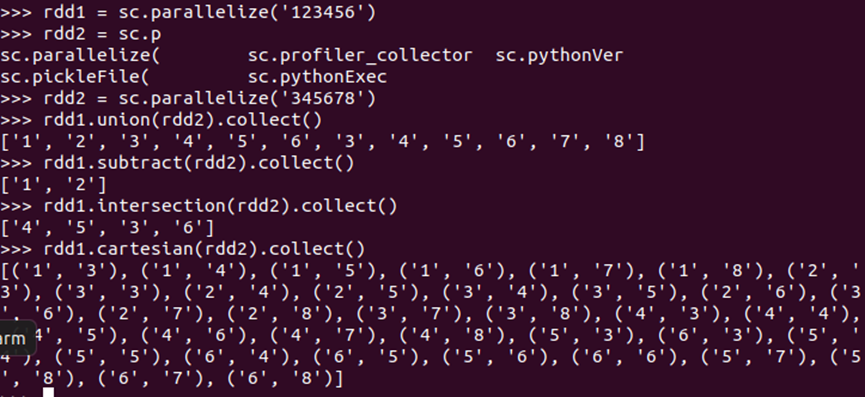
#集合运算操作(union(), intersection(),subtract(), cartesian())
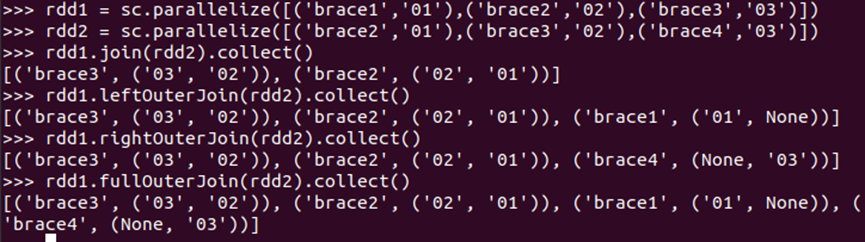
#内连接与外连接(join(), leftOuterJoin(), rightOuterJoin(), fullOuterJoin())
三、综合练习:学生课程分数
#导入数据并进行持久化操作
url='file:///home/hadoop/sc.txt' scm=sc.textFile(url).map(lambda line:line.split(',')).map(lambda line:[line[0],line[1],int(line[2])]) scm.cache()

scm.take(3) #取出前三个数据

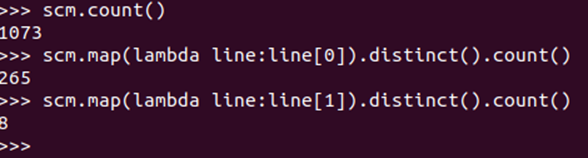
#通过一次映射去除重复姓名以及科目数量
scm.count() scm.map(lambda line:line[0]).distinct().count() scm.map(lambda line:line[1]).distinct().count()
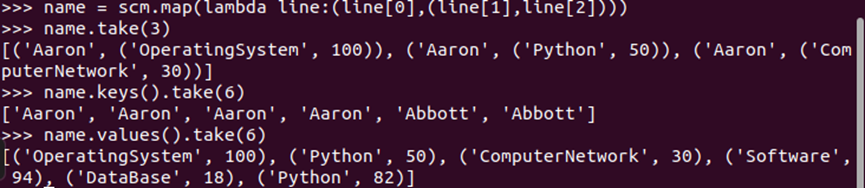
#键值对rdd转换操作
name = scm.map(lambda line:(line[0],(line[1],line[2]))) name.take(3) name.keys().take(6) name.values().take(6)
#统计每个学生选修多少门课程
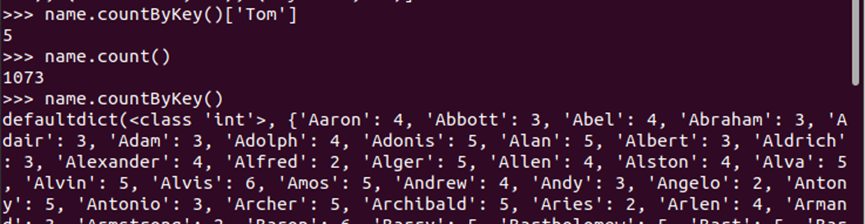
name.countByKey()['Tom'] name.count() name.countByKey()
#统计每门课程有多少学生选
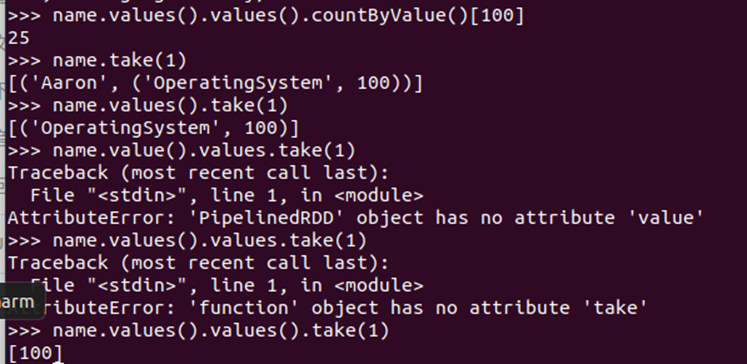
name.values().countByKey()

#统计有多少个100分
name.values().values().countByValue()[100] name.take(1) name.values().take(1) name.value().values.take(1) name.values().values().take(1)
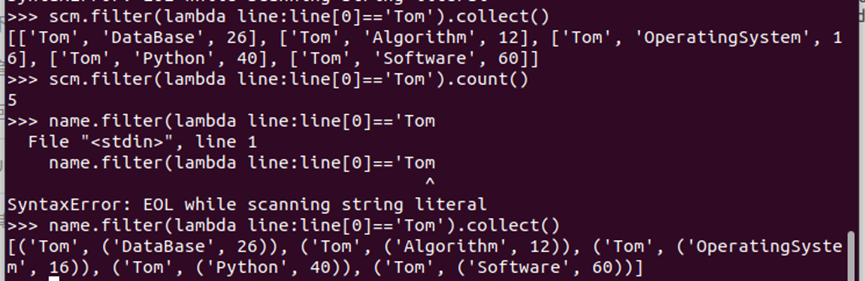
#Tom选修的课程
scm.filter(lambda line:line[0]=='Tom').collect() scm.filter(lambda line:line[0]=='Tom').count()
#Tom所有课程的平均分
np.mean(scm.filter(lambda line:line[0]=='Tom').map(lambda line:line[2]).collect())

#Tom的成绩按大小排序
name.filter(lambda line:line[0]=='Tom').values().collect() name.filter(lambda line:line[0]=='Tom').values().sortBy(lambda a:a[1],False).collect()

#生成课程Rdd
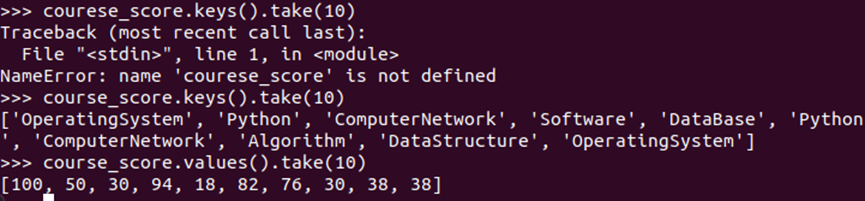
course_score = scm.map(lambda x:(x[1],int(x[2]))) courese_score.keys().take(10) course_score.keys().take(10) course_score.values().take(10)
#每个分数+5分。mapValues(func)
newscore = scm.map(lambda x:((x[0],x[1],x[2]))).mapValues(lambda x:x+5) scm.map(lambda x:((x[0],x[1],x[2]))).take(10) newscore.take(10)

#求每门课的选修人数及所有人的总分。combineByKey()
course_score.reduceByKey(lambda a,b:a+b).collectAsMap()
course_score.countByKey()

- 求每门课的选修人数及平均分,精确到2位小数。map(),round()
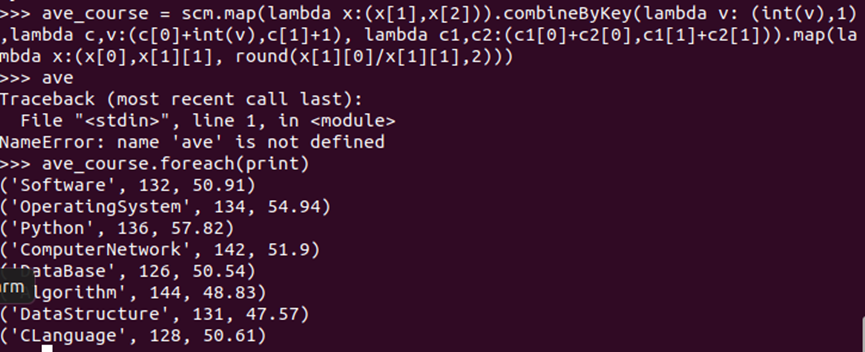
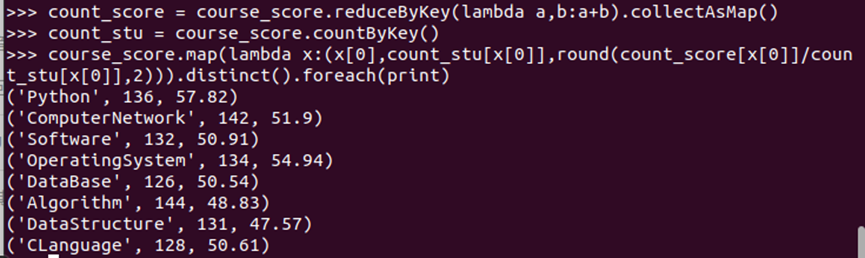
#求每门课的选修人数及平均分。用reduceByKey()实现,并比较与combineByKey()的异同
count_score = course_score.reduceByKey(lambda a,b:a+b).collectAsMap() count_stu = course_score.countByKey() course_score.map(lambda x:(x[0],count_stu[x[0]],round(count_score[x[0]]/count_stu[x[0]],2))).distinct().foreach(print)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号