数据结构与算法_19 _ 散列表(中):如何打造一个工业级水平的散列表?
通过上一节的学习,我们知道,散列表的查询效率并不能笼统地说成是O(1)。它跟散列函数、装载因子、散列冲突等都有关系。如果散列函数设计得不好,或者装载因子过高,都可能导致散列冲突发生的概率升高,查询效率下降。
在极端情况下,有些恶意的攻击者,还有可能通过精心构造的数据,使得所有的数据经过散列函数之后,都散列到同一个槽里。如果我们使用的是基于链表的冲突解决方法,那这个时候,散列表就会退化为链表,查询的时间复杂度就从O(1)急剧退化为O(n)。
如果散列表中有10万个数据,退化后的散列表查询的效率就下降了10万倍。更直接点说,如果之前运行100次查询只需要0.1秒,那现在就需要1万秒。这样就有可能因为查询操作消耗大量CPU或者线程资源,导致系统无法响应其他请求,从而达到拒绝服务攻击(DoS)的目的。这也就是散列表碰撞攻击的基本原理。
今天,我们就来学习一下,如何设计一个可以应对各种异常情况的工业级散列表,来避免在散列冲突的情况下,散列表性能的急剧下降,并且能抵抗散列碰撞攻击?
如何设计散列函数?
散列函数设计的好坏,决定了散列表冲突的概率大小,也直接决定了散列表的性能。那什么才是好的散列函数呢?
首先,散列函数的设计不能太复杂。过于复杂的散列函数,势必会消耗很多计算时间,也就间接地影响到散列表的性能。其次,散列函数生成的值要尽可能随机并且均匀分布,这样才能避免或者最小化散列冲突,而且即便出现冲突,散列到每个槽里的数据也会比较平均,不会出现某个槽内数据特别多的情况。
实际工作中,我们还需要综合考虑各种因素。这些因素有关键字的长度、特点、分布、还有散列表的大小等。散列函数各式各样,我举几个常用的、简单的散列函数的设计方法,让你有个直观的感受。
第一个例子就是我们上一节的学生运动会的例子,我们通过分析参赛编号的特征,把编号中的后两位作为散列值。我们还可以用类似的散列函数处理手机号码,因为手机号码前几位重复的可能性很大,但是后面几位就比较随机,我们可以取手机号的后四位作为散列值。这种散列函数的设计方法,我们一般叫做“数据分析法”。
第二个例子就是上一节的开篇思考题,如何实现Word拼写检查功能。这里面的散列函数,我们就可以这样设计:将单词中每个字母的ASCll码值“进位”相加,然后再跟散列表的大小求余、取模,作为散列值。比如,英文单词nice,我们转化出来的散列值就是下面这样:
hash("nice")=(("n" - "a") * 26*26*26 + ("i" - "a")*26*26 + ("c" - "a")*26+ ("e"-"a")) / 78978
实际上,散列函数的设计方法还有很多,比如直接寻址法、平方取中法、折叠法、随机数法等,这些你只要了解就行了,不需要全都掌握。
装载因子过大了怎么办?
我们上一节讲到散列表的装载因子的时候说过,装载因子越大,说明散列表中的元素越多,空闲位置越少,散列冲突的概率就越大。不仅插入数据的过程要多次寻址或者拉很长的链,查找的过程也会因此变得很慢。
对于没有频繁插入和删除的静态数据集合来说,我们很容易根据数据的特点、分布等,设计出完美的、极少冲突的散列函数,因为毕竟之前数据都是已知的。
对于动态散列表来说,数据集合是频繁变动的,我们事先无法预估将要加入的数据个数,所以我们也无法事先申请一个足够大的散列表。随着数据慢慢加入,装载因子就会慢慢变大。当装载因子大到一定程度之后,散列冲突就会变得不可接受。这个时候,我们该如何处理呢?
还记得我们前面多次讲的“动态扩容”吗?你可以回想一下,我们是如何做数组、栈、队列的动态扩容的。
针对散列表,当装载因子过大时,我们也可以进行动态扩容,重新申请一个更大的散列表,将数据搬移到这个新散列表中。假设每次扩容我们都申请一个原来散列表大小两倍的空间。如果原来散列表的装载因子是0.8,那经过扩容之后,新散列表的装载因子就下降为原来的一半,变成了0.4。
针对数组的扩容,数据搬移操作比较简单。但是,针对散列表的扩容,数据搬移操作要复杂很多。因为散列表的大小变了,数据的存储位置也变了,所以我们需要通过散列函数重新计算每个数据的存储位置。
你可以看我图里这个例子。在原来的散列表中,21这个元素原来存储在下标为0的位置,搬移到新的散列表中,存储在下标为7的位置。
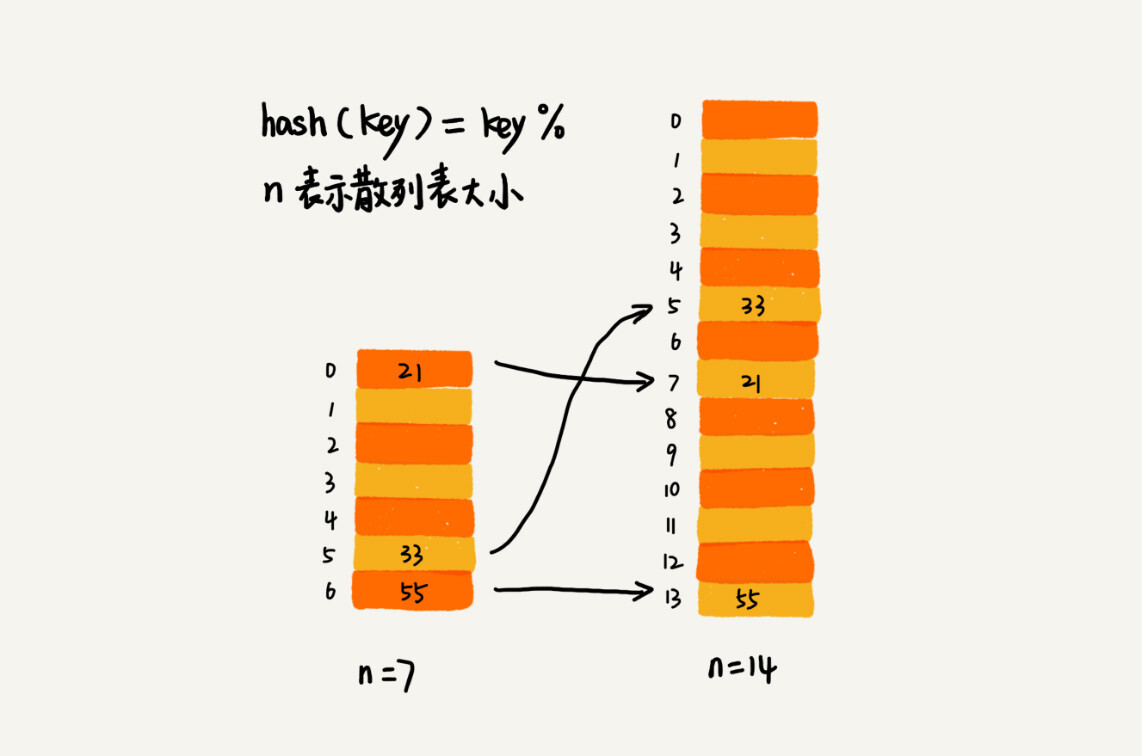
对于支持动态扩容的散列表,插入操作的时间复杂度是多少呢?前面章节我已经多次分析过支持动态扩容的数组、栈等数据结构的时间复杂度了。所以,这里我就不啰嗦了,你要是还不清楚的话,可以回去复习一下。
插入一个数据,最好情况下,不需要扩容,最好时间复杂度是O(1)。最坏情况下,散列表装载因子过高,启动扩容,我们需要重新申请内存空间,重新计算哈希位置,并且搬移数据,所以时间复杂度是O(n)。用摊还分析法,均摊情况下,时间复杂度接近最好情况,就是O(1)。
实际上,对于动态散列表,随着数据的删除,散列表中的数据会越来越少,空闲空间会越来越多。如果我们对空间消耗非常敏感,我们可以在装载因子小于某个值之后,启动动态缩容。当然,如果我们更加在意执行效率,能够容忍多消耗一点内存空间,那就可以不用费劲来缩容了。
我们前面讲到,当散列表的装载因子超过某个阈值时,就需要进行扩容。装载因子阈值需要选择得当。如果太大,会导致冲突过多;如果太小,会导致内存浪费严重。
装载因子阈值的设置要权衡时间、空间复杂度。如果内存空间不紧张,对执行效率要求很高,可以降低负载因子的阈值;相反,如果内存空间紧张,对执行效率要求又不高,可以增加负载因子的值,甚至可以大于1。
如何避免低效的扩容?
我们刚刚分析得到,大部分情况下,动态扩容的散列表插入一个数据都很快,但是在特殊情况下,当装载因子已经到达阈值,需要先进行扩容,再插入数据。这个时候,插入数据就会变得很慢,甚至会无法接受。
我举一个极端的例子,如果散列表当前大小为1GB,要想扩容为原来的两倍大小,那就需要对1GB的数据重新计算哈希值,并且从原来的散列表搬移到新的散列表,听起来就很耗时,是不是?
如果我们的业务代码直接服务于用户,尽管大部分情况下,插入一个数据的操作都很快,但是,极个别非常慢的插入操作,也会让用户崩溃。这个时候,“一次性”扩容的机制就不合适了。
为了解决一次性扩容耗时过多的情况,我们可以将扩容操作穿插在插入操作的过程中,分批完成。当装载因子触达阈值之后,我们只申请新空间,但并不将老的数据搬移到新散列表中。
当有新数据要插入时,我们将新数据插入新散列表中,并且从老的散列表中拿出一个数据放入到新散列表。每次插入一个数据到散列表,我们都重复上面的过程。经过多次插入操作之后,老的散列表中的数据就一点一点全部搬移到新散列表中了。这样没有了集中的一次性数据搬移,插入操作就都变得很快了。

这期间的查询操作怎么来做呢?对于查询操作,为了兼容了新、老散列表中的数据,我们先从新散列表中查找,如果没有找到,再去老的散列表中查找。
通过这样均摊的方法,将一次性扩容的代价,均摊到多次插入操作中,就避免了一次性扩容耗时过多的情况。这种实现方式,任何情况下,插入一个数据的时间复杂度都是O(1)。
如何选择冲突解决方法?
上一节我们讲了两种主要的散列冲突的解决办法,开放寻址法和链表法。这两种冲突解决办法在实际的软件开发中都非常常用。比如,Java中LinkedHashMap就采用了链表法解决冲突,ThreadLocalMap是通过线性探测的开放寻址法来解决冲突。那你知道,这两种冲突解决方法各有什么优势和劣势,又各自适用哪些场景吗?
1.开放寻址法
我们先来看看,开放寻址法的优点有哪些。
开放寻址法不像链表法,需要拉很多链表。散列表中的数据都存储在数组中,可以有效地利用CPU缓存加快查询速度。而且,这种方法实现的散列表,序列化起来比较简单。链表法包含指针,序列化起来就没那么容易。你可不要小看序列化,很多场合都会用到的。我们后面就有一节会讲什么是数据结构序列化、如何序列化,以及为什么要序列化。
我们再来看下,开放寻址法有哪些缺点。
上一节我们讲到,用开放寻址法解决冲突的散列表,删除数据的时候比较麻烦,需要特殊标记已经删除掉的数据。而且,在开放寻址法中,所有的数据都存储在一个数组中,比起链表法来说,冲突的代价更高。所以,使用开放寻址法解决冲突的散列表,装载因子的上限不能太大。这也导致这种方法比链表法更浪费内存空间。
所以,我总结一下,当数据量比较小、装载因子小的时候,适合采用开放寻址法。这也是Java中的ThreadLocalMap使用开放寻址法解决散列冲突的原因。
2.链表法
首先,链表法对内存的利用率比开放寻址法要高。因为链表结点可以在需要的时候再创建,并不需要像开放寻址法那样事先申请好。实际上,这一点也是我们前面讲过的链表优于数组的地方。
链表法比起开放寻址法,对大装载因子的容忍度更高。开放寻址法只能适用装载因子小于1的情况。接近1时,就可能会有大量的散列冲突,导致大量的探测、再散列等,性能会下降很多。但是对于链表法来说,只要散列函数的值随机均匀,即便装载因子变成10,也就是链表的长度变长了而已,虽然查找效率有所下降,但是比起顺序查找还是快很多。
还记得我们之前在链表那一节讲的吗?链表因为要存储指针,所以对于比较小的对象的存储,是比较消耗内存的,还有可能会让内存的消耗翻倍。而且,因为链表中的结点是零散分布在内存中的,不是连续的,所以对CPU缓存是不友好的,这方面对于执行效率也有一定的影响。
当然,如果我们存储的是大对象,也就是说要存储的对象的大小远远大于一个指针的大小(4个字节或者8个字节),那链表中指针的内存消耗在大对象面前就可以忽略了。
实际上,我们对链表法稍加改造,可以实现一个更加高效的散列表。那就是,我们将链表法中的链表改造为其他高效的动态数据结构,比如跳表、红黑树。这样,即便出现散列冲突,极端情况下,所有的数据都散列到同一个桶内,那最终退化成的散列表的查找时间也只不过是O(logn)。这样也就有效避免了前面讲到的散列碰撞攻击。
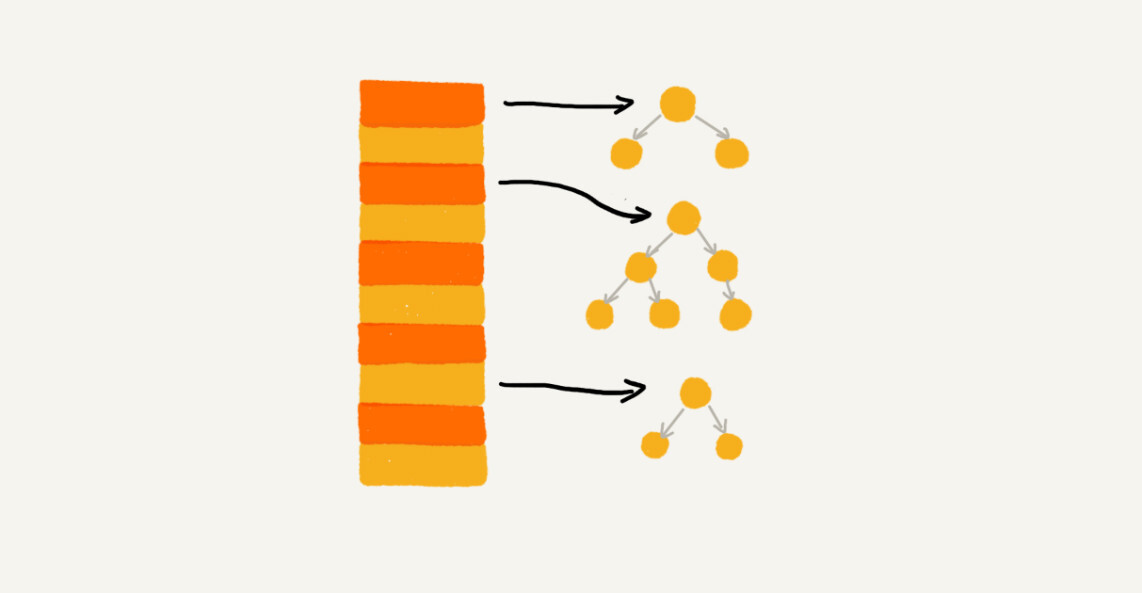
所以,我总结一下,基于链表的散列冲突处理方法比较适合存储大对象、大数据量的散列表,而且,比起开放寻址法,它更加灵活,支持更多的优化策略,比如用红黑树代替链表。
工业级散列表举例分析
刚刚我讲了实现一个工业级散列表需要涉及的一些关键技术,现在,我就拿一个具体的例子,Java中的HashMap这样一个工业级的散列表,来具体看下,这些技术是怎么应用的。
1.初始大小
HashMap默认的初始大小是16,当然这个默认值是可以设置的,如果事先知道大概的数据量有多大,可以通过修改默认初始大小,减少动态扩容的次数,这样会大大提高HashMap的性能。
2.装载因子和动态扩容
最大装载因子默认是0.75,当HashMap中元素个数超过0.75*capacity(capacity表示散列表的容量)的时候,就会启动扩容,每次扩容都会扩容为原来的两倍大小。
3.散列冲突解决方法
HashMap底层采用链表法来解决冲突。即使负载因子和散列函数设计得再合理,也免不了会出现拉链过长的情况,一旦出现拉链过长,则会严重影响HashMap的性能。
于是,在JDK1.8版本中,为了对HashMap做进一步优化,我们引入了红黑树。而当链表长度太长(默认超过8)时,链表就转换为红黑树。我们可以利用红黑树快速增删改查的特点,提高HashMap的性能。当红黑树结点个数少于8个的时候,又会将红黑树转化为链表。因为在数据量较小的情况下,红黑树要维护平衡,比起链表来,性能上的优势并不明显。
4.散列函数
散列函数的设计并不复杂,追求的是简单高效、分布均匀。我把它摘抄出来,你可以看看。
int hash(Object key) {
int h = key.hashCode();
return (h ^ (h >>> 16)) & (capicity -1); //capicity表示散列表的大小
}
其中,hashCode()返回的是Java对象的hash code。比如String类型的对象的hashCode()就是下面这样:
public int hashCode() {
int var1 = this.hash;
if(var1 == 0 && this.value.length > 0) {
char[] var2 = this.value;
for(int var3 = 0; var3 < this.value.length; ++var3) {
var1 = 31 * var1 + var2[var3];
}
this.hash = var1;
}
return var1;
}
解答开篇
今天的内容就讲完了,我现在来分析一下开篇的问题:如何设计一个工业级的散列函数?如果这是一道面试题或者是摆在你面前的实际开发问题,你会从哪几个方面思考呢?
首先,我会思考,何为一个工业级的散列表?工业级的散列表应该具有哪些特性?
结合已经学习过的散列知识,我觉得应该有这样几点要求:
-
支持快速地查询、插入、删除操作;
-
内存占用合理,不能浪费过多的内存空间;
-
性能稳定,极端情况下,散列表的性能也不会退化到无法接受的情况。
如何实现这样一个散列表呢?根据前面讲到的知识,我会从这三个方面来考虑设计思路:
-
设计一个合适的散列函数;
-
定义装载因子阈值,并且设计动态扩容策略;
-
选择合适的散列冲突解决方法。
关于散列函数、装载因子、动态扩容策略,还有散列冲突的解决办法,我们前面都讲过了,具体如何选择,还要结合具体的业务场景、具体的业务数据来具体分析。不过只要我们朝这三个方向努力,就离设计出工业级的散列表不远了。
内容小结
上一节的内容比较偏理论,今天的内容侧重实战。我主要讲了如何设计一个工业级的散列表,以及如何应对各种异常情况,防止在极端情况下,散列表的性能退化过于严重。我分了三部分来讲解这些内容,分别是:如何设计散列函数,如何根据装载因子动态扩容,以及如何选择散列冲突解决方法。
关于散列函数的设计,我们要尽可能让散列后的值随机且均匀分布,这样会尽可能地减少散列冲突,即便冲突之后,分配到每个槽内的数据也比较均匀。除此之外,散列函数的设计也不能太复杂,太复杂就会太耗时间,也会影响散列表的性能。
关于散列冲突解决方法的选择,我对比了开放寻址法和链表法两种方法的优劣和适应的场景。大部分情况下,链表法更加普适。而且,我们还可以通过将链表法中的链表改造成其他动态查找数据结构,比如红黑树,来避免散列表时间复杂度退化成O(n),抵御散列碰撞攻击。但是,对于小规模数据、装载因子不高的散列表,比较适合用开放寻址法。
对于动态散列表来说,不管我们如何设计散列函数,选择什么样的散列冲突解决方法。随着数据的不断增加,散列表总会出现装载因子过高的情况。这个时候,我们就需要启动动态扩容。
课后思考
在你熟悉的编程语言中,哪些数据类型底层是基于散列表实现的?散列函数是如何设计的?散列冲突是通过哪种方法解决的?是否支持动态扩容呢?
欢迎留言和我分享,我会第一时间给你反馈。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号