一、词频统计
- 分步骤实现
- 准备文件
- 下载小说或长篇新闻稿
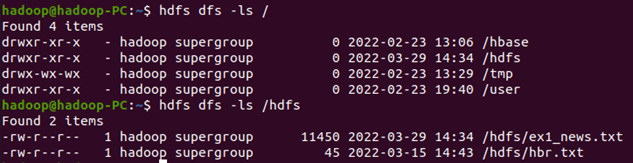
上传到hdfs上
hdfs dfs -ls /hdfs
- 读文件创建RDD
lines = sc.textFile(“file:///home/hadoop/ex1_news.txt”) lines.foreach(print)

- 分词
初次分词:无法分出带有字符的英文字符,需进行再次分词
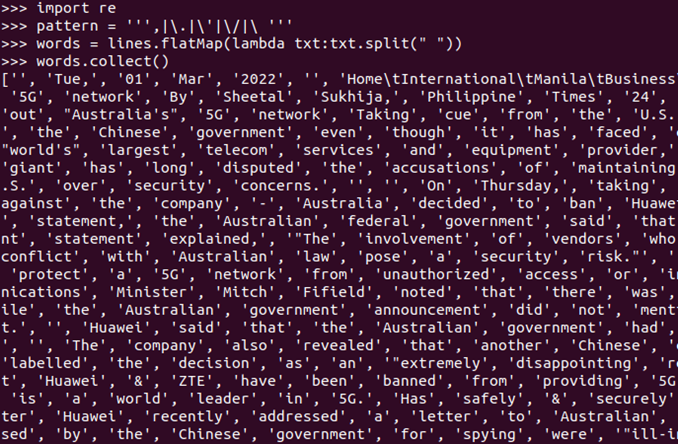
lines.flatMap(lambda line:line.split()).collect()

第二次分词:分出带有字符的英文字符
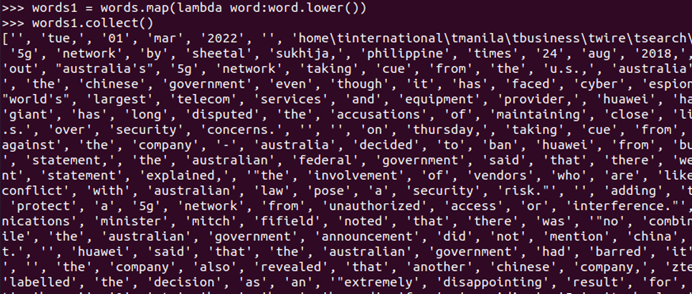
- 排除大小写lower(),map()
words1 = words.map(lambda word:word.lower())
words1.collect()
标点符号re.split(pattern,str),flatMap(),
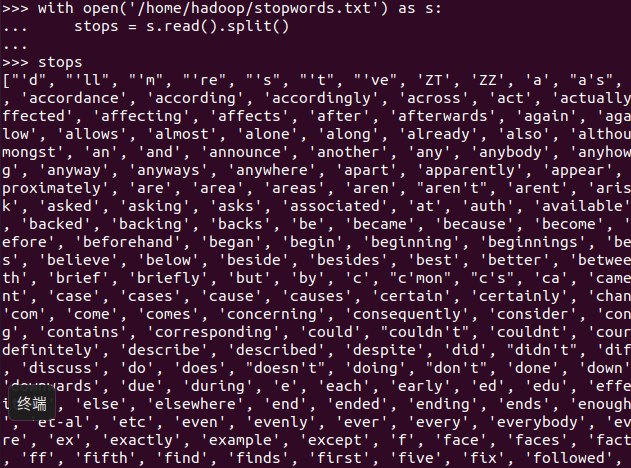
停用词,可网盘下载stopwords.txt,filter(),
with open(‘/home/Hadoop/stopwords.txt’) as s: stops = s.read().split()
words2 = words1.filter(lambda word:word not in stops).count()words.filter(lambda word:word not in stops).collect()

长度小于2的词filter()
words=words1.filter(lambda word:len(word)>2)words.collect()
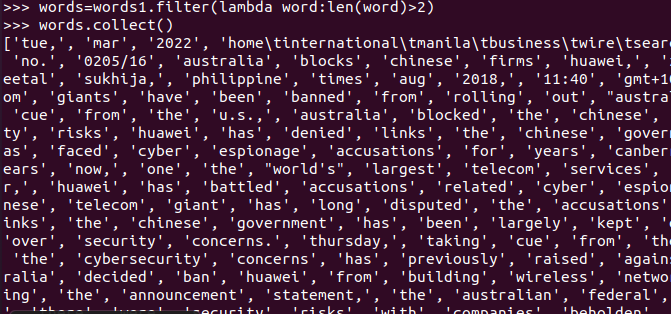
- 统计词频
wordKv = words.map(lambda word:(word,1)) wordKv.collect()
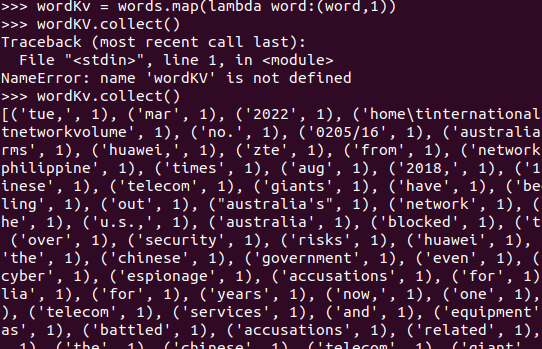
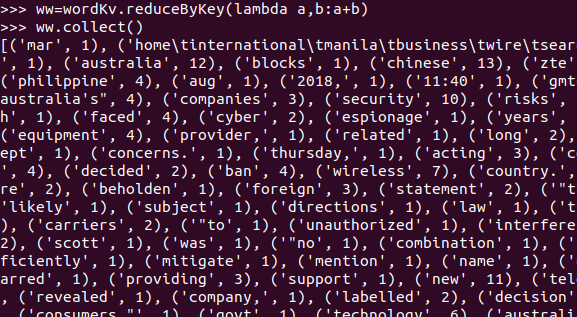
ww=wordKv.reduceByKey(lambda a,b:a+b)
ww.collect()
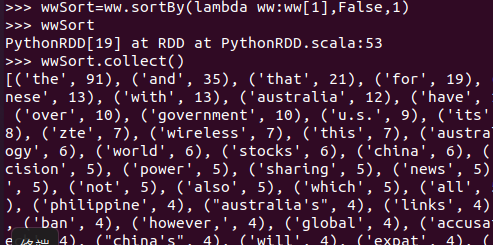
- 按词频排序
wwSort=ww.sortBy(lambda ww:ww[1],False,1) wwSort.collect()
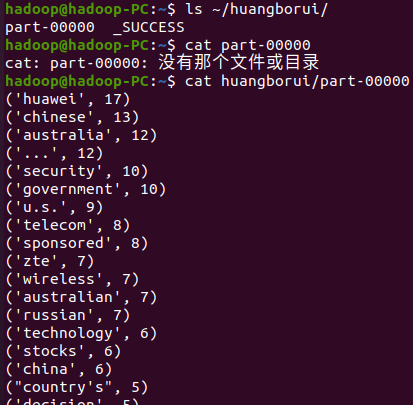
- 输出到文件
out_url = 'huangborui' wwSort.saveAsTextFile(out_url)

- 查看结果
hdfs dfs -ls

- 一句话实现:文件入文件出
sc.textFile("file:///home/hadoop/ex1_news.txt").flatMap(lambda line: line.split(" ")).map(lambda word: word.lower()).filter(lambda word: word not in stops).filter(lambda word:len(word)>2).map(lambda word:(word,1)).reduceByKey(lambda x,y :x+y).sortBy(lambda wc:wc[1],False,1).saveAsTextFile("file:///home/hadoop/huangborui")

二、求Top值
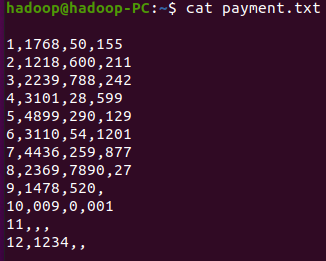
网盘下载payment.txt文件,通过RDD操作实现选出最大支付额的用户。
cat payment.txt
lines = sc.textFile("file:///home/hadoop/payment.txt")
lines.take(14)

items = lines.map(lambda line:line.split(',')) //拆分字段
items.collect()

//丢弃空行与字段不完整的行
items.map(lambda item:len(item)).collect()
items.count()

//过滤剩下长度为4的字段
item.filter(lambda item:len(item)==4).collect()


//丢弃有空值的行

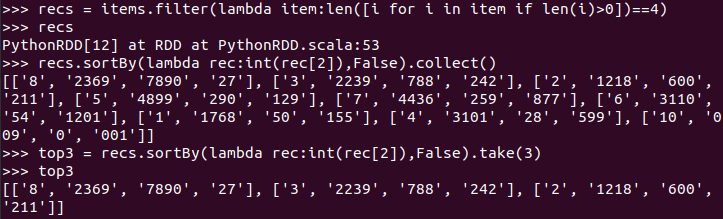
//有效的记录

//取前三名
top3 = recs.sortBy(lambda rec:int(rec[2]),False).take(3)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号