一、 RDD创建
1.从本地文件系统中加载数据创建RDD
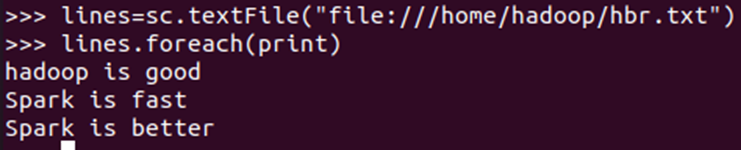
lines=sc.textFile("file:///home/hadoop/hbr.txt") lines.foreach(print)
2.从HDFS加载数据创建RDD
- 启动hdfs
start-all.sh
- 上传文件
hdfs dfs -put hbr.txt/hdfs

3.查看文件
hdfs dfs -cat /hdfs/ hbr.txt
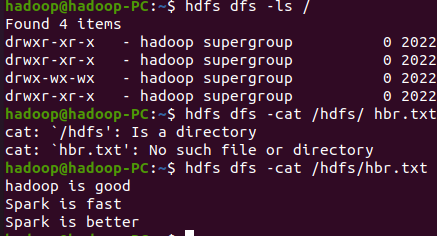
加载
- 停止hdfs
-
stop-all.sh
- 通过并行集合(列表)创建RDD
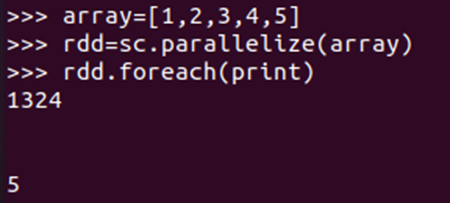
输入列表
字符串
numpy生成数组
二、 RDD操作
转换操作
- filter(func)
显式定义函数
lambda函数

- map(func)
显式定义函数
lambda函数
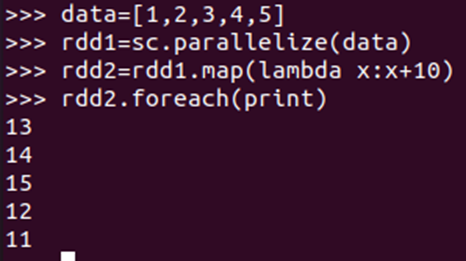
行动操作
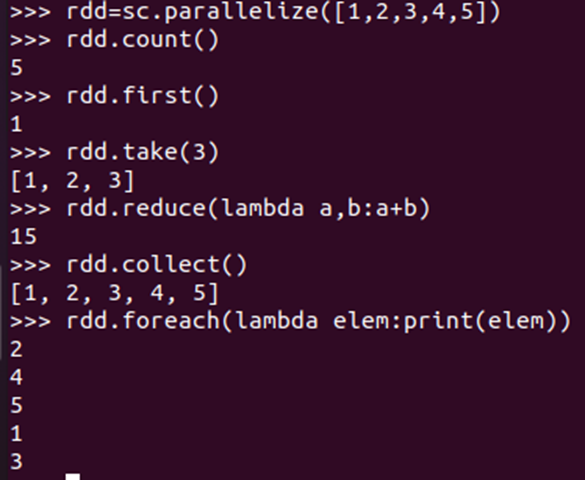
- foreach(print)
foreach(lambda a:print(a.upper()) - collect()
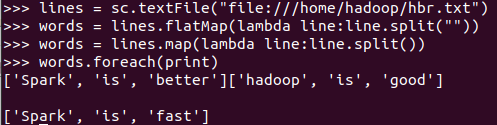
- 字符串分词
-
lines = sc.textFile("file:///home/hadoop/hbr.txt") words = lines.flatMap(lambda line:line.split("")) words = lines.map(lambda line:line.split()) words.foreach(print)
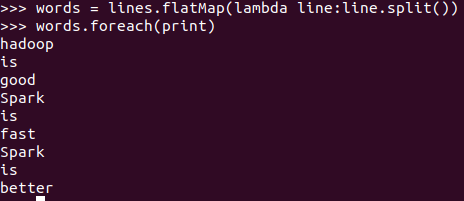
words = lines.flatMap(lambda line:line.split()) words.foreach(print)
- 数字加100
- 字符串加固定前缀
- flatMap(func)
- 分词
- 单词映射成键值对
- reduceByKey()
- 统计词频,累加
- 乘法规则
- groupByKey()
- 单词分组
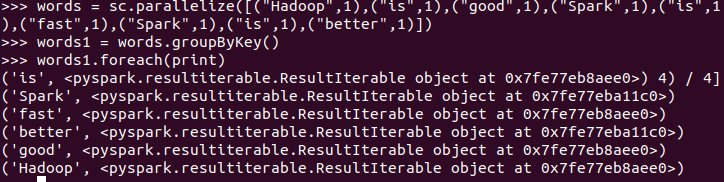
words = sc.parallelize([("Hadoop",1),("is",1),("good",1),("Spark",1),("is",1),("fast",1),("Spark",1),("is",1),("better",1)]) words1 = words.groupByKey() words1.foreach(print)
- 查看分组的内容
- 分组之后做累加 map
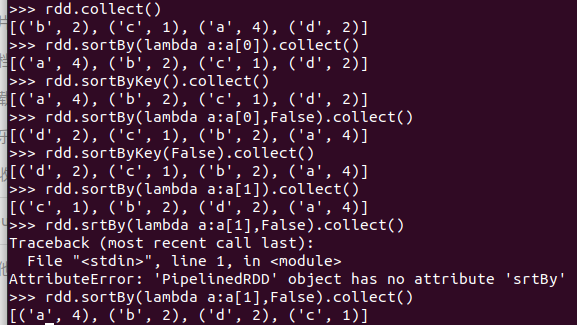
- sortByKey()
- 词频统计按单词排序
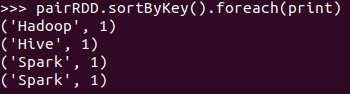
pairRDD.sortByKey().foreach(print)
- sortBy()
- 词频统计按词频排序
行动操作
- foreach(print)
foreach(lambda a:print(a.upper()) 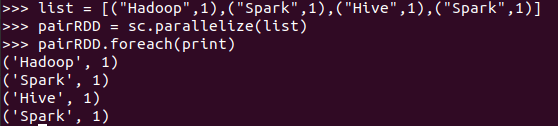
list = [("Hadoop",1),("Spark",1),("Hive",1),("Spark",1)] pairRDD = sc.parallelize(list) pairRDD.foreach(print)
- collect()
- count()
- take(n)
- reduce()
数值型的rdd元素做累加 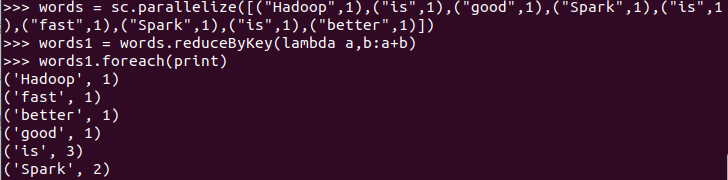
words = sc.parallelize([("Hadoop",1),("is",1),("good",1),("Spark",1),("is",1),("fast",1),("Spark",1),("is",1),("better",1)]) words1 = words.reduceByKey(lambda a,b:a+b) words1.foreach(print)
与reduceByKey区别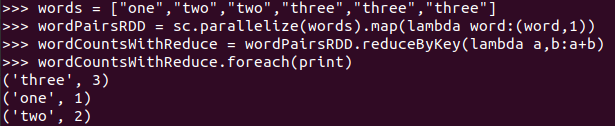
words = ["one","two","two","three","three","three"] wordPairsRDD = sc.parallelize(words).map(lambda word:(word,1)) wordCountsWithReduce = wordPairsRDD.reduceByKey(lambda a,b:a+b) wordCountsWithReduce.foreach(print)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号