一、安装Spark
1. 检查基础环境hadoop,jdk
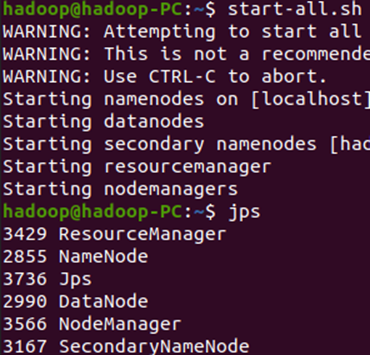
Start-all.sh(启动全部服务)
Jps:查看是否启动成功
2:下载spark
https://archive.apache.org/dist/spark/spark-3.2.0/spark-3.2.0-bin-without-hadoop.tgz

3:解压,文件夹重命名、权限
解压
sudo tar -zxvf ~/VMOS_share_DockerOS/spark-3.2.0-bin-without-hadoop.tgz -C /usr/local/
改名
sudo mv /usr/local/spark-3.2.0-bin-without-hadoop /usr/local/spark
授权
sudo chown -R hadoop /usr/local/spark
4:配置文件
配置PATH

5:环境变量
配置spark-env.sh
cd /usr/local/spark/conf sudo cp spark-env.sh.template spark-env.sh sudo vim spark-env.sh
开头加入
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath) export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_301 # 你的jdk export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop # 你的hadoop export SPARK_MASTER_HOST=master # 你的机器名 export SPARK_MASTER_PORT=7077 export SPARK_WORKER_CORES=1 export SPARK_WORKER_MEMORY=0.7g
配置workers

6:试运行Python代码
二、Python编程练习:英文文本的词频统计
- 准备文本文件
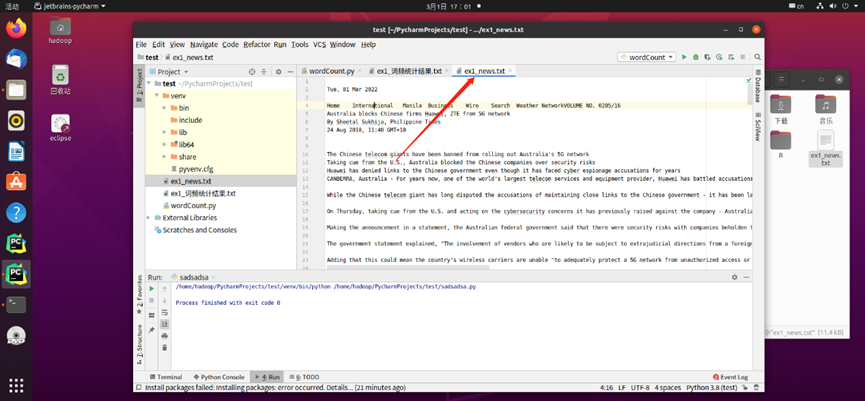
- 读文件
file = open('ex1_news.txt', encoding='utf-8')
- 预处理:大小写,标点符号,停用词
lowerText = file.read().lower()
- 分词
file.close() arr = re.split('[ ,.+"\n]', lowerText)
- 统计每个单词出现的次数
voc = {}; for each in arr: if each not in voc: voc[each] = 1; else: voc[each] += 1; voc.pop('');
- 按词频大小排序
vocSorted = sorted(voc.items(), key=lambda x: x[1], reverse=True) # 按照键值进行排序
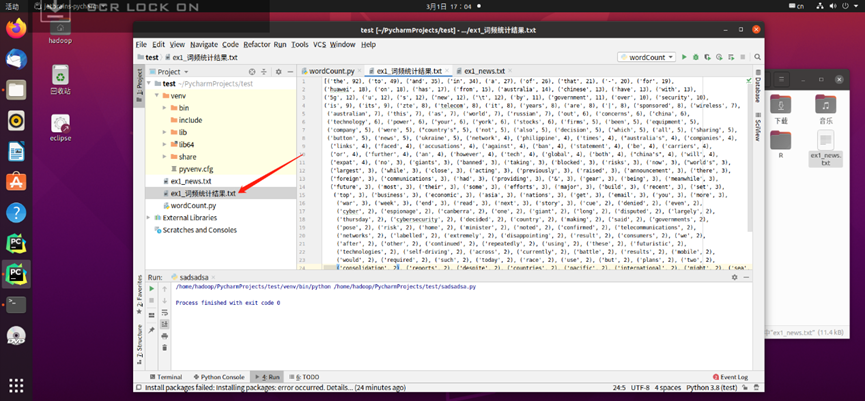
7.结果写文件
newFile = open('ex1_词频统计结果.txt', 'w') newFile.write(str(vocSorted)) newFile.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号