递归讲解
递归——调用“自己”的函数
1. 调用“自己”是新开一个函数,而不是真的调用 “自己”.
2. 可以看作每一个函数都是“不同”的,即要么输入的参数不同,要么全局变量有变化.
3. 明白一个函数的作用并相信它能完成这个任务,千万不要跳进这个函数里面企图探究更多细节, 否则就会陷入无穷的细节无法自拔
int func(传入数值) {
if (终止条件) return 最小子问题解;
return func(缩小规模);
}
递归——递与归
递归与递推的区别:递推只有归,递归先有一步递.
考虑一道题:
$\mathrm{f[x] = f[x - 1] + x},x \geqslant 1$.
$\mathrm{f[x] = 1}, x = 1$.
递推:
void calc() {
f[1] = 1;
for(int i = 2; i <= n ; ++ i)
f[i] = f[i - 1] + i;
}
递归:
int f(int x) {
if(x == 1) return x;
else return x + f(x - 1);
}
考虑二者不同:
递推由边界出发,逆向从终点走到起点.
递归由起点出发,走到终点,并从终点逆向退回起点.
递归 = 递(找终点)+ 归(从终点递推回起点)
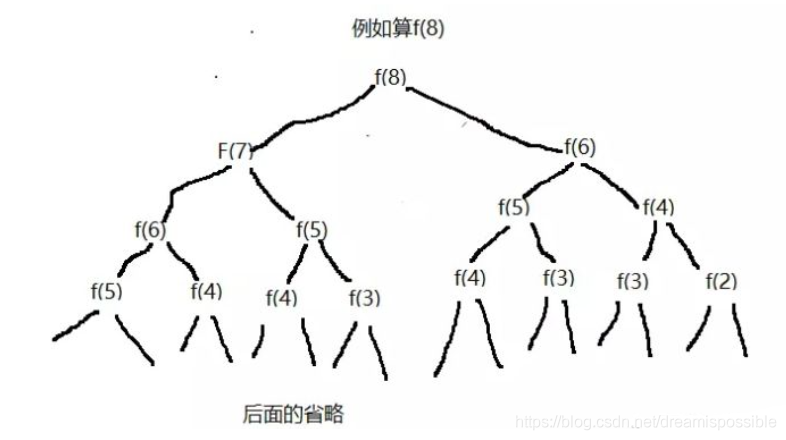
源自 详解递归思想_dreamispossible的博客-CSDN博客_递归思想
递归函数的书写
递归的定义可能会有点绕,但是递归函数的书写确是不难的.
为了便于理解,这里举几个简单递归函数.
设递归函数 $\mathrm{f(sta)}$ 表示运算规则为函数 $\mathrm{f}$, 传入参数为 $\mathrm{sta}$.
$\mathrm{f}$ 函数不涉及全局变量,传入的是数值参数(不改变传入的变量)时,这样的递归是易于理解的.
在书写函数 $\mathrm{f}$ 时,只需考虑这几个事情:
1. $\mathrm{f}$ 的功能
2. $\mathrm{f(x)}$ 可以由哪些 $\mathrm{f(y)}$ 转移得来.
3. 边界
正确性可以类比数学归纳法:
1. 边界条件正确.
2. $\mathrm{f(y)}$ 正确.
3. $\mathrm{f}$ 本身书写正确.(即转移状态正确)
由这三个条件可以归纳推得 $\mathrm{f(x)}$ 正确.
例题:
1. 斐波那契数列:
$\mathrm{f(x)=1, x \leqslant 2}$.
$\mathrm{f(x)=f(x-1)+f(x-2)}$.
思考步骤:
1. $\mathrm{f(x)}$ 干什么?
——计算斐波那契数列第 $\mathrm{x}$ 项的值.
2. 转移 ?
——$\mathrm{f(x)=f(x-1)+f(x-2), x \geqslant 3}$.
3. 边界条件 ?
——$\mathrm{f(x)=1}, x \leqslant 2$.
代码:
int f(int x) {
if(x <= 2) {
return 1;
}
else {
return f(x - 1) + (x - 2);
}
}
2. 计算 $\mathrm{n!}$.
1. $\mathrm{f}$ 要实现什么功能 ?
——计算 $\mathrm{n!}$.
2. $\mathrm{f}$ 的转移是什么?
——$\mathrm{f(n)=f(n-1) \times n}$.
3. $\mathrm{f}$ 的边界是什么?
——$\mathrm{f(1)=1}$.
int f(int n) {
if(n == 1) return 1;
else return n * f(n - 1);
}
为什么要用递归?
上文也提到过递归 = 递 + 归,即如果知道函数的转移方向则和递推是等价的.
但是在很多情况,我们并不能很清楚的得知函数的递推方向.
在计算斐波那契函数和阶乘函数时,递推方向是下标由小到大.
但是在 $\mathrm{DAG}$, 树上进行逆向递推时递推的顺序就是有讲究的(至少并不那么显然)
这个时候递归来做就显得更加无脑,更加方便.
例
1. 求解两个数字的最大公约数.
有公式:
$\mathrm{if}$ $\mathrm{y=0}$ $\mathrm{gcd(x, y) = x}$
$\mathrm{else}$ $\mathrm{gcd(x,y) = gcd(y, x \ mod y)}$.
int gcd(int x, int y) {
return y ? gcd(y, x % y) : x;
}
2. 给定一棵有根树,求点 $\mathrm{i}$ 的子树大小 $\mathrm{size[i]}$.
树:$\mathrm{n}$ 个点,$\mathrm{n-1}$ 条边的无向图(无环)
对于有根树,我们可以将每个点的儿子(直接与 $\mathrm{x}$ 相邻的点且并不是 $\mathrm{x}$ 的父亲)存储起来.

子树的概念:

(图片源自 OI - wiki)
递推做法:
对于一个点 $\mathrm{x}$, 若 $\mathrm{x}$ 能使 $\mathrm{y}$ 的子树大小 +1, 则 $\mathrm{y}$ 必为 $\mathrm{x}$ 的祖先.
裸做的话要暴力跳祖先一个一个贡献.
递归做法:
考虑定义递归函数 $\mathrm{f(x)}$ 表示 $\mathrm{x}$ 点的子树大小.
显然有 $\mathrm{f(x)=1 + \sum_{v \in son[x]} f(v)}$.
int dfs(int x) {
int cur = 1;
for(int i = 0; i < G[x].size() ; ++ i) {
cur += dfs(G[x][i]);
}
return cur;
}
3. 全排列问题
给定 $\mathrm{n}$, 输出 $\mathrm{n}$ 的所有排列.
按照递归三部曲,定义函数 $\mathrm{dfs(now, a)}$ :
输出”给定 $[1, now]$ 中的数字情况下“的排列,即 $1$ ~ $\mathrm{now-1}$ 中的数字都确定好的情况下输出剩下的排列.
那么,我们枚举 $\mathrm{now}$ 位置上该填什么:即 $\mathrm{now-1}$ 及之前没有加入过的数字就是要加入的.
void dfs(int cur, vector<int>g) {
if(cur == n + 1) {
for(int i = 0; i < n ; ++ i) {
printf(" %d", g[i]);
}
printf("\n");
return ;
}
for(int i = 1; i <= n ; ++ i) {
int flag = 0;
for(int j = 0; j < g.size() ; ++ j) {
if(g[j] == i) { flag = 1; break; }
}
if(!flag) {
g.pb(i);
dfs(cur + 1, g);
g.pop_back();
}
}
}
但是,我们每次都要在函数里有一个 $\mathrm{a}$, 在空间上就显得很不方便,不妨用全局变量来代替.
那么,在这个时候我们就要改变一下函数的定义方式:
即令 $dfs(now)$ 表示:
当前已添加完 $\mathrm{now-1}$ 及之前的数字,且填入数字数组为 $\mathrm{a}$,状态为 $\mathrm{vis}$.
且:执行完本函数之后 $\mathrm{a}$ 与 $\mathrm{vis}$ 的状态不改变.
如果后面觉得懵的话反复朗读这两句话.
那么函数调用就好写了:
#include <bits/stdc++.h>
#define ll long long
#define pb push_back
using namespace std;
int n , a[20], vis[20];
void dfs(int now) {
if(now > n) {
for(int i = 1; i <= n ; ++ i) {
printf(" %d", a[i]);
}
printf("\n");
return ;
}
for(int i = 1; i <= n ; ++ i) {
if(!vis[i]) {
vis[i] = 1;
a[now] = i;
dfs(now + 1);
vis[i] = 0;
a[now] = 0;
}
}
}
int main() {
scanf("%d", &n);
dfs(1);
return 0;
}
既然我们已经学会了递归,就利用递归做题吧!
1. Painting Fence
来源:codeforces round 256 (Div 2)
有 $\mathrm{n}$ 块连着的木板,每个木板高度为 $\mathrm{h[i]}$,我们需要把 $\mathrm{n}$ 个木板涂上颜色.
每次涂色可以有两种选择:
1. 竖着涂完一块木板(若之前这个木板有涂过,则可以继续涂完)
2. 横着刷一个高度单位的连续的木板(中间不能空着,不能间断)
问:最少需要刷多少次,使得所有木板都涂上颜色 ?
数据范围:$n \leqslant 5000, a_{i} \leqslant 10^9$.
#include <stdio.h>
#define N 5009
#define setIO(s) freopen(s".in","r",stdin)
int min(int x, int y) { return x < y ? x : y; }
int a[N], n;
int solve(int l, int r, int cur) {
if(l == r) {
return 1;
}
int mi = a[l];
for(int i = l; i <= r; ++ i) {
mi = min(mi, a[i]);
}
int an = mi - cur, i, j;
for(i = l; i <= r; ) {
if(a[i] == mi) {
++ i;
continue;
}
else {
for(j = i; j + 1 <= r && a[j + 1] > mi; ++ j);
an += solve(i, j, mi);
i = j + 1;
}
}
return min(an, r - l + 1);
}
int main() {
// setIO("input");
scanf("%d",&n);
for(int i = 1; i <= n ; ++ i) {
scanf("%d", &a[i]);
}
printf("%d", solve(1, n, 0));
return 0;
}
解:直接做肯定不太好做,因为问题十分复杂,不妨考虑递归。
按照递归三部曲:
1.$\mathrm{solve(l, r, cur)}$ :当前 $\mathrm{[l,r]}$ 区间已经涂上 $\mathrm{cur}$ 高度的, 还需要最少多少次可以将这个区间的墙涂完.
2. 转移:若已经涂过的高度小于这段区间的最小值,则肯定可以横着给这个区间都涂上,缩小问题规模.
3. 边界:$\mathrm{l=r}$ 时直接返回 1.
#include <stdio.h>
#define N 5009
#define setIO(s) freopen(s".in","r",stdin)
int min(int x, int y) { return x < y ? x : y; }
int a[N], n;
int solve(int l, int r, int cur) {
if(l == r) {
return 1;
}
int mi = a[l];
for(int i = l; i <= r; ++ i) {
mi = min(mi, a[i]);
}
int an = mi - cur, i, j;
for(i = l; i <= r; ) {
if(a[i] == mi) {
++ i;
continue;
}
else {
for(j = i; j + 1 <= r && a[j + 1] > mi; ++ j);
an += solve(i, j, mi);
i = j + 1;
}
}
return min(an, r - l + 1);
}
int main() {
// setIO("input");
scanf("%d",&n);
for(int i = 1; i <= n ; ++ i) {
scanf("%d", &a[i]);
}
printf("%d", solve(1, n, 0));
return 0;
}
2. Chloe and the sequence
来源:codeforces 743B
给定两个数 $n$ ,$k$($n \leqslant 50$,$k \leqslant 2^n-1$)
再生成一个长度为 $2^n-1$ 的数列;
这个数列是这样的:
首先在正中间填上 $n$.
接着在 $n$ 的两边的正中间填上 $n-1$.
再在两个 $n-1$ 的两边填上 $n-2$ ………………
当 $n=4$ 时,这个数列是这样的:
$1,2,1,3,1,2,1,4,1,2,1,3,1,2,1$
问:第 $k$ 位数字是什么 ?
定义递归函数 $\mathrm{f(n, k)}$ 表示中间数字为 $\mathrm{n}$ 时第 $\mathrm{k}$ 位是多少.
1. $\mathrm{k}$ 就是中间位置,则输出
2. $\mathrm{k}$ 是中间位置左面,则递归左面.
3. $\mathrm{k}$ 是中间位置右面,则递归右面.
#include <bits/stdc++.h>
#define ll long long
using namespace std;
int solve(int n, ll k) {
ll len = (1ll << n) - 1;
if(k == len / 2 + 1) return n;
if(k < len / 2 + 1) return solve(n - 1, k);
if(k > len / 2 + 1) return solve(n - 1, k - (len / 2 + 1));
}
int main() {
int n ;
ll K;
scanf("%d%lld", &n, &K);
printf("%d\n", solve(n, K));
return 0;
}
3. How many integers can you find ?
来源:HDU1796
给定 $\mathrm{n}$, 一个大小为 $10$ 的正整数集合 $\mathrm{M}$.
问 $\mathrm{[1,n]}$ 中有多少个数字 $\mathrm{x}$ 满足 $\mathrm{M}$ 中存在 $\mathrm{x}$ 的因数.
#include <cstdio>
#define ll long long
using namespace std;
ll a[20], n,ans;
int m, cnt;
ll gcd(ll a,ll b){
return b==0 ? a : gcd(b,a % b);
}
void dfs(int cur,ll lcm,int id){
if(cur > cnt) return;
lcm = a[cur] / gcd(a[cur], lcm) * lcm;
if(id) ans += (n - 1) / lcm;
else ans -= (n - 1) / lcm;
for(int i = cur + 1; i <= cnt ; ++ i)
dfs(i, lcm, !id);
}
int main(){
while(scanf("%lld%d",&n,&m) != EOF)
{
ans = cnt = 0;
for(int i = 1; i <= m ; ++ i){
ll k;
scanf("%lld",&k);
if(k) a[ ++cnt] = k;
}
for(int i = 1; i <= cnt ; ++ i)
dfs(i, a[i], 1);
printf("%lld\n",ans);
}
return 0;
}
根据容斥原理,答案 $=$ 被一个数整除 - 被 2 个数整除 + 被 3 个数整除......
即我们要找到 $\mathrm{M}$ 的所有子集,然后判断这个子集应该加上还是减去.
这个用递归可以方便地进行求解.
4. 平面最近点对
给定平面上 $n$ 个点,问距离最近的点对的距离是多少 ?
用分治法可以做到在 $O(n \log n)$ 的时间复杂度内求解.
先把所有点按照 $x$ 坐标排序,$x$ 坐标相同则按照 $y$ 来排序.
每次取中间点 $\mathrm{mid}$, 递归求解 $\mathrm{[l,mid]}$ 与 $\mathrm{[mid+1,r]}$.
考虑如何合并:即一个点在左侧,一个点在右侧.
求解完左侧后自动按照纵坐标排序,右侧同理.
那么这里就有一个结论:对于左侧一个点,所需要枚举到的右侧点的个数不大于 $8$.
记忆化搜索
讲完这么多递归,不讲记忆化搜索就可惜了,这里介绍一下:
考虑最开始讲得计算斐波那契数列的递归函数:
int f(int x) {
return x <= 2 ? 1: f(x - 1) + f(x - 2);
}
仔细分析一下这个函数,假如说现在要求 $f(5)$.
$f(5)=f(4)+f(3)$
$f(4)=f(3)+f(2)$
$f(3)=f(2)+f(1)$
$f(3)=f(2)+f(1)$
在短短的调用关系中,不难发现 $f(3)$ 就要计算两次.
在递推中,每一个 $f(i)$ 只会计算一次,所以时间复杂度是线性的.
而在这个简陋的递归中,每一个 $f(i)$ 会被重复计算,这个计算量就不是线性了.
所以这里引入记忆化搜索的概念,即计算过的值就被保留在数组中,下次调用就直接拿来用.
#include <bits/stdc++.h>
using namespace std;
int f[40];
int dfs(int x) {
if(f[x]) return f[x];
if(x <= 2) return f[x] = 1;
else return f[x] = dfs(x - 1) + dfs(x - 2);
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号