
5.DBus学习-2
1、编译DBus源代码
DBus本身是一个前后端分离的maven多模块项目,前端基于React,后端基于SpringCloud全家桶 。
到 https://github.com/BriData/DBus 拉取源码

我本地已经安装好了
通过git工具拉取代码到本地
git clone https://github.com/BriData/DBus.git

通过idea打开项目
先编译后端代码
在dbus-commons/pom.xml 中,需要在占位符处引入 mysql和 oracle相关包
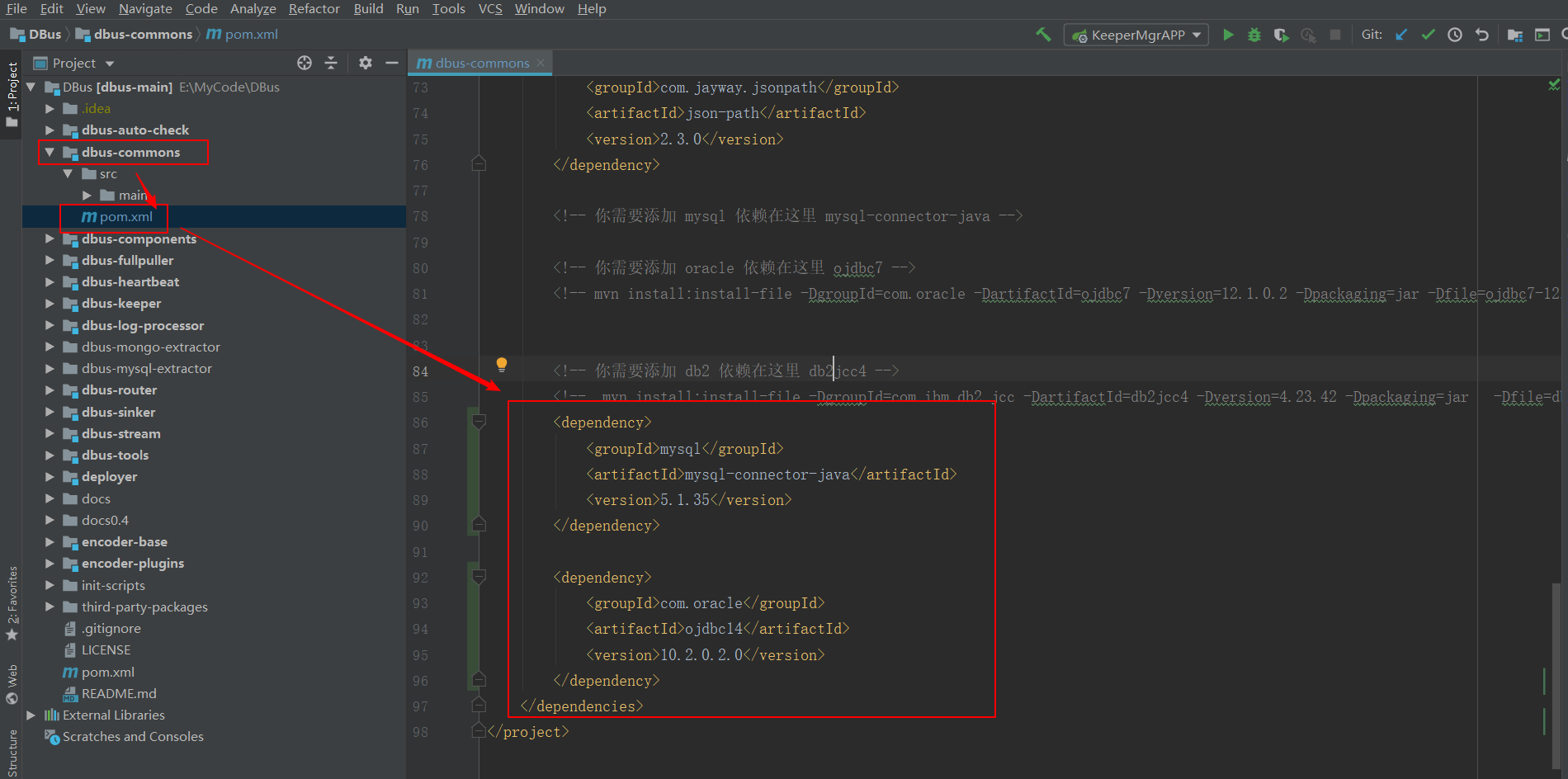
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.35</version>
</dependency>
<dependency>
<groupId>com.oracle</groupId>
<artifactId>ojdbc14</artifactId>
<version>10.2.0.2.0</version>
</dependency>
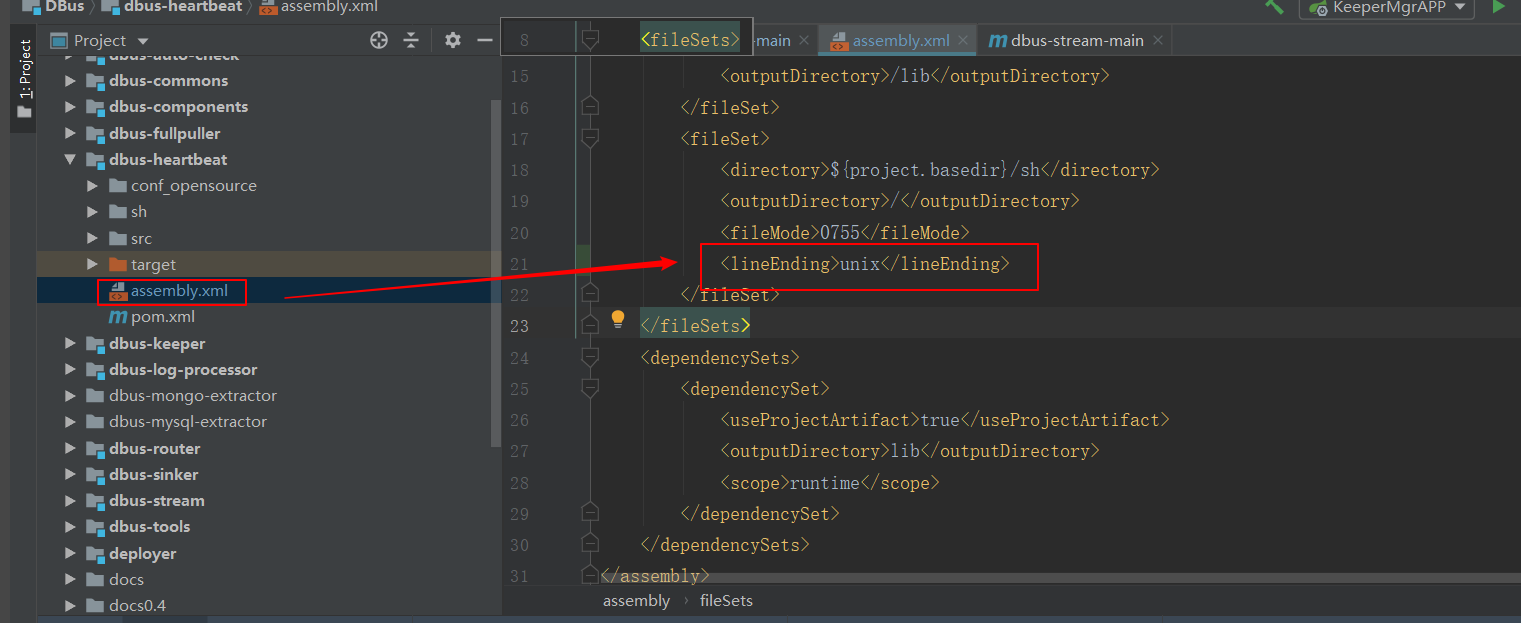
修改依赖组件的版本号
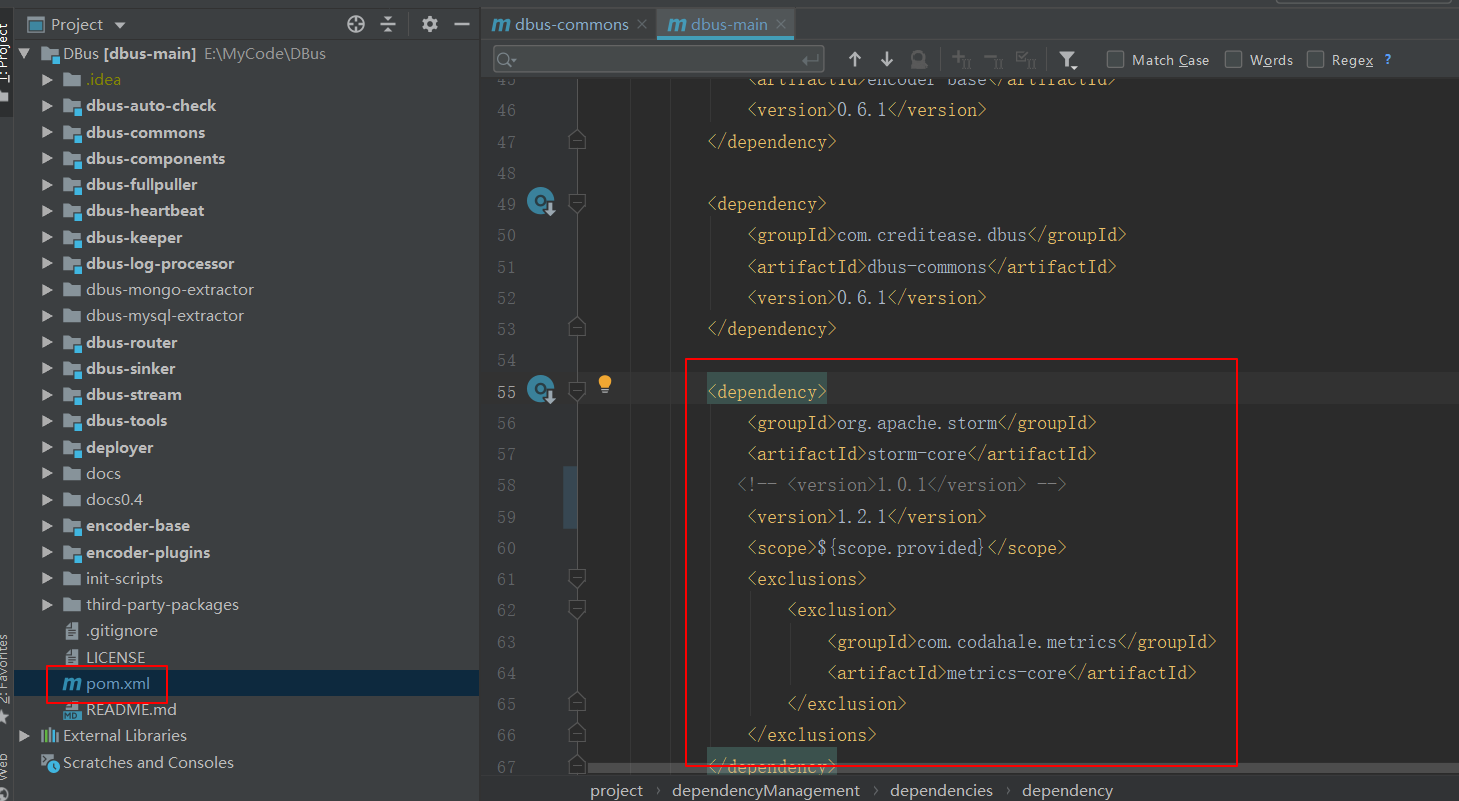
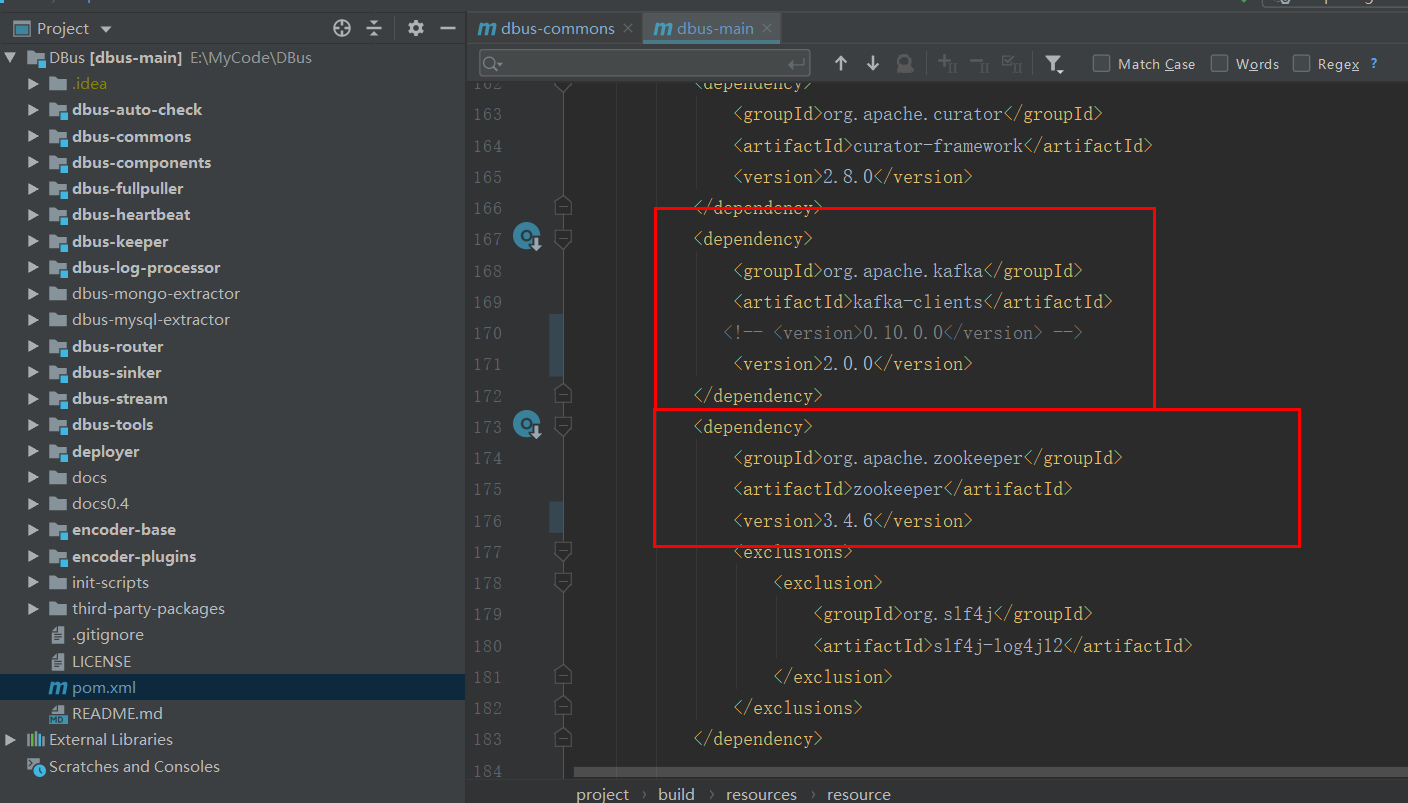
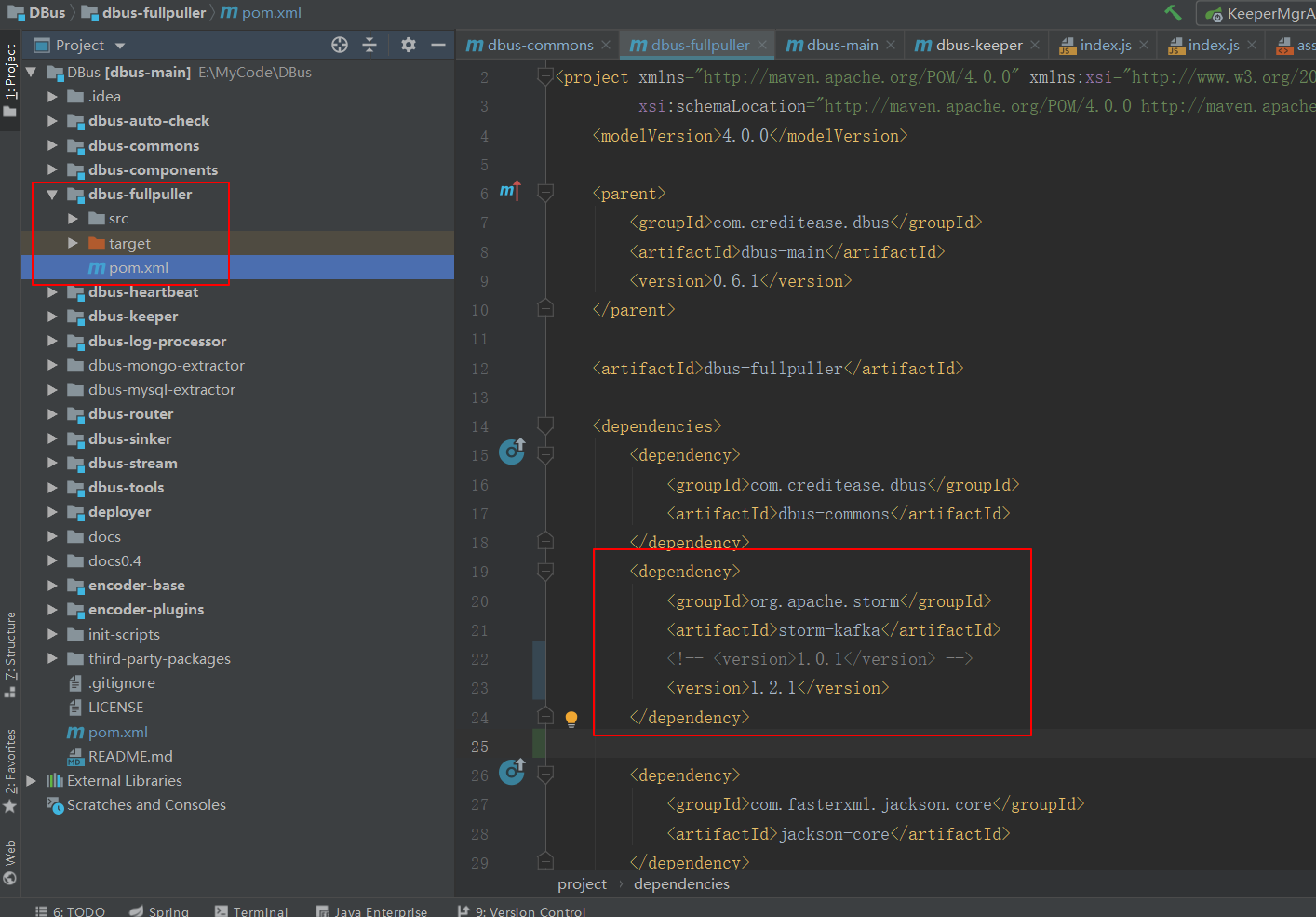
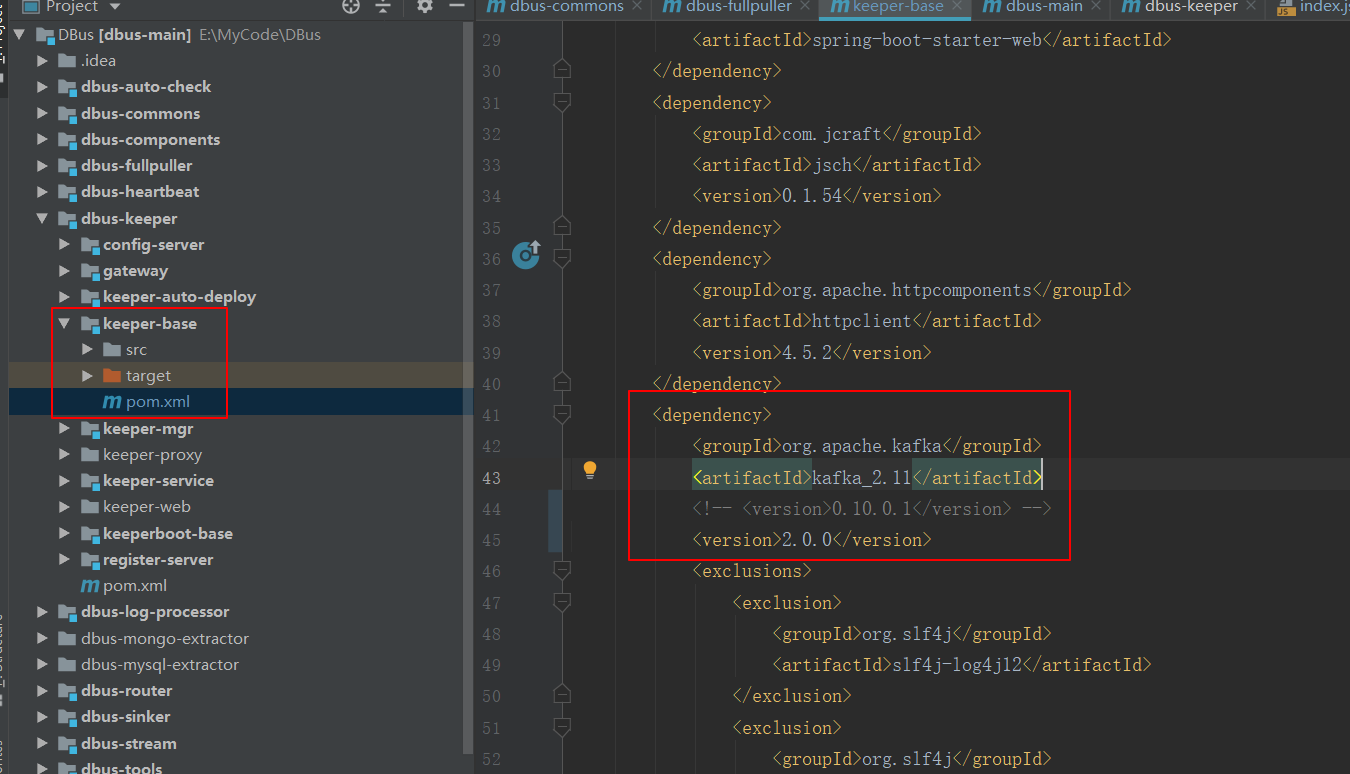
修改
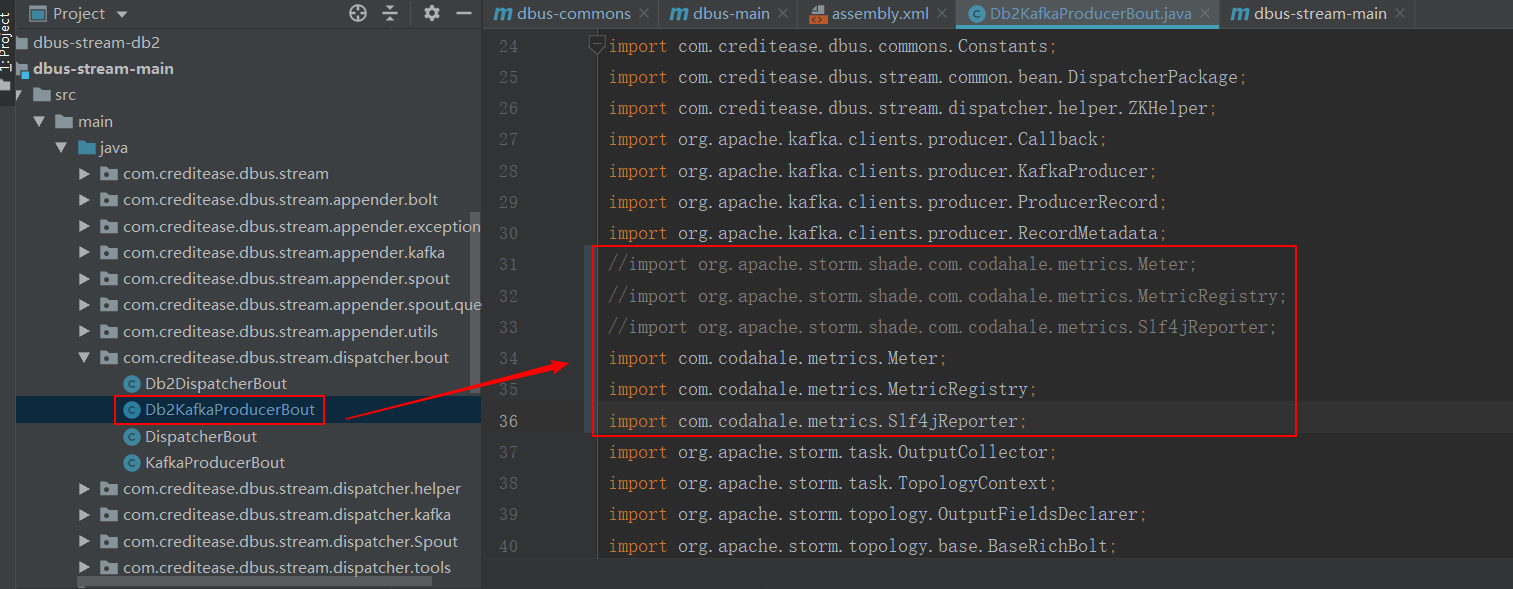
dbus-main是总体工程,其中encoder-base、 dbus-commons等一些模块是公共模块,会被其他引用。
所以,推荐直接在dbus-main工程上使用mvn clean package命令进行编译。
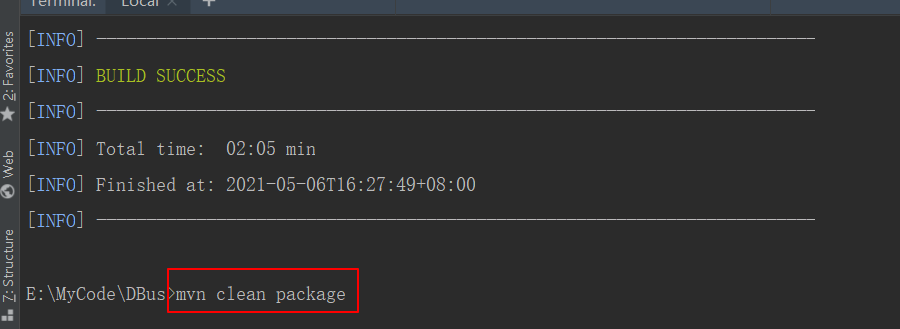
编译完成后,DBus/deployer/target目录下的deployer-0.6.1.zip就是最终的部署文件
前端代码编译
使用淘宝NPM镜像
npm install -g cnpm --registry=https://registry.npm.taobao.org
前端编译
修改源码:
# (1) 文件:DBus/dbus-keeper/keeper-web/app/containers/Project/route/index.js,确保目录Project首字母P是大写,源码中有几行是project // 导入自定义组件 # 注意,确保第一行import的路径为'@/app/containers/App' import App from '@/app/containers/App' import TopologyWrapper from '@/app/containers/Project/TopologyWrapper' import TableWrapper from '@/app/containers/Project/TableWrapper' import SinkWrapper from '@/app/containers/Project/SinkWrapper' import UserWrapper from '@/app/containers/Project/UserWrapper' import ResourceWrapper from '@/app/containers/Project/ResourceWrapper' import FullpullWrapper from '@/app/containers/Project/FullpullWrapper' import MonitorWrapper from '@/app/containers/Project/MonitorWrapper' import UserKeyDownloadWrapper from '@/app/containers/Project/UserKeyDownloadWrapper'
# (2) 文件:DBus/dbus-keeper/keeper-web/app/components/index.js,确保目录common是小写,源码中有几行是Common // common 公共无状态组件 export Bread from './common/Bread' export Navigator from './common/Navigator' export Header from './common/Header' export Foot from './common/Foot' export OperatingButton from './common/OperatingButton' export FileTree from './common/FileTree'
# (3) 将DBus/dbus-keeper/keeper-web/app/containers/Project目录下的几个js文件的名称首字母改成大写 [admin@hdp01 Project]$ mv resourceWrapper.js ResourceWrapper.js [admin@hdp01 Project]$ mv tableWrapper.js TableWrapper.js [admin@hdp01 Project]$ mv topologyWrapper.js TopologyWrapper.js
进入DBus\dbus-keeper\keeper-web下,在执行如下命令
cnpm install
编译
cnpm run build
编译成功后,在keeper-web生成了build目录,整个目录都是我们需要的前端文件
2、基础软件安装部署
在各个节点安装ZIP
sudo yum -y install zip
在安装软件之前,我们登录Ambari把用不到的服务先关掉,以节约
来。如下图所示,先保留Zookeeper和Ambari Metrics服务即可:
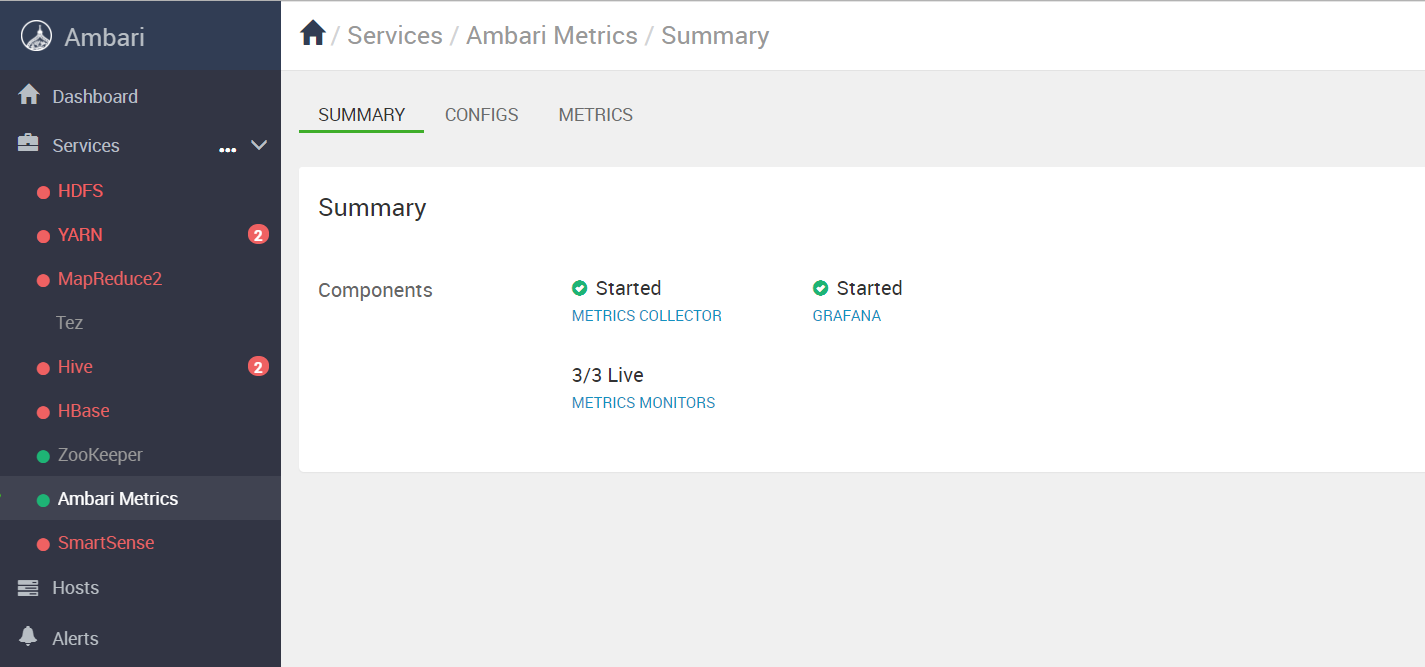
直接使用HDP3.1自带的Zookeeper,版本3.4.6正好合适,之前就安装好了这里保持不动,处于启动状态即可。
安装Kafka
生产上我们起码要部署三个节点的Kafka集群,这里我们就在node02上部署一个单点,
所有的部署方法、操作等跟部署集群没有差别。

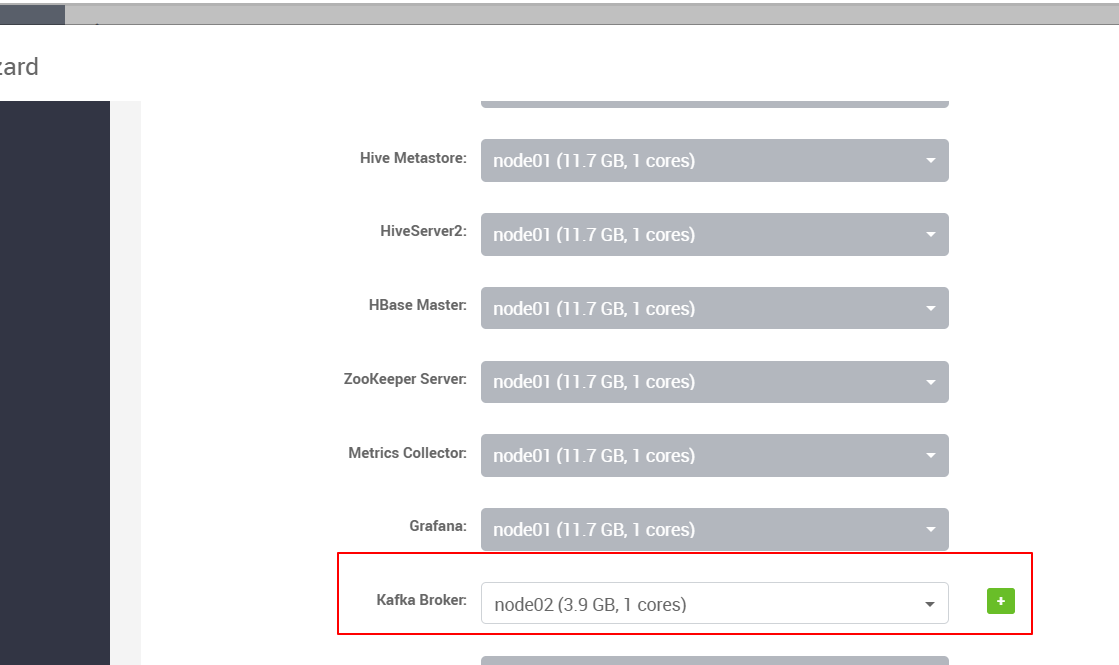
后续步骤就一路下一步。
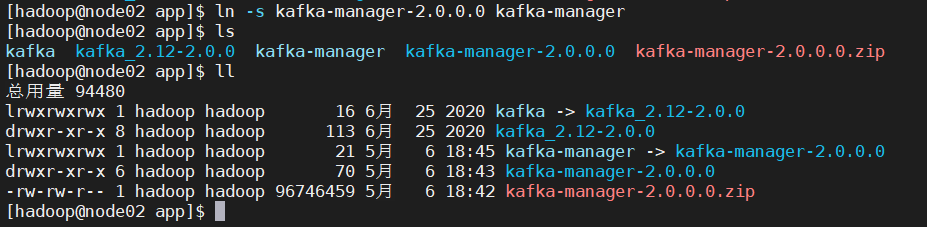
上传安装包到node02节点

解压安装包
unzip kafka-manager-2.0.0.0.zip ln -s kafka-manager-2.0.0.0 kafka-manager
创建软链接
配置环境变量:
sudo vim /etc/profile
末尾添加:
export KAFKA_MANAGER_HOME=/home/hadoop/app/kafka-manager
export PATH=$KAFKA_MANAGER_HOME/bin:$PATH
使环境变量生效
source /etc/profile
配置kafka-manager

修改如下配置项:
kafka-manager.zkhosts="node01:2181" basicAuthentication.enabled=true basicAuthentication.password="admin"
启动kafka-manager:
cd /home/hadoop/app/kafka-manager
#前台启动 kafka-manager -Dhttp.port=9999
#也可以后台启动 nohup $KAFKA_MANAGER_HOME/kafka-manager -Dhttp.port=9999 > kafka-managernohup.log 2>&1 &
访问 http://node02:9999/ 前提是配置好hosts文件
用户名 admin
密码admin
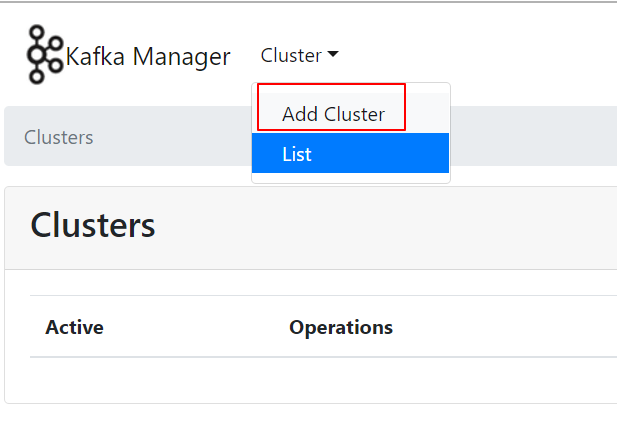
接下来添加一个kafka集群到kafka-manager

其余选项根具体是修改,不需要修改的保持默认即可,直接点击保存即可,至此kafka-manager就安装
好了,一个Kafka-manager可以管理多个集群。
保存后:
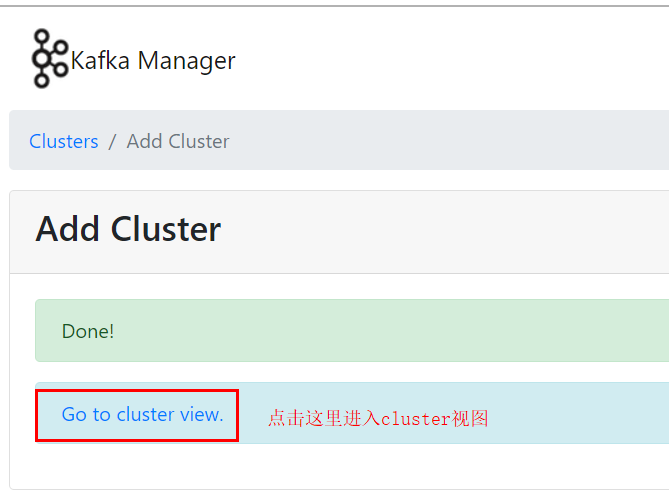
此时,Kafka-manager是获取不到Kafka Broker的相关信息的,cluster视图如下:
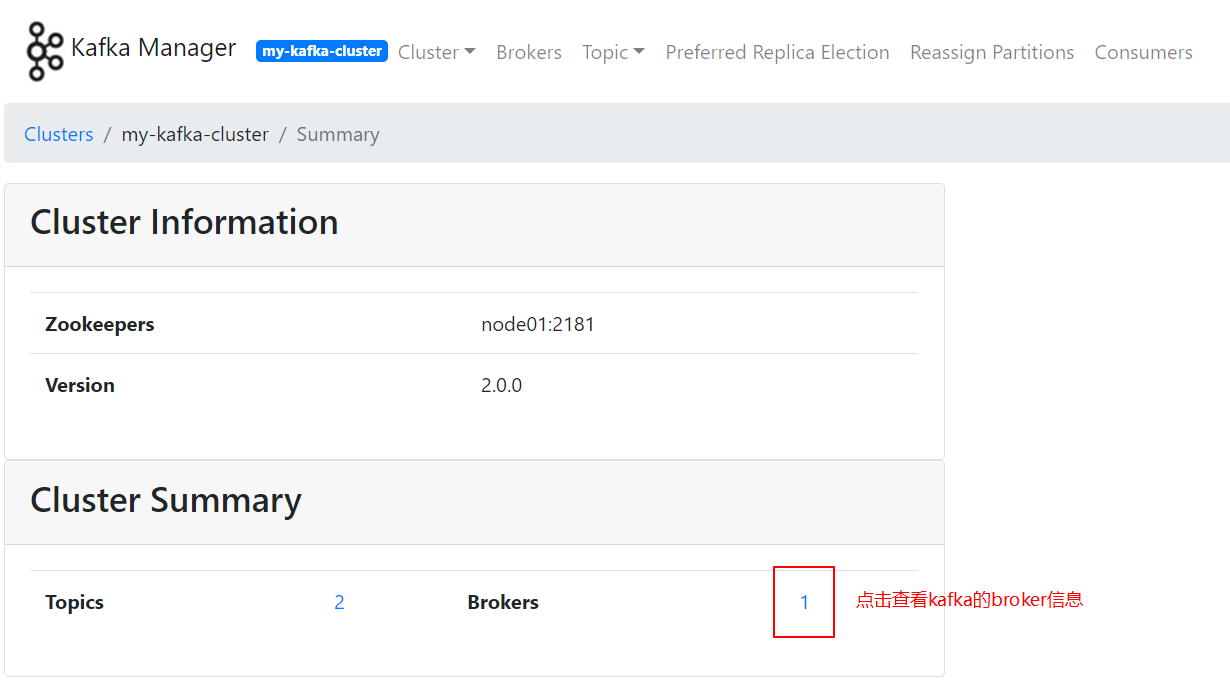
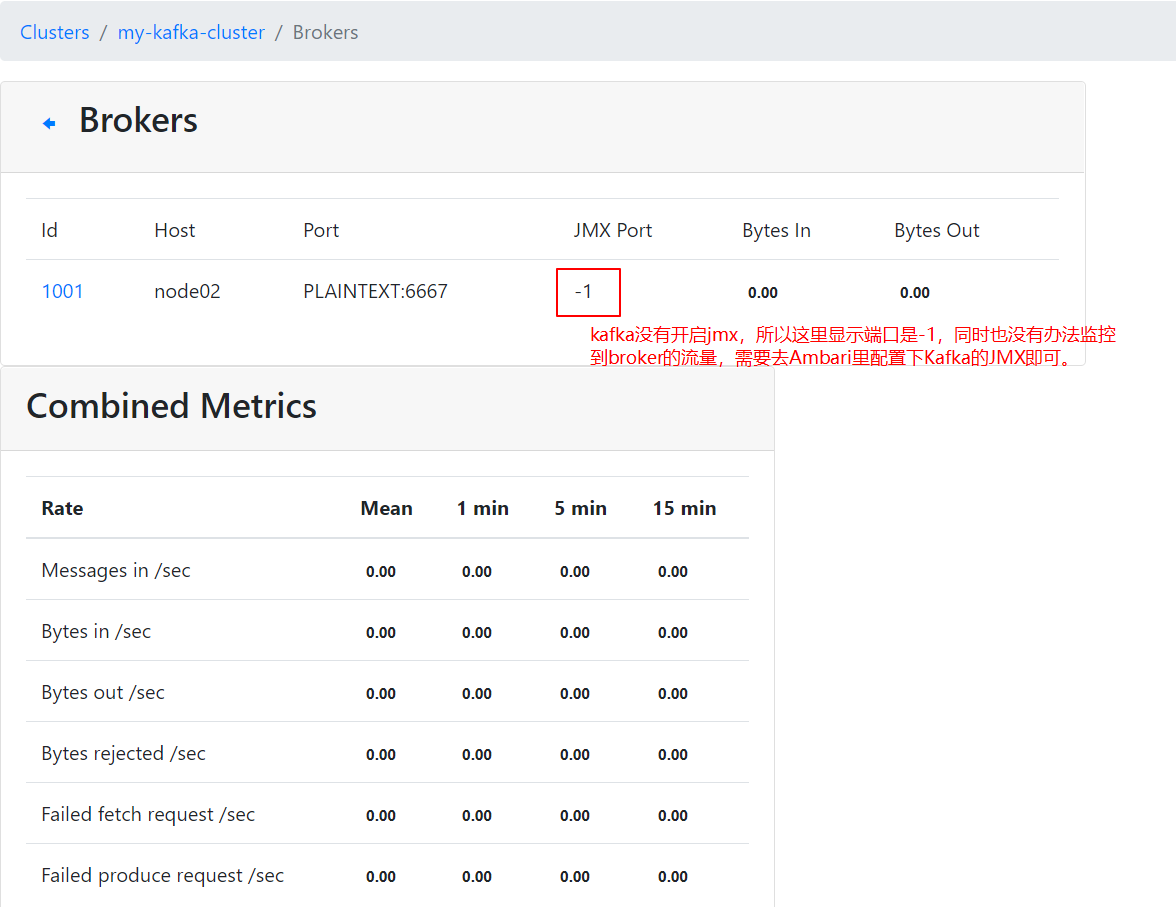
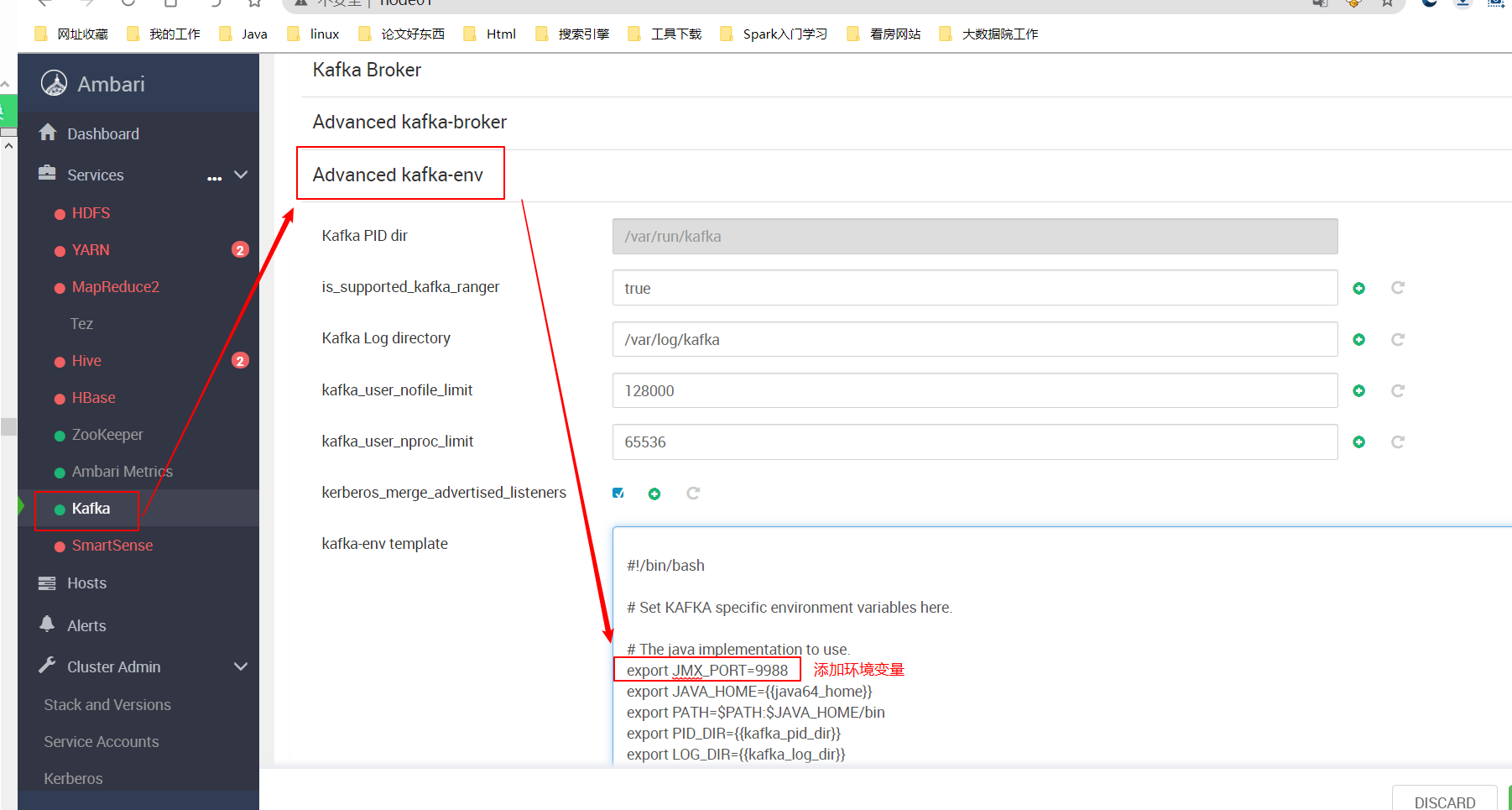
开启kafka的JMX
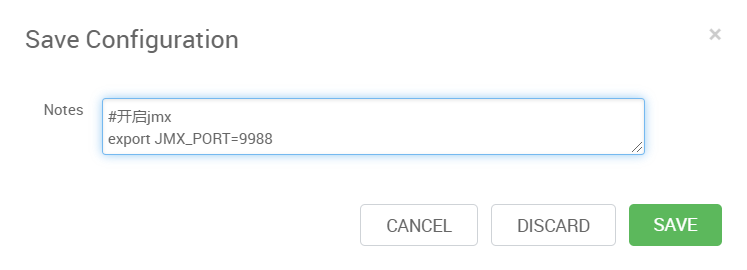
保存的时候,记得输入描述信息,这是个好习惯:
改完一定要重启kafka Broker才能生效:
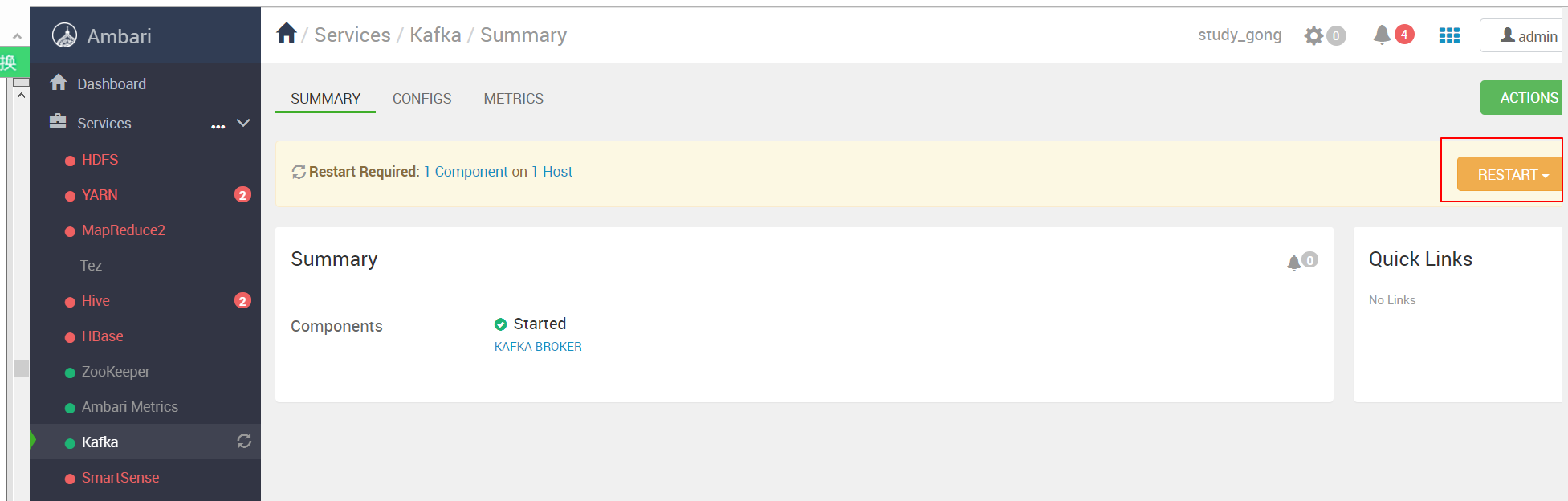
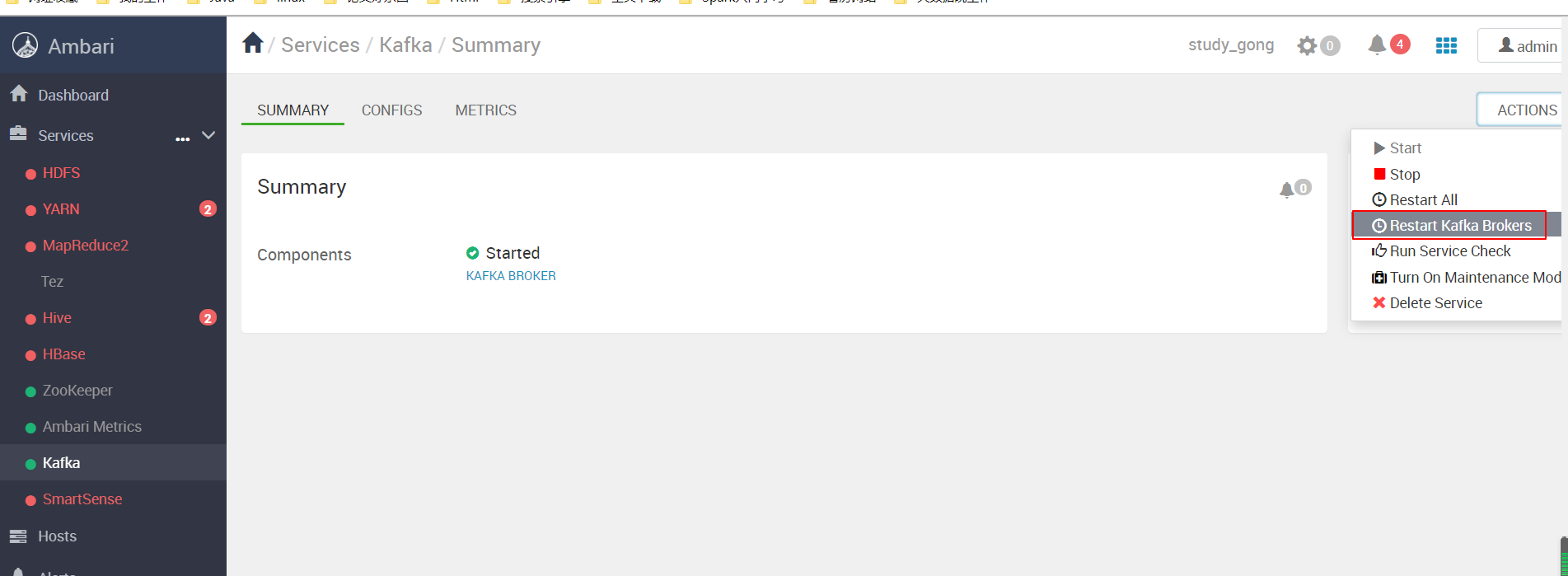
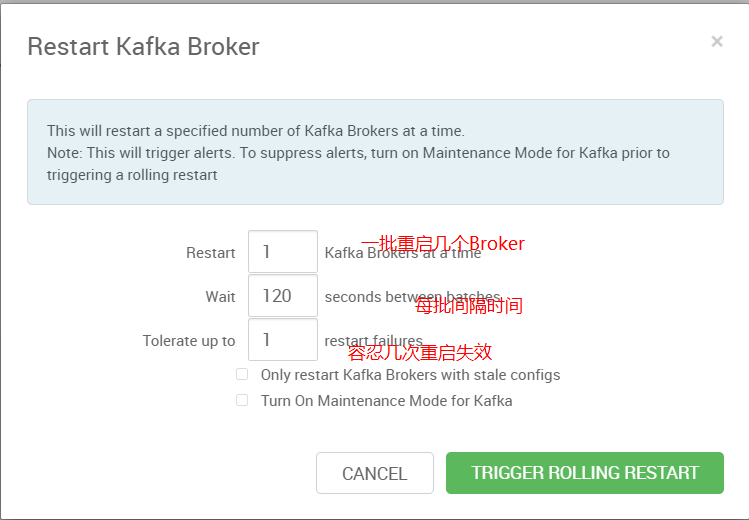
我们可以看到Ambari考虑得比较全面,在生产环境肯定不能随意整体重启,肯定是滚动重启的。
安装Storm
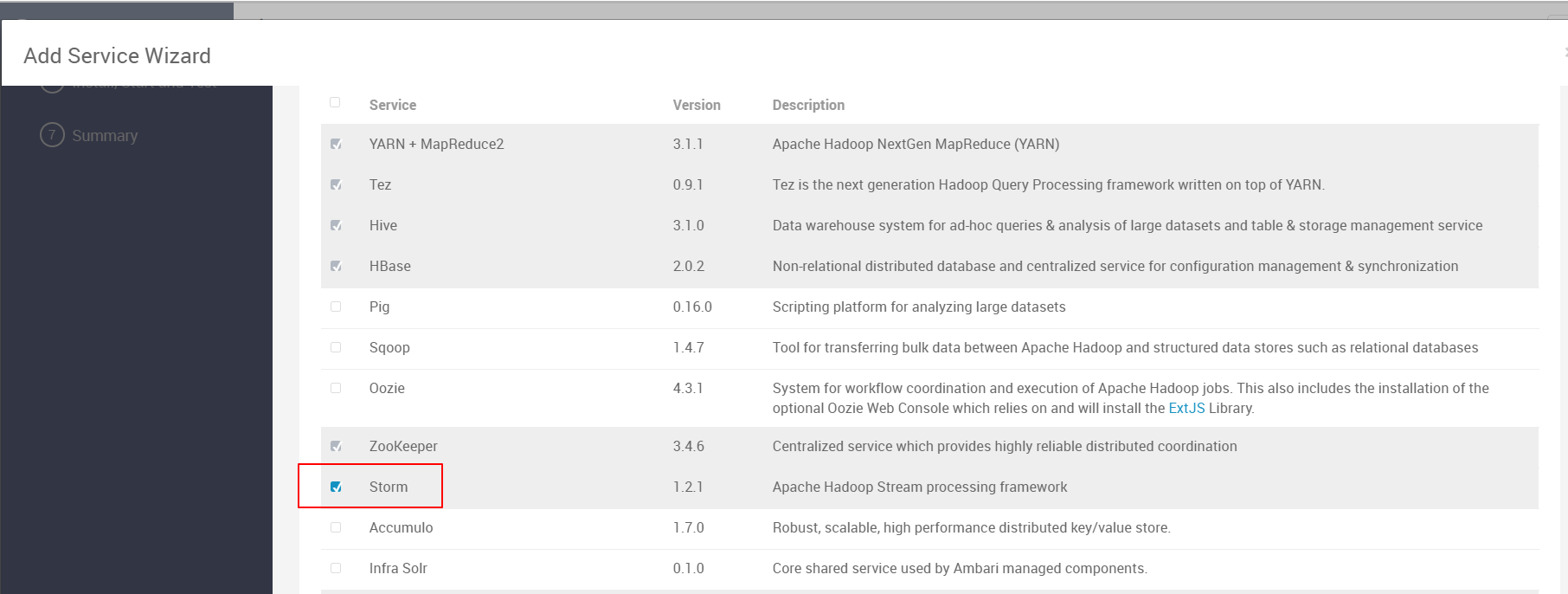
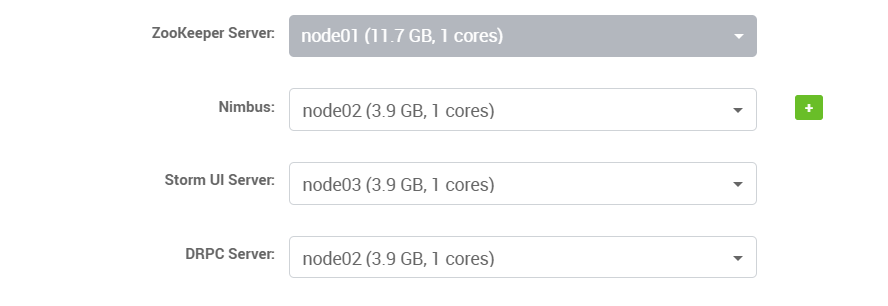
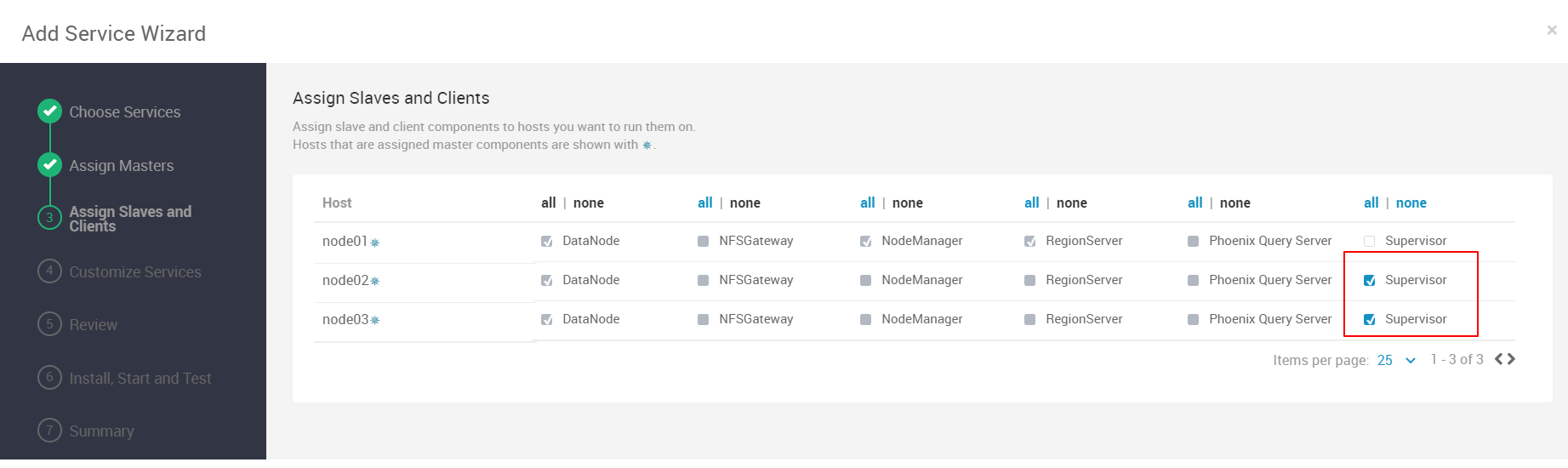
基于步骤基本就是下一步。
安装InfluxDB
我们将infludb安装到node03
wget https://dl.influxdata.com/influxdb/releases/influxdb-1.7.6.x86_64.rpm
安装
sudo yum -y localinstall influxdb-1.7.6.x86_64.rpm
启动
sudo systemctl start influxdb #启动influxdb
sudo systemctl status influxdb #查看状态
sudo systemctl enable influxdb #开启开机启动
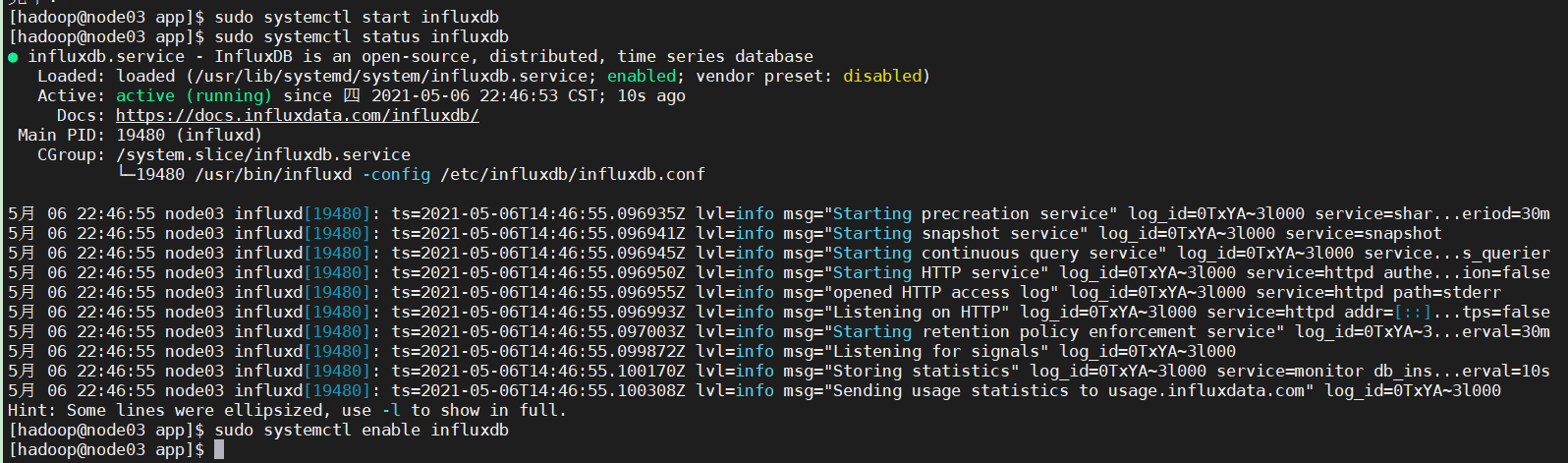
初始化配置
登录influxdb

执行如下命令:
#执行初始化脚本 create database dbus_stat_db use dbus_stat_db CREATE USER "dbus" WITH PASSWORD 'dbus' #配置监控数据的保留时间,实际生产时根据自己的运维要求来定 ALTER RETENTION POLICY autogen ON dbus_stat_db DURATION 15d exit
安装Grafana
Ambari使用的Grafana根DBus依赖的版本不一样,需要单独安装以便于导入Dashboard
我们安装在node02上:
wget https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana-4.2.0-1.x86_64.rpm
sudo yum -y localinstall grafana-4.2.0-1.x86_64.rpm
配置文件:
sudo vim /etc/grafana/grafana.ini
我们保持默认,启动即可:
sudo systemctl start grafana-server sudo systemctl status grafana-server sudo systemctl enable grafana-server.service #设置开机启动

登录Grafana:
访问 http://node02:3000/login

默认的用户名密码是admin/admin,登录即可。
生成GrafanaToken
Dbus使用Grafana展示数据线监控信息。需要提供Grafana Token进行监控模板的初始化。
点击打开API Keys管理页面:
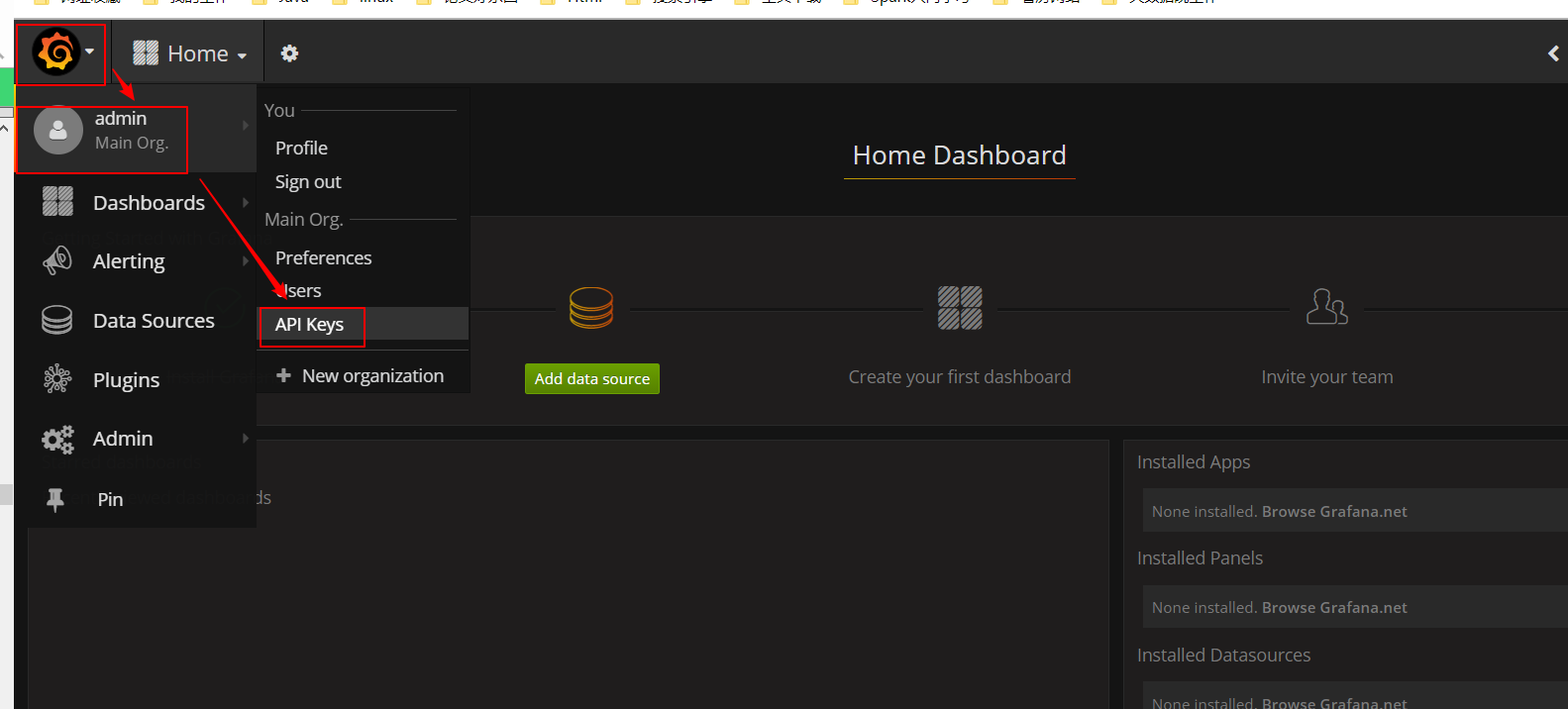
添加Key
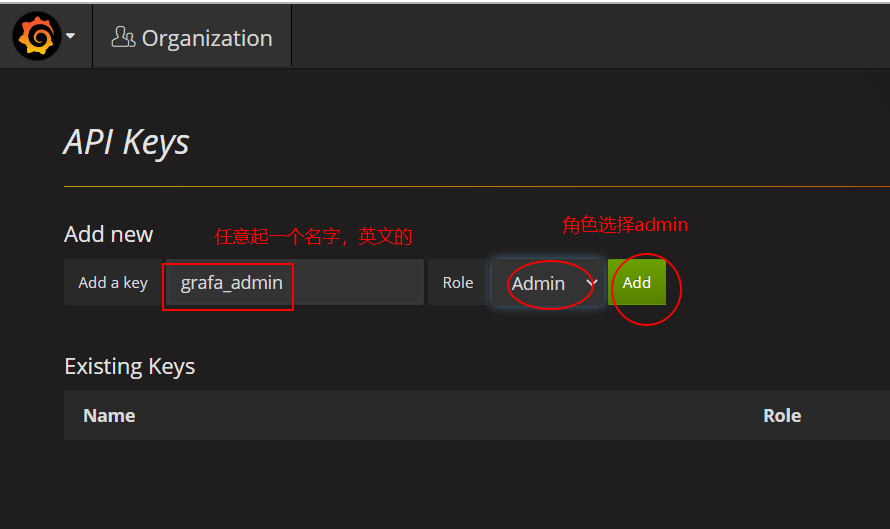
在跳出来的页面拷贝Key并并保存好:
eyJrIjoieFhwSHcwMTd4NE94bkVGa0taTFVyWVNsZHdnUlZhRWUiLCJuIjoiZ3JhZmFfYWRtaW4iLCJpZCI6MX0=
curl -H "Authorization: Bearer eyJrIjoieFhwSHcwMTd4NE94bkVGa0taTFVyWVNsZHdnUlZhRWUiLCJuIjoiZ3JhZmFfYWRtaW4iLCJpZCI6MX0=" http://node02:3000/api/dashboards/home
创建MySQL dbusmgr库
DBus的Web管理模块就是一个web程序,它需要用到Mysql数据库,我们复用Ambari所用的node01
上安装的MySQL即可,但是需要创建库、用户和表。
在node01上登录MySQL(密码是root)
mysql -u root -p
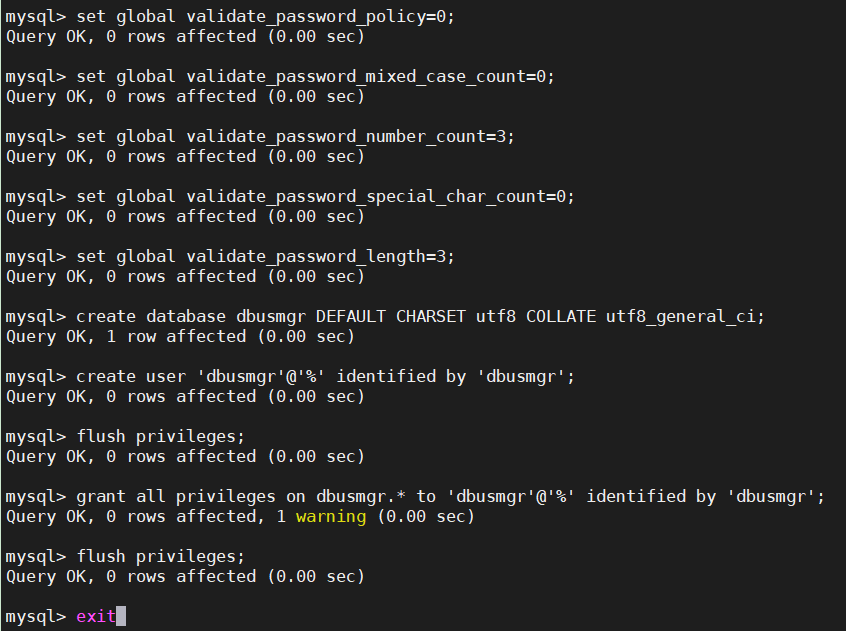
执行如下命令:
set global validate_password_policy=0; set global validate_password_mixed_case_count=0; set global validate_password_number_count=3; set global validate_password_special_char_count=0; set global validate_password_length=3; create database dbusmgr DEFAULT CHARSET utf8 COLLATE utf8_general_ci; create user 'dbusmgr'@'%' identified by 'dbusmgr'; flush privileges; grant all privileges on dbusmgr.* to 'dbusmgr'@'%' identified by 'dbusmgr'; flush privileges; exit
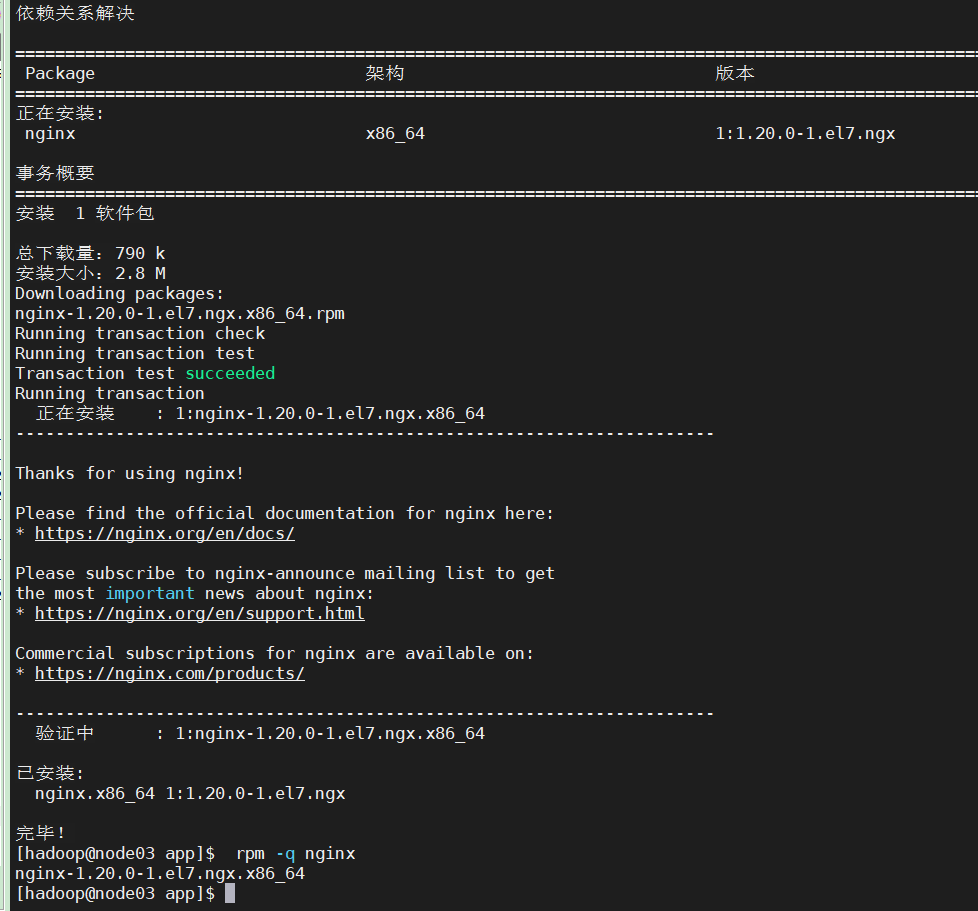
安装Nginx
我们在node03上安装Nginx
安装依赖环境,安装命令:
sudo yum -y install gcc pcre-devel zlib-devel openssl openssl-devel
添加Nginx官方Yum源:
由于yum源中没有我们想要的nginx,那么我们就需要创建一个“/etc/yum.repos.d/nginx.repo”的文件,其实就是新增一个yum源。
sudo vim /etc/yum.repos.d/nginx.repo
然后将下面的内容复制进去:
[nginx] name=nginx repo baseurl=http://nginx.org/packages/centos/$releasever/$basearch/ gpgcheck=0 enabled=1
然后保存“/etc/yum.repos.d/nginx.repo”文件后,我们就使用yum命令查询一下我们的nginx的yum源配置好了没有。
sudo yum list |grep nginx

然后要安装我们的nginx就直接执行:
sudo yum -y install nginx
也可以查看一下是否安装完成:
rpm -q nginx
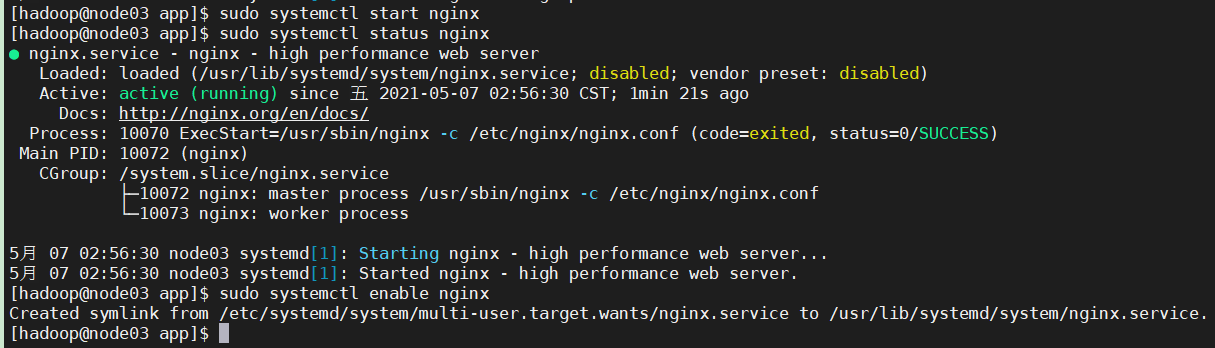
启动Nginx:
sudo systemctl start nginx
sudo systemctl status nginx
sudo systemctl enable nginx #设置开机启动
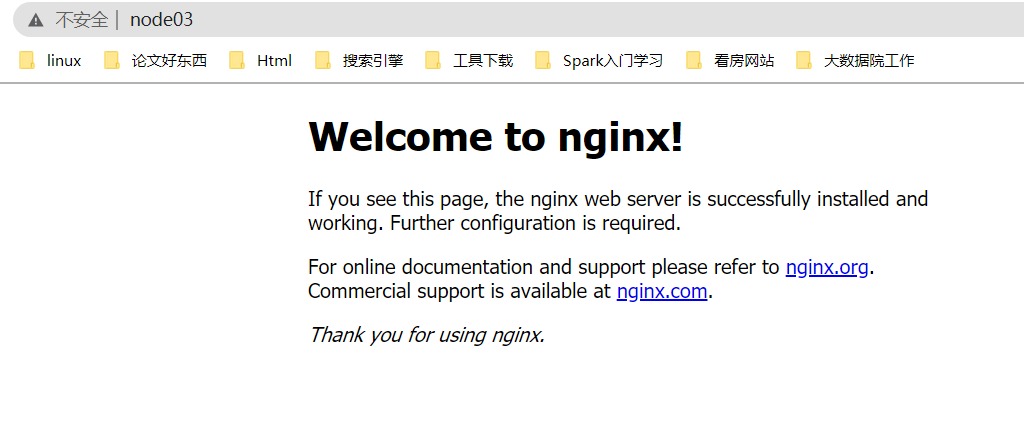
访问Nginx:
http://node03/
Nginx配置信息说明
yum方式安装Nginx相关配置信息如下:
nginx 全局配置文件
/etc/nginx/nginx.conf
网站默认站点配置
/etc/nginx/conf.d/default.conf
自定义 nginx 站点配置文件存放目录
/etc/nginx/conf.d/
网站文件存放默认位置(Welcome to nginx 页面)
/usr/share/nginx/html
3、DBus安装配置
修改Storm目录权限(我安装在node02)
sudo chmod o+w /usr/hdp/3.1.4.0-315/storm/
DBus安装过程中会通过hadoop用户远程把Storm的拓扑程序拷贝到该目录下,所以得有写权限。
下载DBus-Keeper
上传压缩包,并解压

unzip deployer-0.6.1.zip
Nginx配置
sudo cp nginx.conf /etc/nginx/

上传build到Nginx的安装目录下

来源自这里
重启Nginx:
sudo systemctl restart nginx
修改Dbus-Keeper启动配置

####################################################################################################### # 是否使用dbus提供的配置中心,默认开启,目前仅支持spring cloud配置中心 config.server.enabled=true # 如果config.server.enabled=false,请配置以下地址 #spring.cloud.config.profile=环境名必须修改 release #spring.cloud.config.label=分支名必须修改 master #spring.cloud.config.uri=必须修改 http://localhost:19090 # 配置中心端口,端口号可用则需修改 config.server.port=19090 ####################################################################################################### # 是否使用dbus提供的注册中心,默认开启 register.server.enabled=true # 如果register.server.enabled=false,请配置以下地址 #register.server.url=必须修改 http://localhost:9090/eureka/ # 注册中心端口,端口号可用则需修改 register.server.port=9090 ####################################################################################################### # 暂不支持使用自己的网关 # 网关端口,端口号可用则需修改 gateway.server.port=5 # dbus控制台端口,端口号可用则需修改 mgr.server.port=8901 # dbus数据库服务端口,端口号可用则需修改 service.server.port=18901 # mysql管理库相关配置 spring.datasource.driver-class-name=com.mysql.jdbc.Driver spring.datasource.url=jdbc:mysql://node01:3306/dbusmgr?characterEncoding=utf-8 spring.datasource.username=dbusmgr spring.datasource.password=dbusmgr ####################################################################################################### # dbus集群列表,dbus web所在机器必须能免密访问该列表所有机器 dbus.cluster.server.list=node01,node02,node03 # dbus集群统一免密用户 dbus.cluster.server.ssh.user=hadoop # dbus集群统一免密端口号 dbus.cluster.server.ssh.port=22 # ZK地址 zk.str= node01:2181 # kafka地址 bootstrap.servers=node02:6667 bootstrap.servers.version=2.0.0 # influxdb外网地址(域名) influxdb.web.url=http://node03:8086 # influxdb内网地址,不区分内外网influxdb_url_web和influxdb_url_dbus配置一样即可 influxdb.dbus.url=http://node03:8086 # grafana外网地址(域名) grafana.web.url=http://node02:3000 # grafana内网地址,不区分内外网igrafana_url_web和grafana_url_dbus配置一样即可 grafana.dbus.url=http://node02:3000 # grafana管理员token grafana.token=eyJrIjoiZTQ3Zk9lUnR3Q3N4OThvQlA2bTZoWWlOMlJtN0dMQm4iLCJuIjoiZ3JhZmFfYWRtaW4iLCJpZCI6MX0= # storm nimbus leader所在机器,这里只需配置leader机器,仅一台 storm.nimbus.host=node02 # storm nimbus根目录 storm.nimbus.home.path=/usr/hdp/current/storm-client/ # storm worker日志根目录,默认storm.nimbus.home.path下的logs目录 storm.nimbus.log.path=/usr/hdp/current/storm-client/logs/ # stormUI url storm.rest.url= http://node03:8744/api/v1 # storm在zookeeper的根节点 storm.zookeeper.root=/storm # 心跳程序自动部署目标机器,多个机器逗号隔开(半角逗号) heartbeat.host=node02,node03 # 心跳程序自动部署根目录 heartbeat.path=/home/hadoop/app/dbus/heartbeat ####################################################################################################### # nginx所在机器ip nginx.ip=172.16.25.13 # nginx.config配置的listen端口号 nginx.port=8080
初始化jar包,此操作为替换jar包里面的配置文件 
可以看到报错了!
错误原因:
这个文件在Windows 下编辑过,在Windows下每一行结尾是\n\r,而Linux下则是\n,所以才会有 多出来的\r。
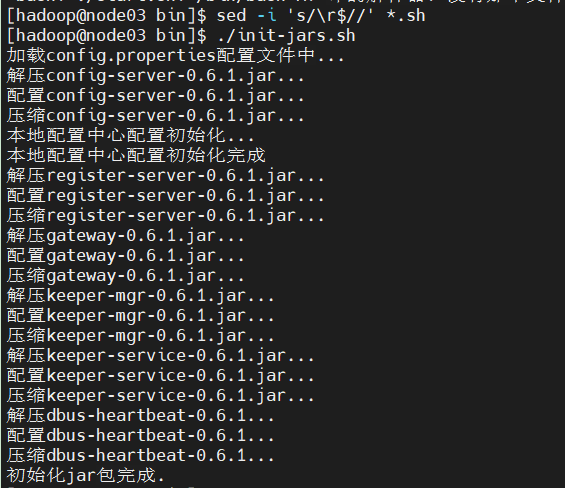
我们这样解决,在.sh脚本的目录下执行
sed -i 's/\r$//' *.sh
启动web
./start.sh

可以看到不能正常启动,我们需要手动创建logs目录

再次启动成功
修改nginx配置文件

#user nobody; worker_processes 1; #error_log logs/error.log; #error_log logs/error.log notice; #error_log logs/error.log info; #pid logs/nginx.pid; events { worker_connections 1024; } http { include mime.types; default_type application/octet-stream; client_max_body_size 2000M; keepalive_timeout 65; server { listen 8080; server_name localhost; #charset utf-8; #access_log logs/host.access.log main; location / { root /usr/share/nginx/html/build; index index.html index.htm; try_files $uri /index.html; add_header Cache-Control "private, no-store, no-cache, must-revalidate, proxy-revalidate"; } location /keeper/ { proxy_pass http://172.16.25.13:5090/v1/keeper/; } location /keeper-webSocket/ { proxy_pass http://172.16.25.13:8901/; proxy_read_timeout 60s; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "upgrade"; } } }
重启nginx
sudo systemctl restart nginx
访问地址:http://node03:8080/login
当然啦,这个时候是无法登录的,我们还需要全局初始化
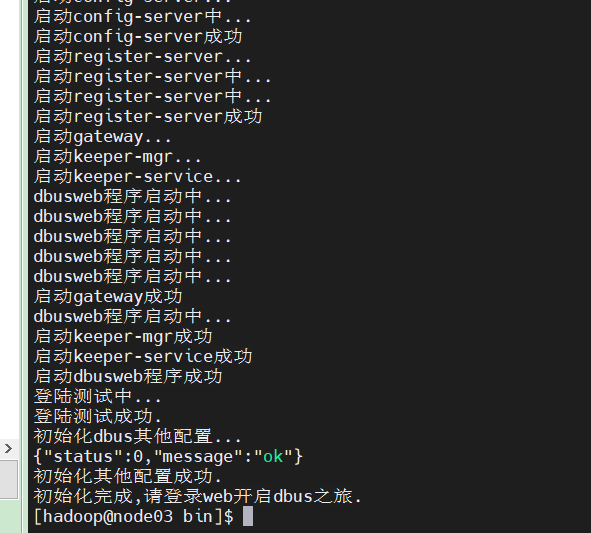
看到这个就表示初始化成功了
 车的
车的
这个时候就可以登录dbus了,超级管理员账号/密码 : admin/12345678
检查heartbeat
根据DBus-Keeper的初始化配置,它已经在node02和node03的/home/hadoop/app/dbus/下安装了
heartbeat,去检查下heartbeat进程在不在,如果不在的话用如下命令手工启动

nohup ./heartbeat.sh >/dev/null 2>&1 &
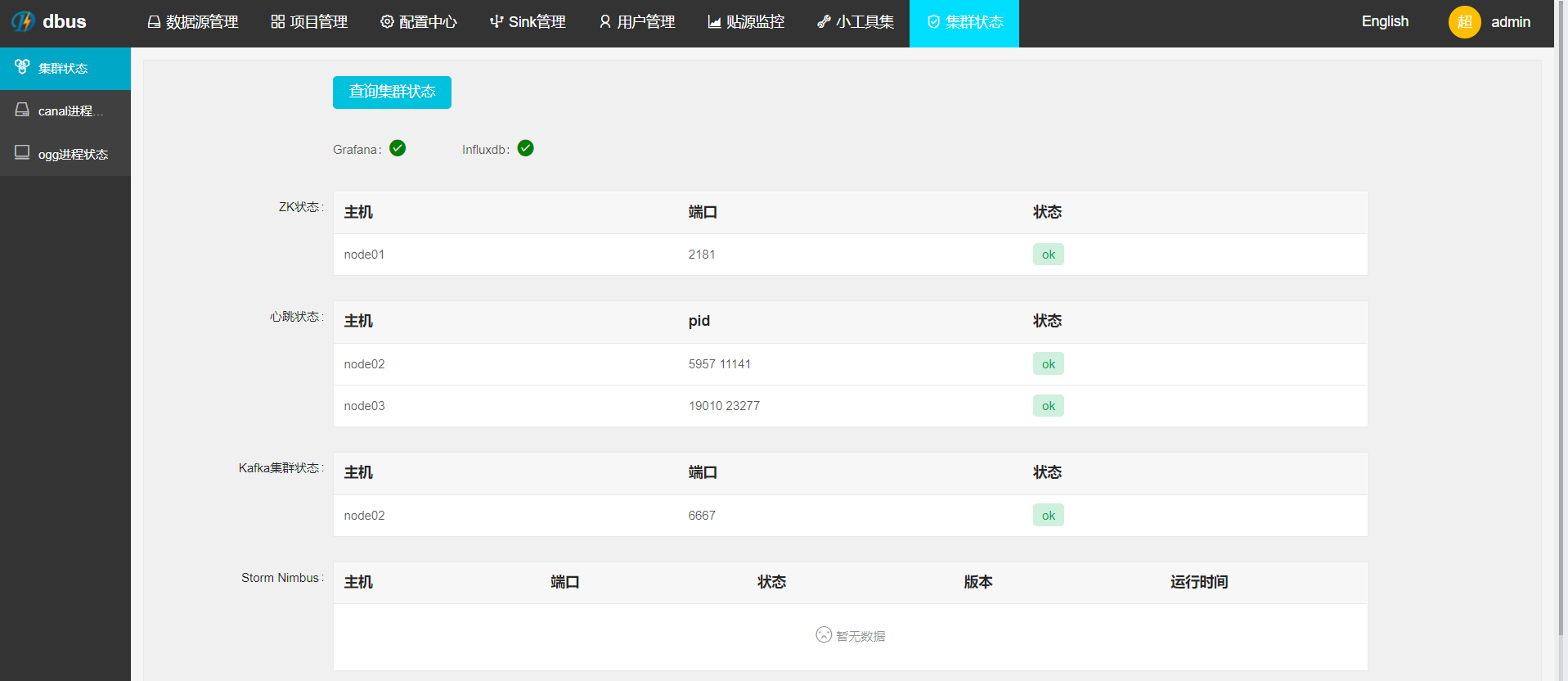
通过DBus-Keeper界面可以检查系统状态
检查表是否创建成功
mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | ambari | | dbusmgr | | hive | | mysql | | performance_schema | | sys | +--------------------+ 7 rows in set (0.00 sec) mysql> use dbusmgr; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> show tables; +--------------------------------------------+ | Tables_in_dbusmgr | +--------------------------------------------+ | t_avro_schema | | t_data_schema | | t_data_tables | | t_dbus_datasource | | t_ddl_event | | t_encode_columns | | t_encode_plugins | | t_fullpull_history | | t_meta_version | | t_name_alias_mapping | | t_plain_log_rule_group | | t_plain_log_rule_group_version | | t_plain_log_rule_type | | t_plain_log_rules | | t_plain_log_rules_version | | t_project | | t_project_encode_hint | | t_project_resource | | t_project_sink | | t_project_topo | | t_project_topo_table | | t_project_topo_table_encode_output_columns | | t_project_topo_table_meta_version | | t_project_user | | t_query_rule_group | | t_sink | | t_sinker_topo | | t_sinker_topo_schema | | t_sinker_topo_table | | t_storm_topology | | t_table_action | | t_table_meta | | t_topology_jar | | t_user | +--------------------------------------------+ 34 rows in set (0.00 sec)
停止web运行
./stop.sh

4、DBus采集MySQL数据原理

千万不要把我们DBus用的MySQL数据库和我们要采集数据的MySQL数据库混为一谈,在生产上一般是
这样的:
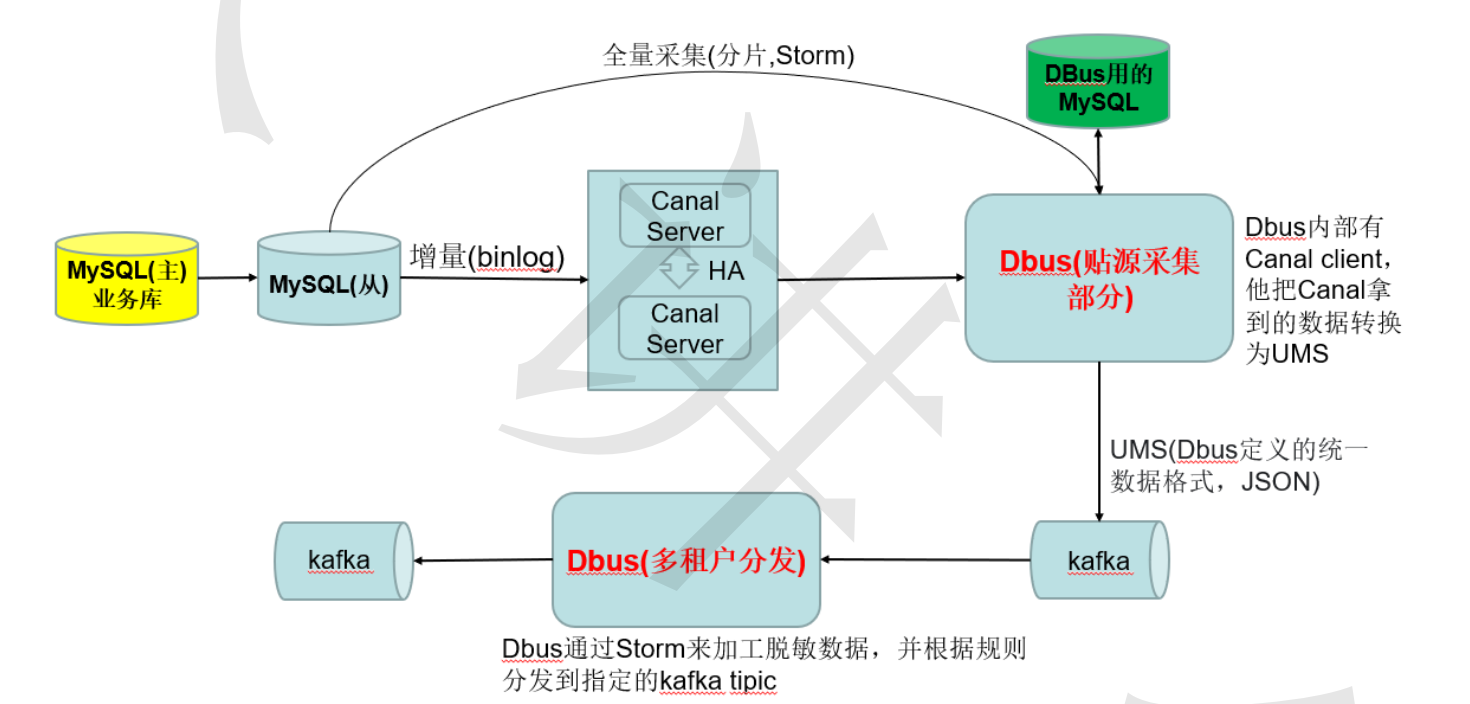
为了更贴近真是环境,部署规划如下:

部件说明:
Canal :版本 v1.0.22 DBus用于实时抽取binlog日志。DBus修改一个1文件, 具体配置可参考
canal相关支持说明,支持mysql5.6,5.7
Mysql :版本 v5.6,v5.7
限制:
被同步的Mysql blog需要是row模式
考虑到kafka的message大小不宜太大,目前设置的是最大10MB,因此不支持同步mysql
MEDIUUMTEXT/MediumBlob和LongTEXT/LongBlob, 即如果表中有这样类型的数据会直接被替
换为空
业务MySQL(主)复用Ambari的MySQL,这个我们早就部署了,因此只需要在ndoe02上安装MySQL。
Ambari的MySQL才用的5.7,我们也用5.7避免MySQL主从出现问题
安装MySQL

下载安装包
sudo wget http://dev.mysql.com/get/mysql57-community-release-el7-11.noarch.rpm
安装mysql源
sudo yum -y install mysql57-community-release-el7-11.noarch.rpm
安装mysql服务器
sudo yum -y install mysql-community-server
设置为开机启动
sudo systemctl enable mysqld
启动Mysql
sudo systemctl start mysqld
查看mysql状态
sudo systemctl status mysqld
如果安装mysql的过程中遇到这个问题
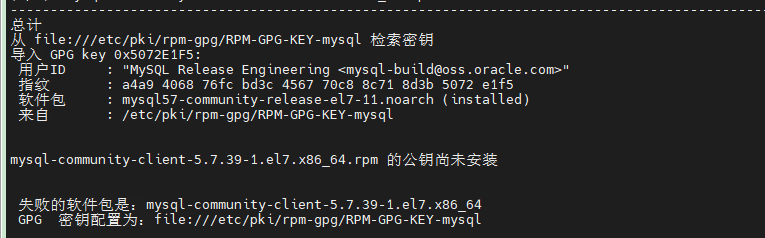
这样解决:
sudo rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022
查看临时root临时密码
sudo grep 'temporary password' /var/log/mysqld.log

利用临时密码登录
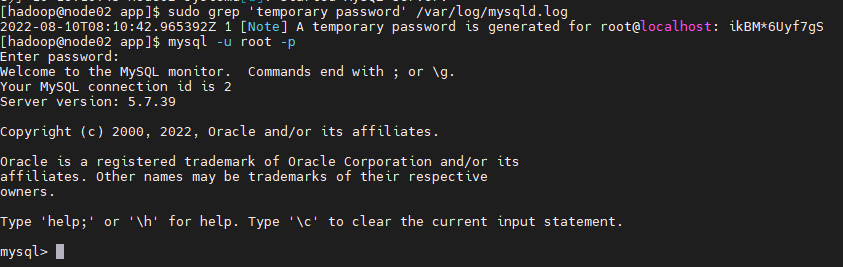
现在我们修改root用户密码:
set global validate_password_policy=0;
set global validate_password_mixed_case_count=0;
set global validate_password_number_count=3;
set global validate_password_special_char_count=0;
set global validate_password_length=3;
ALTER USER 'root'@'localhost' IDENTIFIED BY 'root';
exit

MySQL主从
接下来我们把node01和node02上的MySQL配置主从(node01上的MySQL早就上线了,node02上的
MySQL是新装的)。
首先我们分析下主从关系,如下图:
如上图所示,中间的MySQL(node02)即是主又是从,一定要及得加上log_slave_updates配置,否则在
MySQL主节点(node01)上插入数据,MySQL从虽然可以同步数据,但是它不会级联生成binlog日志,
canal就采集不到数据了
主库配置
登陆node01,编辑MySQL配置文件:
sudo vi /etc/my.cnf
增加以下配置:
server-id=1 log-bin=mysql-bin binlog-format=Row binlog-ignore-db=information_schema binlog-ignore-db=ambari binlog-ignore-db=dbusmgr binlog-ignore-db=hive binlog-ignore-db=mysql binlog-ignore-db=performance_schema binlog-ignore-db=sys #binlog-do-db=test
log-bin用于指定binlog日志文件名前缀,默认存储在/var/lib/mysql 目录下。
server-id用于标识唯一的数据库,不能和别的服务器重复,建议使用ip的最后一段,默认值也不可以。
binlog-ignore-db:表示同步的时候忽略的数据库。
binlog-do-db:指定需要同步的数据库(如果没有此项,表示同步所有的库)。
配置完后重启mysql
sudo systemctl restart mysqld
重启之后再次登录MySQL终端,并执行以下命令:
set global validate_password_policy=0; set global validate_password_mixed_case_count=0; set global validate_password_number_count=3; set global validate_password_special_char_count=0; set global validate_password_length=3; #创建一个用户,MySQL slave服务器使用这个用户连接Master同步binlog(有多个从库可以分别创建多个 用户) CREATE USER 'repl'@'%' IDENTIFIED BY 'repl%123'; #授予该用户SLAVE权限 GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%' identified by 'repl%123'; show master status;
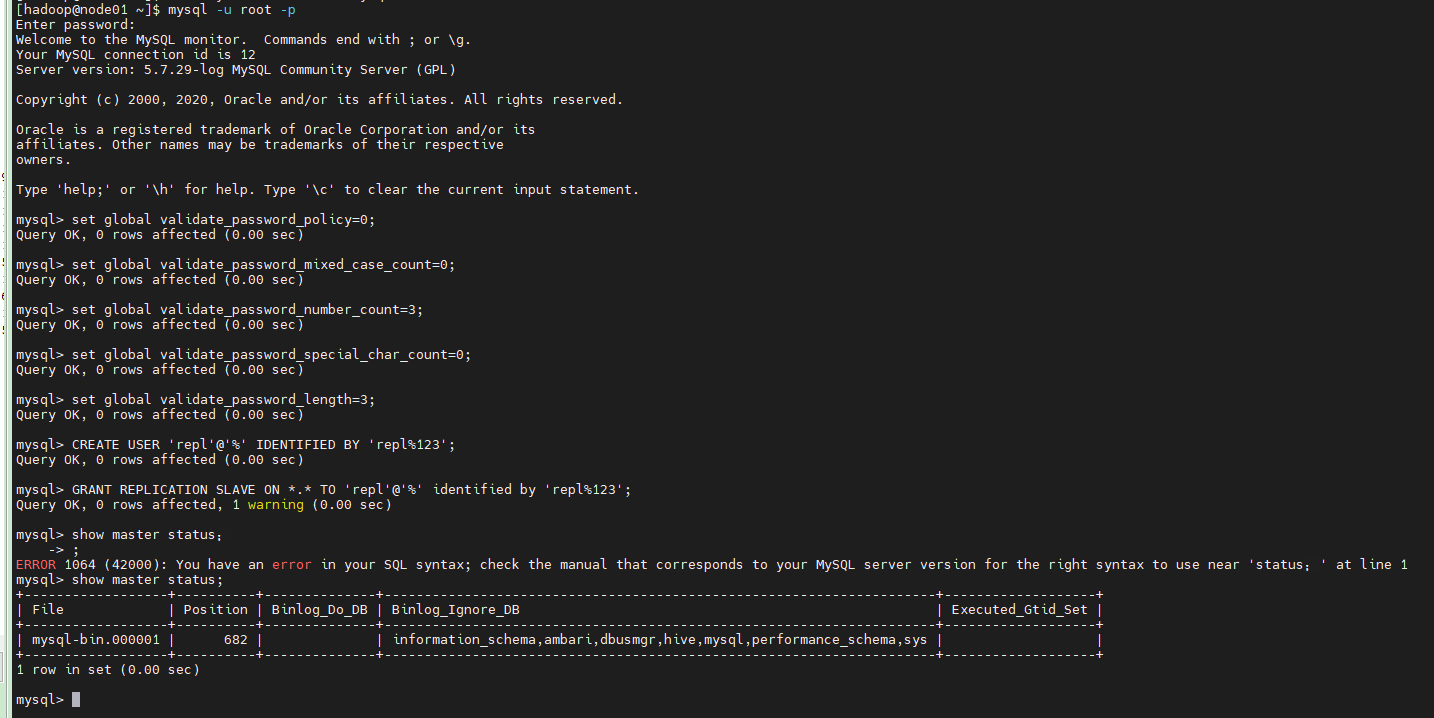
从库配置
登node02,编辑MySQL配置文件:
sudo vim /etc/my.cnf
增加如下配置:
#跟主库的server-id一定要不一样 server-id=2 log-bin=mysql-bin #下面这个必须加上,因为node02上的MySQL既是slave又是master,加上该选项才会生成级联binlog log_slave_updates binlog-format=Row binlog-ignore-db=information_schema binlog-ignore-db=ambari binlog-ignore-db=dbusmgr binlog-ignore-db=hive binlog-ignore-db=mysql binlog-ignore-db=performance_schema binlog-ignore-db=sys #binlog-do-db=test
保存退出,并重启mysql
sudo systemctl restart mysqld
重启之后再次登录Mysql,执行以下命令:
CHANGE MASTER TO MASTER_HOST='node01', MASTER_USER='repl', MASTER_PASSWORD='repl%123', MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=682; START SLAVE;
MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=682;并不是乱填的,这个要跟show
master status获取的主库状态保持一致
查看slave状态(作为主库node01的从库)
show slave status;
查看master状态(作为Canal的主库)
show master status;
检查用户是否创建好了:
SELECT DISTINCT CONCAT('User: ''',user,'''@''',host,''';') AS query FROM mysql.user;
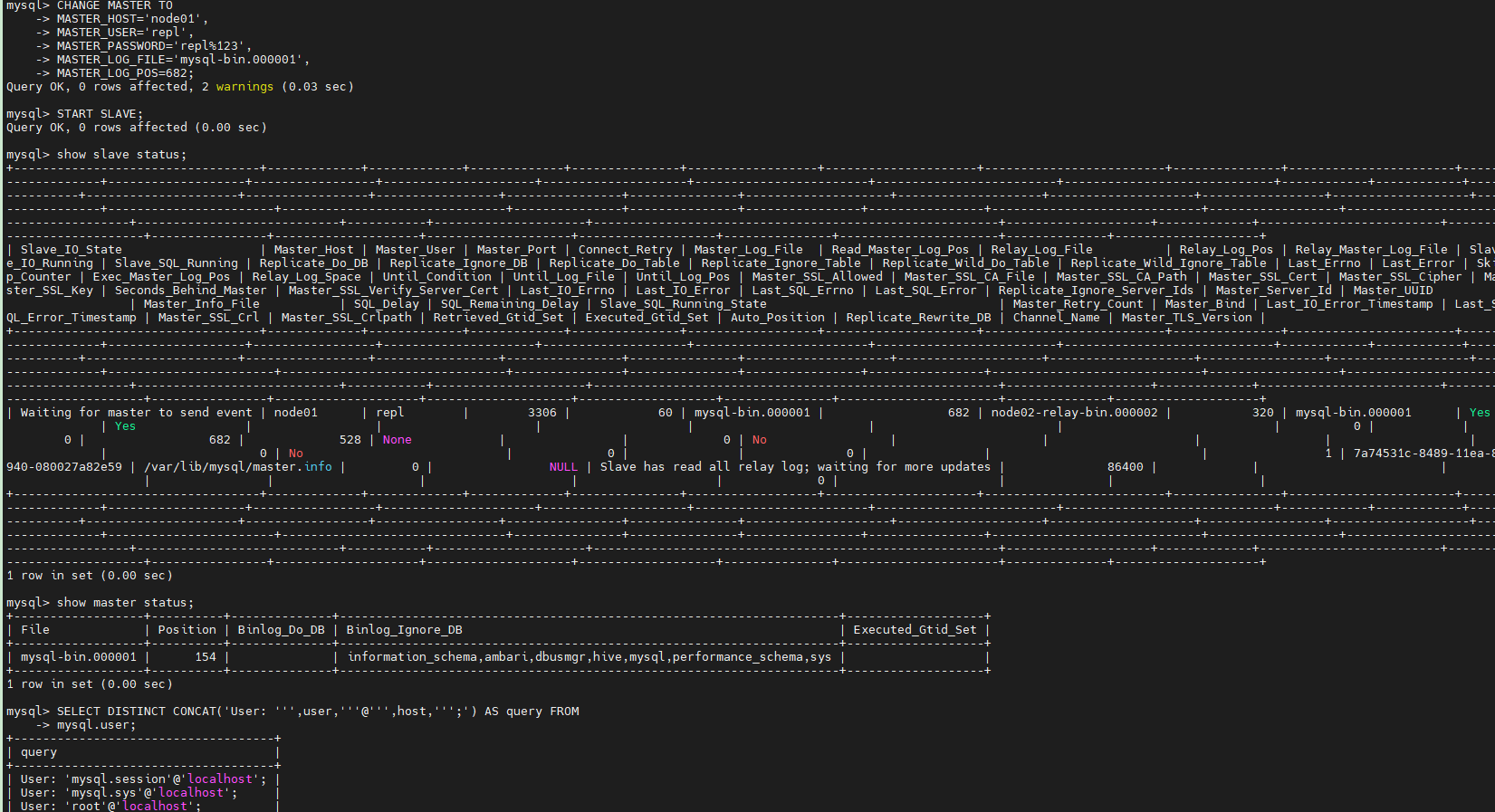
数据库源端创建心跳库
此步骤中需要在MySQL业务库上创建一个名字为dbus的库,并在此库下创建表db_heartbeat_monitor
和db_full_pull_requests两张表,用于心跳检测和全量拉取。
在数据源端新建的dbus库,可以实现无侵入方式接入多种数据源,业务系统无需任何修改,以无侵入
性读取数据库系统的日志获得增量数据实时变化。
登录node01上的mysql
执行如下操作:
set global validate_password_policy=0;
set global validate_password_mixed_case_count=0;
set global validate_password_number_count=3;
set global validate_password_special_char_count=0;
set global validate_password_length=3;
--- 1 创建库,库大小由dba制定(可以很小,就2张表)
create database dbus;
--- 2 创建用户,密码由dba制定
CREATE USER 'dbus'@'%' IDENTIFIED BY 'dbus%123';
--- 3 授权dbus用户访问dbus自己的库
GRANT ALL ON dbus.* TO dbus@'%' IDENTIFIED BY 'dbus%123';
flush privileges;
在dbus库下创建2个表:
use dbus;
DROP TABLE IF EXISTS `db_full_pull_requests`;
CREATE TABLE `db_full_pull_requests` (
`seqno` bigint(19) NOT NULL AUTO_INCREMENT,
`schema_name` varchar(64) DEFAULT NULL,
`table_name` varchar(64) NOT NULL,
`physical_tables` varchar(10240) DEFAULT NULL,
`scn_no` int(11) DEFAULT NULL,
`split_col` varchar(50) DEFAULT NULL,
`split_bounding_query` varchar(512) DEFAULT NULL,
`pull_target_cols` varchar(512) DEFAULT NULL,
`pull_req_create_time` timestamp(6) NOT NULL,
`pull_start_time` timestamp(6) NULL DEFAULT NULL,
`pull_end_time` timestamp(6) NULL DEFAULT NULL,
`pull_status` varchar(16) DEFAULT NULL,
`pull_remark` varchar(1024) DEFAULT NULL,
PRIMARY KEY (`seqno`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
SET FOREIGN_KEY_CHECKS=0;
DROP TABLE IF EXISTS `db_heartbeat_monitor`;
CREATE TABLE `db_heartbeat_monitor` (
`ID` bigint(19) NOT NULL AUTO_INCREMENT COMMENT '心跳表主键',
`DS_NAME` varchar(64) NOT NULL COMMENT '数据源名称',
`SCHEMA_NAME` varchar(64) NOT NULL COMMENT '用户名',
`TABLE_NAME` varchar(64) NOT NULL COMMENT '表名',
`PACKET` varchar(256) NOT NULL COMMENT '数据包',
`CREATE_TIME` datetime NOT NULL COMMENT '创建时间',
`UPDATE_TIME` datetime NOT NULL COMMENT '修改时间',
PRIMARY KEY (`ID`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
SET FOREIGN_KEY_CHECKS=0;
注意:从库node02不用执行上述操作,之前作了主动复制,他会自动复制的,你可以自行登录从库查看。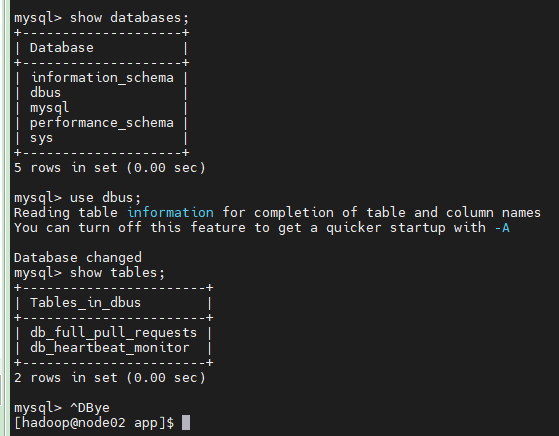
创建业务库表
我们这里要创建一个业务库和表,后面要插入数据,观察DBus是否能实时采集到数据。
我能依旧登录node01上的mysql(主库)
执行以下操作:
set global validate_password_policy=0;
set global validate_password_mixed_case_count=0;
set global validate_password_number_count=3;
set global validate_password_special_char_count=0;
set global validate_password_length=3;
-- 1 创建测试库 测试表, 用于测试的.(已有的库不需要此步骤,仅作为示例)
create database test_schema1;
use test_schema1;
create table t1(a int, b varchar(50));
--- 2 创建测试用户,密码由dba制定。(已有的用户不需要此步骤,仅作为示例)
CREATE USER 'test_user'@'%' IDENTIFIED BY 'test_user%123';
GRANT ALL ON test_schema1.* TO test_user@'%' IDENTIFIED BY 'test_user%123';
flush privileges;
--- 3 授权dbus用户 可以访问 t1 的备库只读权限
GRANT select on test_schema1.* TO dbus;
flush privileges;
开启dbus用户拉备库权限
dbus在拉取数据时可以先全量拉取历史数据,在增量获取增量数据,全量拉取只是初始化加载操作,
只做一次。
全量拉取是在备库上进行的(拉主库会影响主业务),因此需要授予dbus用户获取拟拉取的目标表备库的
读权限,用于初始化加载。以test_schema1.t1为例,在node01上操作(会自动同步到备库的)
部署canal
创建专用用户,Canal专门负责从备库拉取binlog实现增量获取数据,需要为他指定一个用户专门复制binlog日志
登录备库node02上的MySQL(从库):
执行如下操作:
set global validate_password_policy=0;
set global validate_password_mixed_case_count=0;
set global validate_password_number_count=3;
set global validate_password_special_char_count=0;
set global validate_password_length=3;
--- 创建Canal用户,密码由dba指定, 此处为canal
CREATE USER 'canal'@'%' IDENTIFIED BY 'canal%123';
--- 授权给Canal用户
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;
下载安装包:https://pan.baidu.com/s/1b1aKueXLvO2GigB5fa4kNw
别的版本也可以参考地址:https://github.com/BriData/DBus/releases
我们只需要下载这个就够了
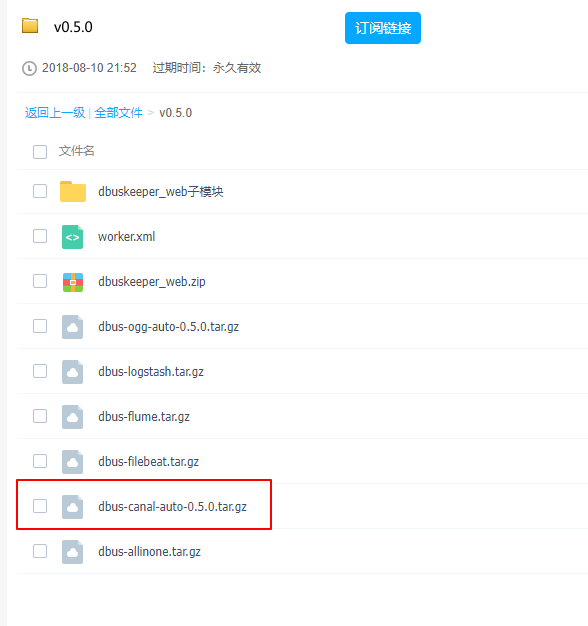
先把dbus-canal-auto-0.5.0.tar.gz上传至node02、node03的/home/hadoop/app/dbus下并解压缩,node02、node03都要部署
cd /home/hadoop/app/dbus tar -zxvf dbus-canal-auto-0.5.0.tar.gz
解压后的目录结构
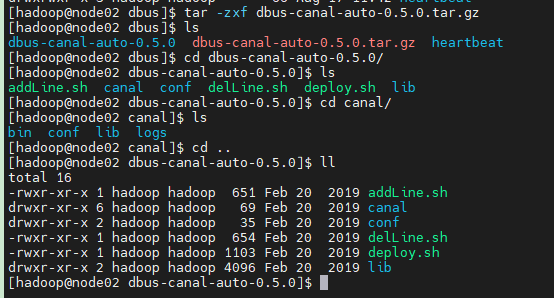
1. canal目录是自带的canal,该文件夹不能重命名,否则脚本会运行失败。
2. 是需要用户配置的
3. lib 目录不用关心
4. deploy.sh 自动化脚本
修改conf 目录下的canal-auto.properties
将conf目录下的canal-auto.properties文件中内容,修改成自己的信息。例如:
#数据源名称,需要与dbus keeper中添加的一致
dsname=gong_db
#zk地址,替换成自己的信息
zk.path=node01:2181
#canal 用户连接地址。即:要canal去同步的源端库的备库的地址
canal.address=node02:3306
#canal用户名
canal.user=canal
#canal密码,替换成自己配置的
canal.pwd=canal%123
执行deploy.sh脚本
sh deploy.sh

执行如下命令检查部署有没有问题:
sh deploy.sh check

我们采用deploy.sh脚本部署了Canal,它自动就已经启动了,自动部署之后目录结构是
这样的: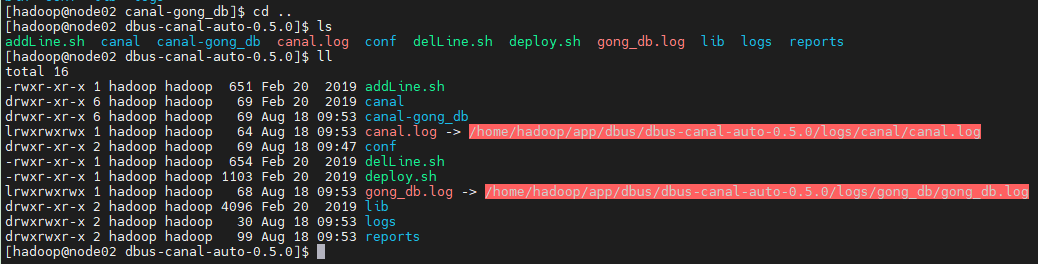
多个几个目录:
canal-gong_db:这个就是他自动部署的canal,实际上是从它上面的canal目录拷贝了一份,并自动生成了配置
canal.log、gong_db.log就是两个软连接,方便我们查看日志,省得进到很深的目录里
reports:这里存放自动部署和deploy.sh check时生成的报告,如果发现canal异常可以去这里面检查部署时的报错信息
我们的启停脚本就在canal-gong_db这个目录下,大家进入目录就能看到。
自动部署之后就不要再执行deploy.sh
DBus一键加线
所谓数据线是一种形象的说法,DBus要想采集某个数据库( 数据源 )的数据,就得拉一根线连接数据库
和DBus,加数据线就是在DBus-Keeper页面配置一条数据线,即指定从哪个数据源的哪个库采集哪些表的数据。
Keeper加线
Dbus对每个DataSource数据源配置一条数据线,当要添加新的datasource时,需要添加一条数据线。
删除自动部署Canal的配置
我们采用手工方式部署Canal,所以把相关配置删掉,避免加数据线时出现问题
管理员身份进入dbus keeper页面,数据源管理-新建数据线 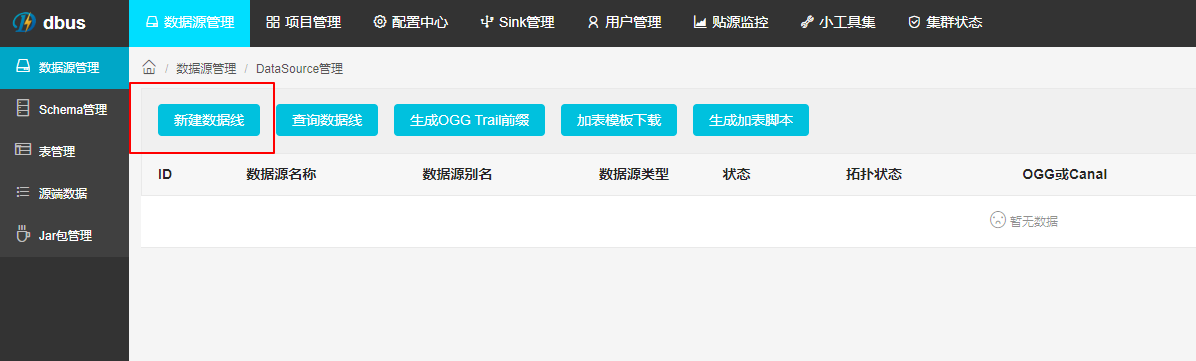
填写数据源基本信息(master和slave jdbc连接串信息)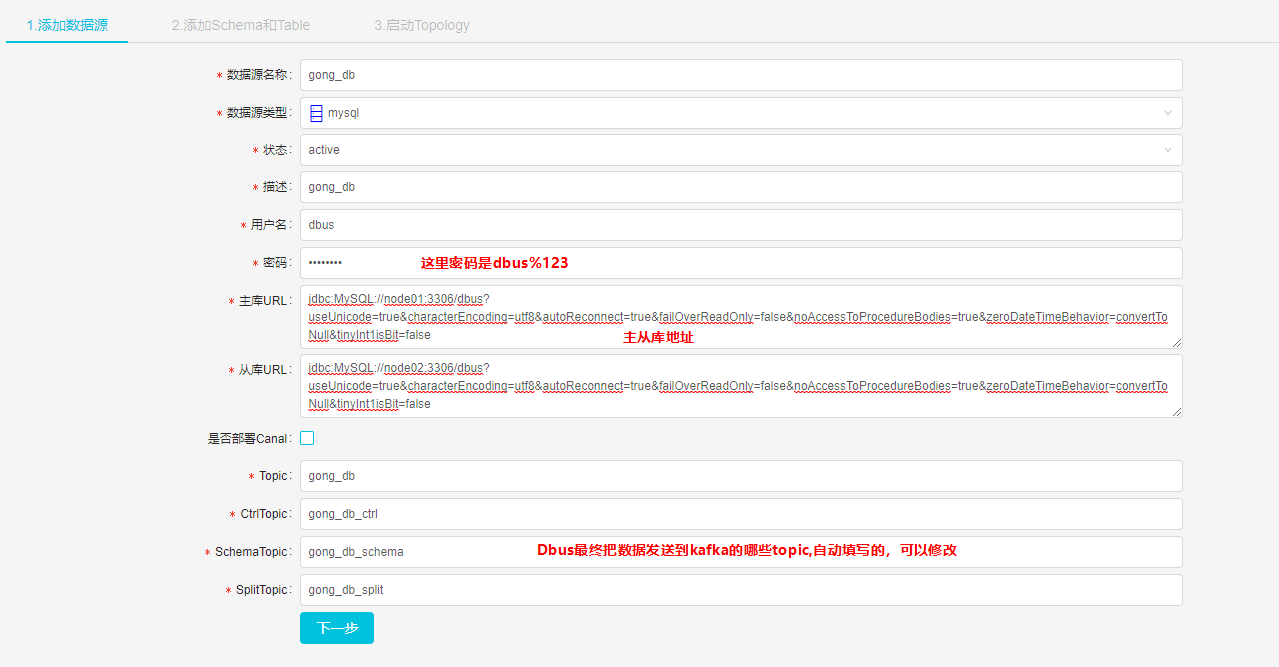
主库url:
jdbc:MySQL://node01:3306/dbus?useUnicode=true&characterEncoding=utf8&autoReconnect=true&failOverReadOnly=false&noAccessToProcedureBodies=true&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false
从库url:
jdbc:MySQL://node02:3306/dbus?useUnicode=true&characterEncoding=utf8&autoReconnect=true&failOverReadOnly=false&noAccessToProcedureBodies=true&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false
下一步添加的schema,勾选要添加的表。Keeper支持一次添加多个schema下的多个table 
启动Topology

在启动的同时,可以去Storm UI上看看:
http://node03:8744/index.html
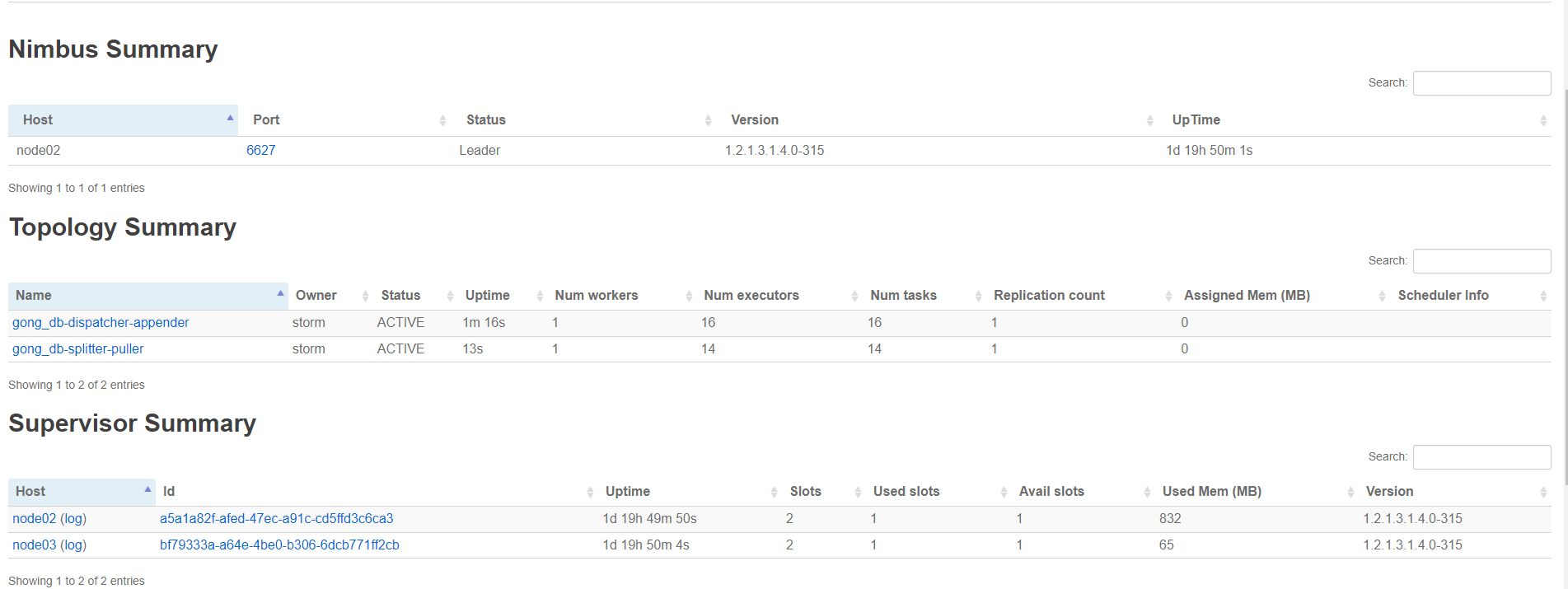
再次回到“数据源管理”,我们看到数据线加载好了:

DBus0.5.0添加数据线就会自动启动表数据同步
验证增量数据:
去业务表 test_schema1.t1添加数据:
use test_schema1; INSERT INTO t1(a, b) VALUES (101, "zhangsan"); INSERT INTO t1(a, b) VALUES (102, "lisi"); INSERT INTO t1(a, b) VALUES (103, "wangwu"); INSERT INTO t1(a, b) VALUES (104, "zhaoliu"); INSERT INTO t1(a, b) VALUES (105, "maqi"); INSERT INTO t1(a, b) VALUES (106, "zhouba"); INSERT INTO t1(a, b) VALUES (107, "zhouba"); INSERT INTO t1(a, b) VALUES (108, "zhouba");

 浙公网安备 33010602011771号
浙公网安备 33010602011771号