python从入门到精通
第零章 python常识
0.1 python环境安装
-
进入官网,下载python:https://www.python.org/downloads/windows/,选择合适的python版本。3.9及以上的版本无法在win7上安装。点击下载对应版本的windows installer(32-bit)或windows installer(64-bit)。本教程使用的是python3.10.7(64-bit)。
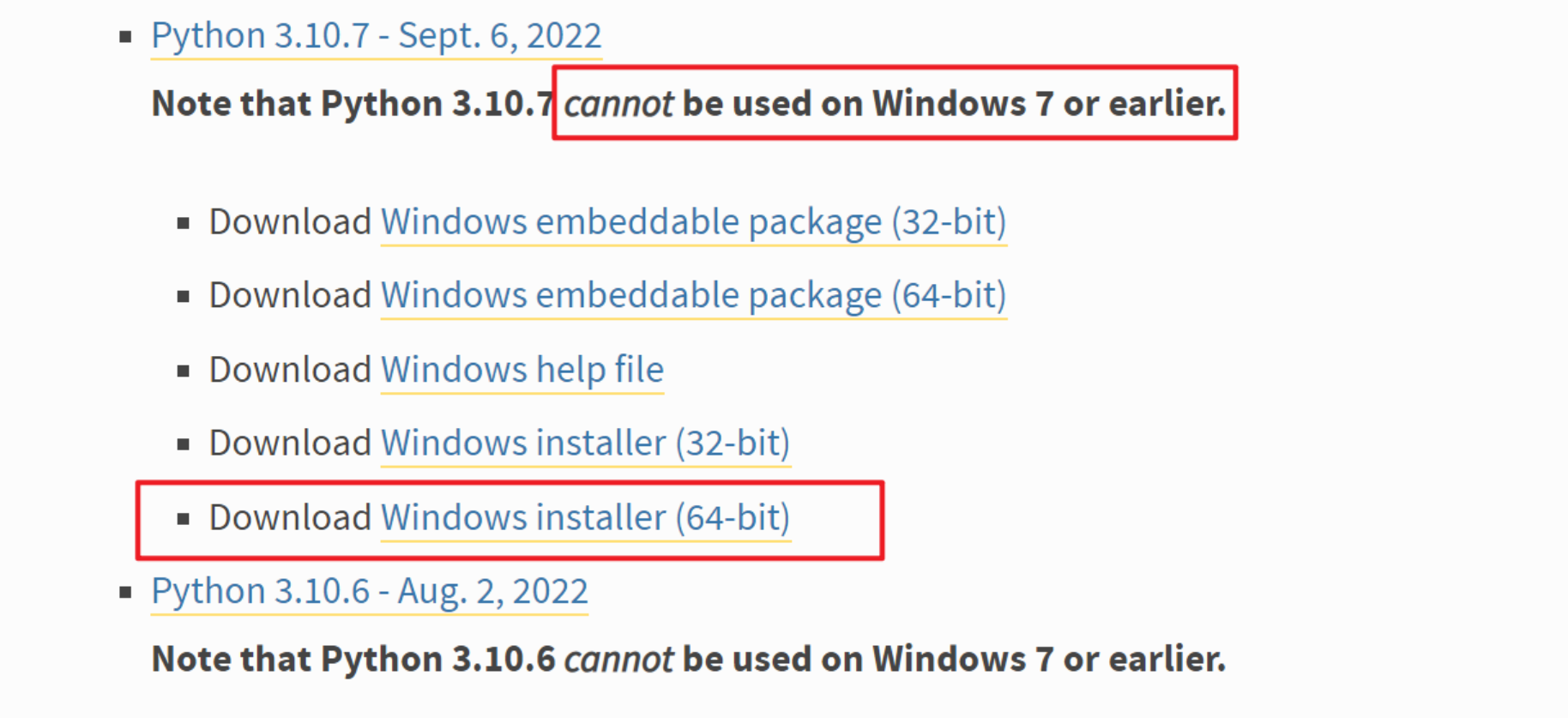
-
安装
-
双击下载好的python
-
选择安装路径,并添加到环境变量
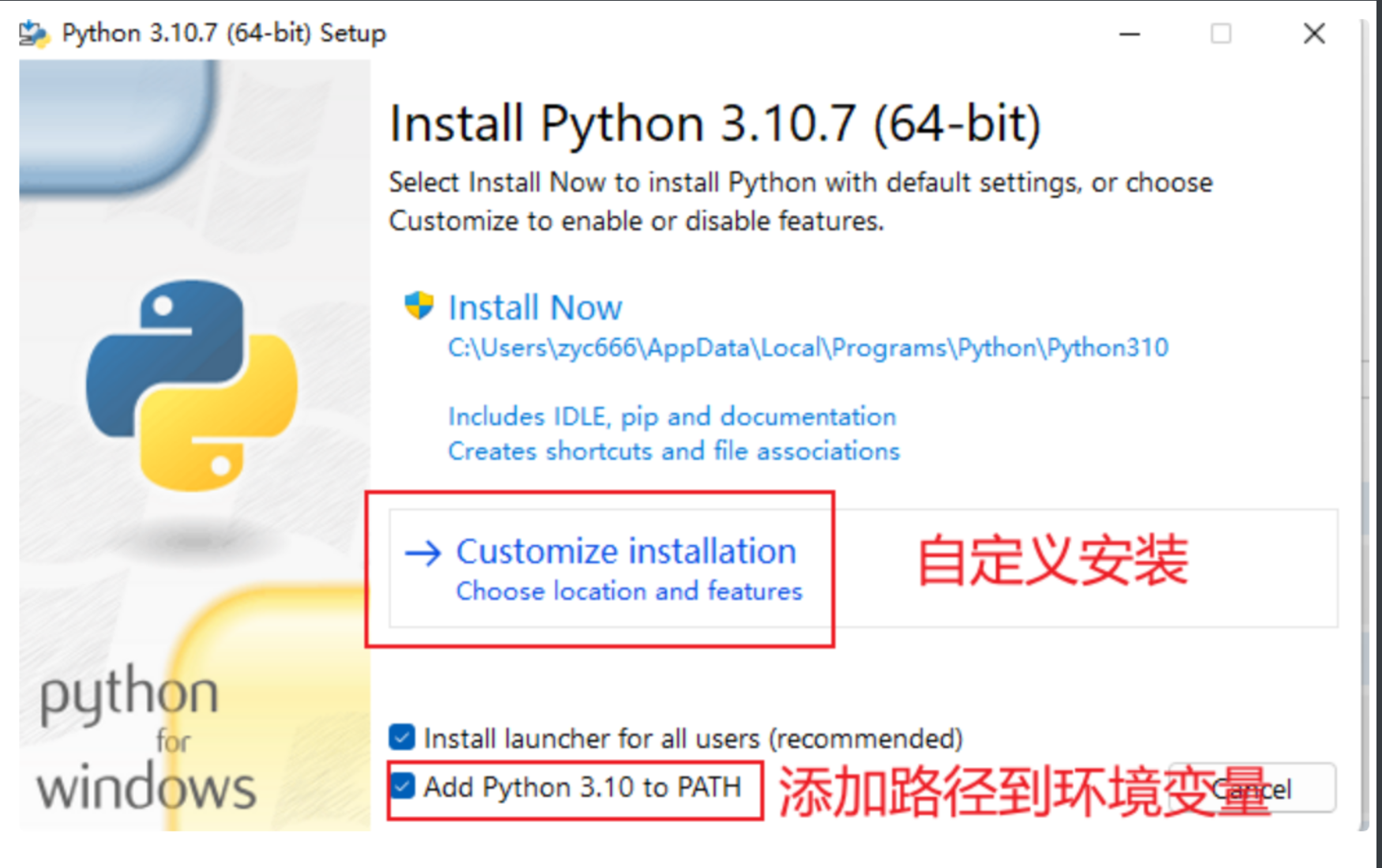
可以选择Install Now,默认安装到C盘,只要有空间,系统并不会变卡,安装简单,并且以后找不到路径时,百度即可。我这里空间不够了,选择自定义安装。注意,一定要将下面的两个复选框勾上,特别是添加到环境变量。
-
勾选,下一步
-
该路径(如果是默认安装,就不需要该路径)
-
等待安装
-
安装成功
-
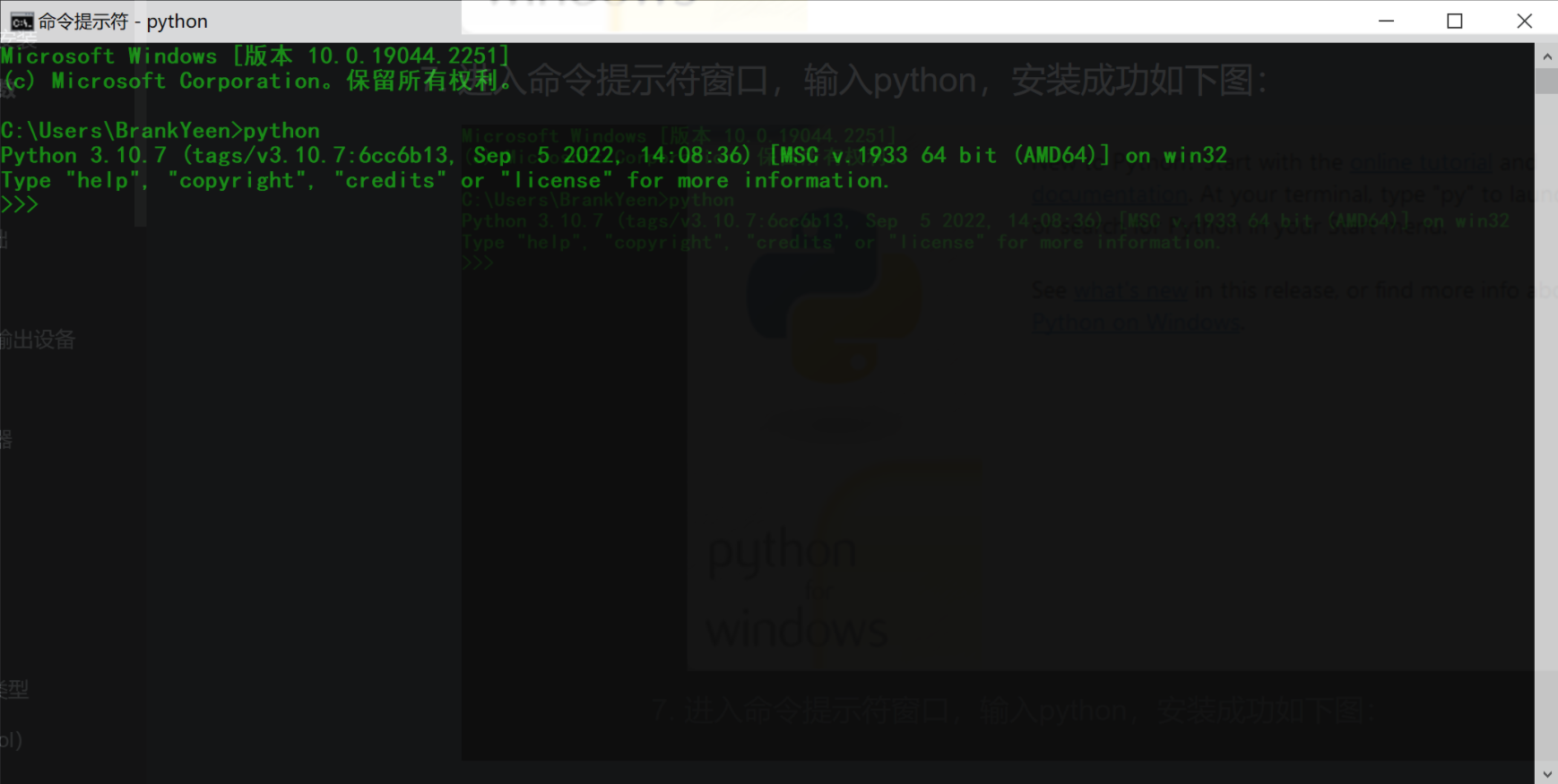
进入命令提示符窗口,输入python,安装成功如下图(如果没有添加到环境变量变量中,不会显示该图):
-
0.2 内置函数

这些内置函数都是常用的,必须掌握。教程中,也会用到一些内置函数,不清楚的同学,可以自行查阅官方文档(https://docs.python.org/zh-cn/3/library/functions.html)。
0.3 专业术语
python是一门非常自由的语言,不仅体现在代码的风格上,对于同一个东西,由于各种原因,不同的人可能也有不同的叫法。python官方,也并没有全部明确地规定专业术语,因此,当你听到不同的称谓时,不要纠结,只需明白他人讲述的内容是什么即可。这一点非常重要,不知道的人,在看其他文档时,常常会疑惑。
python官方,术语查询文档:https://docs.python.org/zh-cn/3/(只作参考)
0.4 两个函数
在学习任何一门语言的时候,使用最频繁的函数,一定是输入输出函数,而python的入门学习中,输入函数:input(),输出函数:print()。
a = input("请输入:")#括号里面写提示语句,也可以不写
print(a)#括号里面写打印输出的内容
#甚至可以
print(input("请输入:"))
0.5 关键字
关键字又称保留字,由官方定义,所有语言中都有关键字,不同的语言关键字不同。这些关键字代表着特殊的含义,由特殊的作用。比如,def 用来定义函数,True代表真。教程中会有用到,不需要单独学习,不清楚的可以自行百度。
python中的关键字:

0.6 变量
数据都是存放在内存中的,变量(又叫变量名)就是给这块内存地址起的名字,假设数据10存放在内存地址1234 5678中,每次使用时都要表示出这个地址,很不方便,特别是在多次使用该数据时,如果能给这个地址起一个名字,例如用number表示这个地址,之后就可以直接使用number访问该地址,从而获取里面的数据。

-
变量的命名规范:
- 要有语义,要能表述里面存放的数据;
- 只能包含字母、数字、下划线三种符号;
- 不能以数字开头,也不能是纯数字;
- python中,下划线开头有特殊的含义,不推荐随意使用;
- 不能用关键字命名。
-
变量的类型
在python中,变量不需要单独申明,赋值即申明,也不需要特意指定变量的类型,其类型由变量值决定。例如,number = 10,已经表示number的类型为整型。
-
常量
与变量对应的是常量,已经被赋值的变量,还可以被其他数据赋值,即该名称可以取消与当前内存地址的绑定关系,再与其他内存地址绑定,例如,number = 10(假设内存地址为1234 5677),number = 20(假设内存地址为1234 5677),最终number绑定的内存地址是1234 5677。常量则不允许变量随意的更换绑定的内存地址,即名称一旦代表某一数据,就无法更换成其他数据,但是python并没有规定常量这一概念,没有申明常量的关键字,但是某些时候确实需要常量,因此人为规定,变量名所有字母大写代表该数据是常量,不会轻易被修改(本质上是变量,这个规定是给程序员看的)。例如,PAI = 3.14,之后就不应该用PAI来代表其他数据。
0.7 注释
在实际开发过程中,有效的代码注释不仅可以提升个人的工作效率,快速了解自己的程序情况,在团队协作开发过程中可以更加方便地让同事学习和调用你的代码。注释的内容是给程序员看的,并不会执行。在python中的注释一般分为单行注释、多行注释,不同语言中的注释符不一样。
单行注释:#后面的内容,就是注释内容;
多行注释:'''这里写注释内容'''。
第一章 计算机基础
1.1 硬件组成
冯诺依曼体系:所有的计算机都由输入设备、存储器、运算器、控制器、输出设备这五部分组成。
1.1.1 输入输出设备
输入设备:接收用户输入的设备。例如鼠标、键盘、触摸板等等;
输出设备:将计算机运算的结果反馈给用户的设备。例如:耳机、显示屏等等。
1.1.2 CPU
Central Processing Unit,中央处理器,是运算器和控制器的集合体,用于处理数据的算术运算和逻辑运算(运算器的作用),并且能够控制其他硬件工作(控制器的作用)。
CPU好比是一个团体,核心就是就是团体中大脑的个数(人的个数),线程就是每个人的胳膊。所以,8核心8线程就代表这个团体由八个人、每个人由一条胳膊组成,8核心16线程代表这个团体由8个人、每个人两条胳膊组成 。理论上,核心数越多、线程数越多,处理任务的能力越大、速度越快。
目前,全球CPU两大厂商:Intel和AMD,Intel在单核性能方面更强,适合游戏或重度办公的场景,AMD在多线程方面更有优势,多个核心的协同性更好,在多任务处理上更突出。无论是Intel还是AMD,都有好几个系列,我们电脑所用的都是Intel的酷睿系列和AMD的锐龙系列;酷睿系列CPU的等级:i3<i5<i7<i9,锐龙系CPU的等级:R3<R5<R7<R9;CPU在不断更新迭代,同一系列同一级的新代CPU肯定比上一代的CPU性能更强;CPU的频率代表着CPU大致的能力,频率又分为主频和睿频,主频是一般情况下的能力,睿频是爆发时刻的能力,频率越高性能越好。后缀名代表CPU的电压、功耗、核显、频率等,Intel和AMD的后缀名不同。
酷睿i9 13900K:Intel酷睿系列,i9等级,13代,900(没有具体的含义,一般数字越大性能越好),可以超频;
R7 5800HS:锐龙系列,第七等级,5代,800(没有具体的含义,一般数字越大性能越好),高性能轻薄本。
1.1.3 存储器
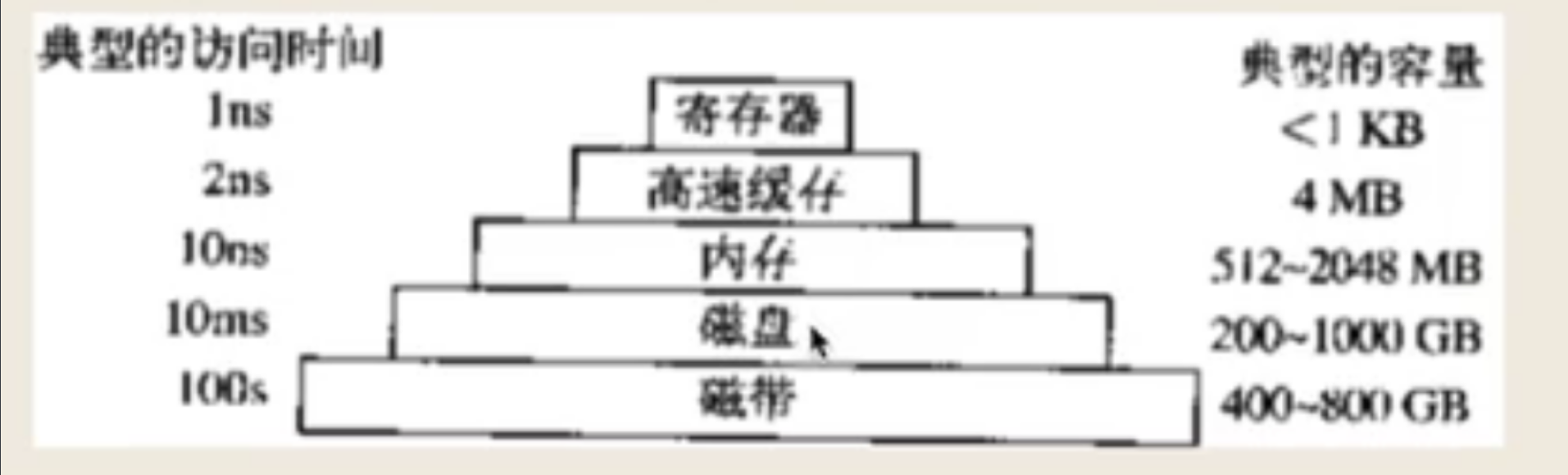
存储器是用来存放数据的设备。常见的存储器有:磁带、硬盘、U盘、内存条、寄存器等等。
硬盘:永久保存数据的地方,断电之后,数据不会消失。硬盘分为固态硬盘(SSD)和机械硬盘(HHD)两种,固态硬盘的读写速率远远高于机械硬盘,并且体积比机械硬盘小许多,跟内存条类似。如果你的电脑同时装有两种硬盘,装系统时,应该装到固态硬盘中,运行速率更快。如果是游戏玩家或者重度工作者,应该选择1TB及以上大小的硬盘,轻度工作者可以选择512GB大小的硬盘。
内存(RAM/随机可读可写存储器):程序运行时,数据从硬盘被提取到内存,再将常用或重要的指令,上传到高速缓存或寄存器中;内存中的数据,断电即丢失。内存的运行读写速率比硬盘快。总容量相同时,多通道的搭配比单通道的性能更好,例如,8GB+8GB组成的双通道,比单条16GB的性能要好。注意,某些笔记本的内存是板载内存(内存条嵌入到主板中),意味着无法更换内存条,购买时一定要看清楚。
高速缓存(高速缓冲存储器):CPU需要实时提取数据,而主存储器,即主存(主要是指内存,还有其他的主存储器,辅助存储器,主要是指硬盘)的速率远远低于CPU的速率,导致了供不应求的现象,大大降低了运行效率。高速缓存介于主存与CPU之间,速率比内存快得多,接近于CPU的速率,但是存储容量比主存小得多,因此,高速缓存主要用来存放最重要和最常用的数据和指令,这样就能大幅度提高运行效率。高速缓存又分为三种级别:一级缓存(L1Cache)、二级缓存(L2Cache)、三级缓存(L3Cache),他们的速率逐渐降低,容量逐渐增大。
寄存器:寄存器是CPU内部存放数据的小型存放区域,用来暂时存放参与运算的二进制数据,以及运算的结果。寄存器的读取速度比高速缓存更快,更接近于CPU的速度。寄存器又分为三类:通用寄存器、专用寄存器、控制寄存器。一颗CPU有多个寄存器
各存储器按照速率和容量排序:
1.2 操作系统
应用程序不能直接运行在硬件上,操作系统介于硬件与应用程序之间,应用程序通过调用操作系统的指令,从而操作硬件。操作系统由四部分组成:内核、驱动程序、接口库、外围。操作系统按照不同的分类标准,可以分为不同的类别,按照运行环境可以分为:桌面操作系统、手机操作系统、服务器操作系统、嵌入式操作系统等。
常见的桌面操作系统:windows、Unix、Linux、iOS等。
Unix:1970年问世,Unix是一个分水岭,在此之前,只有批处理操作系统,Unix的出现,意味着分时操作系统的诞生。Unix绝大部分程序由C语言编写,只有约5%的程序由汇编语言编写,因此,Unix的运行速率极快,并且由于Unix的特殊化设计,使得Unix的安全性非常高,稳定性非常好。绝大部分的Unix都收费,而且价格不菲,加之Windows的市场份额非常大,许多程序都是针对windows开发,所以Unix一般用于企业。
Windows:1985年,微软公司正式发布windows操作系统,比尔·盖茨在发布时说:“这是一款专为PC用户打造的独特软件。”windows最大的特点就是图形化界面,用户只需要通过鼠标点击,就能完成相应的命令,非常方便用户使用,比如使用windows能轻松的运行游戏,而其他操作系统会很麻烦,除了专门针对该系统开发的游戏。因此,Windows非常适合日常使用,这也导致了Windows的市场份额非常大。因为windows使用的人多,从而导致研究windows的人也多,加之windows闭源,所以大大降低了系统的安全性。windows也是需要收费的。
Linux:Linux,全称GNU/Linux,是一种免费使用和自由传播的类UNIX操作系统,其内核由林纳斯·本纳第克特·托瓦兹于1991年10月5日首次发布,它主要受到Minix和Unix思想的启发,是一个基于POSIX的多用户、多任务、支持多线程和多CPU的操作系统。它能运行主要的Unix工具软件、应用程序和网络协议。它支持32位和64位硬件。Linux继承了Unix以网络为核心的设计思想,是一个性能稳定的多用户网络操作系统。Linux有上百种不同的发行版,如基于社区开发的debian、archlinux,和基于商业开发的Red Hat Enterprise Linux、SUSE、Oracle Linux等。Linux稳定性好、体积小、开源、并且绝大部分都免费,导致了Linux的市场份额在逐年增加,但是Linux和Unix一样,适合工作,不适合娱乐,所以Linux的用户基本上是计算机相关人员,普通用户更适合windows操作系统。由于Linux的开源性,导致了用于可以定制自己的操作系统,因此安全性十分高。企业中,Linux的使用率排行第一,绝大部分的企业都是用Linux作为服务器。
1.3 进制转换
1.3.1 十进制与二进制的转换
-
计算机采用二进制的原因
首先,二进位计数制仅用两个数码。0和1,所以,任何具有二个不同稳定状态的元件都可用来表示数的某一位。例如,开关的“开” 和 “关”;电压的“高” 和“低”、“正”和 “负”;电路中的“有信号” 和 “无信号”等等。 利用0和1代表这些截然不同的状态,是很容易实现的。不仅如此,更重要的是两种截然不同的状态不单有量上的差别,而且是有质上的不同。这样就能大大提高机器的抗干扰能力,提高可靠性。而要找出一个能表示多于二种状态而且简单可靠的器件,就困难得多了。
其次,二进制的四则运算规则十分简单。而且四则运算最后都可归结为加法运算和移位,这样,电子计算机中的运算器线路也变得十分简单了。不仅如此,线路简化了,速度也就可以提高。这也是十进制所不能相比的。
最后,在电子计算机中采用二进制表示数可以节省设备。可 以从理论上证明,用三进位制最省设备,其次就是二进位制。但由于二进位制有包括三进位制在内的其他进位制所没有的优点,所以大多数电子计算机还是采用二进制。
-
十进制转二进制
十进制整数转二进制 将整数除以2,记下余数,再用商除以2,记下余数,直到商为0。将得到的余数逆序排列,就是该整数的二进制表示方式。 示例1 255=11111111(B) 255/2=127-----余1 第8位 127/2=63------余1 第7位 63/2=31-------余1 第6位 31/2=15-------余1 第5位 15/2=7--------余1 第4位 7/2=3---------余1 第3位 3/2=1---------余1 第2位 1/2=0---------余1 第1位 示例2 789=1100010101(B) 789/2=394-----余1 第10位 394/2=197-----余0 第9位 197/2=98------余1 第8位 98/2=49-------余0 第7位 49/2=24-------余1 第6位 24/2=12-------余0 第5位 12/2=6--------余0 第4位 6/2=3---------余0 第3位 3/2=1---------余1 第2位 1/2=0---------余1 第1位 十进制小数转二进制 小数部分乘以2,记下结果中的整数部分,将结果中的小数部分乘以2,再记下整数部分,直到得到的结果是一个整数,将所有的整数顺序排列,就是小数部分对应的二进制表示方式。大部分情况,得不到整数(只有2x5才等于0),因此根据要求保留相应的位数。 示例1 0.625=0.101(B) 0.625*2=1.25----------1 0.25*2=0.5------------0 0.5*2=1---------------1 示例2 24.7=11000.1 0110 0110...(B) 0.7*2=1.4--------------1 0.4*2=0.8--------------0 0.8*2=1.6--------------1 0.6*2=1.2--------------1 0.2*2=0.4--------------0 0.4*2=0.8--------------0 0.8*2=1.6--------------1 0.6*2=1.2--------------1 0.2*2=0.4--------------0 ... -
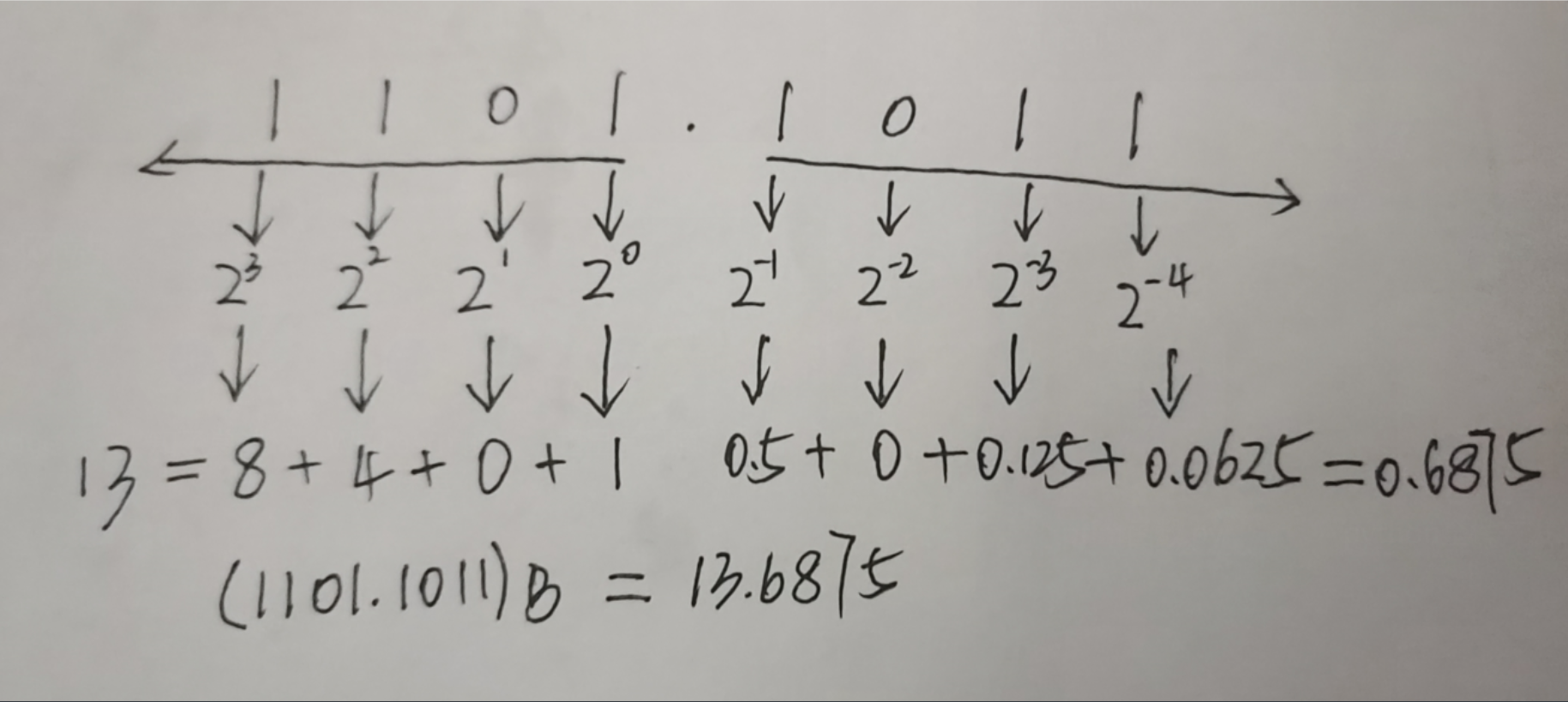
二进制转十进制
以小数点为中心,整数部分从右到左,每位数字依次乘以对应的位权,再将结果相加,就是十进制的整数部分(整数部分第一位的位权是2的0次方);小数部分从左到右,每位数字依次乘以对应的位权,再将结果相加,就是十进制的小数部分(小数部分第一位的位权是2的-1次方)。
1.3.2 二进制的四则运算
-
加法
十进制中,相加为10,向前进1;二进制中,相加为2,向前进1。
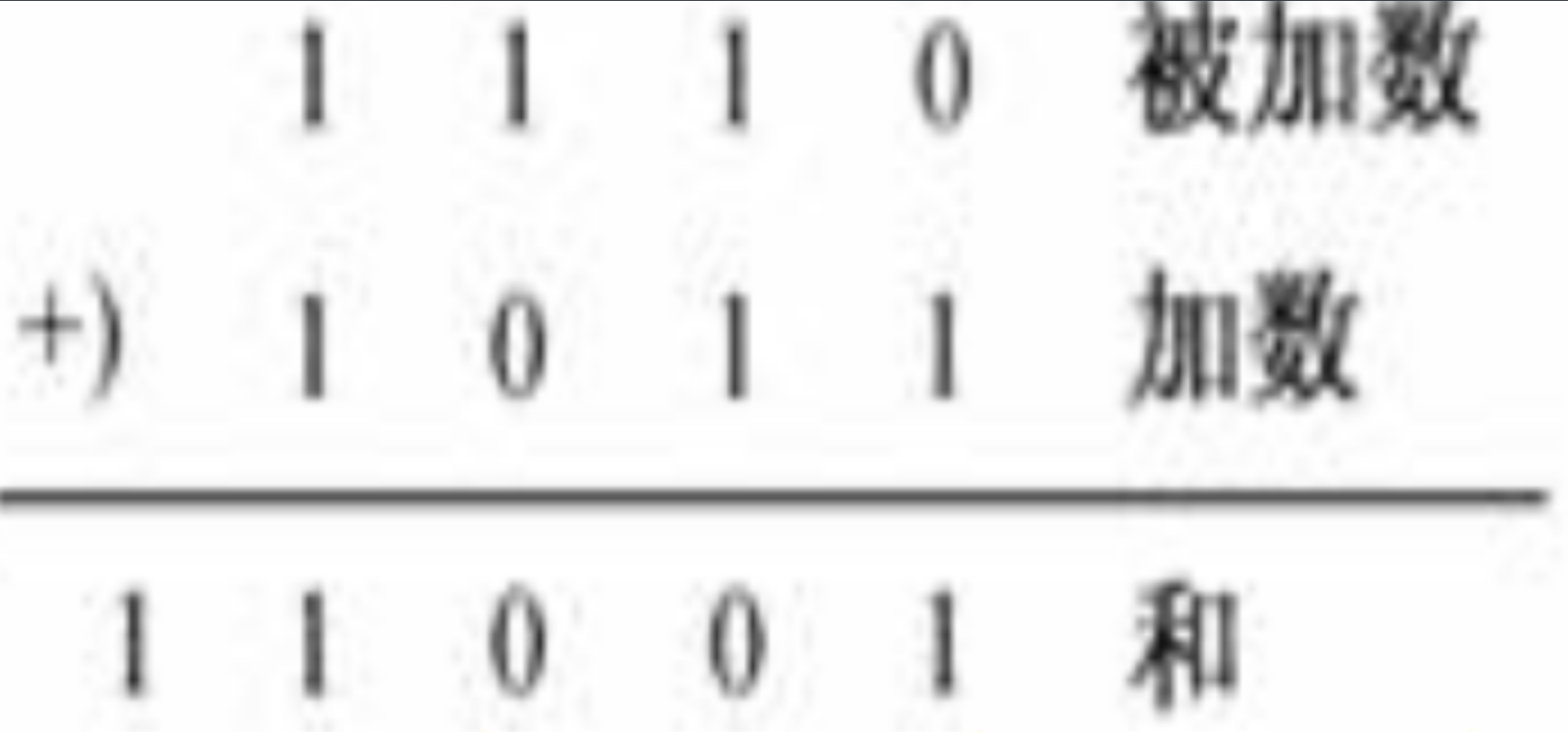
-
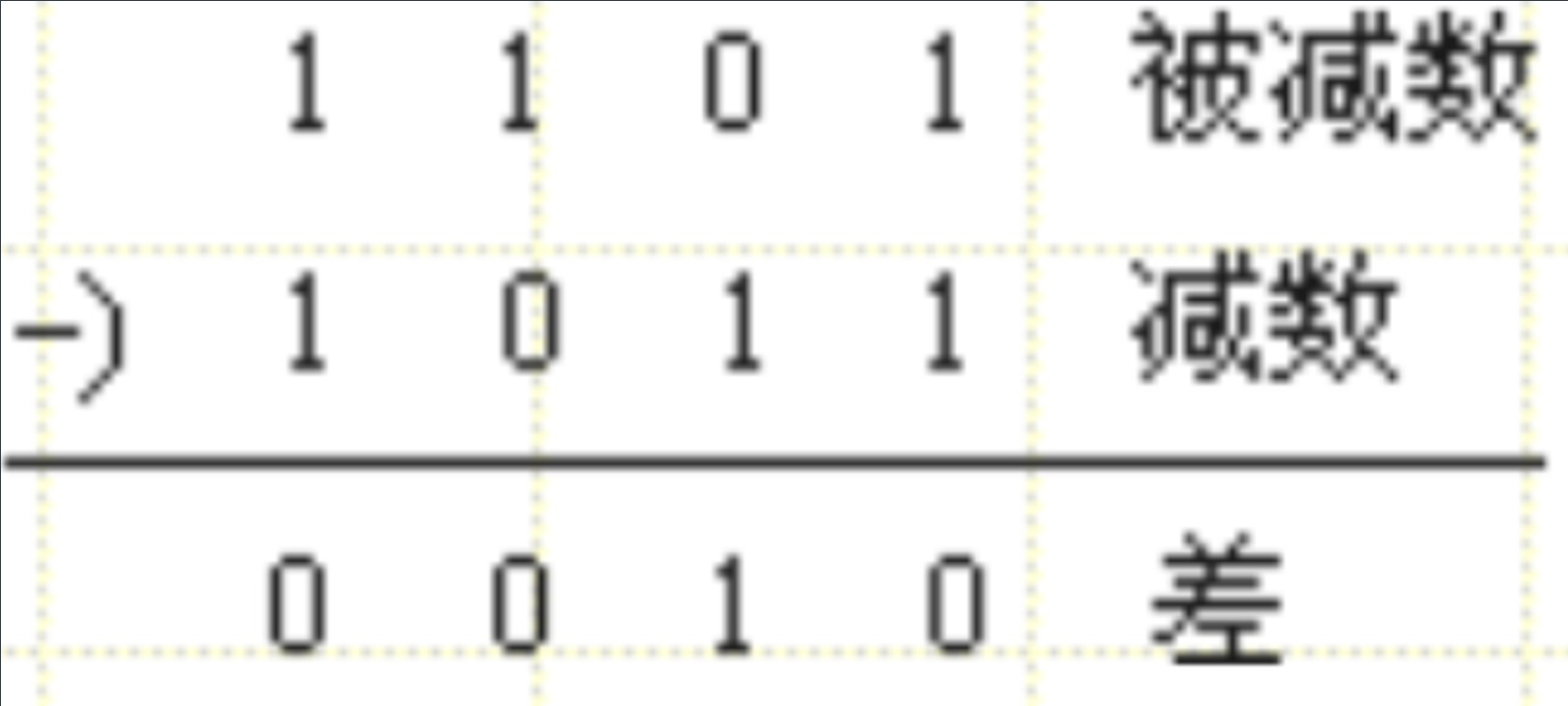
减法
当被减数小于减数时,需要向前借一位,十进制中借1当10,二进制中借1当2。
-
乘法
与十进制一样,下面的每一位都与上面的每一位相乘,再将结果错位相加。

-
除法
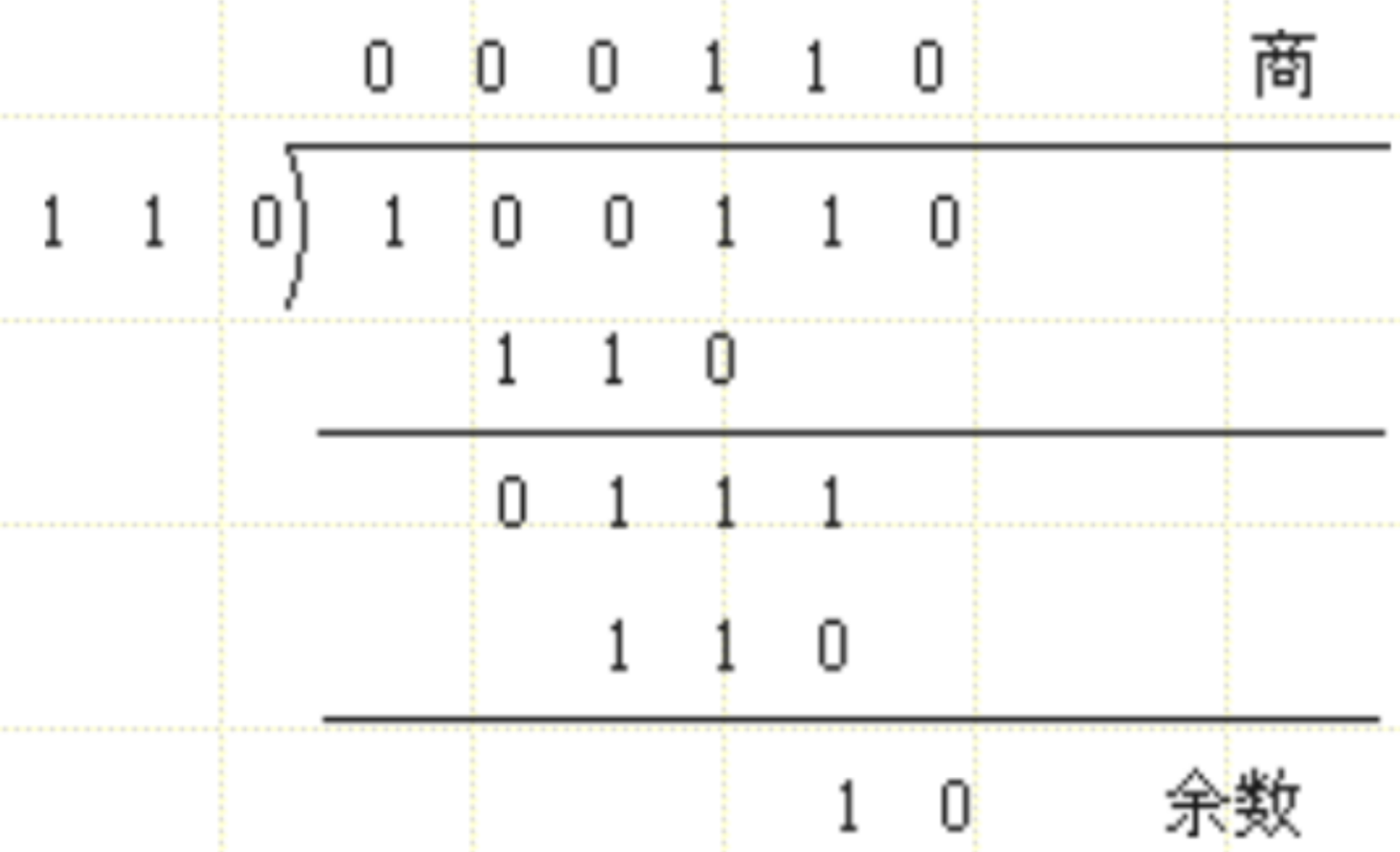
1.3.3 原码、反码和补码
计算机中的有符号数有三种表示方法,即原码、反码和补码。三种表示方法均有符号位和数值位两部分,符号位都是用0表示“正”,用1表示“负”,而数值位,三种表示方法各不相同。
-
原码:前面讲述的二进制数没有正负之分,原码在原来的二进制数的前面加了以为符号位,0表示正数,1表示负数。例如,+11的原码为00001011,-11的原码就是10001011。
原码不能直接参加运算,可能会出错。例如数学上,1+(-1)=0,而在二进制中00000001+10000001=10000010,换算成十进制为-2。显然出错了。所以,原码的符号位不能直接参与运算,必须和其他位分开,这就增加了硬件的开销和复杂性。
-
反码:反码通常是用来由原码求补码或者由补码求原码的过渡码。如果原码是正数,则反码与原码一样,如果原码是负数,则符号位不动,其余各位全部取反(0变1,1变0)。例如,+11的原码为00001011,+11的反码为00001011;-11的原码为10001011,-11的反码为11110100。
-
补码:在计算机系统中,数值一律用补码来表示和存储。原因在于,使用补码,可以将符号位和数值域统一处理;同时,加法和减法也可以统一处理。正数的补码与反码一致(与原码一致),负数的补码,需要用反码+1。例如,+11的原码为00001011,+11的反码为00001011,+11的补码为00001011;-11的原码为10001011,-11的反码为11110100,-11的补码为11110101。
-
十进制运算在计算机中的过程:先将十进制数转为二进制原码,在将原码转为反码,最后转为补码,将两个补码进行二进制的运算,得到的结果也是一个补码,如果是正数,就是其本身(原码,反码,补码都一样);如果是负数,则需要将该数-1,在求其反码,就是最后的结果。
例如,(+5) + (-11) = (-6):(假设以8位二进制数存储)
- 原码: +5 = 0000 0101 -11 = 1000 1011
- 反码:0000 0101 = 0000 0101 1000 1011 = 1111 0100
- 补码:0000 0101 = 0000 0101 1111 0100 = 1111 0101
- 运算:0000 0101 + 1111 0101 = 1111 1010(如果由结果比规定的存储位数多,则丢弃高位多余的数字,不影响结果)
- 由结果求原码:1111 1010 = 1111 1001,1111 1001 = 1000 0110(十进制的-6)。
1.3.4 其他进制
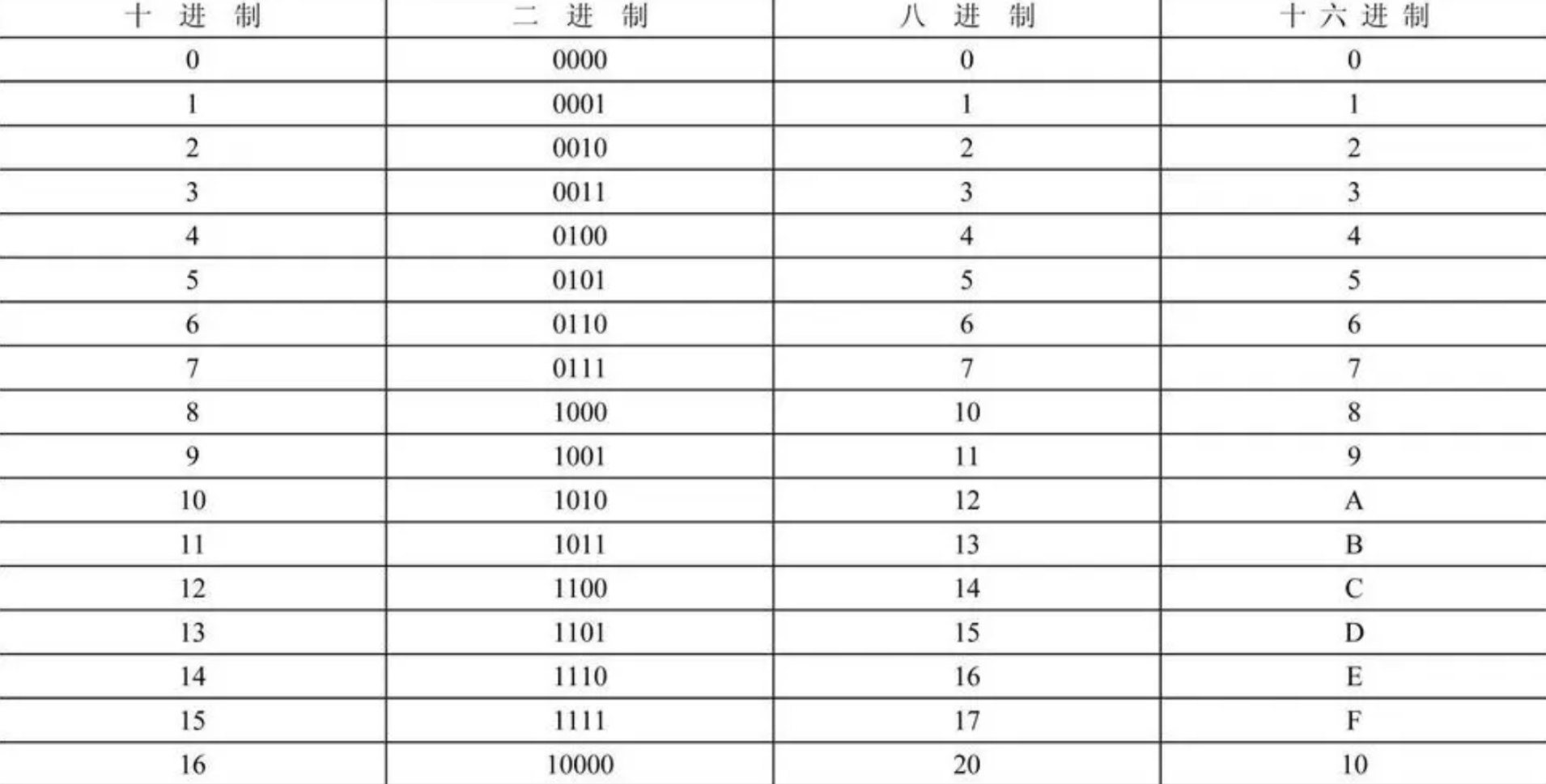
十六进制主要是为了简短地表示二进制,和一些非常大的数。例如,十进制数57,在二进制写作111001,在16进制写作39;十进制数12345678,二进制中为101111000110000101001110,用16进制表示为bc614e。如今的16进制则普遍应用在计算机领域,这是因为将4个位元(Bit)化成单独的16进制数字不太困难。1字节可以表示成2个连续的16进制数字。可是,这种混合表示法容易令人混淆,因此需要一些字首、字尾或下标来显示。
第二章 基本数据类型
2.1 布尔型(bool)
布尔类型只有两个值:True和False,分别代表真和假,常常用来做判断。可以用数字表示,0表示False,非零数字表示True(常常用1来表示)。
2.2 整型(int)
2.2.1 python中的整型
整型就是整数,与生活中的一样,也有正负之分。在python中,整型有两种用途,一是用来参与数学运算,二是用来表示布尔值,0表示False,0之外的整数表示True(默认用1表示)。
整型和下面讲的浮点型一样,都是数字,数学运算必须用数字,而不是字符串(例如,"3"就是一个字符串,不能参与数学运算)。因此,很多时候,必须要将这种纯数字的字符串强制转换为整型或浮点型(例如,上面的"3",就必须转换:int("3"))。
在条件判断中,也可以使用:
get_char = input()
if len(get_char):#返回字符串的长度,有长度(非零数字)代表真,执行if里的语句
print(get_char)
else:#没有长度(数字为0)代表假,执行else里面的语句
print("没有输入内容。")
2.2.2 算术运算符
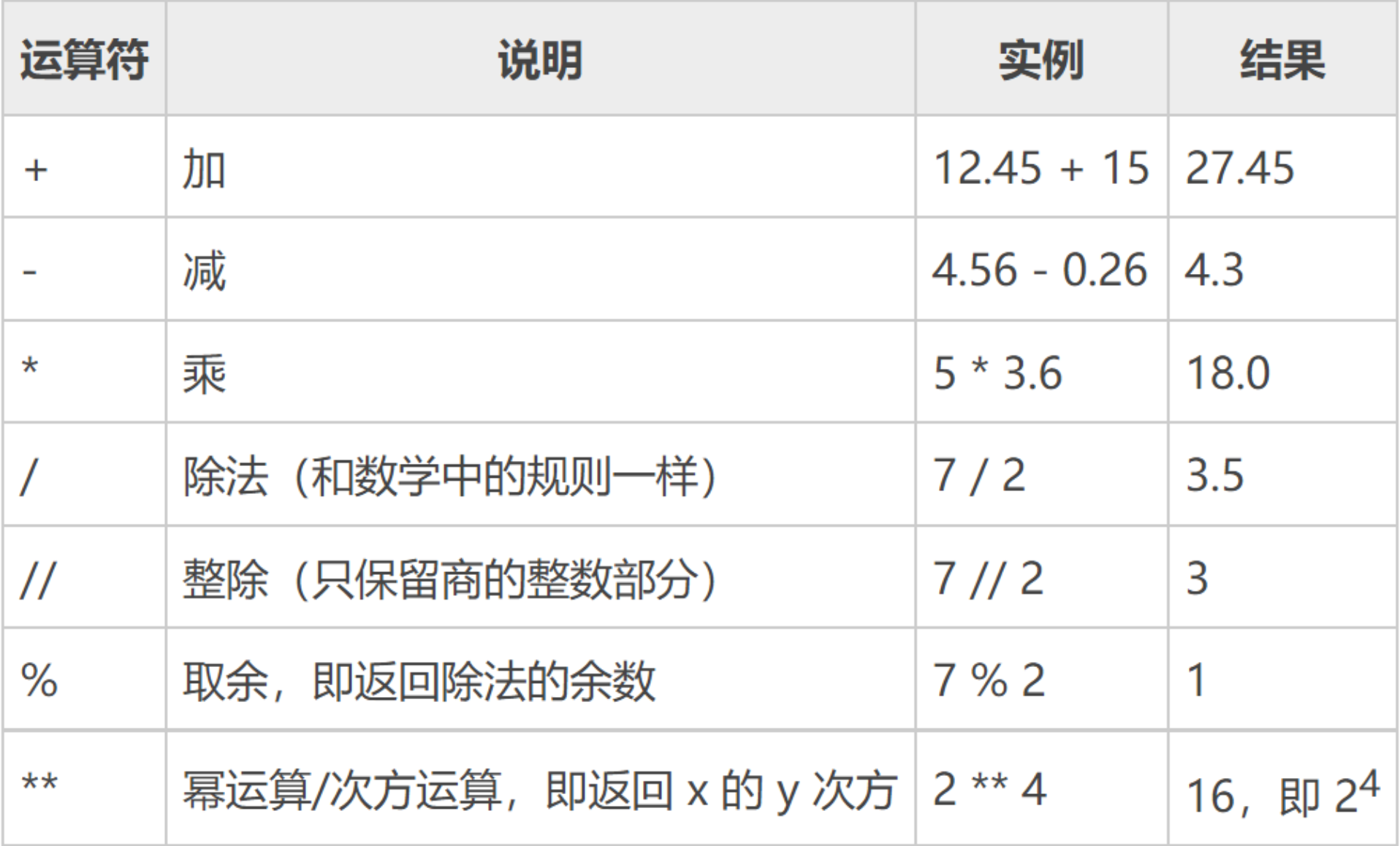
2.3 浮点型(float)
2.3.1 python中的浮点型
浮点型就是生活中的小数,编程语言中基本上都有这个概念,但是和其他语言不同,其他语言的整型和浮点型在做数学运算的时候,结果往往是一个整数(丢弃了小数部分),而python中,只要有浮点型参与运算,结果都是一个小数(3+2.0 = 5.0),与日常生活非常契合。
2.3.2 分数
python和其他很多语言一样,没有分数这种类型,但是python提供了一个标准库——fractions,里面有一个类Fraction,可以用来表示分数(注意使用的时候要先导入)。
from fractions import Fraction #导入Fraction
#将小数转为分数
num = Fraction(3.14)
print(num)
#分数的表示
num = Fraction(7, 3)#Fraction(分子, 分母)
print(num)
#分数参与数学运算,结果以分数表示
result = Fraction(3, 5) + 2
print(result)
#分子分母也可以是分数(与生活中的数学非常契合)
num = Fraction(Fraction(3, 5), 2)#但不能是小数,生活中也没人这样表示
print(num)
2.4 字符串(str)
2.4.1 python中的字符串
在编程语言中,都有字符串这个数据类型,但是python和其他一些语言不同,python中,只有字符串,而没有字符这种数据类型。python规定,单个的字符,也是字符串。
由于没有字符数据类型,因此python中的字符串,既可以用单引号包裹内容,也可以用双引号包裹内容,甚至可以用三引号。但是注意,如果内容本身带有某一种引号,外面包裹的引号就要用其他两种表示。例如,'hello' 就应该表示成 " 'hello' "(为了方便展示,所以才加了空格)。python程序员,一般都习惯用单引号。
2.4.2 常用方法
-
不管是什么方法,都不会对原来的字符串修改(可以理解为python先将原字符串复制了一份,然后再对这个副本进行修改,并将最后的结果返回),如果要想修改原字符串,可以将修改后的结果赋值给原来的那个变量名。
-
强制类型转换:有时候,需要将数字和一些文字拼接在一起输出,如果使用'+'拼接,那么就必须将数字转为字符串。
a = 3 b = 2 print("3+2的结果是"+str(a+b)) -
索引取值:字符串中的每个字符,都叫做该字符串的元素;并且每个元素都有一个序号,这个序号就叫做索引,从左到右开始排序,第一个元素的索引是0。可以根据索引,获取到具体的某一个元素。
name = "BrankYeen" print(name[0])#第一个元素 print(name[3])#第四个元素 print(name[-1])#索引值可以是负数,-1表示从右往左的第一个元素 -
分割字符串
string = "Hello@World@ hello@brankyeen" words1 = string.split('@')#分割出来的内容会放到列表中 words2 = string.split()#默认以空格分割 print(words1, words2) -
去除两边的内容
string = " @@@@Hello@World@ hello@brankyeen@@@ " string = string.strip()#默认去除空格 print(string) string = string.strip('@')#只能去除最外面的字符 print(string) -
替换原有的内容
string = " @@@@Hello@World@ hello@brankyeen@@@ " string = string.replace(' ', "")#将空格替换掉,默认全部替换 print(string) string = string.replace('@', '#', 2) print(string) -
找到元素第一次出现时的索引
name = "BrankYeen" index_n = name.find('n') print(index_n) -
大小写
#将所有字母全部转为小写 string = "HelloWorld" string = string.lower() print(string) #将所有字母全部转为大写 name = "brankyeen" name = name.upper() print(name) #将每个单词的首字母大写,以空格分开的字母才认定为单词 string = "helloworld brank yeen" string = string.title() print(string) #将整个句子的首字母大写 string = "i love python" string = string.capitalize() print(string) -
控制字符串的长度
#原字符串居中,填充的字符在两边 string = "HelloWorld" string = string.center(30, '@') print(string) #原字符串靠左,填充的字符在右边 string = "HelloWorld" string = string.ljust(30, '@') print(string) #原字符串靠右,填充的字符在左边 string = "HelloWorld" string = string.rjust(30, '*#') print(string) #原字符串靠右,用字符0填充在左边 num = "3854" num = num.zfill(6) print(num) -
字符串的拼接
# 1.+:效率最慢,不建议使用 str1 = "Brank" str2 = "Yeen" str3 = "19" print(str1+str2+' '+str3) # 2.f"其他内容{变量}其他内容":效率最快,但仅支持python3.6及以后的版本 name = "Brank Yeen" age = 19 print(f"{name}的年龄是{age}岁。") # 3."原有的内容{}".format():效率居中,但支持所有的python版本 string = "{name}的年龄是{age}岁。".format(name="BrankYeen", age=19) print(string) # 4."原有的内容%占位符"%():效率比第三种低,但支持所有的python版本 string = "%s的年龄是%d岁"%("BrankYeen", 19) print(string) #第四种方法常用来控制小数的位数 PAI = 3.1415926 print("%.2f"%(PAI)) age = 19 print("%.1f"%(age))#如果是整数,小数点后面的0依然会显示出来 # 5."字符".join():将可循环对象的每个元素用该字符拼接起来(前提是每个元素都必须是字符换类型) string = "helloWorld" print('~'.join(string)) -
判断字符串的组成:is系列
#判断字符串是否有纯数字组成 nums = "1314520" print(nums.isdigit())#是返回True,不是返回False #判断字符串是否有纯小写字母组成 string = "HelloWorld" print(string.islower()) #判断字符串是否有纯大写字母组成 string = "ILOVEU" print(string.isupper()) #判断字符串是否全由空格组成 name = "brank yeen" print(name.isspace()) #判断字符串中,每个单词的首字母是否是大写 name = "Brank Yeen" print(name.istitle()) #还有其他的is方法,自行查阅 -
判断指定内容是否在/不在字符串中
string = "I love Python." print("Python" in string)#存在返回True,不存在返回False print("love" not in string)#不存在返回True,存在返回False
2.5 列表(list)
2.5.1 列表的定义
列表是一种组合数据类型,用于有序地存储一系列数据,相当于其他语言中的数组,但是python中的列表,功能更加强大,可以存放其他任意类型的数据,而且方法极其丰富。
两种定义方式:1.array = [] 2.array = list()
2.5.2 列表的嵌套
B列表作为A列表的元素,这种行为称作列表的嵌套。
chars = [1, 2, 3, ['aa', 'bb', 'cc']]#列表['aa', 'bb', 'cc']嵌套在列表chars中
print(chars[3])
2.5.4 遍历列表
在遍历列表的时候,如果列表中的所有元素,都是具有相同元素个数的组合数据类型,那么可以同时遍历该组合类型。
for 循环遍历列表及组合数据类型的元素:
#浅遍历
chars = [[11, 22, 33], ['aa', 'bb', 'cc']]
for item in chars:
print(item)
#深遍历
chars = [[11, 22, 33], ['aa', 'bb', 'cc']]
for item1, item2, item3 in chars:
print(item1, item2, item3)
2.5.5 常用方法
-
强制类型转换
string = "HelloWorld" character_1 = list(string) character_2 = [string] print(character) -
追加元素
num = [11, 22, 33] num.append(44)#在列表的末尾添加元素 print(num) -
插入元素
num = [11, 22, 33] num.insert(2, 44)#insert(索引,元素)将元素插入到指定索引的位置 print(num) -
将可循环对象的每个元素添加到列表中
character = list("Hello") string = "World" character.extend(string) print(character) -
删除元素
# 1.pop(索引) string = list("HelloWorld") result = string.pop(5)#返回删除的元素,默认删除最后一个 print(result, string) # 2.remove(元素) string = list("HelloWorld") result = string.remove('o')#删除指定的元素(只删第一个),没有返回值 print(result, string) # 3.del list[索引] string = list("helloworld") del string[5] print(string) # 4.list.clear() string = list("helloworld") string.clear()#清空列表 print(string) -
倒转列表
string = list("HelloWorld") string.reverse()#将列表元素反过来排列 print(string) -
根据ASCII码排列元素
string = list("HelloWorld") string.sort(reverse="False")#根据ASCII码,从小到大排列元素(升序),当reverse="True"时,降序排列元素,默认为false print(string)
2.6 元组(tuple)
元组跟列表一样,也是一个有序存放一些列数据的容器,可以根据索引取值。但是,元组中的元素不能够更改,至少不能全部更改(每个数据都有一个自己的内存地址,只要内存地址没变,python就允许。例如,元组中有个元素是3,这个3有自己的内存地址,就不能够改成在另一个内存地址的5;但是,如果元组中某个元素是一个列表,那么该元素的地址就是整个列表的地址,是一块区域,只要不删除列表,这个区域的地址就不会变)。元组主要是用来放不可变数据类型的(当然元组本身也是一个不可变数据类型),因此不会对元组中的元素进行操作。如果元组中的某个元素是一个可变的数据类型,只要不改变该元素的内存地址,可以更改该元素中的元素(一般没有人这么干)。
元组主要是用来存放和读取元素的,因此,没有太多的操作,常用的只有两个索引通用方法(详见2.9.1)。
2.7 字典(dict)
2.7.1 字典的创建
字典是一个专门存放变量名和变量值的容器,只不过赋值语句中的等号要写成冒号,字典中的每个元素(特殊的赋值语句)叫做键值对,变量名叫做键,变量值叫做值。字典没有顺序,但是可以通过索引取值(之前定义的索引不够准确,python中,除了字典以外,其他数据类型的索引都是整数,根元素的顺序有关)。
键的命名规则:可以是所有的不可变数据类型(整型、浮点型、字符串、元组)
创建字典:
#1.普通创建
info = {
"name" : "BrankYeen",
"age" : 19,
"height" : 178
}
print(f'{info["age"]}岁的{info["name"]}身高是{info["height"]}')
#2.以实例化对象的方式创建
info = dict(name="BrankYeen", age=19, height=178)
print(f'{info["age"]}岁的{info["name"]}身高是{info["height"]}')
#3.使用字典生成式
index = int(input())
week_days = [(1, "Monday", "Sunny"), (2, "Tuesday", "Rainy"), (3, "Wednesday", "Sunny"), (4, "Tursday", "Rainy"), (5, "Friday", "Sunny"), (6, "Saturday", "Rainy"), (7, "Sunday", "Rainy")]
days = {index:day for index, day, weather in week_days}
print(days[index])
#4.使用fromkeys函数
parameters = ("name", "age", "height", "weight")
info = dict.fromkeys(parameters, "None")#第一个参数为存放键名的容器,第二个参数表示键值,默认为None
print(info)
2.7.2 常用方法
-
追加元素
info = dict(name="BrankYeen", age=19) info.update(height=178)#字典中不存在改键,就添加 info["weight"] = 60#字典中不存在该键,就添加 print(info) -
修改元素
info = dict(name="BrankYeen", age=19, height=178) info.update(name="brankyeen")#字典中存在该键,就修改 info["age"] = 18 #字典中存在改键,就修改 print(info) -
判断键的存在
student = dict(name="BrankYeen", age=19, height=178) result1 = student.get("name", "不存在")#第一个参数为查找的键名,第二个参数为找不到时返回的结果(默认返回None),找得到返回对应的键值。 result2 = student.get("weight") print(result1, result2) -
获取所有的键和值
student = dict(name="BrankYeen", age=19, height=178) keys = student.keys()#返回的是可视图对象 values = student.values()#返回的是可视图对象 key_value = student.items()#返回的是可视图对象 print(list(keys))#将对象转为列表 print(list(values))#将对象转为列表 print(list(key_value))#将对象转为列表 -
删除元素
student = dict(name="BrankYeen", age=19, height=178) result = student.pop("name")#根据键名删除元素,返回删除元素的值 print(result) print(student) student = dict(name="BrankYeen", age=19, height=178) result = student.popitem()#删除字典中的最后一个元素,并返回删除的键值对 print(result) print(student)
2.8 集合(set)
2.8.1 集合的定义
python中的集合与数学中的集合一样,没有重复的元素,集合中的元素也没有顺序,两个集合可以进行交并补的运算。
集合可以使用{}定义,也可以使用set()实例化对象的方式进行创建,但是空集合只能通过实例化对象的方式创建,因为{}已经用于创建字典了。
创建字典:
nums = {11, 22, 33, 44, 22, 66, 33}
chars = set()#创建空集合
print(nums)#集合会默认去除重复的元素,元素没有顺序,打印的结果不一定和定义时的顺序一样。
2.8.2 集合的运算
set_a = {11, 22, 33, 44, "aa", "bb", "cc", "dd"}
set_b = {44, 55, 66, "dd", "ee", "ff"}
intersection = set_a & set_b#交集
unionsection = set_a | set_b#并集
difference = set_a - set_b#差集,只出现在set_a中,set_b中没有
not_intersection = set_a ^ set_b#并集减去交集剩余的部分
print(intersection)
print(unionsection)
print(difference)
print(not_intersection)
2.8.3 常用方法
-
添加和移除元素
section = {11, 22, 33, 44} setction.add(55)#添加元素 print(section) section.update(66)#添加元素 print(section) section.remove(22)#删除元素 print(section) section.pop()#随机删除元素 print(section) section.clear()#清空集合 print(section) -
集合运算
set_a = {11, 22, 33, 44, "aa", "bb", "cc", "dd"} set_b = {44, 55, 66, "dd", "ee", "ff"} intersection = set_a.intersection(set_b)#交集 unionsection = set_a.union(set_b)#并集 differsection = set_a.difference(set_b)#差集 print(intersection) print(unionsection) print(differsection) -
判断子集
set_a = {11, 22, 33, "aa", "bb", "cc"} set_b = {11, 22, 33} print(set_a.issuperset(set_b))#判断set_b是否是set_a的子集(判断set_a是否是set_b的父集) print(set_b.issubset(set_a))#判断set_b是否是set_a的子集 -
判断是否有交集是否是空集
set_a = {11, 22, 33, "aa", "bb", "cc"} set_b = {11, "dd", "ee"} print(set_a.isdisjoint(set_b))#判断set_a和set_b的交集是否是空集
2.9 索引与切片
2.9.1索引相关函数
前面讲过索引的概念和使用,下面介绍两个有关具有索引的数据类型,它们的通用函数。
# 1.count(内容):判断改内容出现的次数
name = "BrankYeen"
count_e = name.count('e')
print(count_e)
# 2.index(元素):判断该元素第一次出现时的索引
name = "BrankYeen"
index_e = name.index('e')
print(index_e)
2.9.2 切片
列表、元祖、字符串都有索引这个属性,但是一般的索引只能取到一个元素,而使用切片就可以取到多个位置的元素。
语法:str[起始索引:结束索引:步长]
起始索引:表示开始截取的元素位置。如果起始索引是正数,表示从左往右开始找(第一个元素的索引为0);如果起始索引是负数,表示从右往左找到该元素(此时第一个元素的索引为-1)。
结束索引:表示截取到那个元素为止。与起始索引一样,如果是正数,从左往右找到该元素,如果是负数,从右往左找到该元素。结束索引可以省略,表示从起始索引开始,截取到最后一个元素(注意不要省略那个冒号)。注意这个结束索引,不包含在截取的范围内,只能截取到它左边的第一个元素(也就是说,这个截取范围是一个前闭后开的区间)。
步长:起始索引和结束索引规定了截取的范围,而步长规定了在该范围中,向哪个方向截取元素,以及每一次跨越的步数(切片就像人走路,步长为2,代表走两步获取元素,也就是中间要隔一个元素)。步长为正,表示在该范围中,从左往右走,步长为负表示从右往左走;步长的绝对值表示走的步数。
以列表为例,演示切片:
string = list("HelloWorldhellobrankyeen")
#起始索引和结束索引只是找到开始元素和结束元素的位置,不决定截取的方向
result1 = string[5:20:1]
result2 = string[-19:-4:1]
print(result1, result2)
#步长的正负表示截取的方向
result3 = string[5:20:1]
result4 = string[5:20:-1]
print(result3, result4)
#步长的绝对值表示走的步数
result5 = string[5:20:2]
result6 = string[5:20:3]
2.10 *和组合数据类型
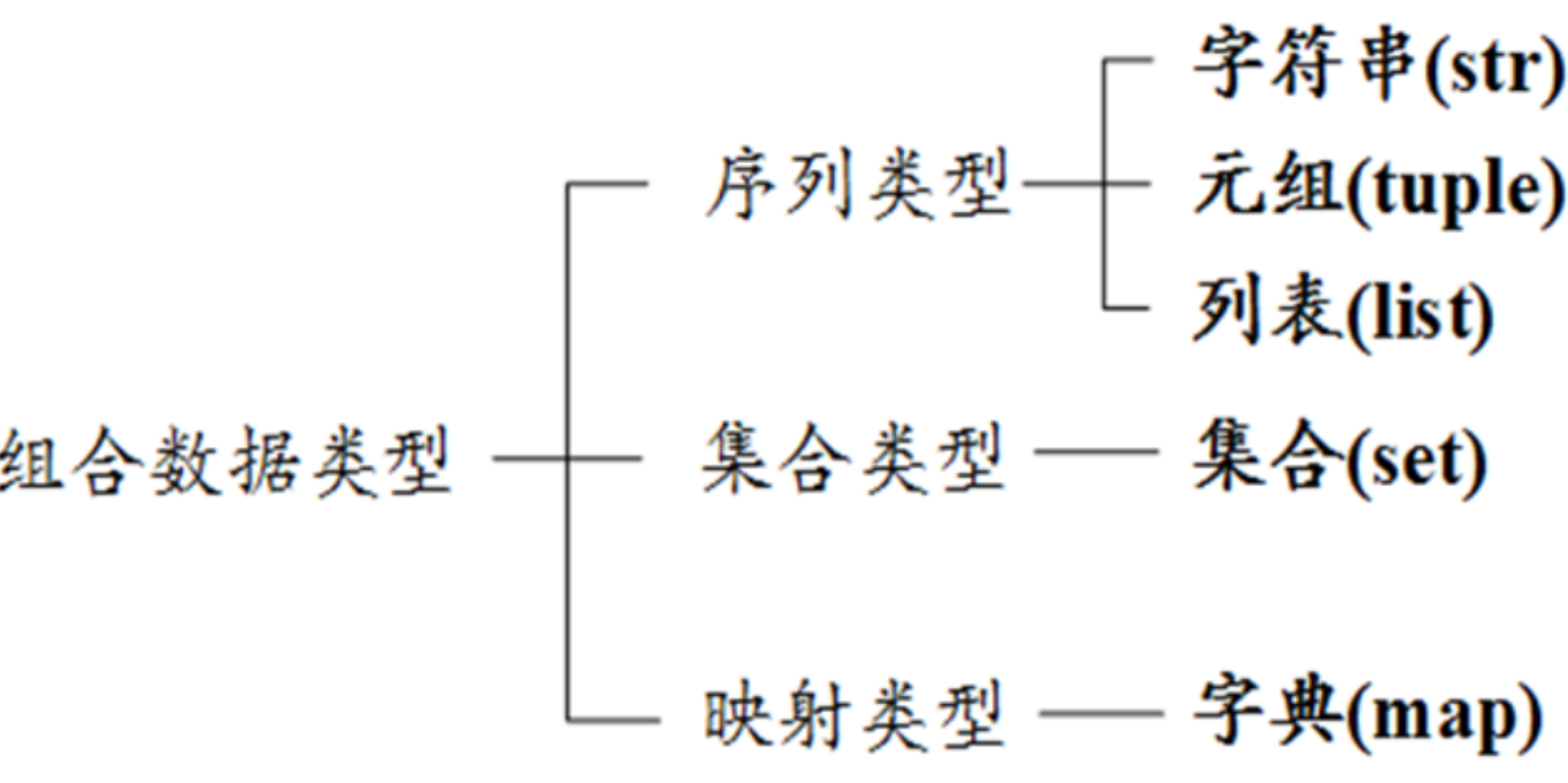
# *用来表示乘法运算符
print(3*2)
# *变量名,用来在赋值的时候,接收多余的数据,并存放到列表中
a, *b = 1, 2, 3, 4, 5
print(a)
print(b)
# *组合数据类型,将组合数据类型解压缩,取出里面所有的元素
name = "brankyeen"
nums = [11, 22, 33, 44]
info = dict(name="BrankYeen", age=19, height=178)
print(name, *name)
print(nums, *nums)
print(info, *info)
# *参数名,表示不定长参数,用来接收多余的、任意个数的实参,并存到元组中
def add(x, y, *args):
print(*args)#解压缩args元组
add(11, 22, 33, 44, 55, 66)
# **参数名,表示不定长参数,用来接收多余的、任意个数的字典或关键字参数,存到字典中
def get_info(name, age, **kwargs):
print(name, age, kwargs)
get_info("BrankYeen", 18, height=178, weight=60)
第三章 流程控制
3.1 if 条件语句
3.1.1 if 语句
用判断条件控制代码的执行,如果条件成立,则执行对应部分的代码(其他所有部分的代码都不会执行),否则不执行。
-
基本的条件判断:
a = 3 b = 2 if a+b > 10:#如果条件成立,执行该部分的代码 print("这两个数的结果大于10") else:#否则(条件不成立),执行这个部分的代码 print("这两个数的结果小于10") -
多条件判断
a = 3 b = 2 if a+b > 10: print(">10") elif a+b = 9:#如果上面的条件不成立,再判断这个条件 print("=9") elif a+b < 10:#如果上面的条件不成立,再判断这个条件 print("<10") else:#如果上面所有的条件都不成立,执行这部分的代码 print("<0")
练习:
用户输入星期几,程序输出对应的英文单词。例如,用户输入1,则输出Monday;用户输入2,则输入Tuesday。
get_day = int(input())
if get_day == 1:
print("Monday")
elif get_day == 2:
print("Tuesday")
elif get_day == 3:
print("Wednesday")
elif get_day == 4:
print("Tursday")
elif get_day == 5:
print("Friday")
elif get_day == 6:
print("Saturday")
elif get_day == 7:
print("Sunday")
else:
print("您输错了!")
#简写多个简单的elif
get_day = int(input())
week_days = [(1,"Monday"), (2, "Tuesday"), (3, "Wednesday"), (4, "Tursday"), (5, "Friday"), (6, "Saturday"), (7, "Sunday")]
for day, word in week_days:#原理是2.5.4遍历列表
if get_day == day:
print(word)
3.1.2 三目运算符
三目运算符又叫做三元表达式,用于一行写完简单基本的条件判断。
语法:代码1 if 判断条件 else 代码2:如果条件成立,执行代码1,否则执行代码2。
# 原来的写法
a = 3
b = 2
if a>b :
print(a)
else:
print(b)
#三目运算符
a = 3
b = 2
print(a) if a>b else print(b)
# ###################################################################
a = 5
b = 10
maximum = a if a>b else b
print(maxinum)
3.1.3 嵌套
一个物体嵌入到另一个物体内,叫做嵌套。在开发中,一般是指两个相同的类型嵌在一起,有许多嵌套,例如if语句的嵌套,for循环嵌套,while循环嵌套,函数嵌套等等。
以if判断嵌套为例:
number = 10
if number<=10 :
if number<5:
print("这个数小于5")
else:
print("这个数在5到10之间")
else:
print("这个数大于10")
3.2 for 循环
3.2.1 for 循环
循环用于处理步骤重复非常多的问题。
语法:for 元素 in 范围:代码。依次获取范围中的每个元素,获取一次,执行一遍代码。如果,循环到某一次是,不想再进行剩余的循环,可以在代码中写上break关键字,来结束循环。
#示例1
for i in "abcdefg":
print(i)
#示例2
nums = [11, 22, 33, 44, 55]
for item in nums:
print(item)
#示例3
for i in range(0, 10):
if i!=4 :
print(i)
else:
break
练习:求1到100的和。
sum = 0
for i in range(0, 101):
sum += i
print(sum)
利用for循环,输出斐波那契数列前50项中,所有的偶数
nums = [0, 1, 1]
#数列的前50项
for i in range(50):
next_num = nums[len(nums)-2] + nums[len(nums)-1]
nums.append(next_num)
#输出偶数
for item in nums:
print(item, end=" ") if item%2==0 else 1
3.2.2 列表生成式:利用for循环,快速创建列表
语法:[元素表达式 for 元素 in 范围 if 判断条件]。如果if条件成立,将元素表达式的结果添加到列表中。
#示例1
nums = [i for i in range(0, 101) if i%2 = 0]
print(nums)
#示例2
nums1 = [11, 22, 33, 44, 55, 66]
nums2 = [nums1[index] for index in range(0, len(nums1)) if index%2 != 0]
print(nums2)
3.3 while 循环
语法:while 条件:代码。条件成立的时候一直执行代码,结束循环放在代码内,如果没写就成了死循环。
while True:#条件为真,进入循环
#进来循环之后,一直执行下面的代码
get_num = int(input())
if get_num == 0:#当用户输入的数字是0时,结束掉循环
break
else:#否则,就打印用户输入的数字
print(get_num)
用while循环求1到100的和:
sum = 0
i = 1
while True:
if i == 101:
break
else:
sum += i
i += 1
print(sum)
利用while循环,输出斐波那契数列前50项中,所有的偶数
nums = [0, 1, 1]
#数列的前50项
while len(nums)<51 :
next_num = nums[len(nums)-2] + nums[len(nums)-1]
nums.append(next_num)
#输出偶数
for item in nums:
print(item, end=" ") if item%2==0 else 1
第四章 运算符
4.1 算术运算符
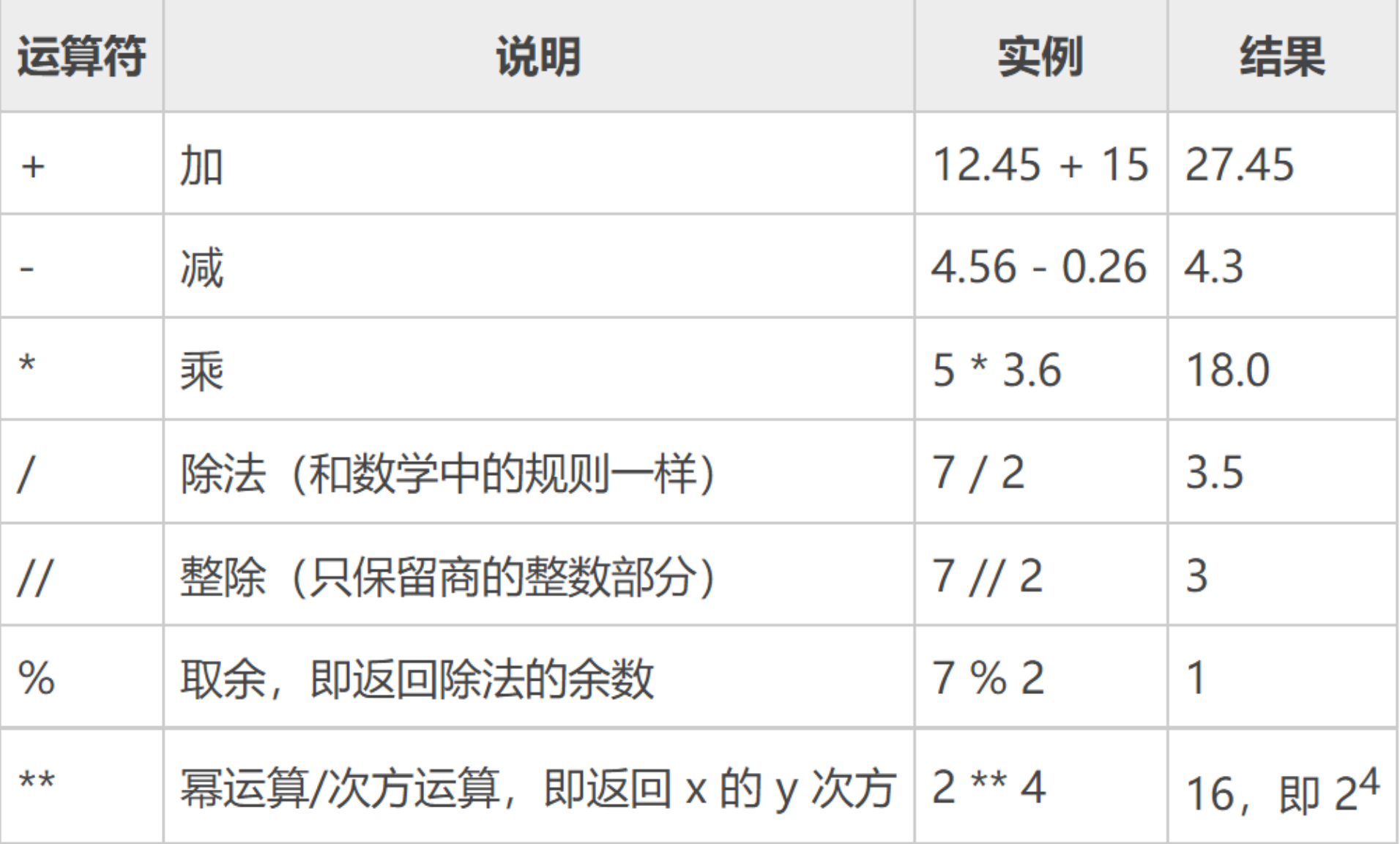
4.2 逻辑运算符
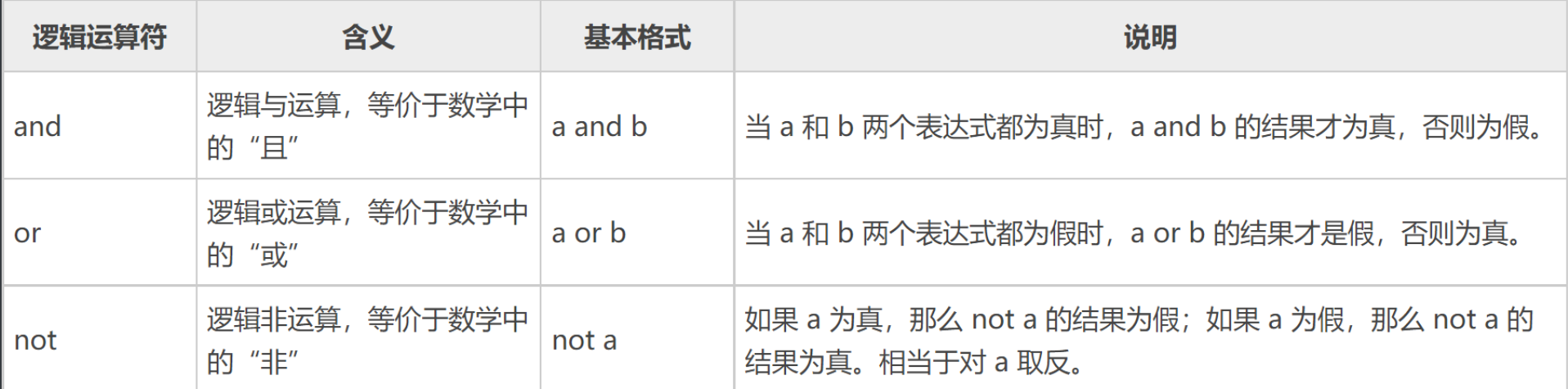
逻辑运算的结果为真或者为假,指的并不是返回的结果是True或者False,只要结果是0或None就代表假,其余任何结果都代表真。逻辑运算的本质:无论是and还是or,都是先判断左边的表达式,再判断右边的表达式,对于and,只要判断的过程中遇到假的结果,就停止判断,并返回该结果,否则返回最后一个表达式的结果;对于or,只要判断的过程中遇到的真的结果,就停止判断,并返回该结果,否则返回最后一个表达式的结果。
print(1 and 2)#1为真,继续判断,2也为真,返回最后一个表达式的结果:2
print(0 and 3)#0的结果为假,不再判断,返回假的结果:0
print(4 and "")#4的结果为真,继续判断,""是一个空字符串(None),返回家的结果:None
print(0 or [])#0为假,继续判断,[]为空,也是假,返回最后一个表达式的结果:None
print(2 or 0)#2为真,不再判断,返回真的结果:2
print(0 or 1)#0为假,继续判断,1为真,返回真的结果:1
#逻辑运算常用于条件判断中
a = 3
b = 2
if a and b:#相当于if 2,并不是所认为的if True
print("哈哈")
else:
print("呜呜")
a = None
b = 0
if a or b:#相当于if 0,并不是所认为的if False
print("哈哈")
else:
print("呜呜")
4.3 比较运算符
比较运算符又叫关系运算符,用来判断大小。
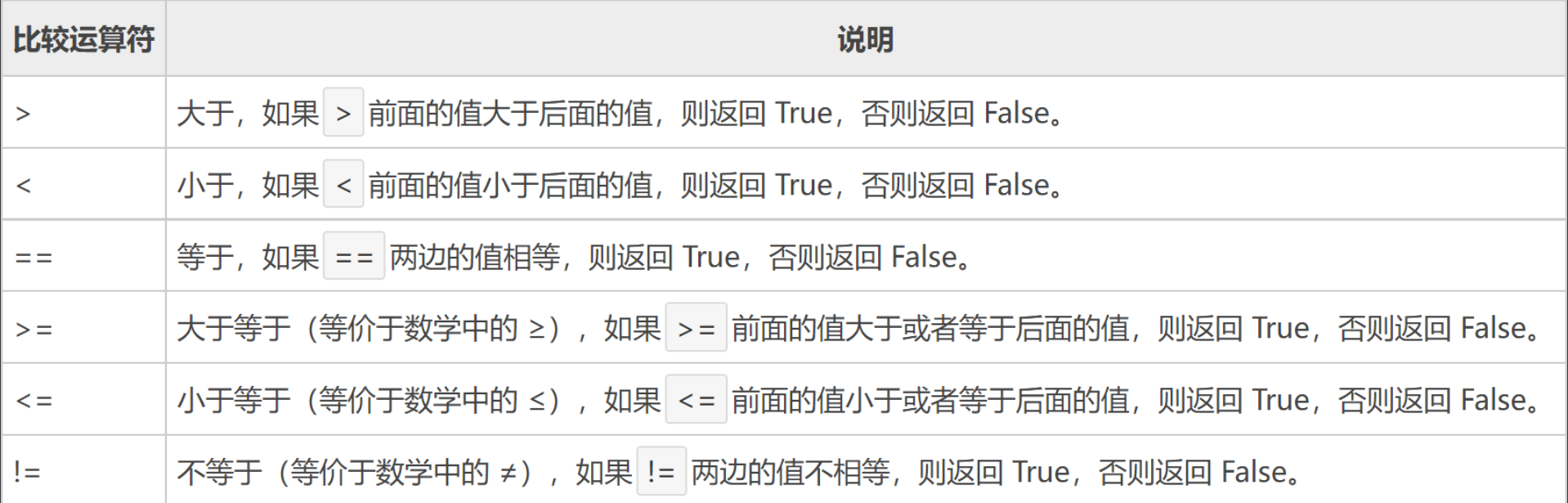
print(3 > 2)
print(3 < 2)
print(3 == 2)
print(3 >= 2)
print(2 <= 3)
print(2 != 3)
#用于条件判断
a = int(input("请输入一个整数>>>"))
b = int(input("请输入一个整数>>>"))
print("您输入的两个数不等。") if a!=b else print("您输入的两个数相等。")
4.4 赋值运算符
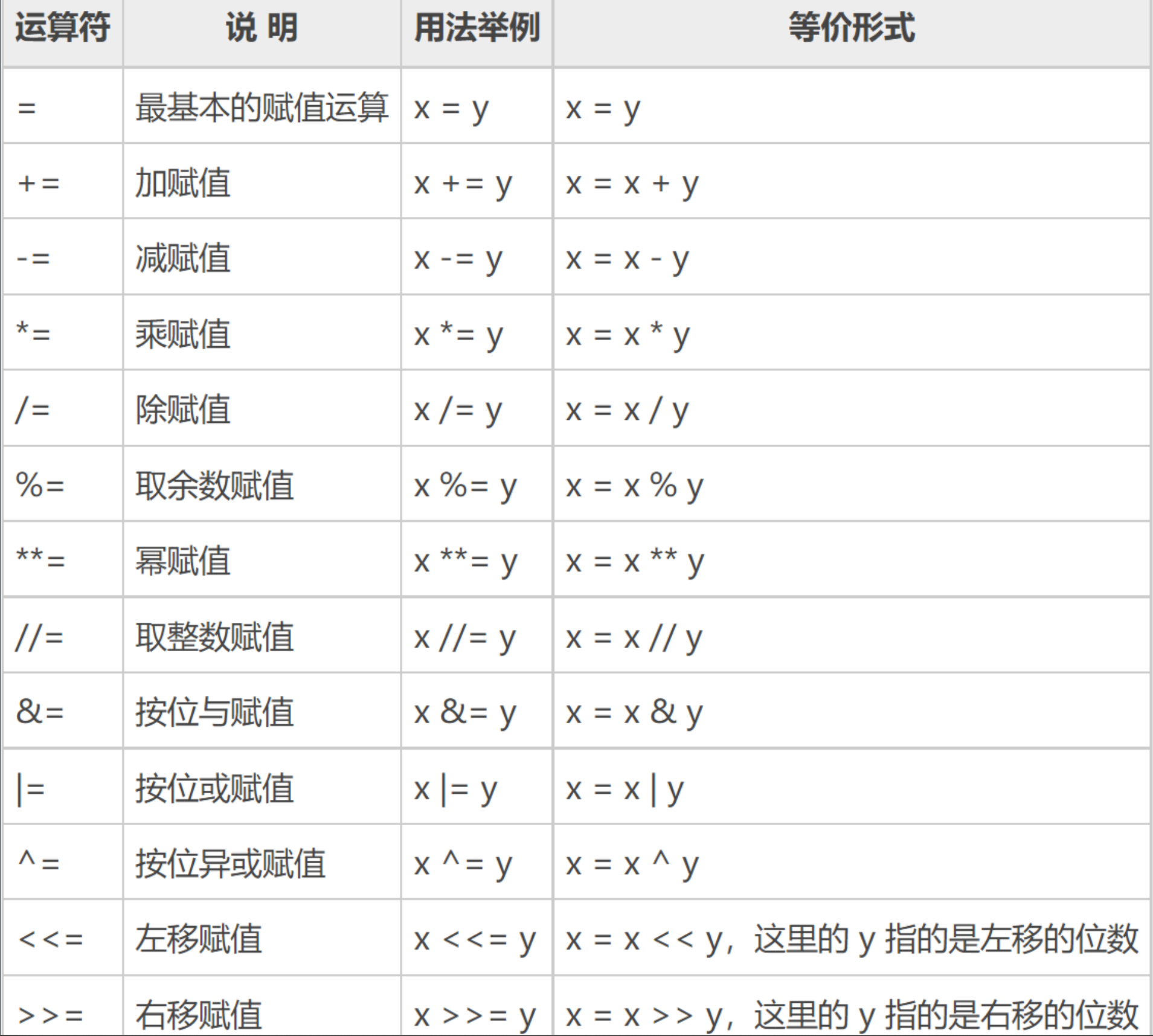
求1到100的和
sum, item = 0, 0
while item!=101 :
sum += item
item += 1
print(sum)
4.5 成员运算符
判断一个数据是否是另一个数据中的元素。
A in B:判断A是否是B的元素,如果是,返回True,否则返回False;
A not in B:判断A是否不是B的元素,如果不是,返回True,否则返回False。
word = "Python"
string = "I love Python."
print(word in string)
print("BrankYeen" not in string)
4.6 身份运算符

a = 1#a是1的对象
b = 2#b是2的对象
c = a#c与a指向同一对象
print(a is b)
print(c is a)
nums1 = [1, 2, 3]
nums2 = [2-1, 4-2, 6-3]#存放的是表达式
print(nums1, nums2)#print输出的时候,将nums2的表达式换成其结果
print(nums1 is nums2)
print(nums2 is not nums2)
4.7 位运算符
位运算:对两个二进制数据的每一位进行运算。
位运算符:只能操作整数类型,将整数转为二进制,在进行位运算。
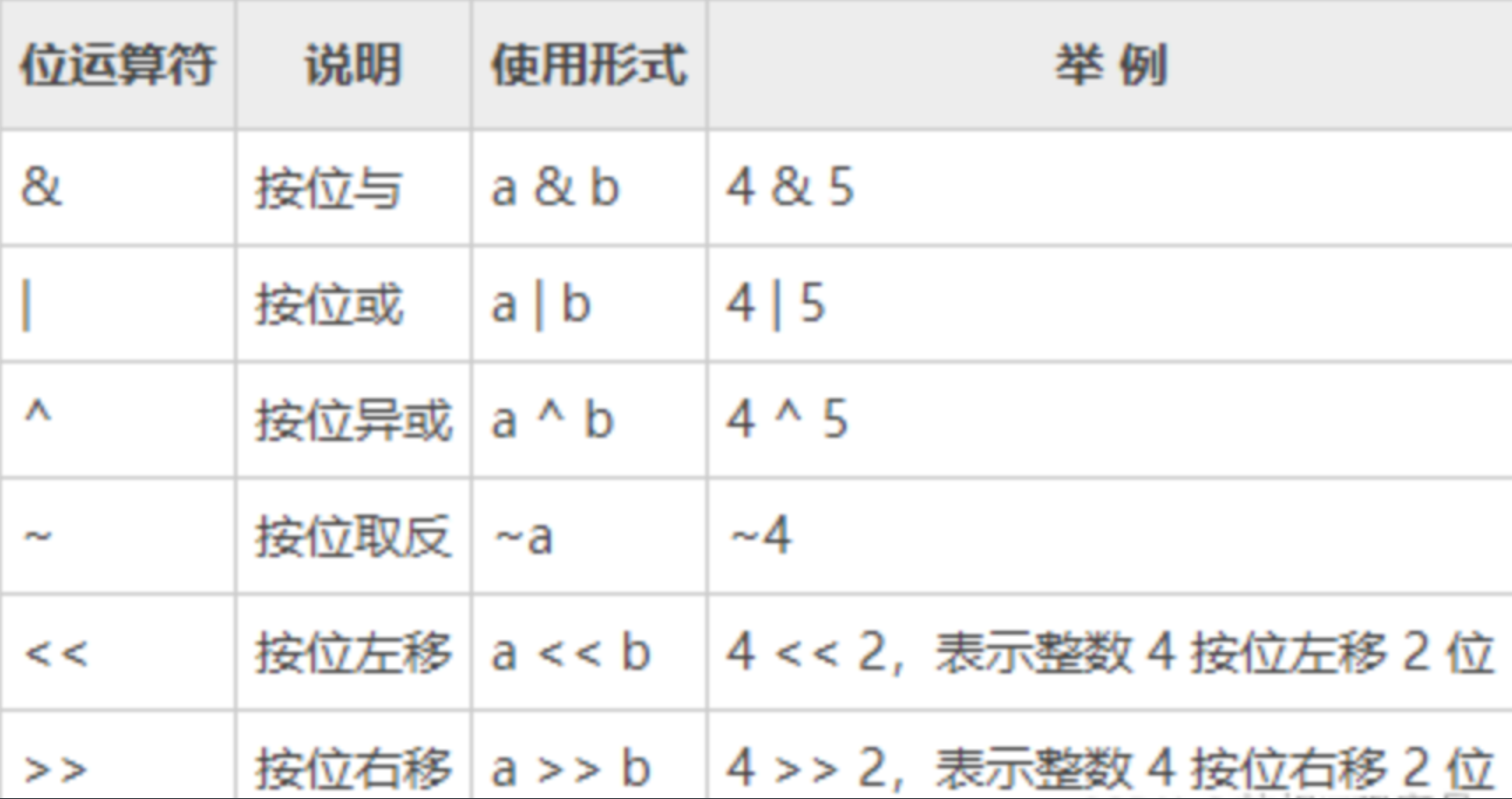
5 & 9:
5 = 0000 0101(前面还有0)
9 = 0000 1001
5&9=0000 0001
第五章 函数
函数是解决一类问题的模板,不仅可以解决当前的问题,还能处理其他类似的问题。没有函数也能编程,也能解决问题,但是函数存在的意义是解决代码复用性的问题,即在函数定义之后,再遇到类似的问题,只需调用即可,不需要再把代码写一遍。例如,range()函数可以生成指定范围内的整数,我们每次想要实现这种功能的时候,调用range()函数就行,不需要自己再把实现功能的代码写一遍。
5.1 函数的定义和调用
定义:def 函数名(参数列表):函数体。def 是定义函数的关键字,参数列表是实现这个功能要用到的一系列变量,函数体是利用参数实现功能的具体代码。
返回值:函数体在执行成功后产生的结果,并且这个结果会被返回。语法:return 结果。return 是关键字,只要函数体运行到return,就不再执行后面的代码,相当于循环中的break(可以只写return,不写结果)。
调用:变量 = 函数名(参数列表)。函数有参数,根据实际情况传入,没有参数,就不要传(传参就是给函数的参数赋值)。函数有返回值,根据实际情况用变量接收,没有返回值,就不要接收。
函数定义的时候,不会运行函数体,只有在调用的时候才会运行,即使函数体有语法或逻辑错误,只要不调用,程序运行时也不会报错(当然,开发工具会实时监测语法错误,并给出提示)。
#必须先定义,后调用
def sum(x, y):
print(x+y)#函数体
sum(2, 3)#函数有参数,调用的时候传入具体的值
#返回值
def sum(x, y):
result = x+y
return result#返回运行结果,并结束掉函数
result = sum(2, 3)#函数有返回值,调用的时候用变量接收返回值
print(sum(2, 3))#返回值可以直接拿来用,根据实际情况再接收
#函数在调用时才执行函数体
def sum(x, y):
sdlkjflnflkhsdiofjlkjdffslkjidolf
return abc
#sum(2, 3)#只要不调用,运行永远不会报错
5.2 参数
参数是函数名后面括号中的变量,是函数功能实现所要用到的数据,并且这个变量需要根据实际情况,在调用的时候赋值。
参数的分类:形式参数(形参)、实际参数(实参)、默认参数、关键字参数、可变长度参数。
形式参数:函数定义时的参数,没有具体的值,跟数学函数表达式中的自变量一样,没有具体的值,只起一个表示的作用,方便后面的函数体使用,例如 def sum(x, y)中的x,y就是形参;
实际参数:函数调用时的参数,即函数调用时被赋值的形式参数,有具体的值。
位置参数:函数调用时,按照形参的位置顺序传入的参数,例如sum(2, 3)中的2,3就是位置参数;
默认参数:函数定义时,已经被赋值的形式参数,有默认的值,当然,在调用的时候,可以根据需要更改,例如def sum(x, y, z=0)中的z就是默认参数;
关键字参数:函数调用时,以“参数名 = 参数值”的形式给形参赋值的参数。在参数较多或者只给一部分参数赋值的时候,可以使用,并且不用按照形参的位置顺序书写,例如 sum(y=2, x=3)中的y=2, x=3就是关键字参数;
可变长度参数:又叫不定长参数。用来接收任意个数的数据的特殊形参,有两种:*参数名,**参数名。第一种,用来接收多余的实参,存放到元组中;第二种,用来接收多余的字典或关键字参数,存放到字典中。第一种的参数名一般写成*args,第二种的参数名一般写成**kwargs。
函数定义或调用时,参数的顺序:位置参数,关键字参数,默认参数,不定长参数
def test(x, y, z=1, *args, **kwargs):
print(x+y+z)
print(args)
print(kwargs)
return
test(2, 3, 4, 5, age=18, height=178)
5.3 作用域
作用域就是变量发挥作用的区域。
分类:全局作用域、局部作用域、闭包作用域、内置作用域
全局作用域:最外层的区域,即与第一行代码同级的区域;
局部作用域:函数内或类中的区域,注意python不是以代码块作为区分的,例如,for循环中的区域不属于上面的四种分类,不讨论这个问题(按道理应该是局部)。因此,局部作用域只针对函数和类。
闭包作用域:闭包中的区域,即嵌套的子函数中的区域;
内置作用域:内置模块或内置函数中的区域。
-
变量搜索的优先级:先在同级区域中找,找不到再向上一级找(全局作用域>局部作用域>闭包作用域>内置作用域)。找到为止,找不到就报错。
#优先在同级区域中找 i = 0#在最外层,属于全局作用域 def print_i(): #这里面的区域是局部作用域 i = 1 print(i) print_i() #找不到,向上找 #示例1 i = 0 def print_i(): print(i) print_i() #示例2 i = 0 def print_i1(): i = 2 def print_i2(): print(i+3) print_i2() print_i1() -
跨作用域访问变量
#在局部或闭包中访问全局变量:通过global关键字申明 #示例1 i = 1 def change_i(): i = 2 change_i() print(i) #示例2 i = 1 def change_i(): global i#通过global关键字申明 i = 2 change_i() print(i) #子函数使用外层函数的变量:通过nonlocal关键字申明 def print_i1(): i = 1 def print_i2(): nonlocal i = 2#通过nonlocal关键字申明 print(i) print_i1() #使用其他区域的变量时,不能和本区域中的变量发生冲突 #示例1 i = 0 def print_i(): i = 1 global i#本区域中,已经定义了一个i,不能再把全局的i引入进来,否则会报错 i = 2 print(i) print_i() #示例2 def print_i1(): i = 1 def print_i2(): i = 2 nonlocal i = 2#本区域中已经定义了一个i,不能再把上一级的i引入进来 print(i) print_i2() print_i2()
5.4 函数的分类
根据不同的标准,可以将函数分为不同的类别。下面是一些基本的类别:
根据返回值分类:有返回值函数,无返回值函数
-
有返回值函数
def sum(x, y): return x+y#把结果返回 result = sum(2, 3) print(result) -
无返回值函数
def sayWord(word): print(word)#没有返回值 sayWord()
根据有无参数分类:有参函数、无参函数
-
有参函数
def sayMax(x, y):#定义了形参 return x if x>y else y result = sayMax(3, 5) print(result) -
无参函数
def saySorry():#没有定义形参 print("Sorry! Sorry! Sorry!") saySorry()
根据函数创建的对象:自定义函数、内置函数
-
自定义函数:自己定义的函数
def Max(x, y): return x if x>y else y -
内置函数:python官方定义的函数,并且内嵌到了python中,可以直接使用
maxinum = max(2, 3)#max()就是一个内置函数,不需要自己定义,也不需要额外引入
空函数:函数体为pass,没有具体的代码,主要用于构思解决问题的步骤
def getMax(x, y):
pass#具体的代码,一会再写
def sayMax(x):
pass
def appendMax(x):
pass
5.5 lambda表达式
- 用于表示简单的有返回值的函数
- 函数名 = lambda 【参数列表】:表达式 表达式的结果自动return
def func1(x, y):
return x+y
func2 = lambda x, y: x+y
print(func1(2, 3))
print(func2(4, 5))
5.6 闭包函数
一组特殊的嵌套函数:根据实际情况生成函数。内层函数的功能随外层函数的参数变化而变化,外层函数将内层函数最为返回值进行返回。这种好处是,可以根据实际情况生成一个函数,而且非核心代码放在外层函数,每次调用时,只调用内层函数,这样就能减少资源的开销,提高效率。
#普通函数的目的:直接解决问题
def power(num, power_num):
return num**power_num
print(power(2, 3))
print(power(3, 4))
#闭包函数的目的:根据实际情况生成函数
def power(power_num):
def calculate(num):
return num**power_num
return calculate
#生成平方函数
two_power = power(2)
result = two_power(3)
print(result)
#生成三次幂函数
three_power = power(3)
result = three_power(2)
print(result)
5.7 装饰器
装饰器采用闭包的形式,将函数名作为外层函数的参数传入,在内层函数中,结合其他代码使用该参数,使之成为一个新的函数,这个新函数就是这个内层函数(在不改变或者根本不触碰原代码的情况下,给函数添加功能。相当于把原函数的函数体复制过来,再加上一些新的代码,成为一个新的函数)。
#理解装饰器
def runTime(func):
def inner():
import time
start_time = time.time()
func()
end_time = time.time()
return end_time-start_time
return inner()
def sayHello():
import time
time.sleep(0.5)
print("Hello")
time.sleep(0.5)
def sayPython():
import time
time.sleep(0.5)
print("I love Python.")
time.sleep(0.5)
sayHello = runTime(sayHello)#runTime返回的是修改后的一个函数,这个函数对全局是没有名字的,因此要用一个变量来给函数命名。为了方便使用,采用原来的函数名。
print(sayHello())
sayPython = runTime(sayPython)
print(sayPython())
#以sayPython为例,上面的代码相当于把sayPython改成了这样:
def sayPython():
import time
start_time = time.time()
#下面四行是func()的部分
import time
time.sleep(0.5)
print("I love Python.")
time.sleep(0.5)
end_time = time.time()
return end_time-start_time
#标准的语法糖写法
def runTime(func):
def inner():
import time
start_time = time.time()
func()
end_time = time.time()
return end_time-start_time
return inner()
@runTime
def sayHello():
import time
time.sleep(0.5)
print("Hello")
time.sleep(0.5)
@runTime
def sayPython():
import time
time.sleep(0.5)
print("I love Python.")
time.sleep(0.5)
4.7 递归
- 函数自己调用自己
- 默认最大递归次数为1000
def func(i):
print(i)
i += 1
func(i)
func(0)
5.8 迭代器
在成千上万条数据的开发中,如果一次性全部将数据装到内存中,会大量消耗内存资源,大大降低运行效率,而迭代器能够根据实际情况将数据装到内存中,使用一条装一条,这样能够极大地减少资源开销,因此,适当地使用迭代器能够提升程序的质量。但是,在生产环境中,迭代器使用的频率并不高,只是某些文献或部分代码中会出现迭代器,遇到的时候要能看懂。
可迭代对象:可以被for循环遍历的对象。基本数据类型中,字符串、列表、元组、集合、字典的对象,都可以被for循环遍历,都属于可迭代对象。
创建一个可迭代类型的类:必须包含__iter__和__next__方法,iter方法中,必须返回一个可迭代对象(可以是自己,也可以是其他可迭代对象),next方法用来返回下一个元素。只要有这两个方法,这个类就是一个可迭代对象。
迭代就像while循环一样,一直在取值,哪怕next没有返回值了,也会取到None值,因此,必须要控制迭代的次数,否则就会无穷尽的取下去。常常在next方法中,最后一次返回值时,抛出异常:raise StopIteration
class Person:
def __init__(self) -> None:
self.persons = []
def add(self, name):
self.persons.append(name)
def __iter__(self):
self.index = 0
return self#有iter和next方法,自己就是一个可迭代对象了
def __next__(self):
if self.index<len(self.persons) :
index = self.index
self.index += 1
return self.persons[index]
else:
raise StopIteration
a = Person()
a.add("张三")
a.add("李四")
a.add("王五")
#使用for循环,遍历Person的对象a
for item in a:
print(item)
5.9 生成器
生成器是特殊的迭代器,也是一种特殊的函数,可以一步一步地生成数据(一系列数据,用生成器,每调用一次就生成一个,下一次调用生成下一个,不会一下子全部生成,减少了内存资源的占用)。
语法:yield 返回值。yield相当于普通函数中的return,只不过生成器函数在执行到yield的时候,会暂停执行,而不是终止执行,下一次调用函数的时候,继续执行未完成的步骤。并且无法向调用普通函数那些,调用生成器函数,必须先创建一个生成器对象,再通过next(生成器对象)或者通过生成器对象.__next__()的方式,执行生成器函数。当然,也可以通过for循环遍历生成器对象,因为生成器是一个特殊的迭代器,for循环在遍历的时候,会不断调用next()或__next()__方法(next()内部也是调用的__next__()方法,方便书写)。
def intNum():
for i in range(11):
yield i
print("继续上次未完成的步骤,注意这不是终止哦")
a = intNum()
print(next(a))#返回一个i后,暂停
print(a.__next__())#继续上次的步骤,接着打印print,并开始下一次循环,又遇到yield,返回一个i后,又暂停
#for循环遍历生成器对象
def intNum():
for i in range(11):
yield i
print("继续上次未完成的步骤,注意这不是终止哦")
a = intNum()
for item in a:#for循环内部不断地调用__next__()方法
print(item)
为什么使用生成器而不用列表:
import time
#获取(n, m)内的奇数或偶数
#使用生成器
def numGen(n, m):
while n<m :
yield n
n += 2
t1 = time.time()
sum(numGen(1, 1000000))
print(f"耗时{time.time()-t1}秒")
#使用列表
def numList(n, m):
lst = []
while n<m :
lst.append(n)
n += 2
return lst
t1 = time.time()
sum(numList(1, 1000000))
print(f"耗时{time.time()-t1}秒")
5.10 递归函数
将处理某种问题的循环,写成函数的形式。这种问题的特征:每一步都要用到上一步的结果,将解决这种问题id循环体,改编成的函数就叫做递归函数。递归函数的特征:自己调用自己。递归函数就像套娃一样,一层一层的套,逐层逐层的深入,当递归到某一次时,必须要终止,否则就会无限递归下去。
用递归函数求1到100的和:
def sum(n):
if n==100 :
return 100#当传入的参数为100的时候,返回100,即sum(99+1)=100
return n + sum(n+1)
print(sum(1))

如果实在理解不了递归的本质,只需要记住,return 表达式(规律),并且在这之前需要规定,最后一项的值。例如,上面的例子中,规定了第100项的值为100,否则sum(99+1)又会执行100+sum(100+1),就会无休止的递归下去。
用递归求斐波那契数列的某项(斐波那契数列:1、1、2、3、5、8、13... 每一项都是前两项的和):
def num(n):
if n==1 or n==2 :#第一项与第二项的值为1
return 1
return num(n-1) + num(n-2)#规律:前两项的和
print(num(3))
print(num(5))
print(num(50))
第六章 异常处理
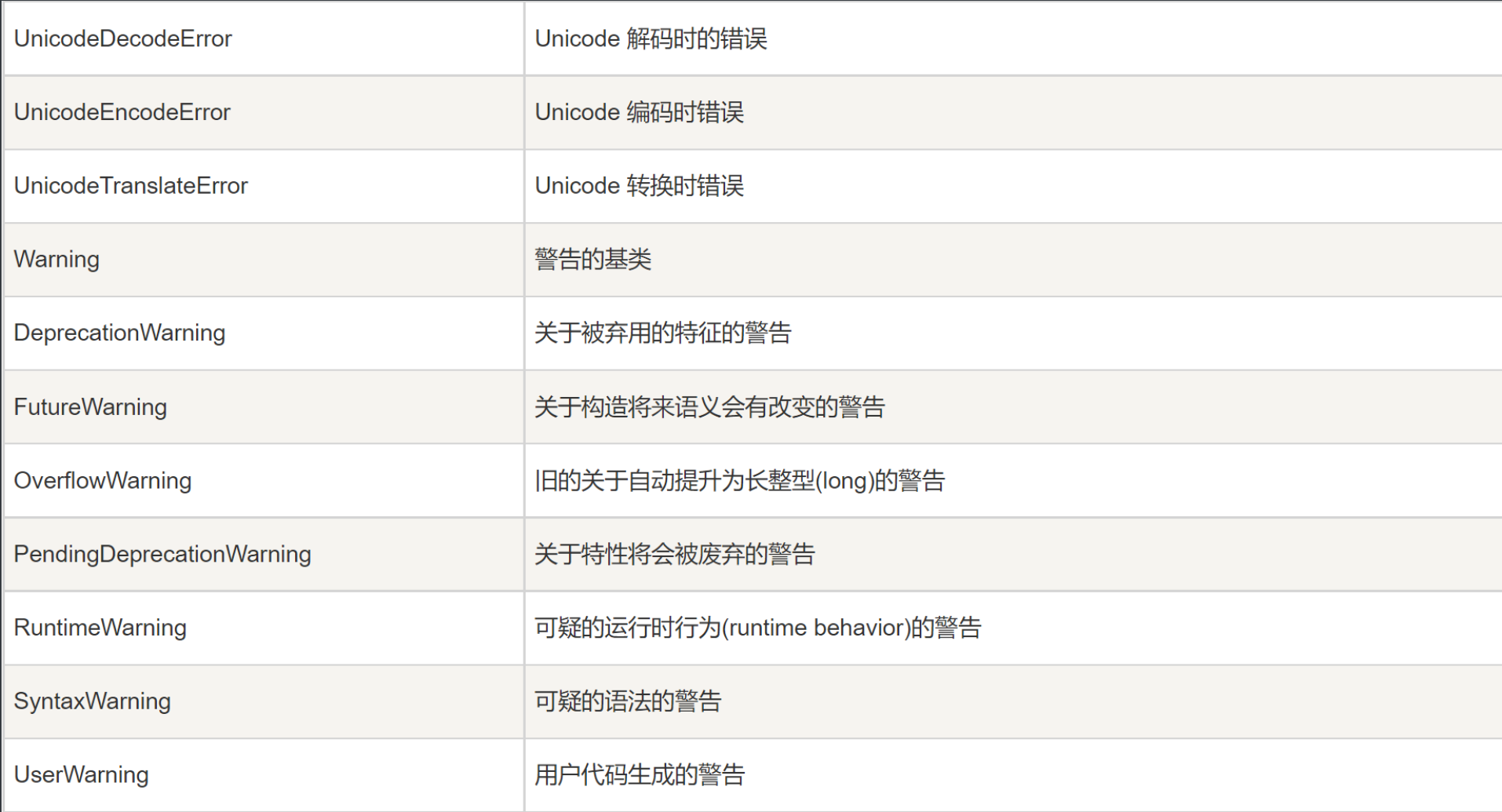
在代码执行的时候,如果出现了错误,又不希望程序停下来,想要根据错误执行相应的代码,然后执行接下来的代码,此时需要用到异常处理。异常处理可以根据错误类型,执行相应的代码。下表是python标准的错误类型:


#示例1
number = int(input())#尝试输入a
number += 1
print("如果出错,则停止执行后面的代码")
#示例2
try:
#这里是尝试运行的代码
number = int(input())
except ValueError:#判断错误类型
print("您输入的不是一个数字")
else:
#执行成功时运行的代码
number += 1
print("无论成功还是失败,都不会影响其他代码的执行")
第七章 文件操作
python中,可以通过一些内置函数对文件进行操作。大致的步骤分为三步:打开文件、操作文件、关闭文件。
-
打开文件
无论要对文件进行怎样的操作,都必须先打开文件,需要用到内置函数open()。
open(file=文件路径,mode=操作模式,encoding=编码方式):以指定的编码方式打开文件,操作模式——稍后要对文件进行怎样的操作。
-
文件路径:分为绝对路径和相对路径。
绝对路径——文件地址的完成表示方式,例如,“C:\Program Files\Google\Chrome\Application\chrome.exe”;相对路径——相对于当前程序所在文件夹的路径,例如,“.\test\helloWorld.txt”表示当前所在文件夹中的test文件夹下的helloWorld.txt文件。
-
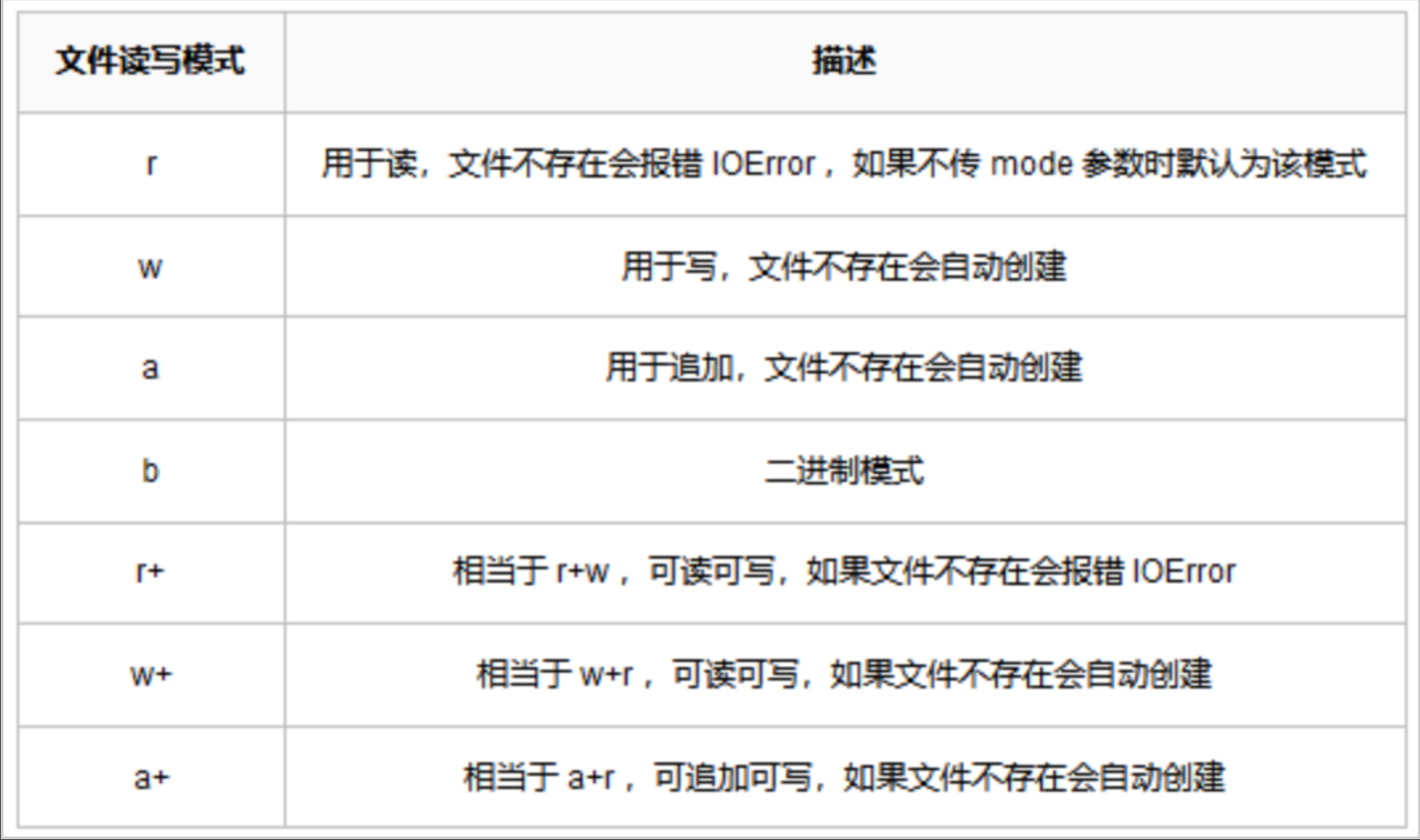
文件操作模式:打开之后要对文件进行的操作。
-
编码方式
https://blog.csdn.net/songfeihu0810232/article/details/127432079
-
-
操作文件
文件操作指的是对文件进行读、写、修改等,无论何种操作,都必须符合打开文件时指定的操作模式。
常用的文件操作函数:
- 文件.read():读取文件中的内容,参数表示读取字符的个数,默认全部读取;
- 文件.readlines():将文件的每一行读取到一个列表中
- 文件.write():将内容写入到文件中;
- 文件.writelines():参数为列表,将列表中的每个元素添加到文件中,一个元素一行;
- 文件.seek():第二个参数表示某个字符的位置,第一个参数表示以第二个参数为基准,将文件指针向前或向后移动指定个字符,正数表示后前移动,负数表示向前移动;
- 文件.flush():
- 文件.tell():当前文件指针的位置(在第几个字符处),注意,0表示在文件开头处;
- 文件.truncate():参数为文件大小,将文件缩短至指定大小。
-
关闭文件
文件操作之后,必须要关闭文件才能保存修改。需要用到内置函数close()。例如,a = open("file=.\\test.txt", mode='w+', encoding="utf-8"),a.write("helloWorld"),a.close()。
-
结合with使用open
有时候,无法打开文件、找不到文件或者忘记了关闭文件时,就会报错,但是却不希望影响后面代码的执行,此时可以结合with使用open,来打开文件,并且不用再手动的关闭文件了。
#示例1
test = open(".\\test.txt", 'w', encoding="utf-8")
test.write("helloWorld")
test.close()
test = open(".\\test.txt", 'r', encoding="utf-8")
result = test.read()
test.close()
print(result)
#示例2
with open(".\\test.txt", 'w', encoding="utf-8") as ft:
ft.write("helloWorld")
with open(".\\test.txt", 'r', encoding="utf-8") as ft:
result = ft.read()
print(result)
第八章 面向对象编程
8.1 面向对象的概念
编程思想分为两类:面向过程编程、面向对象编程。无论是哪种方式,都是针对人、针对程序员而言的,对于计算机,它可不管这么多,写什么代码就执行什么代码,并且从上往下执行。面向过程和面向对象最直观的区别就在于分类和引用时的复杂度不一样,面向过程分类起来比较复杂,引用时也不方便;而面向过程的分类十分简单,使用里面的数据或者函数时,都比较地便捷。
首先在分类上,一般而言,面向过程的语言,一个类只能放到一个源文件中,这也就意味着,如果有多个类,那么需要建立多个源文件,如果这几个类之间要建立关系,还需要在每个源文件中单独引入其他的源文件,非常麻烦;但是面向对象的语言,可以在一个文件中定义多个类,多个类建立关系也非常简单,只需要利用继承的特性就能完成;
其次实在使用上,这些类或者源文件在被引入之后,面向过程只是可以普通调用函数那样使用,仍然需要程序员在一堆函数里寻找;面向对象通过将变量与类建立关系,变量与“.”结合,就能够看到这个类里面所有的函数和数据,而且在引入时,引入某个文件,就能引入这个文件中所有的类,也可以之引入文件中的某一个类,非常灵活、方便。
总之,面向过程,就是站在处理问题的所有步骤面前,面对的是一堆杂乱的数据和函数;面向过程,面对的是一个仓库,这个仓库里面装有很多数据和函数,这些数据和函数都是处理某一类问题所需的。所以,面向对象对于人来说,是非常友好的,让程序员能够快速地找到对应的函数或数据,让程序员的思路更清晰。但是,因为要将一个变量指向一个类,因此,对于计算机而言,面向对象比面向过程的执行效率略低。因此,要不要归类,要合理地判断(一般,函数少的时候,就不要归类了,就不要采用面向对象了)。
教程中的代码都比较简单,只是本章节是专门介绍面向对象编程的,因此会刻意地建立类,但实际中,应该采用面向过程,直接定义函数,然后调用函数。
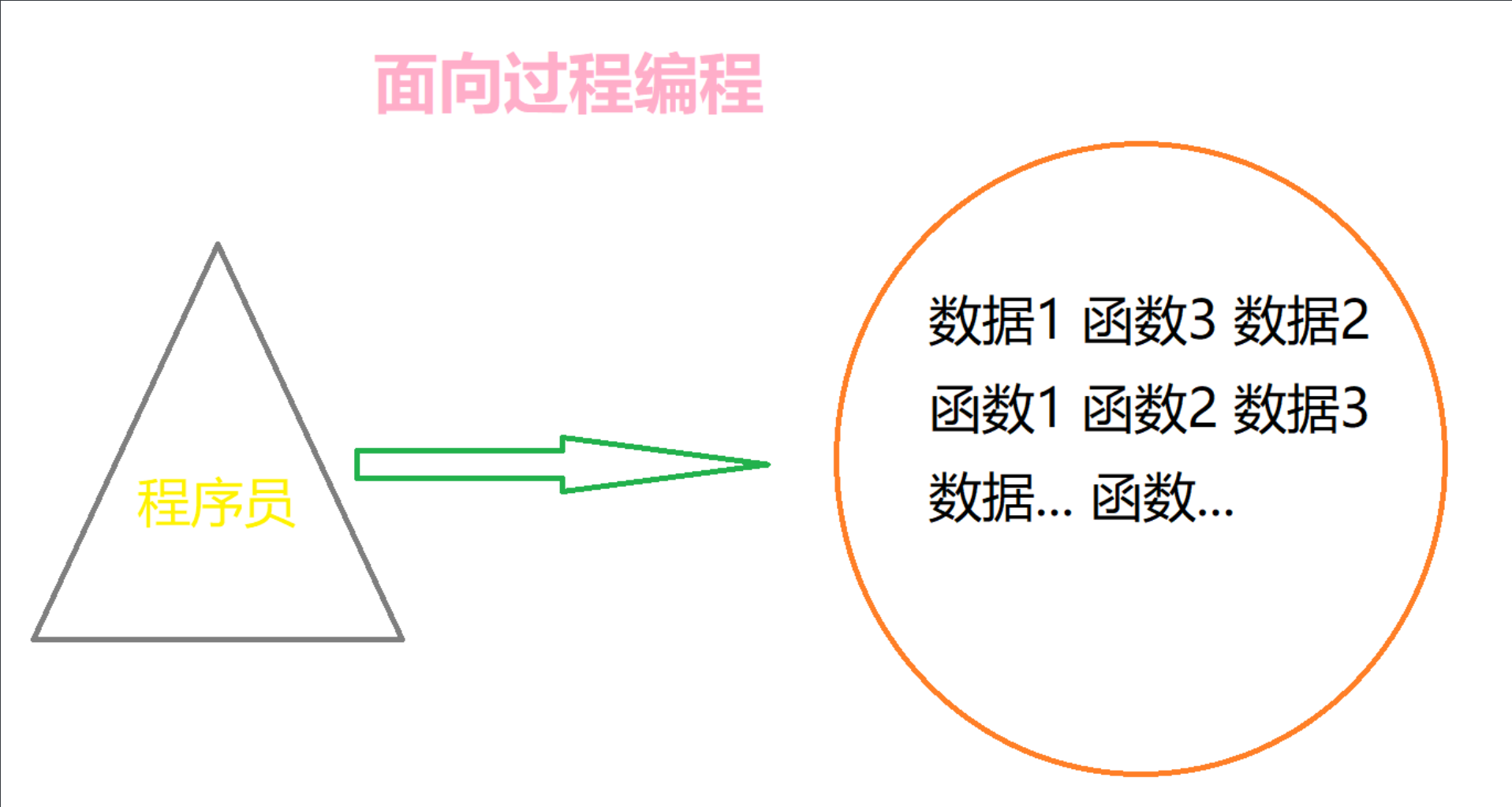
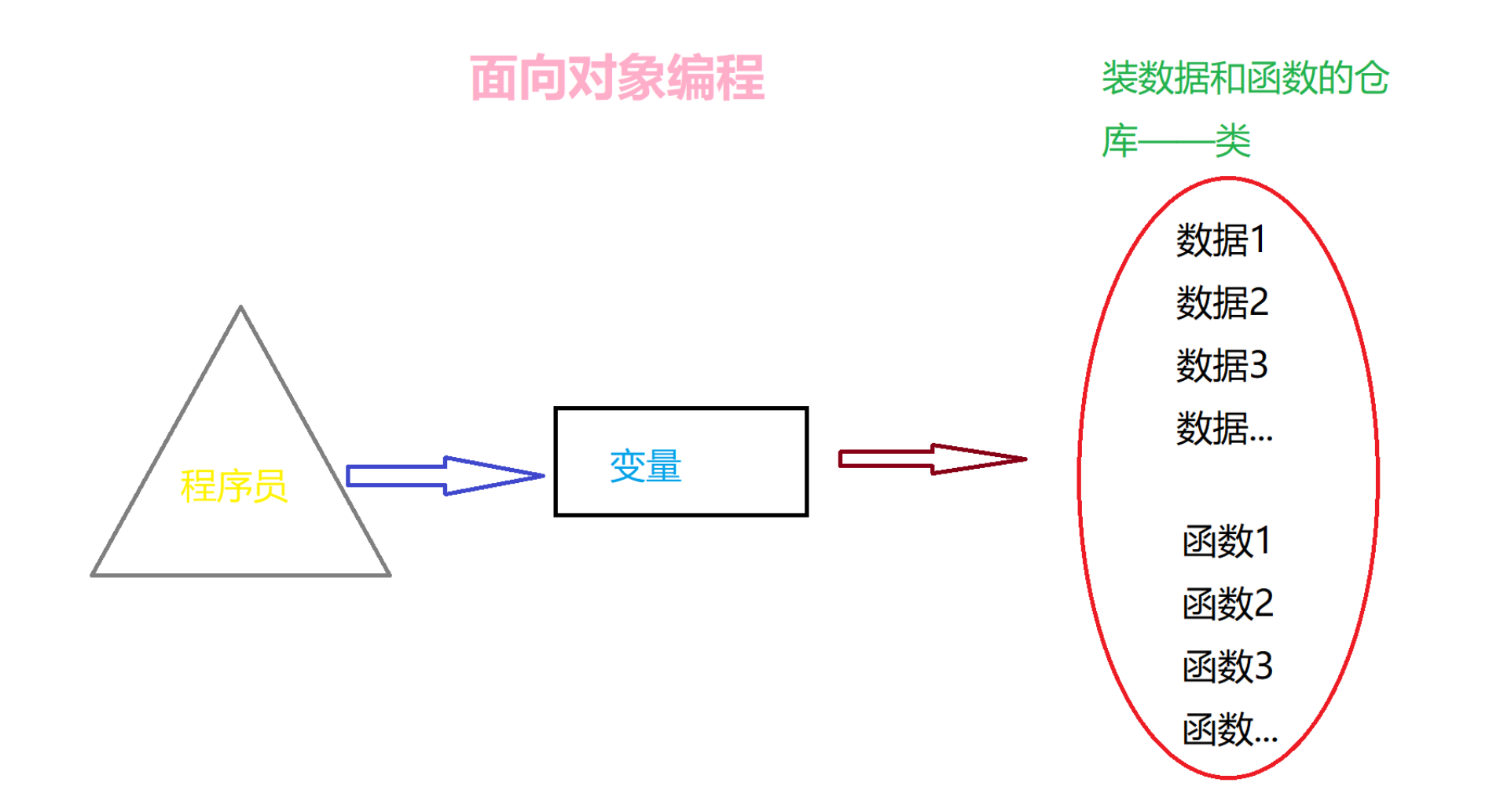
#面向过程编程
def func1():
pass
def func2():
pass
def func3():
pass
def func4():
pass
def func5():
pass
...
def func23():
pass
...
result1 = func1()#程序员要知道存在哪些函数或数据
result2 = func2()
...
#面向对象编程
class Person:
def func1():
pass
def func2():
pass
def func3():
pass
...
class Student(Person):#与其他类建立联系
def func1():
pass
def func2():
pass
def func3():
pass
...
def func23():
pass
...
问题 = Student()#将一个变量与一个类建立联系
问题.func1()#通过.就能看到类里面所有的数据和函数
问题.func2()#由于要通过问题这个变量,再调用类里面的函数,要绕弯路,效率要低一点
...
8.2 成员
8.2.1 基本语法
首先要创建类,用到class关键字;使用时,要将变量与类建立联系,叫做实例化对象,这个变量就叫做该类的对象。
class 公交车:#创建一个公交车类,自定义的类建议首字母大写
def 启动():
pass
def 减速():
pass
def 经停站():
pass
def 刹车():
pass
def 终点站():
pass
def 熄火():
pass
1号车 = 公交车()#实例化对象,注意要加括号
1号车.启动()#通过对象调用函数
1号车.刹车()
1号车.熄火()
8.2.2 属性和类变量
对象和类在内存中存储的区域不同,对象单独一个区域,类单独一个区域,实例化对象之后,相当于在这两个区域之间搭建了一座桥,使得可以在对象的区域中,使用类中的数据,调用类中的函数,不过在类中,只能使用对象中的数据,不能给对象定义一个函数。所以,变量(也就是数据)分为两种,一种存储在对象的区域中,叫做属性,一种存储在类的区域中,叫做类变量(有些人把属性或者类变量叫做字段,这是Java中的叫法,python官方只有类变量的称呼,而对于保存在对象区域中的变量,习惯上称呼为属性,也有人把属性和类变量统称为属性)。
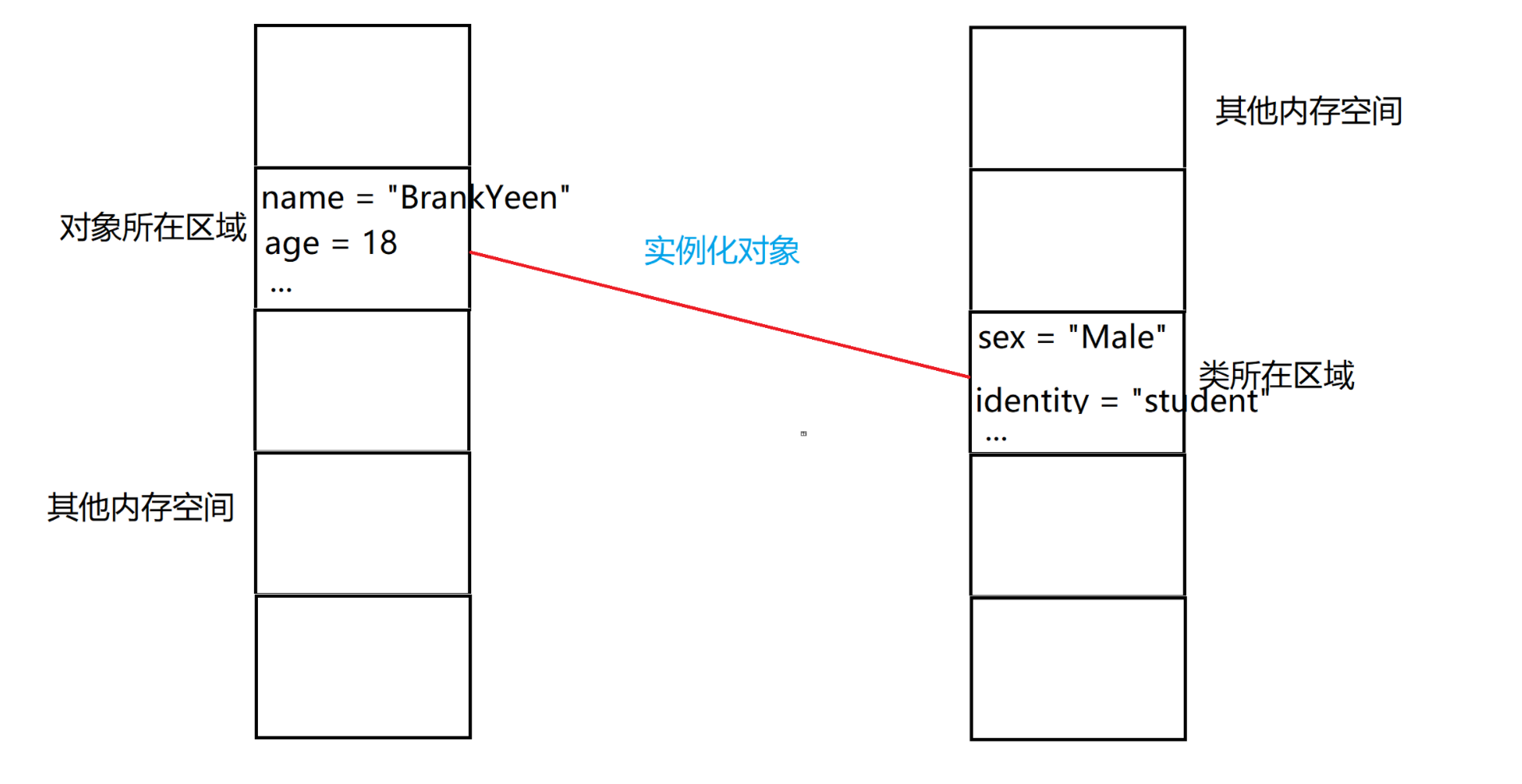
寻找的过程:对象会在自己的区域中找,如果有就用自己的,如果自己没有,就到类所在的区域中找,找到为止,如果还是没有就报错。如果对象所在的区域中,和类所在的区域中,有相同名字的变量,即属性和类变量的名称相同,那么通过对象找到的是属性,通过类找到的是类变量。
class Student:
name = "student"#这种写法,直接保存在类中
def get_name(self,name):#self代表着对象
self.name = name#使对象中的name = 该函数的参数name,如果对象中没有name变量,则自动在对象中创建
by = Student()#实例化对象
by.get_name("BrankYeen")
print(by.name)#打印对象中的name变量
print(Student.name)#打印类中的name变量
8.2.3 方法
类中定义的函数叫做方法,函数也只能在类中定义,不能保存在对象中。但是,某些方法必须通过对象调用。
#实例方法(对象方法):主要用于处理对象中的变量,第一个参数代表对象,一般命名为self,实例方法只能由对象调用。
#类方法:用@classmethod装饰器装饰,类方法的第一个参数代表该类,一般命名为cls,一般由类调用,也可通过对象调用,但不推荐(为了区别)。
#静态方法:用@staticmethod装饰器装饰,属于类中的无参函数,一般由类直接调用,可以通过对象调用,但不推荐。
#属性实例:将实例方法变成属性。如果不希望属性或者类变量被外部引用,可以将其设置为私有成员,以至无法在外部进行引用,只能在类里面使用。这样可以防止属性或者类变量被修改,以提高程序的安全性。但是,如果需要在外部使用属性或者类变量,可以将他们作为函数的返回值返回,在外部调用方法即可,这样就能保证技能在外部引用数据,又无法修改数据。这种函数需要被@property装饰器装饰,并且只用来返回私有属性和私有类变量,不需要参数。外部调用这个函数就像调用属性一样,不需要加括号。
class Student:
identity = "student"
__sex = "Male"#将sex设置为私有成员
def get_info(self, name, age, height, weight):#实例方法
self.name, self.age, self.height, self.weight = name, age, height, weight
@classmethod
def print_identity(cls):#类方法,用于处理类变量
print(cls.identity)
@staticmethod
def print_introduction():
print("这是一个学生类")
@property
def return_sex(self):
return self.__sex
brankyeen = Student()
Student.print_identity()#通过类直接调用类方法
brankyeen.get_info("BrankYeen", 18, 178, 60)#通过对象调用实例方法
print(brankyeen.name)#通过对象获取属性
print(brankyeen.return_sex)#调用属性实例,不需要加括号,当成变量使用,变量值就是函数的返回值
8.2.3 成员修饰符
python中,类的成员有属性、类变量和方法。属性存放在对象中,类变量和方法存储在类中,某些时候,不希望类变量和一些方法被访问到,可以将其设置成私有成员,对象或者类不能直接访问到(能够直接访问的成员为公有成员)。私有成员必须在前面加上双下划线,作为标识。前面讲过,可以通过属性实例的方式,进行访问,python还提供了另一种方式,可以直接访问,十分简单,即对象._类__私有成员。
class Boy:
__age = 18#私有成员
__weight = 60
def set_info(self):
self.name = "BrankYeen"#私有成员是针对对象来说的,对象能访问到的是公有的,不能访问的是私有的,属性保存在对象中,没有公有和私有之分。
self.height = 178
def __sayHello(self):#方法本身属于类,不想让对象调用,将其设置成私有成员
print("BrankYeen is so handsome.")
print("I love him very much.")
by = Boy()
print(by._Boy__age)#访问对象对应类中的私有类变量
by._Boy__sayHello()#调用对象对应类中的私有方法
8.2.4 特殊方法
python给类提供了几个特殊的方法。
-
__init__(self...):初始化方法。实例化对象的同时,自动执行该方法,用于接收对象的参数。如果在类中,定义了该方法,实例化对象,相当于调用初始化方法。
class Student: def __init__(self, name, sex): self.name = name#将name参数的值赋给对象中的name self.sex = sex#将sex参数的值赋给对象中的sex by = Student("BrankYeen", "Male") print(by.name, by.sex) -
__str__(self...):把对象当成普通变量,将str中的返回值当成变量值。
class Student: def __str__(self): return "这是一个学生类"#相当于self="这是一个学生类" by = Student() print(by) -
__call__(self...):把对象当成普通函数,对象加括号,执行call函数。
class Person: def __call__(self): print("I love Python.") by = Person() by() -
__new__(cls):构造方法,构造一个类对象,并返回,类中的self其实是这个返回值,与实例化的对象绑定的也是这个返回值。实例化对象时,先执行构造方法,再执行初始化方法。所有的类都默认继承object类,所以都有__new__这个方法,才能实例化对象。
class Student: def __new__(cls): print("先自动执行__new__方法") result = super().__new__(cls) return result def __init__(self): print("再自动执行__init__方法") by = Student()#这里也可以解释,为什么类可以像函数一样,加括号 -
__dict__:不需要自己定义,该方法的作用是,获取属性或类变量,并以字典的形式展示。由对象调用该方法,则将属性放到字典中返回(属性名作为键名,属性值作为键值);由类调用该方法,则将类变量放到字典中返回(类变量名作为键名,类变量值作为键值)。
class Student: height = 178 weight = 60 def __init__(self, name, age): self.name = name self.age = age by = Student("BrankYeen", 18) print(by.__dict__) print(Student.__dict__)#派生类并不会继承父类的__dict__方法 by.__dict__["name"] = "Python"#可以以字典的形式修改并且只能修改属性 print(by.name) -
__add__(self,...):运算符重载,里面的参数都是对象。两个类或者两个类对象是可以“相加”的,例如,"Brank"是一个字符串类的对象,“Yeen”也是一个字符串类的对象,“Brank”+“Yeen”最终的结果为“BrankYeen”,这是因为在字符串的运算符重载中规定了,当本类与本类“相加”的时候,做拼接的操作。所以,运算符重载表示当前类和其他类“相加”时,执行的操作。一般用不到,了解即可。
-
还有其他的特殊方法(如5.8的迭代器),请自行查阅。
8.3 三大特征
8.3.1 封装
生活中,把东西装到一个容器里,就叫做封装。编程中,封装并不是面向对象的专有特征,面向过程也有。面向对象的封装一般是指,将处理一类问题所用到的数据和函数丢到一个类中,叫做封装。
8.3.2 继承
-
生活中,将他人的财产继承过来,就变成自己的了,就能够用了。面向对象中,一个类也可以继承另外一个或多个类,当前类叫做派生类(子类),被继承的类叫做基类(父类)。派生类可以使用父类的方法或类变量。继承一个类叫做单继承,继承多个类叫做多继承,python是一门支持多继承的语言。为什么要有继承:想要定义的一些方法已经在别的类中定义过了,继承过来就能当成自己的用。
class Animal: def constitude(self): print("我有脑袋,也有身体") class Dog(Animal): def words(self): print("我会汪汪叫") class Cat(Animal): def words(self): print("我会喵喵叫") alpha = Dog() coffee_cat = Cat() alpha.constitude() alpha.words() coffee_cat.constitude() coffee_cat.words() -
python3中,所有的类都默认继承object类,python3中可以不写,但是python2中必须写明。
#python3 class Student#相当于 class Student(object) #python2 class Student(object)#必须这样写 -
对象和类有查找变量的顺序,派生类和基类也有查找方法或类变量的顺序。以方法为例,如果派生类中有该方法,则使用自己的,没有就到所有的基类中依次查找,找到为止(按照继承时的顺序,从左到右找),全都没有就报错;如果派生类中有方法名和基类中的方法名冲突,只使用自己的方法。
class Human(object): def words(self): print("地球上的人类,都有各自的语言。") def who_am_i(self): print("I'm a SB.") class Chinese(Human):#基类继承了object类,就不能再继承object类了 def words(self): print("我会说普通话。") class American(Human): def words(self): print("I can speak English.") brankyeen = Chinese() brankyeen.words()#从自己开始向基类中找,在自己中找到了,就不再找了,就用自己的。 Jack = American() Jack.who_am_i()#自己没有,继续向基类中找,Human中有,用Human的,否则向object找
8.3.3 多态
派生类和基类中有相同名字的方法,这种特殊的继承叫做多态(也可以理解为,继承之后,派生类想要重写基类中的方法)。由多态衍生处的变成机制,叫做鸭子模型或者鸭子类型。多态是python的一大特点。
class Human(object):
def words(self):
print("地球上的人类,都有各自的语言。")
class Chinese(Human):
def words(self):#可以理解为自己的类中定义了一个words方法,也可以理解为重新书写了Human中的words方法
print("我会说普通话。")
第九章 模块
第十章 网络编程
第十一章 并发编程
第十二章 数据库编程
第十三章 简写逻辑简单的代码
13.1 三目运算符
三目运算符又叫三元表达式,用于简写简单的if-else语句,在很多编程语言中都支持,只不过语法上有细微的差别。
语法:表达式1 if 判断条件 else 表达式2。如果条件成立,执行表达式1,否则执行表达式2。
-
通过简单的条件判断赋值
a = int(input()) b = int(input()) if a > b: c = a else: c = b print(c) -
通过三目运算符赋值
a = int(input()) b = int(input()) c = a if a > b else b print(c) # ################################################################# # 还可以写成 a = int(input()) b = int(input()) print(a) if a > b else print(b)
13.2 生成式
生成式又叫做推导式,通过简单的表达式,快速生成四大组合数据类型,主要用于生成列表和字典。
13.2.1 列表生成式
语法:a = [变量 变量表达式 条件判断],其中,条件判断可以省略。
生成100以内,所有的偶数:
-
普通写法
a = [] for item in range(0,101): if item % 2 == 0: a.append(item) print(a) -
列表生成式
a = [item for item in range(101) if item%2 == 0] print(a)
13.2.2 字典生成式
13.3 lambda表达式
用于表示简单的有返回值函数。
语法:变量名 = lambda 参数列表: 表达式。返回表达式的值。
-
普通的定义方式
def func(x, y): return x+y print(func(2,3)) -
lambda表达式
func = lambda x, y: x+y print(func(2,3))
13.4 组合数据类型的列表元素
13.4.1 通过组合数据类型的列表元素创建字典
列表在被循环的时候,如果列表元素是一个组合数据类型,也会被循环。可以利用这种方式,将一些特定的列表,转换为字典。
info = [
["name", "BrankYeen"],
["age", 18]
]#元祖也可以
info = dict(info)
print(info)
13.4.2 通过组合数据类型的列表元素简写多elif语句
-
普通写法
get_num = int(input()) if get_num == 1: print("Monday") elif get_num == 2: print("Tuesday") elif get_num == 3: print("Wednesday") elif get_num == 4: print("Tursday") elif get_num == 5: print("Friday") elif get_num == 6: print("Saturday") elif get_num == 7: print("Sunday") -
简写
get_num = int(input()) week_days = [(1, "Monday"), (2, "Tuesday"), (3, "Wednesday"), (4,"Tursday"), (5, "Friday"), (6, "Saturday"), (7, "Sunday")] for index, day in week_days: print(day) if get_num == index else 1
13.5 多条elif语句简写
13.6 一行写多条语句
13.6.1 一行写多条赋值语句
-
普通的赋值语句
a = 1 b = 2 c = 3 d = 4 -
在一行写
a, b, c, d = 1, 2, 3, 4
13.6.2 python中的分号
x = int(input()); y = int(input()); print(x+y)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号