--> <spark.extension.version>2.3</spark.extension.version>
wormhole 0.6.2及之后版本增加spark不同版本兼容,已适配spark2.2/2.3/2.4,默认支持的是spark2.2,其他版本需要用户修改代码中的spark版本号进行适配。
修改启动stream时调用的sparkx jar包名称,即edp.rider.common.RiderConfig.scala中wormholeJarPath 和wormholeKafka08JarPath变量:

lazy val wormholeJarPath = getStringConfig("spark.wormhole.jar.path", s"${RiderConfig.riderRootPath}/app/wormhole-ums_1.3-sparkx_2.3-0.6.2-jar-with-dependencies.jar")
lazy val wormholeKafka08JarPath = getStringConfig("spark.wormhole.kafka08.jar.path", s"${RiderConfig.riderRootPath}/app/wormhole-ums_1.3-sparkx_2.3-0.6.2-jar-with-dependencies-kafka08.jar")
6、其他bug修复
fix wh feedback mysql bug
rider/conf/wormhole.sql:
#483行新增 alter table `feedback_flow_stats` modify column `batch_id` varchar(100); alter table `feedback_flow_stats` modify column `topics` varchar(2000) NOT NULL;
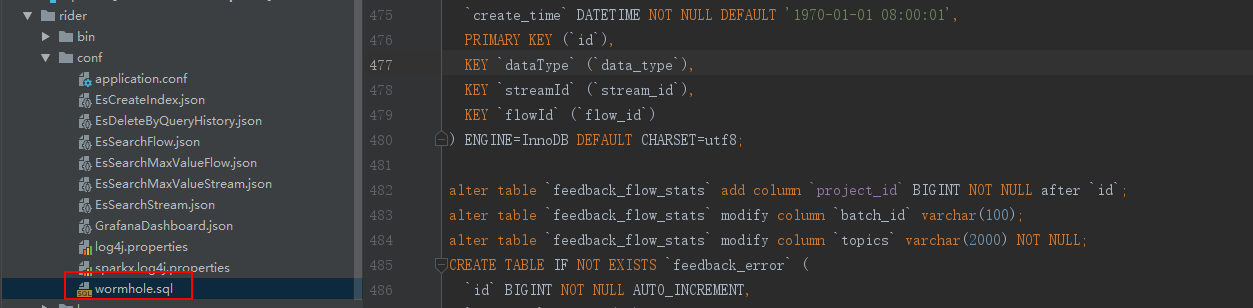
rider/rider-server/src/main/scala/edp/rider/rest/persistence/entities/MonitorInfo.scala:
//val intervalSwiftsToSink: Rep[Long] = column[Long]("interval_swifts_sink") //val intervalSinkToDone: Rep[Long] = column[Long]("interval_sink_done") val intervalSwiftsToSink: Rep[Long] = column[Long]("interval_swifts_to_sink") val intervalSinkToDone: Rep[Long] = column[Long]("interval_sink_to_done")
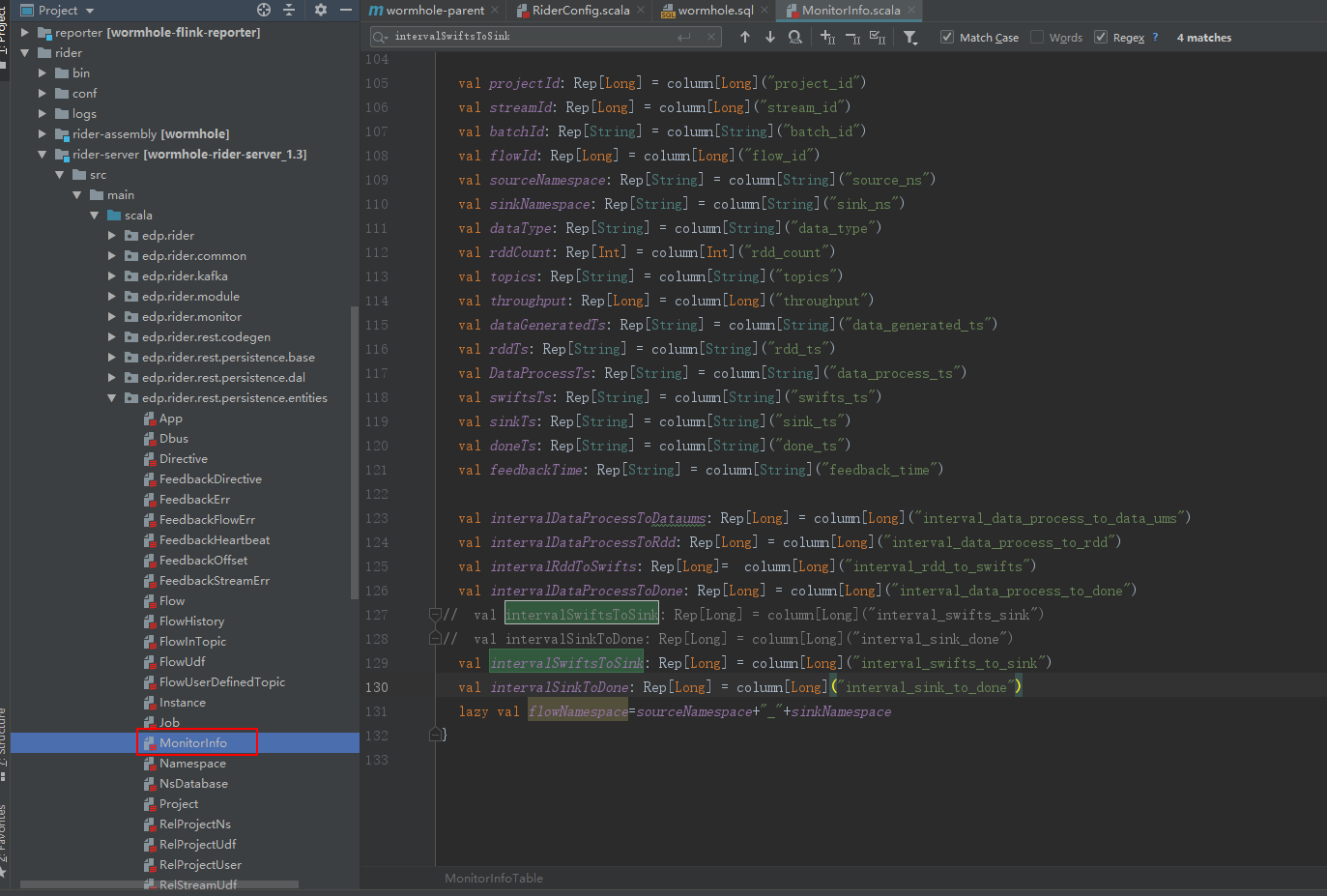
修复Phoenix sink⽆无法建⽴立连接的bug:
修复方法 edp.rider.rest.util.NamespaceUtils 
// case "mysql" | "postgresql" | "phoenix" | "vertica" | "clickhouse"=> // db.config match { // case Some(conf) => // if (conf != "") { // val confStr = // (keyEqualValuePattern.toString.r findAllIn conf.split(",").mkString("&")).toList.mkString("&") // s"jdbc:${instance.nsSys}://${instance.connUrl}/${db.nsDatabase}?$confStr" // } else s"jdbc:${instance.nsSys}://${instance.connUrl}/${db.nsDatabase}" // case None => s"jdbc:${instance.nsSys}://${instance.connUrl}/${db.nsDatabase}" // } case "mysql" | "postgresql" | "vertica" | "clickhouse"=> db.config match { case Some(conf) => if (conf != "") { val confStr = (keyEqualValuePattern.toString.r findAllIn conf.split(",").mkString("&")).toList.mkString("&") s"jdbc:${instance.nsSys}://${instance.connUrl}/${db.nsDatabase}?$confStr" } else s"jdbc:${instance.nsSys}://${instance.connUrl}/${db.nsDatabase}" case None =>s"jdbc:${instance.nsSys}://${instance.connUrl}/${db.nsDatabase}" }
修复Phoenix sink⽆无法正确找到table的bug
现象:明明对应的表存在,仍然报如下错误:
org.apache.phoenix.schema.TableNotFoundException: ERROR 1012 (42M03): Table
undefined. tableName=sca.USER_INFO
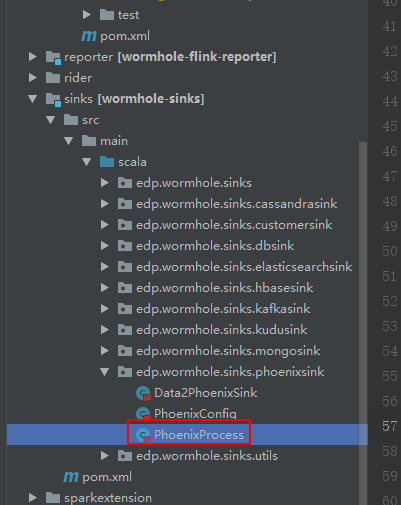
修复方法: edp.wormhole.sinks.phoenixsink.PhoenixProcess 第57、58行:
// val sql = s"UPSERT INTO "+ "\""+tableName+ "\""+s" ($columnNames,"+ "\""+s"${UmsSysField.ACTIVE.toString.toUpperCase}"+"\""+") VALUES " + // (1 to baseFieldNames.size + 1).map(_ => "?").mkString("(", ",", ")") val sql = s"UPSERT INTO "+ ""+tableName+ ""+s" ($columnNames,"+ "\""+s"${UmsSysField.ACTIVE.toString.toUpperCase}"+"\""+") VALUES " + (1 to baseFieldNames.size + 1).map(_ => "?").mkString("(", ",", ")")
7、编译源代码
mvn clean package -DskipTests -Pwormhole

编译完成后,安装包在target目录下:
三、Wormhole部署
1、环境准备

2、启动依赖服务

3、部署规划

4、配置
上传安装包:
将前面编译好的安装包wormhole-0.6.2.tar.gz上传到node01的/home/hadoop/app目录下。
cd /home/hadoop/app tar -xvf wormhole-0.6.2.tar.gz ln -s wormhole-0.6.2 wormhole
配置环境变量:
vim /etc/profile
添加以下内容:
export WORMHOLE_HOME=/home/hadoop/app/wormhole
export PATH=$WORMHOLE_HOME/bin:$PATH
保存退出,使环境变量生效:
source /etc/profile
配置rider-server
vim $WORMHOLE_HOME/conf/application.conf
配置内容如下:
akka.http.server.request-timeout = 120s wormholeServer { cluster.id = "" #optional global uuid host = "0.0.0.0" port = 8989 ui.default.language = "Chinese" token.timeout = 1 token.secret.key = "iytr174395lclkb?lgj~8u;[=L:ljg" admin.username = "admin" #default admin user name admin.password = "admin" #default admin user password refreshInterval = "5" #refresh yarn to update stream status interval(second) } mysql = { driver = "slick.driver.MySQLDriver$" db = { driver = "com.mysql.jdbc.Driver" user = "wormhole" password = "wormhole" url = "jdbc:mysql://node01:3306/wormhole?useUnicode=true&characterEncoding=UTF-8&useSSL=false" numThreads = 4 minConnections = 4 maxConnections = 10 connectionTimeout = 3000 } } ldap = { enabled = false user = "" pwd = "" url = "" dc = "" read.timeout = 3000 read.timeout = 5000 connect = { timeout = 5000 pool = true } } spark = { wormholeServer.user = "hadoop" wormholeServer.ssh.port = 22 spark.home = "/usr/hdp/current/spark2-client" yarn.queue.name = "default" #WormholeServer submit spark streaming/job queue wormhole.hdfs.root.path = "hdfs://node01:8082/wormhole" #WormholeServer hdfslog data default hdfs root path yarn.rm1.http.url = "node01:8088" #Yarn ActiveResourceManager address yarn.rm2.http.url = "node01:8088" #Yarn StandbyResourceManager address #yarn.web-proxy.port = 8888 #Yarn web proxy port, just set if yarn service set yarn.web-proxy.address config } flink = { home = "/usr/local/flink" yarn.queue.name = "default" checkpoint.enable = false checkpoint.interval = 60000 stateBackend = "hdfs://nn1/flink-checkpoints" feedback = { enabled = false state.count = 100 interval = 30 } } zookeeper = { connection.url = "node01:2181" #WormholeServer stream and flow interaction channel wormhole.root.path = "/wormhole" #zookeeper } kafka = { brokers.url = "node02:6667" #WormholeServer feedback data store zookeeper.url = "node01:2181" topic.refactor = 3 using.cluster.suffix = false #if true, _${cluster.id} will be concatenated to consumer.feedback.topic consumer = { feedback.topic = "wormhole_feedback" poll-interval = 1m poll-timeout = 1m stop-timeout = 30s close-timeout = 20s commit-timeout = 70s wakeup-timeout = 1h max-wakeups = 10000 session.timeout.ms = 120000 heartbeat.interval.ms = 50000 max.poll.records = 1000 request.timeout.ms = 130000 max.partition.fetch.bytes = 4194304 } } #kerberos = { # kafka.enabled = false # keytab = "" # rider.java.security.auth.login.config = "" # spark.java.security.auth.login.config = "" # java.security.krb5.conf = "" #} # choose monitor method among ES、MYSQL monitor = { database.type = "MYSQL" } #Wormhole feedback data store, if doesn't want to config, you will not see wormhole processing delay and throughput #if not set, please comment it #elasticSearch.http = { # url = "http://localhost:9200" # user = "" # password = "" #} #delete feedback history data on time maintenance = { mysql.feedback.remain.maxDays = 7 elasticSearch.feedback.remain.maxDays = 7 } #Dbus integration, support serveral DBus services, if not set, please comment it #dbus = { # api = [ # { # login = { # url = "http://localhost:8080/keeper/login" # email = "" # password = "" # } # synchronization.namespace.url = "http://localhost:8080/keeper/tables/riderSearch" # } # ] #}
Feedback State 存储位置配置:
wormhole在0.6版本之前的feedback state默认存储在ES中,在0.6版本之后,将支持用户根据需求在ES与MySQL中间选择合适的存储库进行数据存储。
如果需要将存储位置由ES迁往MySQL,可以参照下面的步骤进行配置。通过配置monitor.database.type选择存储位置
monitor.database.type = "MYSQL" #存储到mysql中
monitor.database.type = "ES" #存储到ES中
当选择存储到mysql时,需要在wormhole/riderlconf/wormhole.sql新建feedback_flow_stats 表,并在wormhole配置的数据库中执行该文件,从而在数据库中建立feedback_flow_stats表
注意:我们前面已经配置为MYSQL了,这里不用动,表会自动创建的。
创建数据库:
在node01上连接mysql:
mysql -u root -p
然后在Mysql命令行执行如下操作:
mysql> set global validate_password_policy=0; Query OK, 0 rows affected (0.01 sec) mysql> set global validate_password_mixed_case_count=0; Query OK, 0 rows affected (0.00 sec) mysql> set global validate_password_number_count=3; Query OK, 0 rows affected (0.00 sec) mysql> set global validate_password_special_char_count=0; Query OK, 0 rows affected (0.00 sec) mysql> set global validate_password_length=3; Query OK, 0 rows affected (0.00 sec) mysql> CREATE DATABASE IF NOT EXISTS wormhole DEFAULT CHARSET utf8 COLLATE utf8_general_ci; Query OK, 1 row affected (0.00 sec) mysql> CREATE USER 'wormhole'@'%' IDENTIFIED BY 'wormhole'; Query OK, 0 rows affected (0.06 sec) mysql> GRANT ALL ON wormhole.* TO 'wormhole'@'%'; Query OK, 0 rows affected (0.02 sec) mysql> FLUSH PRIVILEGES; Query OK, 0 rows affected (0.00 sec)
5、启停
启动:
cd $WORMHOLE_HOME/bin chmod u+x ./* $WORMHOLE_HOME/bin/start.sh
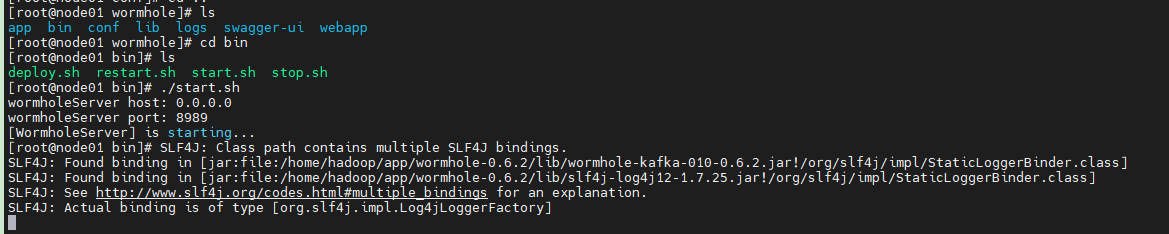
检查
第一次启动之后需要检查一下相关的Topic、表是否创建好:
启动时自动创建 table, kafka topic,elasticsearch index, grafana datasource 创建kafka topic时,有时候会因环境原因失败,须手动创建
topic name: wormhole_feedback partitions: 4
topic nameғ wormhole_heartbeat partitions: 1
# 创建或修改topic命令
cd /usr/hdp/current/kafka-broker/bin/
./kafka-topics.sh --zookeeper node01:2181 --create --topic wormhole_feedback --replication-factor 1 --partitions 4
./kafka-topics.sh --zookeeper node01:2181 --create --topic wormhole_heartbeat --replication-factor 1 --partitions 1
./kafka-topics.sh --zookeeper node01:2181 --alter --topic wormhole_feedback --partitions 4
./kafka-topics.sh --zookeeper node01:2181 --alter --topic wormhole_heartbeat--partitions 1
查看Mysql表
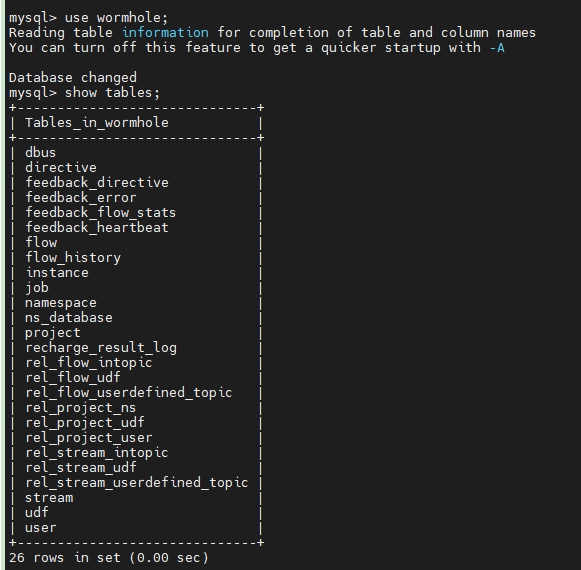
查看kafka topic列表
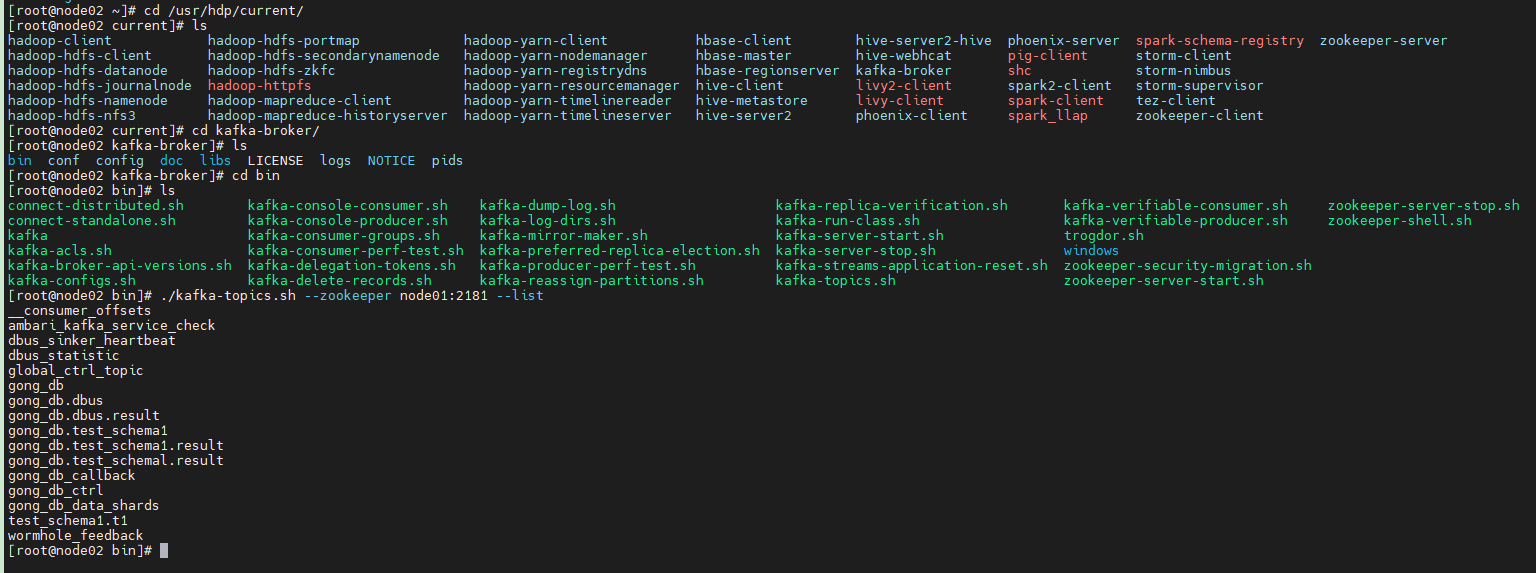
我现在手动把wormhole_heartbeat topic创建上

停止
因为停止脚本通过lsof命令去查找pid的,所以先安装下lsof(一次性操作):
sudo yum -y install lsof
停止命令如下:
$WORMHOLE_HOME/bin/stop.sh
重启:
$WORMHOLE_HOME/bin/restart.sh
6、访问Wormhole
访问http://node01:8989即可试用Wormhole,可使用admin类型用户登录,默认用户名,密码见application.conf中配置,我们设置的是admin/admin。
能看到上述界面wormhole安装基本是没有问题的。
四、快速入门
管理员操作:
创建普通用户
admin/admin登录Wormhole,并按照下图操作切换到用户管理界面︰
在用户管理界面,我们能看到有一个用户就是管理员admin,点击"新建"按钮:

在弹出的窗口中填写相关用户信息,用户类型选择user,点击保存即可,见下图:

为了方便,我把密码设置成666666
1、创建Source Namespace

创建Instance

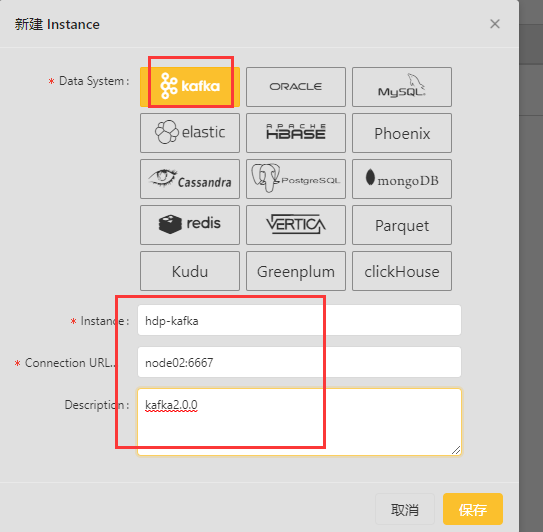
保存之后能看到已经添加成功了:

创建Database


点击新建Database页面:


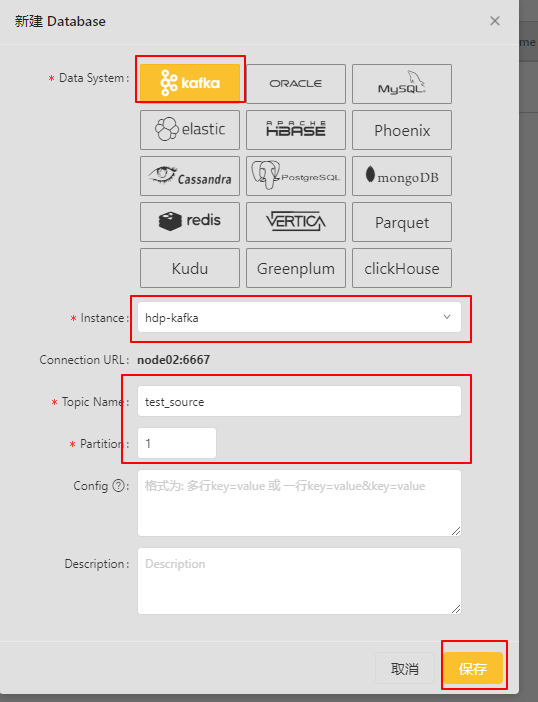
保存之后就能看见:

创建Namespace
有了前面两步创建的Instance和DataBase,接下来就可以轻松创建NameSpace了。进入Namespace列表页:

点击“新建”进入新建Namespace页面:


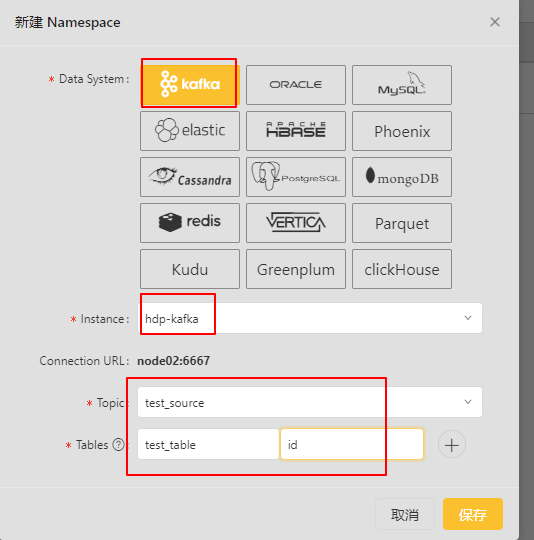
保存之后:

2、创建source topic与模拟数据
kafka集群中创建topic: test_source,并生产测试数据。
创建topic
cd /usr/hdp/current/kafka-broker/bin ./kafka-topics.sh --zookeeper node01:2181 --create --topic test_source --replication-factor 1 --partitions 1
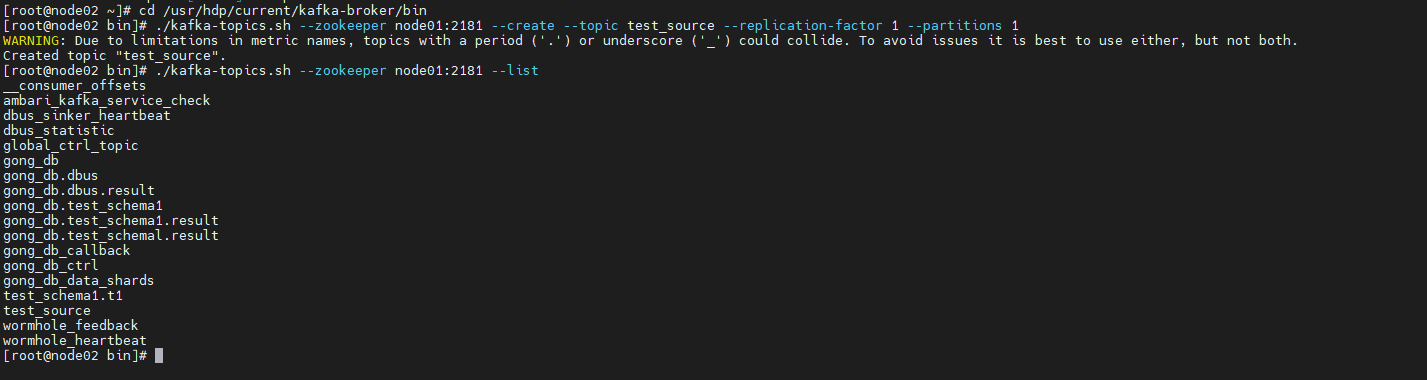
生成测试数据:

data_increment_data.kafka.hdp-kafka.test_source.test_table.*.*.*
生成测试数据命令如下:
cd /usr/hdp/current/kafka-broker/bin ./kafka-console-producer.sh --broker-list node02:6667 --topic test_source --property "parse.key=true" --property "key.separator=@@@"
data_increment_data.kafka.hdp-kafka.test_source.test_table.*.*.*@@@{"id": 1,"name": "test", "phone":"18074546423", "city": "Beijing", "time": "2017-12-2210:00:00"} data_increment_data.kafka.hdp-kafka.test_source.test_table.*.*.*@@@{"id": 2,"name": "test1", "phone":"18074546423", "city": "Shanghai", "time": "2017-12-22 10:00:00"} data_increment_data.kafka.hdp-kafka.test_source.test_table.*.*.*@@@{"id": 3,"name": "test2", "phone":"18074546423", "city": "Wuhan", "time": "2017-12-22 10:00:00"} data_increment_data.kafka.hdp-kafka.test_source.test_table.*.*.*@@@{"id": 4,"name": "test4", "phone":"18074546423", "city": "Wuhan", "time": "2017-12-22 10:00:00"}
3、配置Source Namespace Schema
在前面几步我们创建了Source Namespace,接下来需要配置下他们的Schema。
进入Namespace列表
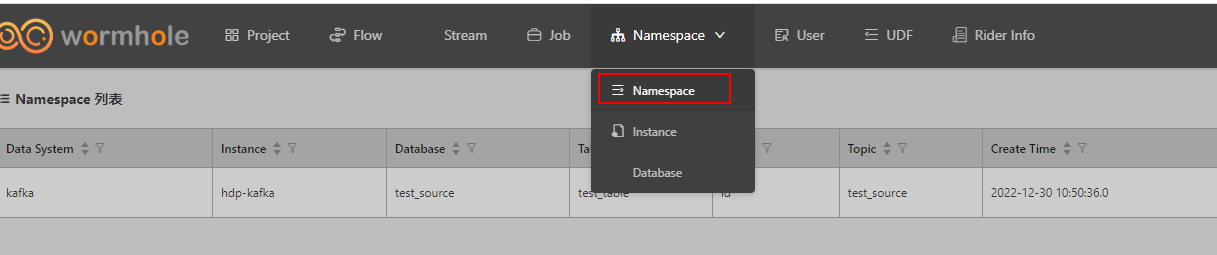
进入souce schema配置页面

配置source schema
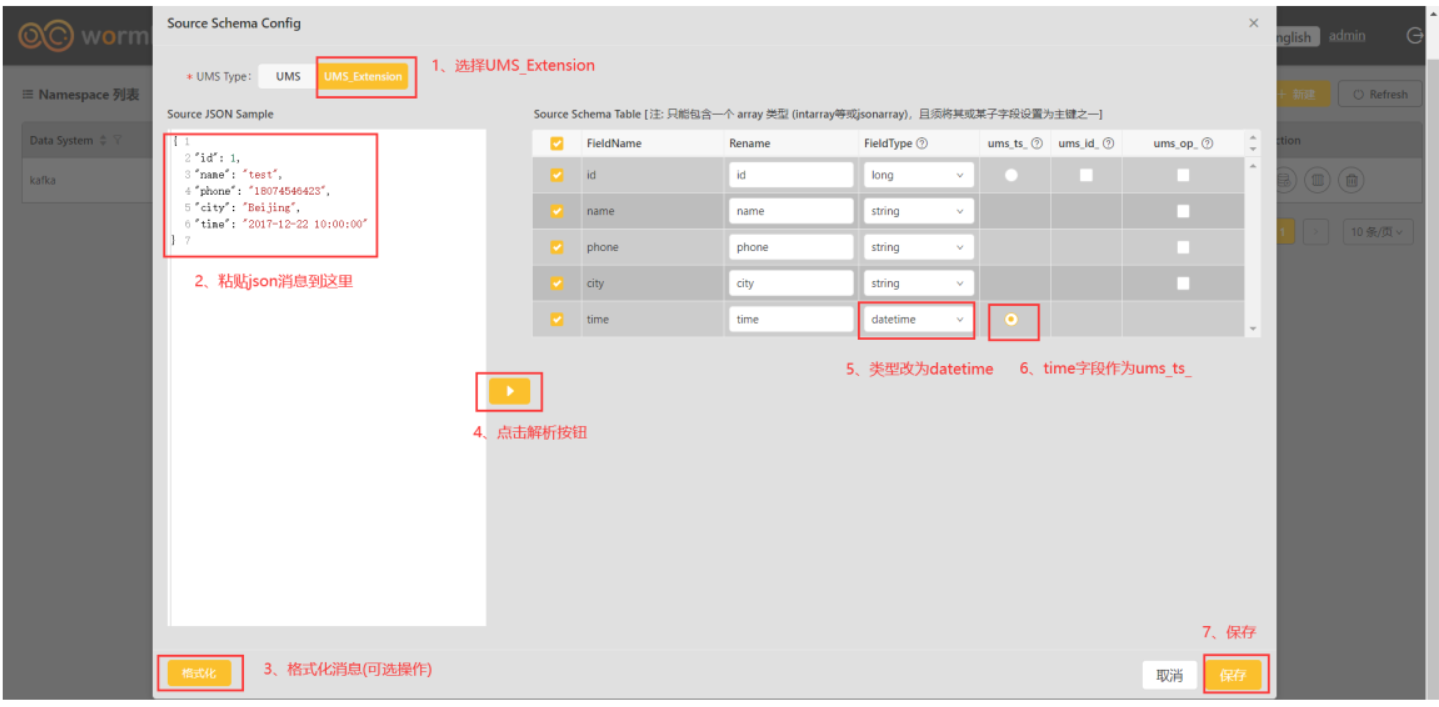
{ "id": 4, "name": "test4", "phone":"18074546423", "city": "Wuhan", "time":"2017-12-22 10:00:00" }
4、创建Sink Namespace

创建Instance


创建Database

useUnicode=true&characterEncoding=utf8&rewriteBatchedStatements=true

创建Namespace
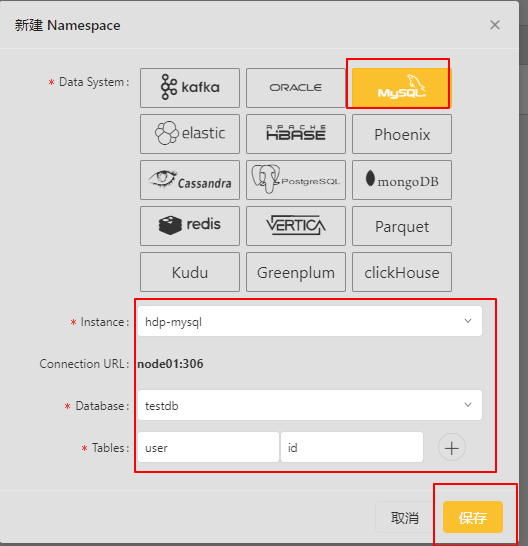

5、创建Lookup Namespace
创建Look Namespace跟Source Namespace也是一样的套路,只不过按照需求咱们的Loop up的Datasys是MySQL。
创建Instance
复用上一步创建的hdp-mysql。
创建Database

useUnicode=true&characterEncoding=utf8&autoReconnect=true&failOverReadOnly=false&noAccessToProcedureBodies=true&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false

创建Namespace
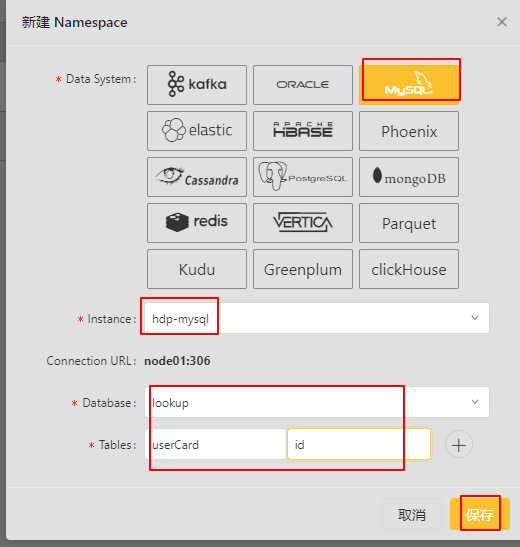

6、创建UDF
UDF为可选项,可以省略该步骤,只有当我们现有的处理逻辑不够用时,才会创建UDF。
7、创建Project并授权
截止当前,我们已经创建好相关Namespace。接下来的操作就可以交给业务部门的普通用户自己来操作了,为了便于管理Wormhole提出了Project的概念。
创建Project
切换到Project列表并点击“新建项目”:

按照下图操作:
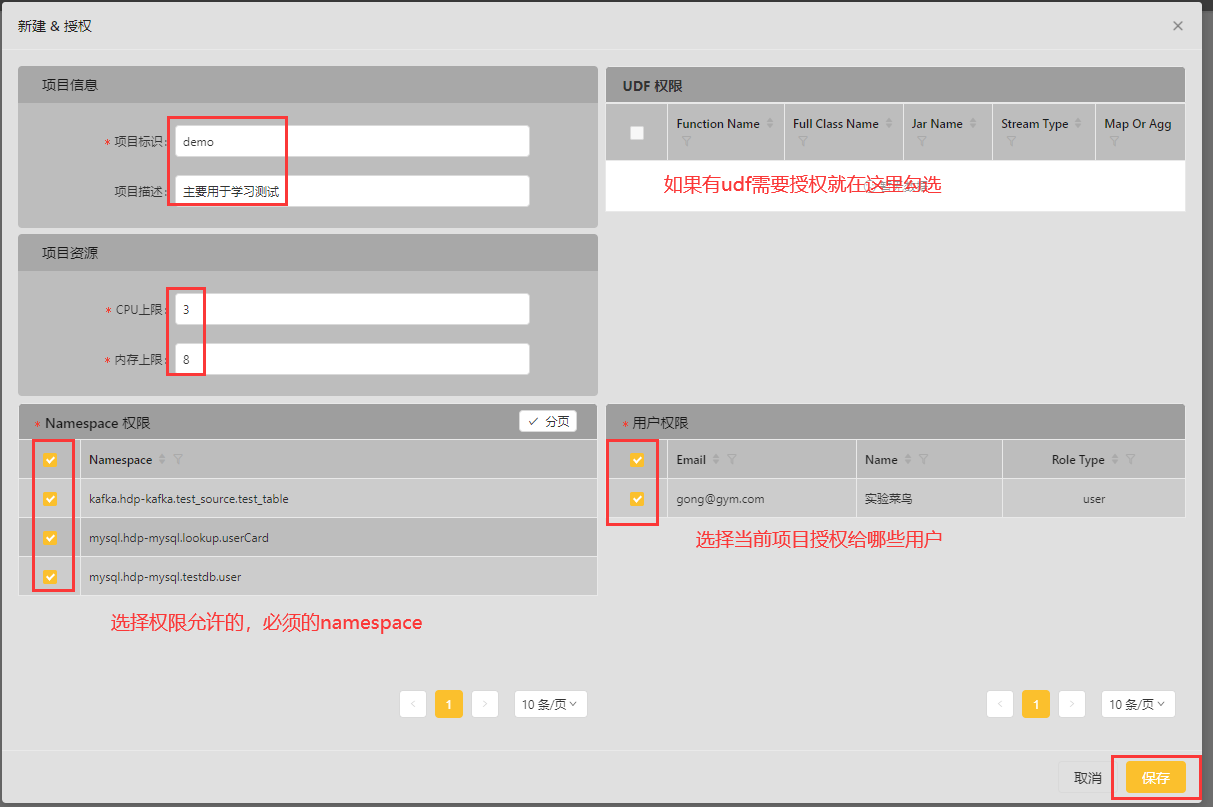
注意:前端有个小bug,添加王project没有自动跳转,直接刷新页面即可。

普通用户操作
Wormhole支持Spark和Flink两种流式处理引擎,这里先介绍Spark Stream/Flow的使用流程。
1、Spark Stream/Flow使用流程
进入项目视图
我这里用之前创建的普通用户登录, 用户名: gong@gym.com 密码:666666 登录Wormhole

点击项目卡片,进入项目视图:

2、创建Stream
进入Stream列表:

添加Stream:
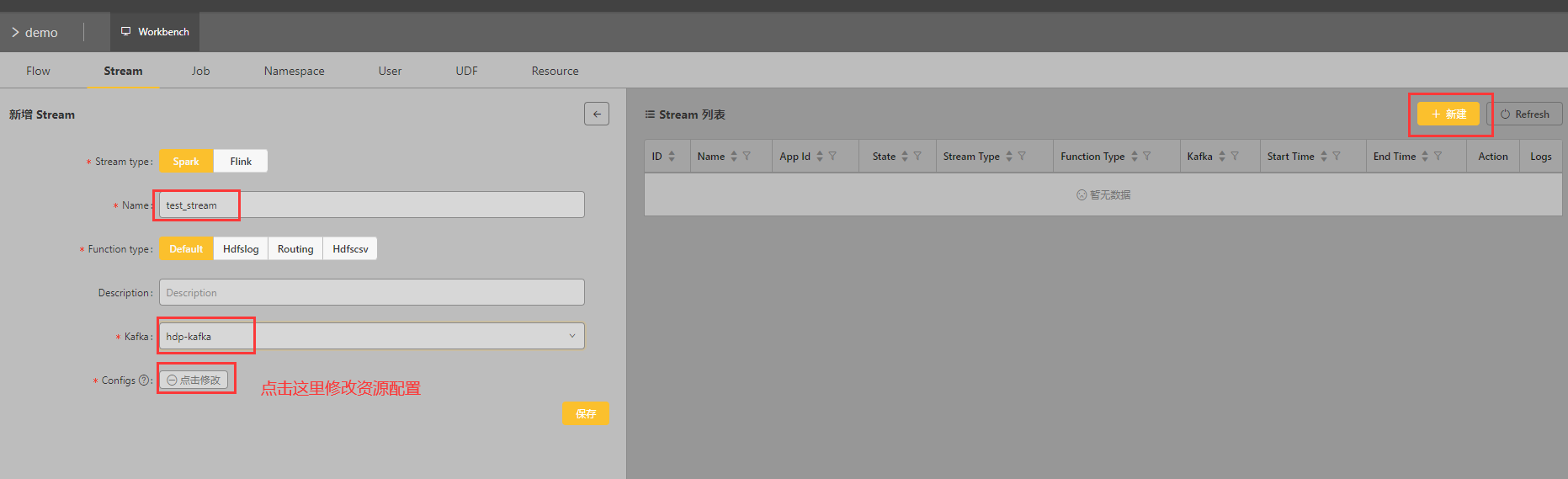
配置Stream资源:

添加完之后就能在列表中看见了:

注意:Stream名字被自动加上了wormhole前缀。
3、创建Flow
选择Spark Stream

选择数据源(source):
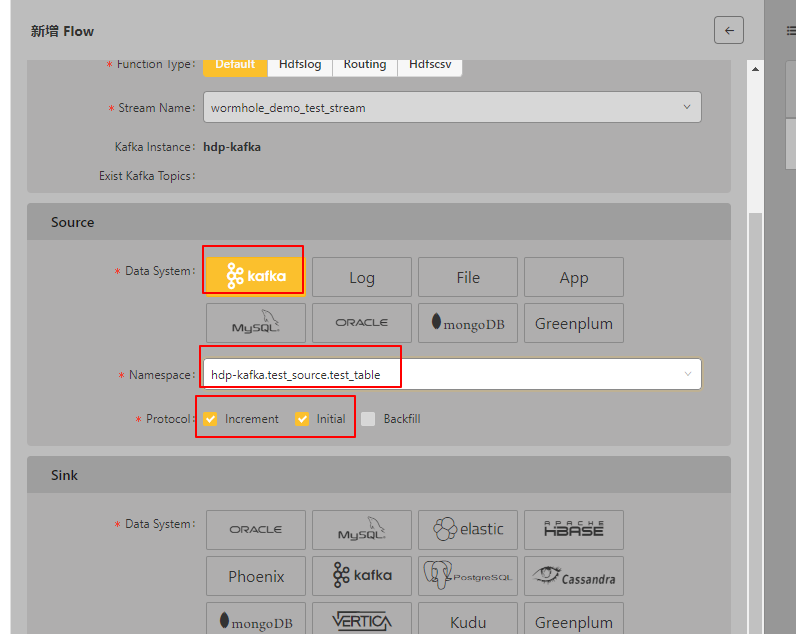
选择目标(sink)
配置sink的基本信息:
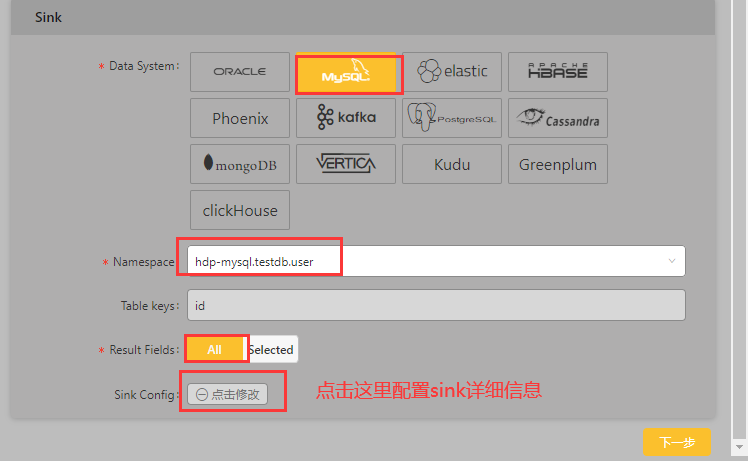
sink高级配置:
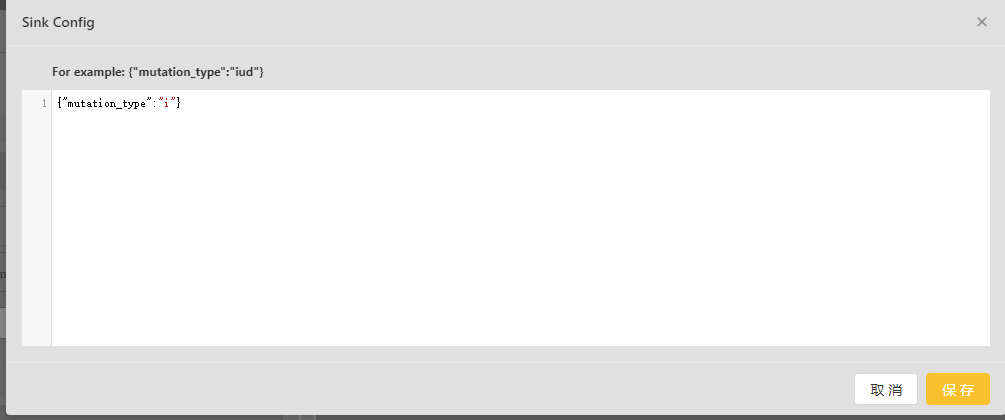
注意:这里配置的是Sink类型,因为在前面Source Namespace 中数据只配置了“ums_ts_”系统字段,"mutation_type”只能设置为“i',即"insert only"。
保存之后点击下一步即可:
配置转换逻辑
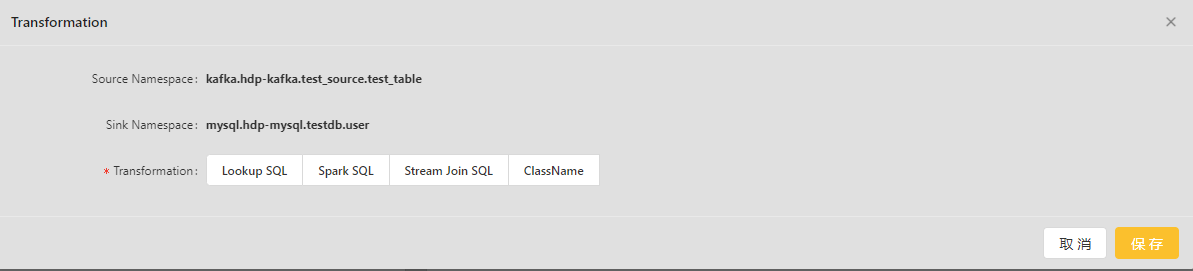
目前Transformation支持 LookupSQL、Spark SQL等类型:
配置lookup SQL
我们直接采用Lookup SQL,配置如下:
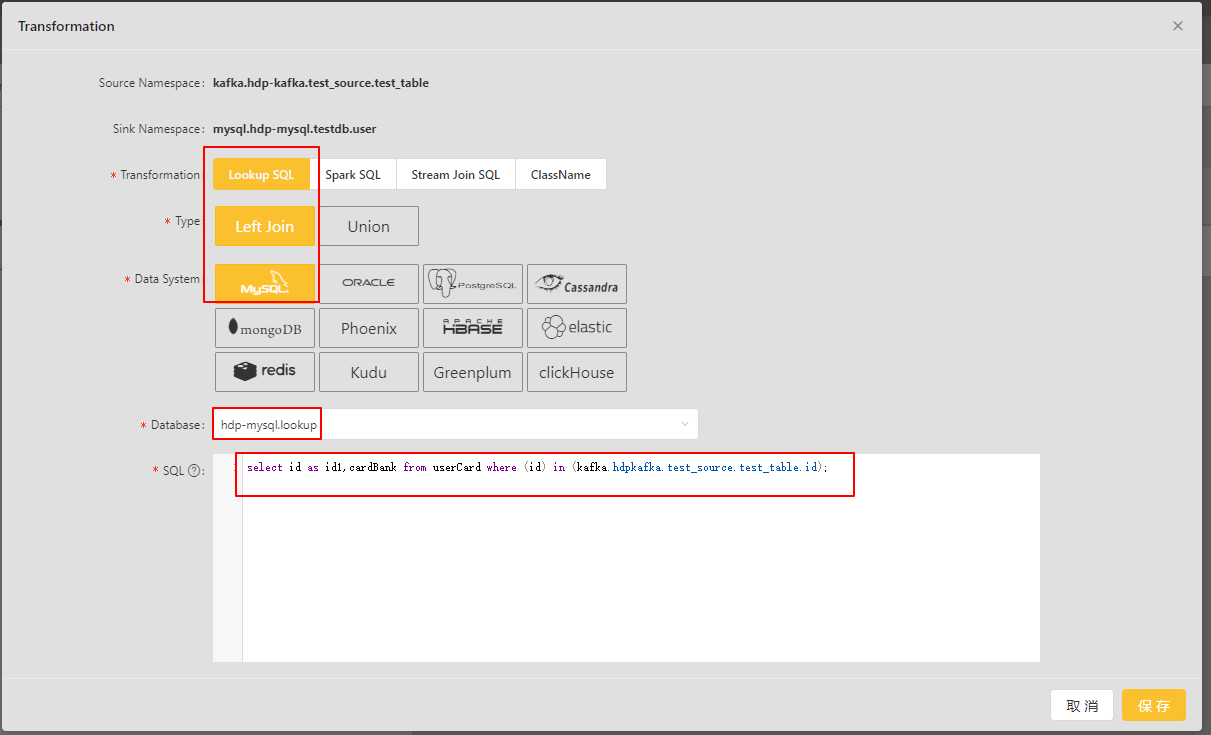
select id as id1,cardBank from userCard where (id) in (kafka.hdpkafka.test_source.test_table.id);
保存之后:
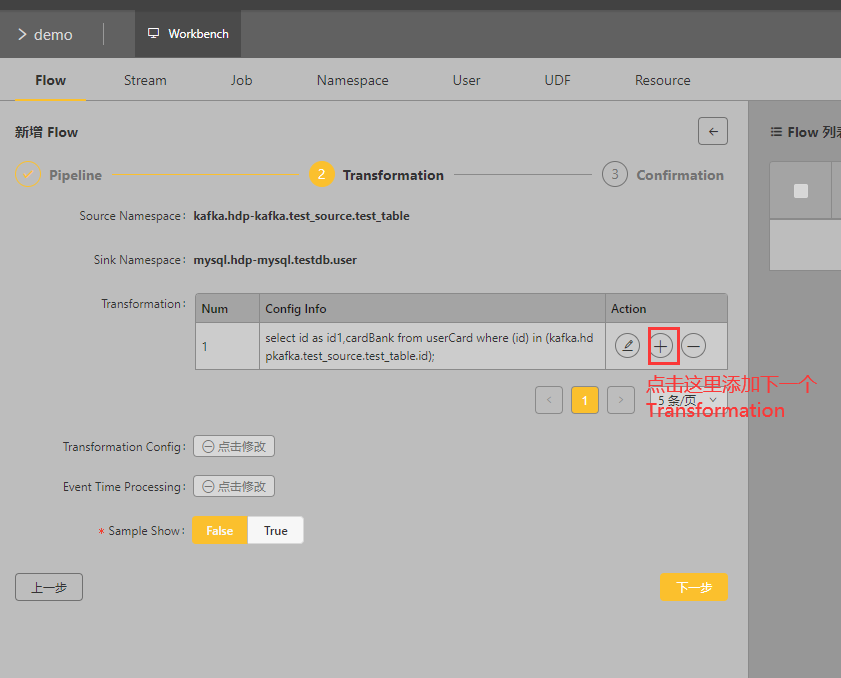
按照上图操作,点击加号再添加一个Spark SQL 类型的转换逻辑来过滤字段:
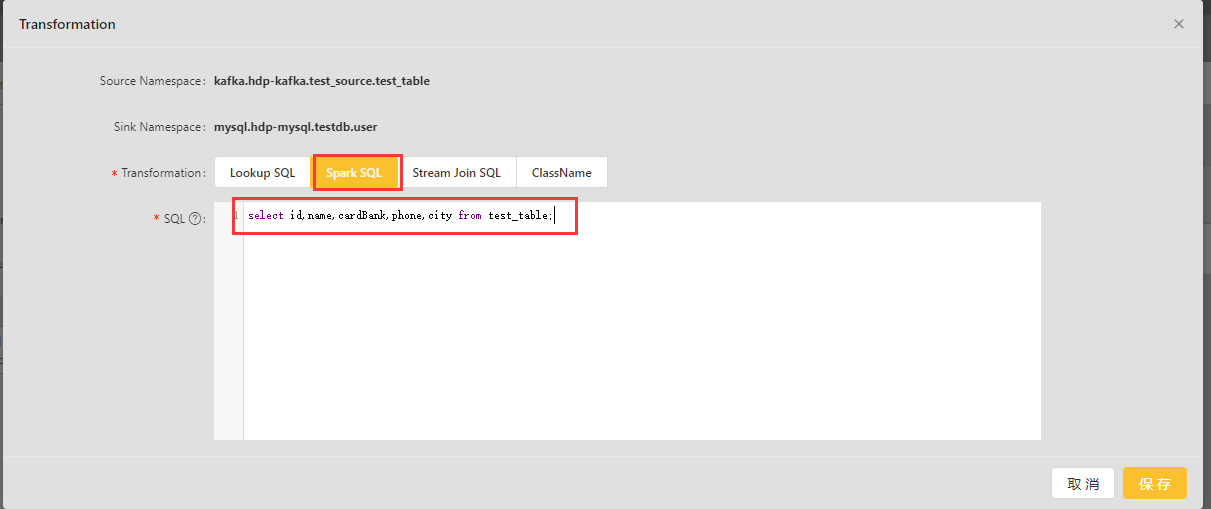
select id,name,cardBank,phone,city from test_table;
保存之后点击下一步:
最后提交:

最后就能看见了:

4、创建Lookup Table/Sink Table
在node01节点上登录Mysql:
mysql -u root -p
Lookup Table:
CREATE DATABASE IF NOT EXISTS lookup DEFAULT CHARSET utf8 COLLATE utf8_unicode_ci; use lookup; CREATE TABLE IF NOT EXISTS `userCard` ( `id` BIGINT NOT NULL AUTO_INCREMENT, `cardBank` VARCHAR(200) NOT NULL, PRIMARY KEY (`id`) )ENGINE = InnoDB CHARSET=utf8 COLLATE=utf8_unicode_ci; INSERT INTO userCard (id, cardBank) VALUES (1, "CMB"); INSERT INTO userCard (id, cardBank) VALUES (2, "CITIC"); INSERT INTO userCard (id, cardBank) VALUES (3, "ABC"); INSERT INTO userCard (id, cardBank) VALUES (4, "BOC"); INSERT INTO userCard (id, cardBank) VALUES (5, "CEB"); INSERT INTO userCard (id, cardBank) VALUES (6, "CCB"); INSERT INTO userCard (id, cardBank) VALUES (7, "ICBC"); INSERT INTO userCard (id, cardBank) VALUES (8, "CMBC"); INSERT INTO userCard (id, cardBank) VALUES (9, "SPDB"); INSERT INTO userCard (id, cardBank) VALUES (10, "GDB");
sink Table:
CREATE DATABASE IF NOT EXISTS testdb DEFAULT CHARSET utf8 COLLATE utf8_unicode_ci; use testdb; CREATE TABLE IF NOT EXISTS `user` ( `id` BIGINT NOT NULL AUTO_INCREMENT, `name` VARCHAR(200) NOT NULL, `cardBank` VARCHAR(200) NOT NULL, `phone` VARCHAR(200) NOT NULL, `city` VARCHAR(200) NOT NULL, PRIMARY KEY (`id`) )ENGINE = InnoDB CHARSET=utf8 COLLATE=utf8_unicode_ci;
5、启动Flow
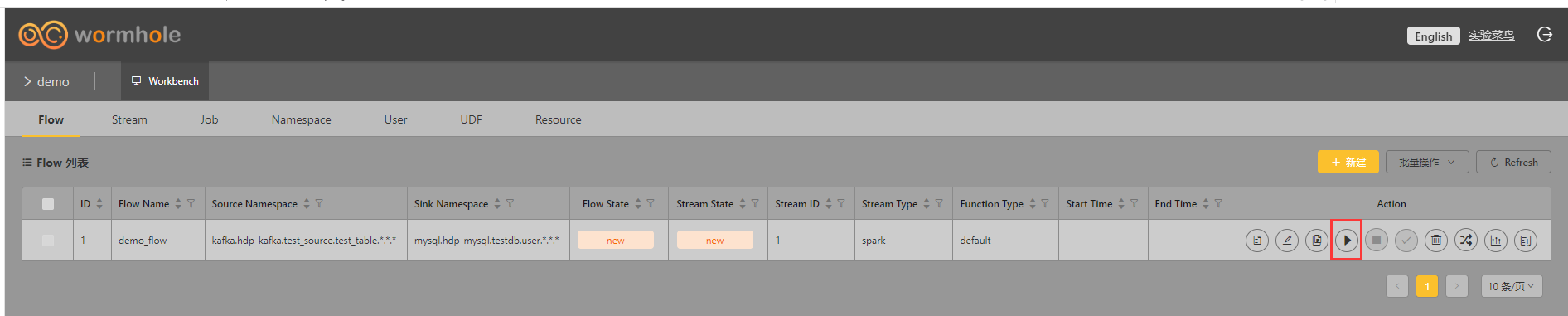

注意:Flow suspending状态代表挂起状态,标识Flow信息已注册到Stream中,Stream目前处于非 running状态。Stream状态正常后Flow状态会自动切换到running或failed状态
6、启动Stream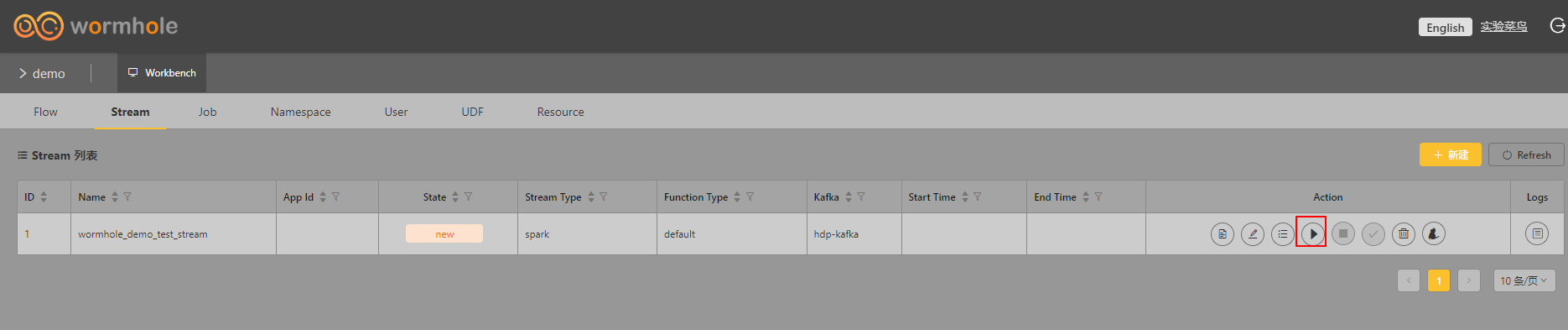
启动时需要设置offset:
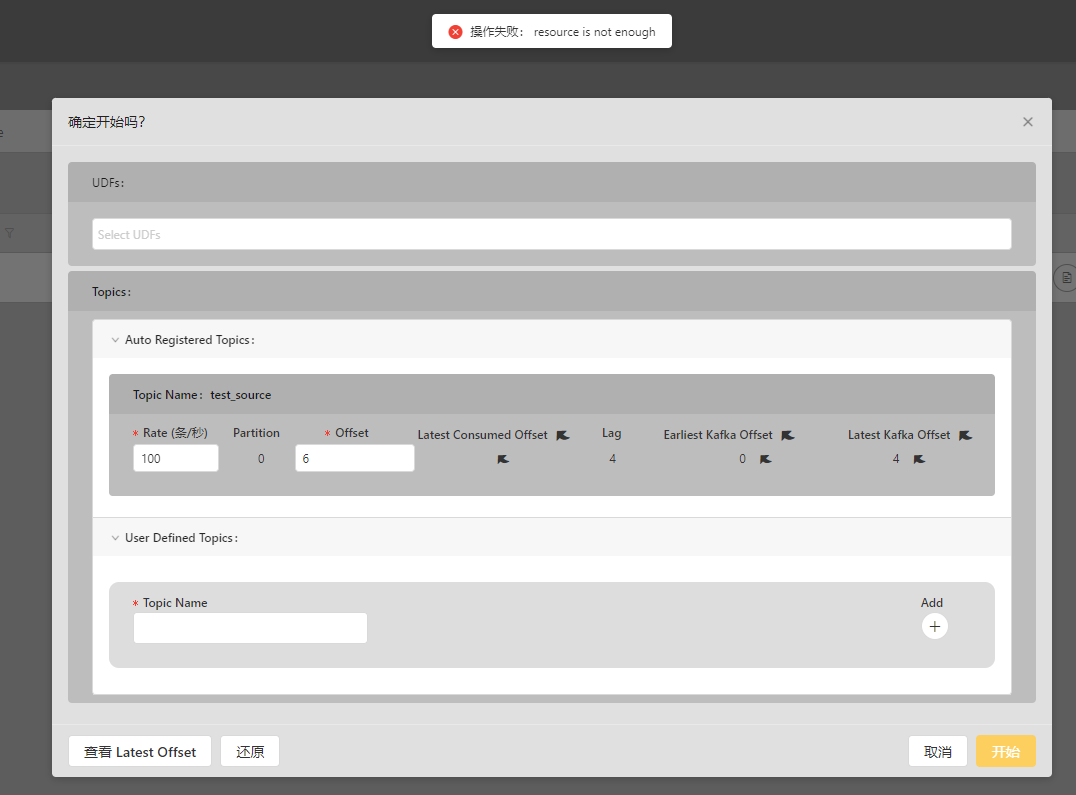
奈何我一直显示资源不足,可能真的因为个人的电脑不给力了,跑不动了。我也尝试个虚拟机加大内存,好像并没有什么用
查看日志
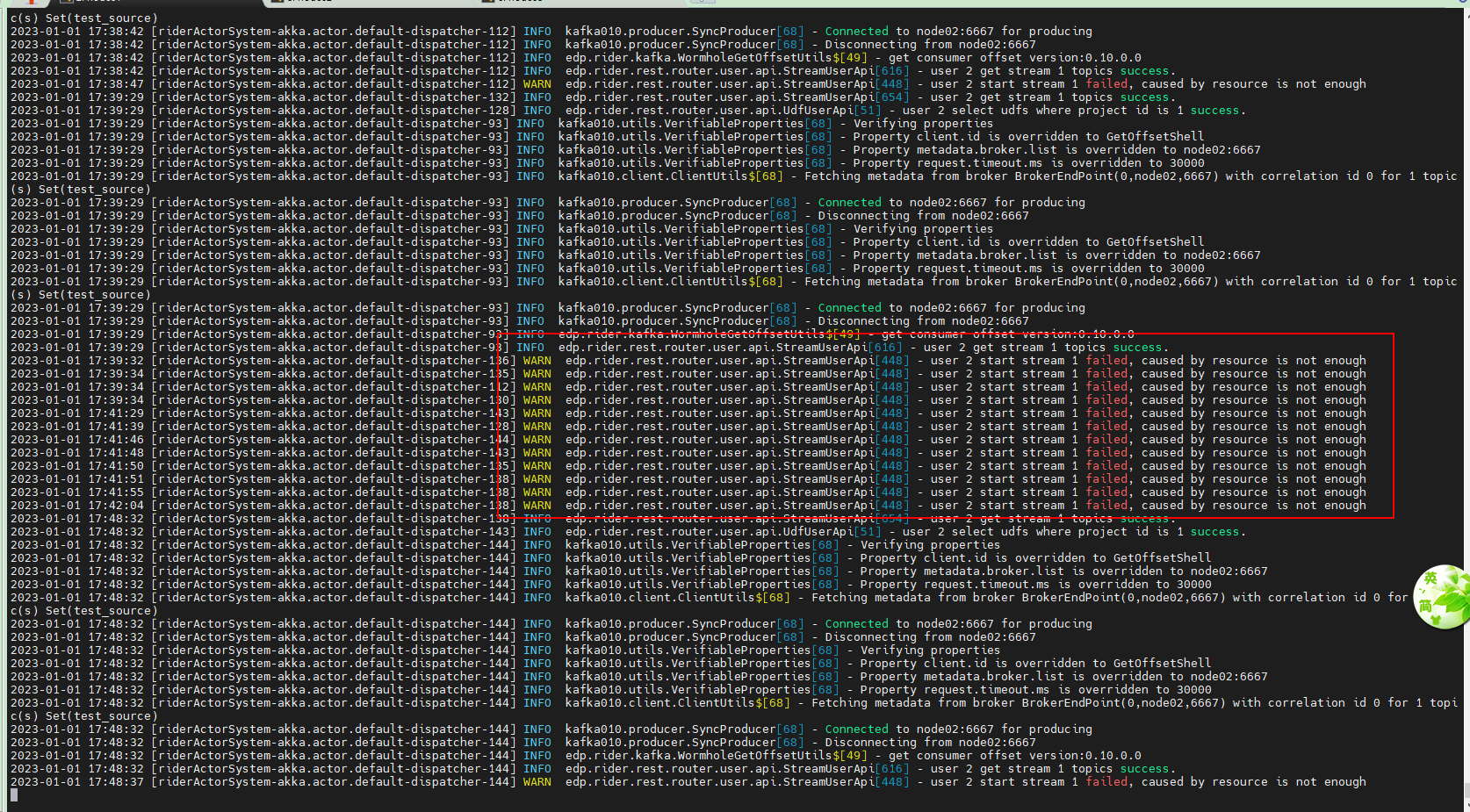
如果大家不存在这个问题,启动完stream后,就像前面的 创建source topic 与模拟数据 这一步生成一些模拟数据
登录kafka里面插入一些数据,
参考命令:
[root@hadoop002 bin]# ./kafka-console-producer.sh --broker-list hadoop002:6667 --topic test_source --property "parse.key=true" --property "key.separator=@@@"
>data_increment_data.kafka.hdp-kafka.test_source.test_table.*.*.*@@@{"id": 2, "name": "test1", "phone":"18074546423", "city": "Shanghai", "time": "2017-12-22 10:00:00"}
最后登录mysql检查数据是否过来:
mysql -u root -p
select * from testdb.user;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号